En règle générale, Nginx utilise des produits commerciaux ou des alternatives open source, telles que Prometheus + Grafana, pour surveiller et analyser les performances de Nginx. C'est une bonne option pour la surveillance ou l'analyse en temps réel, mais pas trop pratique pour l'analyse historique. Sur toute ressource populaire, la quantité de données des journaux nginx augmente rapidement et il est logique d'utiliser quelque chose de plus spécialisé pour analyser une grande quantité de données.
Dans cet article, je vais vous expliquer comment utiliser Athena pour analyser les journaux en utilisant Nginx comme exemple, et montrer comment compiler un tableau de bord analytique à partir de ces données en utilisant le framework open source cube.js. Voici l'architecture complète de la solution:

TL: DR;
Lien vers le tableau de bord terminé .
Nous utilisons Fluentd pour collecter des informations, AWS Kinesis Data Firehose et AWS Glue pour le traitement et AWS S3 pour le stockage. En utilisant cet ensemble, vous pouvez stocker non seulement les journaux nginx, mais également d'autres événements, ainsi que les journaux d'autres services. Vous pouvez remplacer certaines pièces par des pièces similaires pour votre pile, par exemple, vous pouvez écrire des journaux dans kinesis directement à partir de nginx, en contournant fluentd, ou utiliser logstash pour ce faire.
Collecte des journaux Nginx
Par défaut, les journaux Nginx ressemblent à ceci:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-" 4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
Ils peuvent être analysés, mais il est beaucoup plus facile de corriger la configuration Nginx afin qu'elle affiche les journaux en JSON:
log_format json_combined escape=json '{ "created_at": "$msec", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"request": "$request", ' '"status": $status, ' '"bytes_sent": $bytes_sent, ' '"request_length": $request_length, ' '"request_time": $request_time, ' '"http_referrer": "$http_referer", ' '"http_x_forwarded_for": "$http_x_forwarded_for", ' '"http_user_agent": "$http_user_agent" }'; access_log /var/log/nginx/access.log json_combined;
S3 pour le stockage
