Bonjour à tous. Il reste de moins en moins de temps avant le lancement du cours
"Sécurité des systèmes d'information" , nous continuons donc aujourd'hui à partager les publications dédiées au lancement de ce cours. Soit dit en passant, cette publication fait suite à ces deux articles:
«Principes fondamentaux des moteurs JavaScript: formulaires généraux et mise en cache en ligne. Partie 1 " ,
" Principes de base des moteurs JavaScript: formulaires généraux et mise en cache en ligne. Partie 2 " .
L'article décrit les principes de base. Ils sont communs à tous les moteurs JavaScript, et pas seulement au
V8 sur lequel les auteurs travaillent (
Benedict et
Matthias ). En tant que développeur JavaScript, je peux dire qu'une compréhension plus approfondie du fonctionnement du moteur JavaScript vous aidera à comprendre comment écrire du code efficace.

Dans un
article précédent, nous avons expliqué comment les moteurs JavaScript optimisent l'accès aux objets et aux tableaux à l'aide de formulaires et de caches en ligne. Dans cet article, nous examinerons l'optimisation des compromis de pipeline et l'accélération de l'accès aux propriétés du prototype.
Remarque: si vous préférez regarder des présentations que lire des articles, regardez cette vidéo . Sinon, sautez-le et lisez la suite.
Niveaux d'optimisation et de compromisLa dernière fois, nous avons découvert que tous les moteurs JavaScript modernes ont en fait le même pipeline:
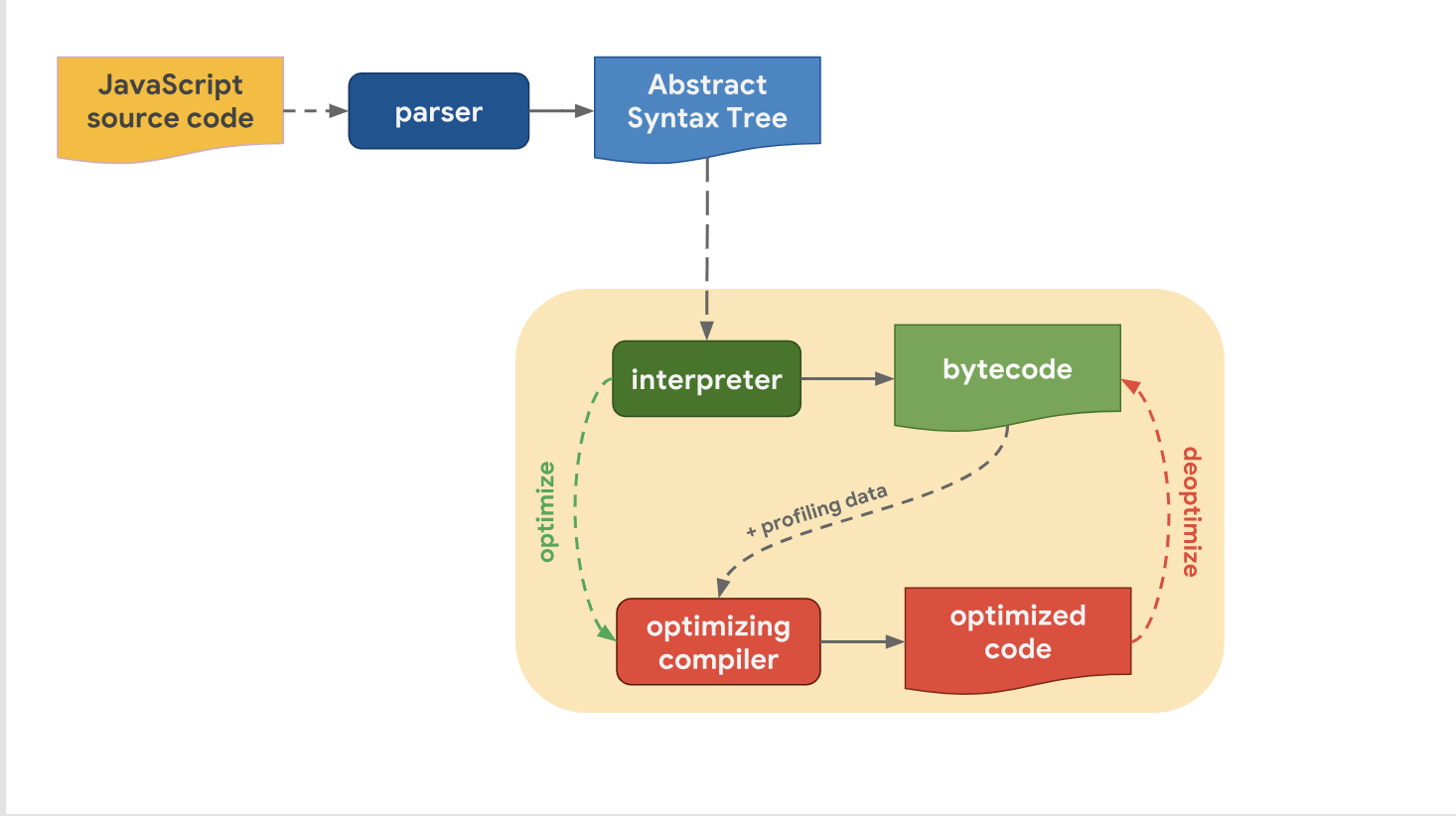
Nous avons également réalisé que, malgré le fait que les pipelines de haut niveau d'un moteur à l'autre aient une structure similaire, il existe une différence dans le pipeline d'optimisation. Pourquoi en est-il ainsi? Pourquoi certains moteurs ont-ils plus de niveaux d'optimisation que d'autres? Il s'agit de faire un compromis entre une transition rapide vers l'étape d'exécution de code ou passer un peu plus de temps à exécuter le code avec des performances optimales.

