L'industrie s'est concentrée sur l'accélération de la multiplication matricielle, mais l'amélioration de l'algorithme de recherche peut conduire à une augmentation plus sérieuse des performances

Ces dernières années, l'industrie informatique s'est efforcée d'accélérer les calculs requis pour les réseaux de neurones artificiels - à la fois pour la formation et pour tirer des conclusions de son travail. En particulier, beaucoup d'efforts ont été consacrés au développement de fer spécial sur lequel ces calculs peuvent être effectués. Google a développé la
Tensor Processing Unit , ou TPU,
présentée pour la première
fois au public en 2016. Nvidia a ensuite présenté l'unité de traitement graphique
V100 , la décrivant comme une puce spécialement conçue pour la formation et l'utilisation de l'IA, ainsi que pour d'autres besoins informatiques à hautes performances. Plein d'autres startups, se concentrant sur d'autres types d'
accélérateurs matériels .
Peut-être qu'ils font tous une grande erreur.
Cette idée a été exprimée dans l'
ouvrage paru mi-mars sur le site arXiv. Ses auteurs,
Beidi Chen ,
Tarun Medini et
Anshumali Srivastava de l'Université Rice, soutiennent que l'équipement spécial développé pour le fonctionnement des réseaux de neurones est peut-être optimisé pour le mauvais algorithme.
Le fait est que le travail des réseaux de neurones dépend généralement de la rapidité avec laquelle l'équipement peut effectuer la multiplication des matrices utilisées pour déterminer les paramètres de sortie de chaque neutron artificiel - son «activation» - pour un ensemble donné de valeurs d'entrée. Les matrices sont utilisées parce que chaque valeur d'entrée pour un neurone est multipliée par le paramètre de poids correspondant, puis elles sont toutes additionnées - et cette multiplication avec addition est l'opération de base de la multiplication matricielle.
Les chercheurs de l'Université Rice, comme certains autres scientifiques, ont réalisé que l'activation de nombreux neurones dans une couche particulière du réseau neuronal est trop petite et n'affecte pas la valeur de sortie calculée par les couches suivantes. Par conséquent, si vous savez ce que sont ces neurones, vous pouvez simplement les ignorer.
Il peut sembler que la seule façon de savoir quels neurones d'une couche ne sont pas activés est d'effectuer d'abord toutes les opérations de multiplication matricielle pour cette couche. Mais les chercheurs ont réalisé que vous pouvez réellement décider de cette manière plus efficace si vous regardez le problème sous un angle différent. «Nous abordons ce problème comme une solution au problème de recherche», explique Srivastava.
Autrement dit, au lieu de calculer les multiplications matricielles et de voir quels neurones ont été activés pour une entrée donnée, vous pouvez simplement voir quels types de neurones se trouvent dans la base de données. L'avantage de cette approche dans le problème est que vous pouvez utiliser une stratégie généralisée qui a longtemps été améliorée par les informaticiens pour accélérer la recherche de données dans la base de données: le hachage.
Le hachage vous permet de vérifier rapidement s'il existe une valeur dans la table de base de données, sans avoir à parcourir chaque ligne d'une ligne. Vous utilisez un hachage, facilement calculé en appliquant une fonction de hachage à la valeur souhaitée, indiquant où cette valeur doit être stockée dans la base de données. Ensuite, vous ne pouvez vérifier qu'un seul endroit pour savoir si cette valeur y est stockée.
Les chercheurs ont fait quelque chose de similaire pour les calculs liés aux réseaux de neurones. L'exemple suivant aidera à illustrer leur approche:
Supposons que nous avons créé un réseau de neurones qui reconnaît la saisie manuscrite de nombres. Supposons que l'entrée soit des pixels gris dans un tableau 16x16, c'est-à-dire un total de 256 nombres. Nous alimentons ces données à une couche cachée de 512 neurones, dont les résultats d'activation sont alimentés par la couche de sortie de 10 neurones, un pour chacun des nombres possibles.