L'interpréteur peut générer rapidement du bytecode, mais le bytecode seul n'est pas suffisamment efficace en termes de vitesse. L'implication d'un compilateur d'optimisation dans ce processus passe un certain temps, mais permet un code machine plus efficace.
Voyons comment le V8 gère cela. Rappelons que dans la V8, l'interpréteur est appelé Ignition et il est considéré comme l'interprète le plus rapide parmi les moteurs existants (en matière de vitesse d'exécution du bytecode brut). Le compilateur d'optimisation dans V8 s'appelle TurboFan, et c'est lui qui génère le code machine hautement optimisé.

Le compromis entre le délai de démarrage et la vitesse d'exécution est la raison pour laquelle certains moteurs JavaScript préfèrent ajouter des niveaux d'optimisation supplémentaires entre les étapes. Par exemple, SpiderMonkey ajoute un niveau Baseline entre son interpréteur et le compilateur IonMonkey d'optimisation complet:
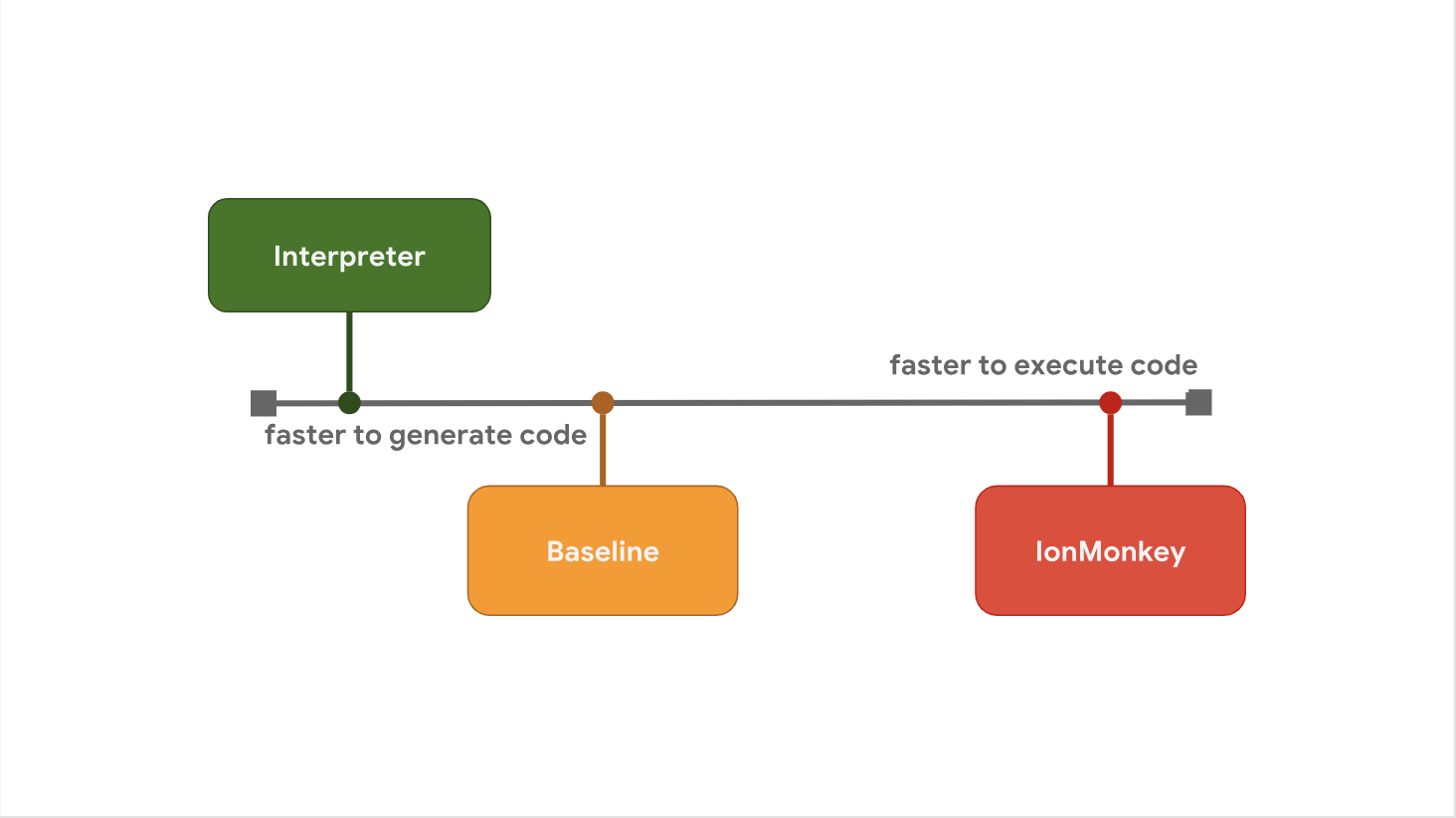
L'interpréteur génère rapidement du bytecode, mais le bytecode lui-même est relativement lent. Baseline génère du code un peu plus longtemps, mais offre de meilleures performances à l'exécution. Enfin, le compilateur d'optimisation IonMonkey passe le plus de temps à générer du code machine, mais ce code est extrêmement efficace.
Regardons un exemple spécifique et voyons comment les pipelines de divers moteurs gèrent ce problème. Ici, dans la boucle chaude, le même code est souvent répété.