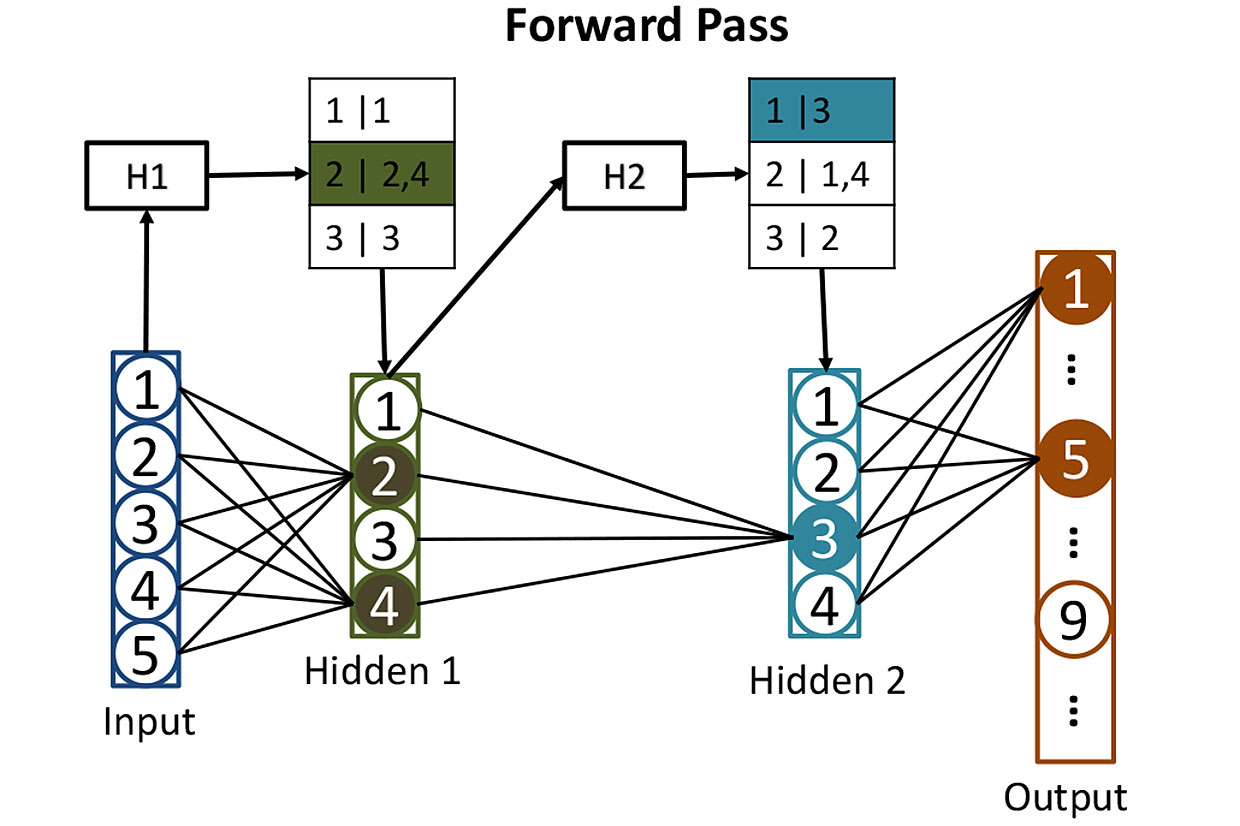 Tableaux de réseaux: avant de calculer l'activation des neurones dans les couches cachées, nous utilisons des hachages pour nous aider à déterminer quels neurones seront activés. Ici, le hachage des valeurs d'entrée H1 est utilisé pour rechercher les neurones correspondants dans la première couche cachée - dans ce cas, ce seront les neurones 2 et 4. Le deuxième hachage H2 montre quels neurones de la deuxième couche cachée contribueront. Une telle stratégie réduit le nombre d'activations à calculer.