let result = 0; for (let i = 0; i < 4242424242; ++i) { result += i; } console.log(result);
V8 commence par démarrer le bytecode dans l'interpréteur Ignition. À un moment donné, le moteur détermine que le code est chaud et lance l'interface TurboFan, qui intègre les données de profilage et crée une représentation machine de base du code. Il est ensuite envoyé à TurboFan optimizer dans un autre thread pour une amélioration supplémentaire.

Pendant que l'optimisation est en cours, V8 continue d'exécuter du code dans Ignition. À un moment donné, lorsque l'optimiseur est terminé et que nous avons reçu du code machine exécutable, il passe immédiatement à l'étape d'exécution.
SpyderMonkey démarre également l'exécution de bytecode dans l'interpréteur. Mais il a un niveau de base supplémentaire, ce qui signifie que le code chaud est envoyé en premier. Le compilateur Baseline génère du code Baseline dans le thread principal et continue son exécution à la fin de sa génération.

Si le code Baseline fonctionne depuis un certain temps, SpiderMonkey lance finalement l'interface IonMonkey (frontend IonMonkey) et exécute l'optimiseur, le processus est très similaire à V8. Tout cela continue de fonctionner en même temps dans Baseline, tandis qu'IonMonkey est engagé dans l'optimisation. Enfin, lorsque l'optimiseur a terminé son travail, le code optimisé est exécuté à la place du code de base.
L'architecture de Chakra est très similaire à SpiderMonkey, mais Chakra essaie d'exécuter plus de processus en même temps pour éviter de bloquer le thread principal. Au lieu d'exécuter n'importe quelle partie du compilateur dans le thread principal, Chakra copie le bytecode et les données de profilage dont le compilateur a besoin et les envoie au processus de compilation dédié.