Tableaux de réseaux: avant de calculer l'activation des neurones dans les couches cachées, nous utilisons des hachages pour nous aider à déterminer quels neurones seront activés. Ici, le hachage des valeurs d'entrée H1 est utilisé pour rechercher les neurones correspondants dans la première couche cachée - dans ce cas, ce seront les neurones 2 et 4. Le deuxième hachage H2 montre quels neurones de la deuxième couche cachée contribueront. Une telle stratégie réduit le nombre d'activations à calculer.Il est assez difficile de former un tel réseau, mais pour l'instant, diminuons ce moment et imaginons que nous avons déjà ajusté tous les poids de chaque neurone afin que le réseau de neurones reconnaisse parfaitement les nombres manuscrits. Lorsqu'un nombre écrit lisiblement arrive à son entrée, l'activation d'un des neurones de sortie (correspondant à ce nombre) sera proche de 1. L'activation des neuf autres sera proche de 0. Classiquement, le fonctionnement d'un tel réseau nécessite une multiplication matricielle pour chacun des 512 neurones cachés, et un de plus pour chaque week-end - ce qui nous donne beaucoup de multiplications.
Les chercheurs adoptent une approche différente. La première étape consiste à hacher les poids de chacun des 512 neurones de la couche cachée en utilisant un "hachage sensible à la localité", dont l'une des propriétés est que des données d'entrée similaires donnent des valeurs de hachage similaires. Vous pouvez ensuite regrouper des neurones avec des hachages similaires, ce qui signifierait que ces neurones ont des ensembles de poids similaires. Chaque groupe peut être stocké dans une base de données et déterminé par le hachage des valeurs d'entrée qui conduira à l'activation de ce groupe de neurones.
Après tout ce hachage, il s'avère facile de déterminer lequel des neurones cachés sera activé par une nouvelle entrée. Vous devez exécuter 256 valeurs d'entrée via des fonctions de hachage faciles à calculer et utiliser le résultat pour rechercher dans la base de données les neurones qui seront activés. De cette façon, vous devrez calculer les valeurs d'activation pour seulement quelques neurones importants. Il n'est pas nécessaire de calculer l'activation de tous les autres neurones de la couche juste pour découvrir qu'ils ne contribuent pas au résultat.
L'entrée d'un tel réseau neuronal de données peut être représentée comme l'exécution d'une requête de recherche dans une base de données qui demande de trouver tous les neurones qui seraient activés par comptage direct. Vous obtenez la réponse rapidement car vous utilisez des hachages pour rechercher. Et puis, vous pouvez simplement calculer l'activation d'un petit nombre de neurones qui comptent vraiment.
Les chercheurs ont utilisé cette technique, qu'ils ont appelée SLIDE (Sub-LInear Deep learning Engine), pour former un réseau de neurones - pour un processus qui a plus de demandes de calcul qu'il ne le fait pour son objectif. Ils ont ensuite comparé les performances de l'algorithme d'apprentissage avec une approche plus traditionnelle utilisant un puissant GPU - en particulier, le GPU Nvidia V100. En conséquence, ils ont obtenu quelque chose d'incroyable: "Nos résultats montrent qu'en moyenne, la technologie CPU SLIDE peut fonctionner des ordres de grandeur plus rapidement que la meilleure alternative possible, implémentée sur le meilleur équipement et avec n'importe quelle précision."
Il est trop tôt pour tirer des conclusions quant à la résistance de ces résultats (que les experts n'ont pas encore évalués) aux tests et s'ils vont obliger les fabricants de puces à porter un regard différent sur le développement d'équipements spéciaux pour le deep learning. Mais le travail souligne définitivement le danger de l'entraînement d'un certain type de fer dans les cas où il existe la possibilité d'un nouvel et meilleur algorithme pour le fonctionnement des réseaux de neurones.