Lorsque le code généré est prêt, le moteur exécute ce code SimpleJIT au lieu du bytecode. La même chose se produit avec FullJIT. L'avantage de cette approche est que la pause qui se produit pendant la copie est généralement beaucoup plus courte que le démarrage d'un compilateur à part entière (frontal). D'un autre côté, cette approche présente un inconvénient. Cela réside dans le fait que l'heuristique de copie peut ignorer certaines informations qui seront nécessaires à l'optimisation, nous pouvons donc dire que dans une certaine mesure, la qualité du code est sacrifiée pour accélérer le travail.
Dans JavaScriptCore, tous les compilateurs d'optimisation fonctionnent complètement en parallèle avec l'exécution de base de JavaScript. Il n'y a pas de phase de copie. Au lieu de cela, le thread principal commence simplement à compiler dans un autre thread. Les compilateurs utilisent ensuite un schéma de verrouillage complexe pour accéder aux données de profilage à partir du thread principal.

L'avantage de cette approche est qu'elle réduit la quantité de déchets qui apparaît après l'optimisation dans le thread principal. L'inconvénient de cette approche est qu'elle nécessite la résolution de problèmes complexes de multithreading et certains coûts de blocage pour diverses opérations.
Nous avons parlé des compromis entre la génération de code rapide pendant l'exécution de l'interpréteur et la génération de code rapide à l'aide du compilateur d'optimisation. Mais il y a un autre compromis, et il concerne l'utilisation de la mémoire. Pour l'illustrer, j'ai écrit un programme JavaScript simple qui ajoute deux nombres.
function add(x, y) { return x + y; } add(1, 2);
Regardez le bytecode qui est généré pour la fonction add par l'interpréteur Ignition dans V8.
StackCheck Ldar a1 Add a0, [0] Return
Ne vous inquiétez pas du bytecode, vous n'avez pas besoin de pouvoir le lire. Ici, il faut faire attention au fait qu'il ne contient
que 4 instructions .
Lorsque le code devient chaud, TurboFan génère un code machine hautement optimisé, qui est présenté ci-dessous:
leaq rcx,[rip+0x0] movq rcx,[rcx-0x37] testb [rcx+0xf],0x1 jnz CompileLazyDeoptimizedCode push rbp movq rbp,rsp push rsi push rdi cmpq rsp,[r13+0xe88] jna StackOverflow movq rax,[rbp+0x18] test al,0x1 jnz Deoptimize movq rbx,[rbp+0x10] testb rbx,0x1 jnz Deoptimize movq rdx,rbx shrq rdx, 32 movq rcx,rax shrq rcx, 32 addl rdx,rcx jo Deoptimize shlq rdx, 32 movq rax,rdx movq rsp,rbp pop rbp ret 0x18
Il y a vraiment beaucoup d'équipes ici, surtout en comparaison avec les quatre que nous avons vues dans le bytecode. En général, le bytecode est beaucoup plus volumineux que le code machine, et en particulier le code machine optimisé. Le bytecode, en revanche, est exécuté par l'interpréteur, tandis que le code optimisé peut être exécuté directement par le processeur.
C'est l'une des raisons pour lesquelles les moteurs JavaScript ne font pas que «tout optimiser». Comme nous l'avons vu précédemment, la génération de code machine optimisé prend beaucoup de temps et nécessite donc plus de mémoire.
 Pour résumer:
Pour résumer: La raison pour laquelle les moteurs JavaScript ont différents niveaux d'optimisation est de trouver un compromis entre la génération de code rapide à l'aide de l'interpréteur et la génération de code rapide à l'aide du compilateur d'optimisation. L'ajout de niveaux d'optimisation supplémentaires vous permet de prendre des décisions plus éclairées, en fonction du coût de la complexité et des frais supplémentaires lors de l'exécution. De plus, il existe un compromis entre le niveau d'optimisation et l'utilisation de la mémoire. C'est pourquoi les moteurs JavaScript essaient d'optimiser uniquement les fonctions chaudes.
Optimiser l'accès aux propriétés du prototypeLa dernière fois, nous avons expliqué comment les moteurs JavaScript optimisent le chargement des propriétés des objets à l'aide de formulaires et de caches en ligne. Rappelons que les moteurs stockent les formes des objets séparément des valeurs de l'objet.
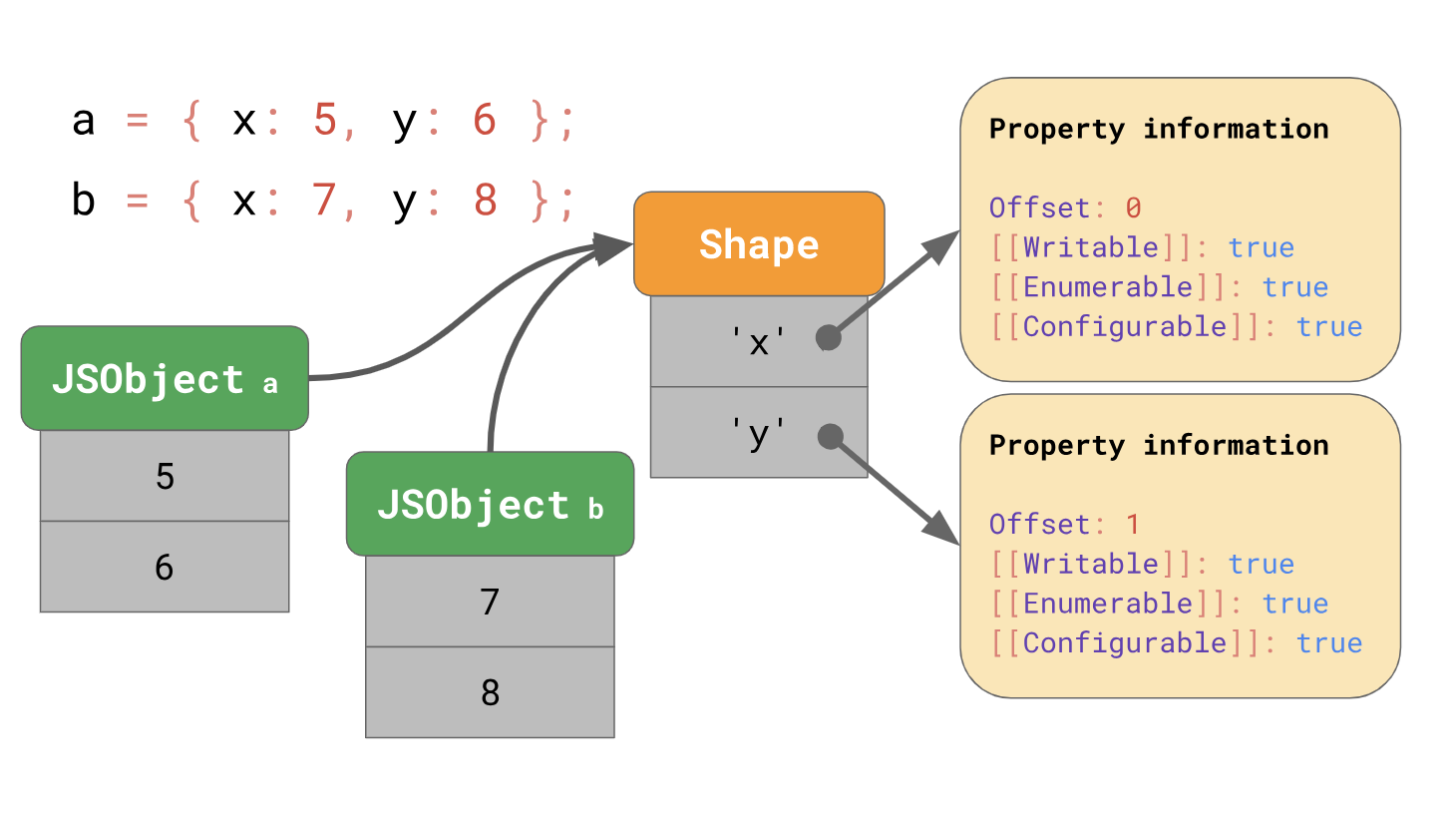
Les formulaires vous permettent d'utiliser l'optimisation à l'aide de caches en ligne ou de circuits intégrés abrégés. Lorsque vous travaillez ensemble, les formulaires et les CI peuvent accélérer l'accès répété aux propriétés au même endroit dans votre code.
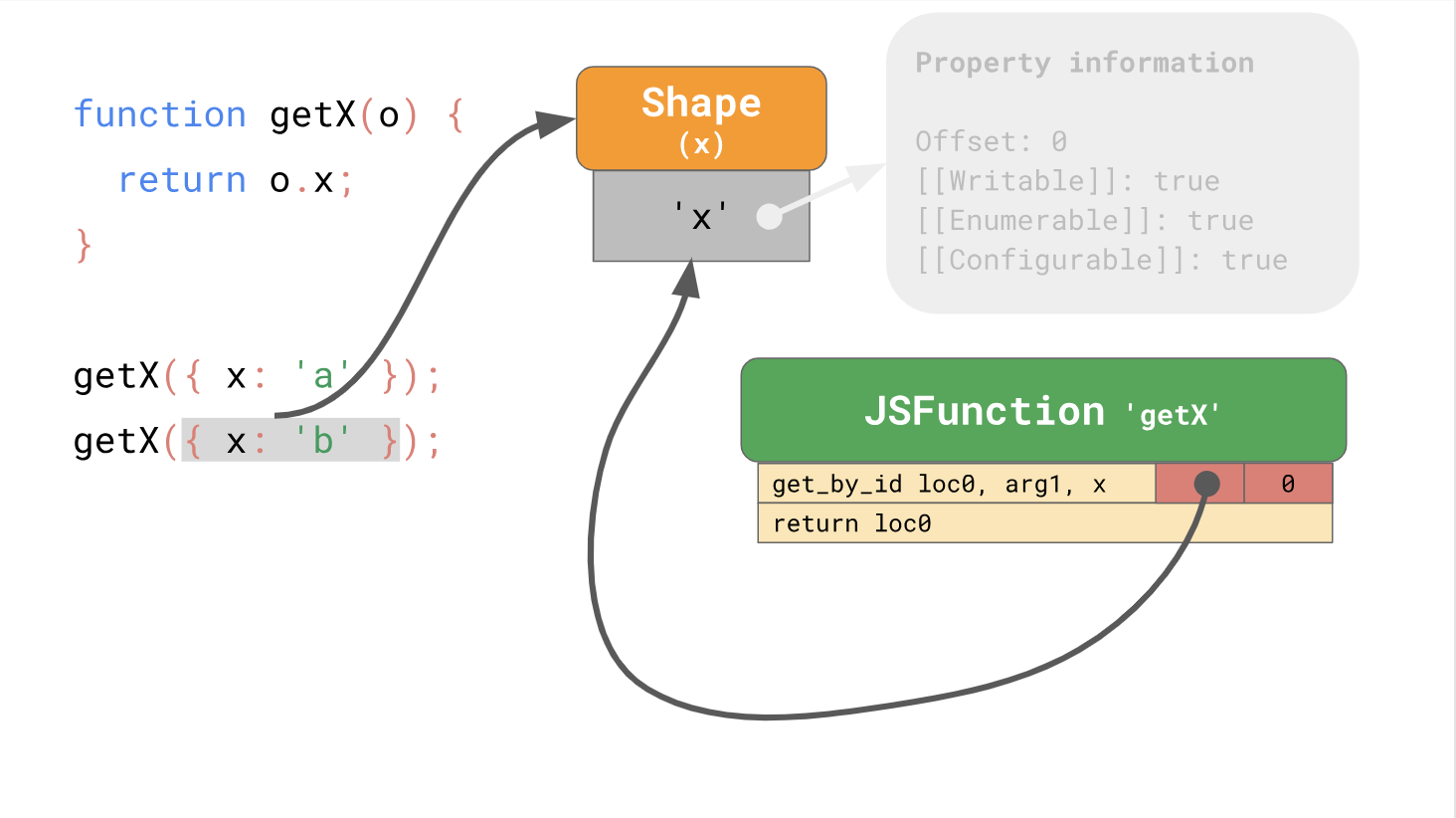
La première partie de la publication a donc pris fin, et les classes et la programmation des prototypes se trouvent dans la
deuxième partie . Traditionnellement, nous attendons vos commentaires et discussions houleuses, ainsi que nous vous invitons à une
journée portes ouvertes sur le cours "Sécurité des Systèmes d'Information".