Pour stocker les journaux, nous utiliserons S3. Cela vous permet de stocker et d'analyser les journaux en un seul endroit, car Athena peut travailler directement avec les données dans S3. Plus loin dans l'article, je vous dirai comment plier et traiter correctement les journaux, mais nous avons d'abord besoin d'un seau propre dans S3, dans lequel rien d'autre ne sera stocké. Il est utile de penser à l'avance dans quelle région vous allez créer le bucket, car Athena n'est pas disponible dans toutes les régions.
Créer un diagramme dans la console Athena
Créez une table dans Athena pour les journaux. Il est nécessaire à la fois pour l'écriture et la lecture, si vous prévoyez d'utiliser Kinesis Firehose. Ouvrez la console Athena et créez une table:
Création de table SQL CREATE EXTERNAL TABLE `kinesis_logs_nginx`( `created_at` double, `remote_addr` string, `remote_user` string, `request` string, `status` int, `bytes_sent` int, `request_length` int, `request_time` double, `http_referrer` string, `http_x_forwarded_for` string, `http_user_agent` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 's3://<YOUR-S3-BUCKET>' TBLPROPERTIES ('has_encrypted_data'='false');
Créer un flux Firehose Kinesis
Kinesis Firehose écrira les données reçues de Nginx vers S3 dans le format sélectionné, divisées en répertoires au format AAAA / MM / JJ / HH. Ceci est utile lors de la lecture de données. Vous pouvez, bien sûr, écrire directement sur S3 à partir de fluentd, mais dans ce cas, vous devez écrire JSON, ce qui est inefficace en raison de la grande taille du fichier. De plus, lorsque vous utilisez PrestoDB ou Athena, JSON est le format de données le plus lent. Alors ouvrez la console Kinesis Firehose, cliquez sur "Créer un flux de livraison", sélectionnez "PUT direct" dans le champ "livraison":
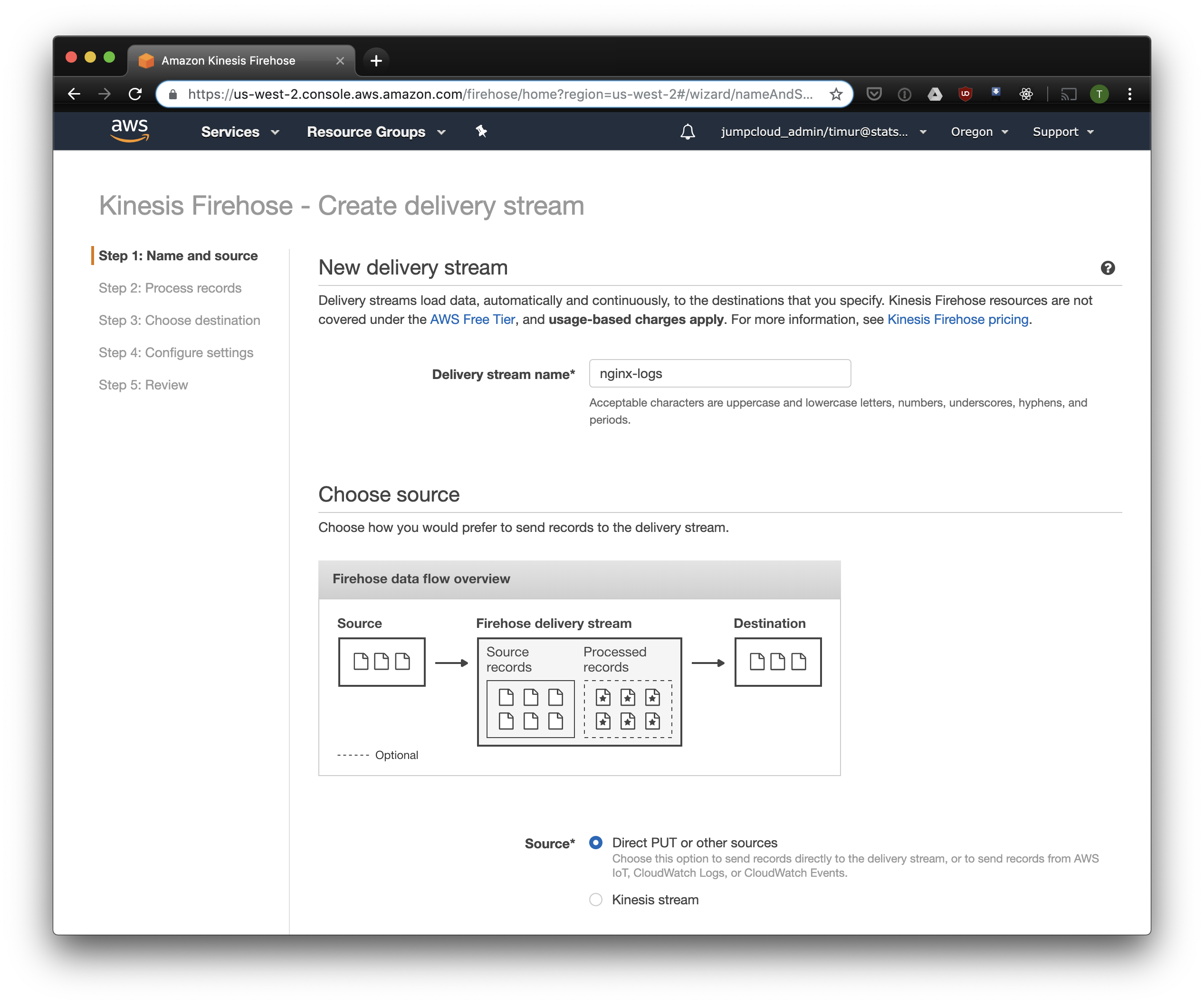
Dans l'onglet suivant, sélectionnez "Conversion de format d'enregistrement" - "Activé" et sélectionnez "Apache ORC" comme format d'enregistrement. Selon certains Owen O'Malley , c'est le format optimal pour PrestoDB et Athena. Sous forme de diagramme, nous indiquons le tableau que nous avons créé ci-dessus. Veuillez noter que vous pouvez spécifier n'importe quel emplacement S3 dans kinesis, seul le schéma est utilisé dans le tableau. Mais si vous spécifiez un autre emplacement S3, la lecture de ces enregistrements de cette table ne fonctionnera pas.
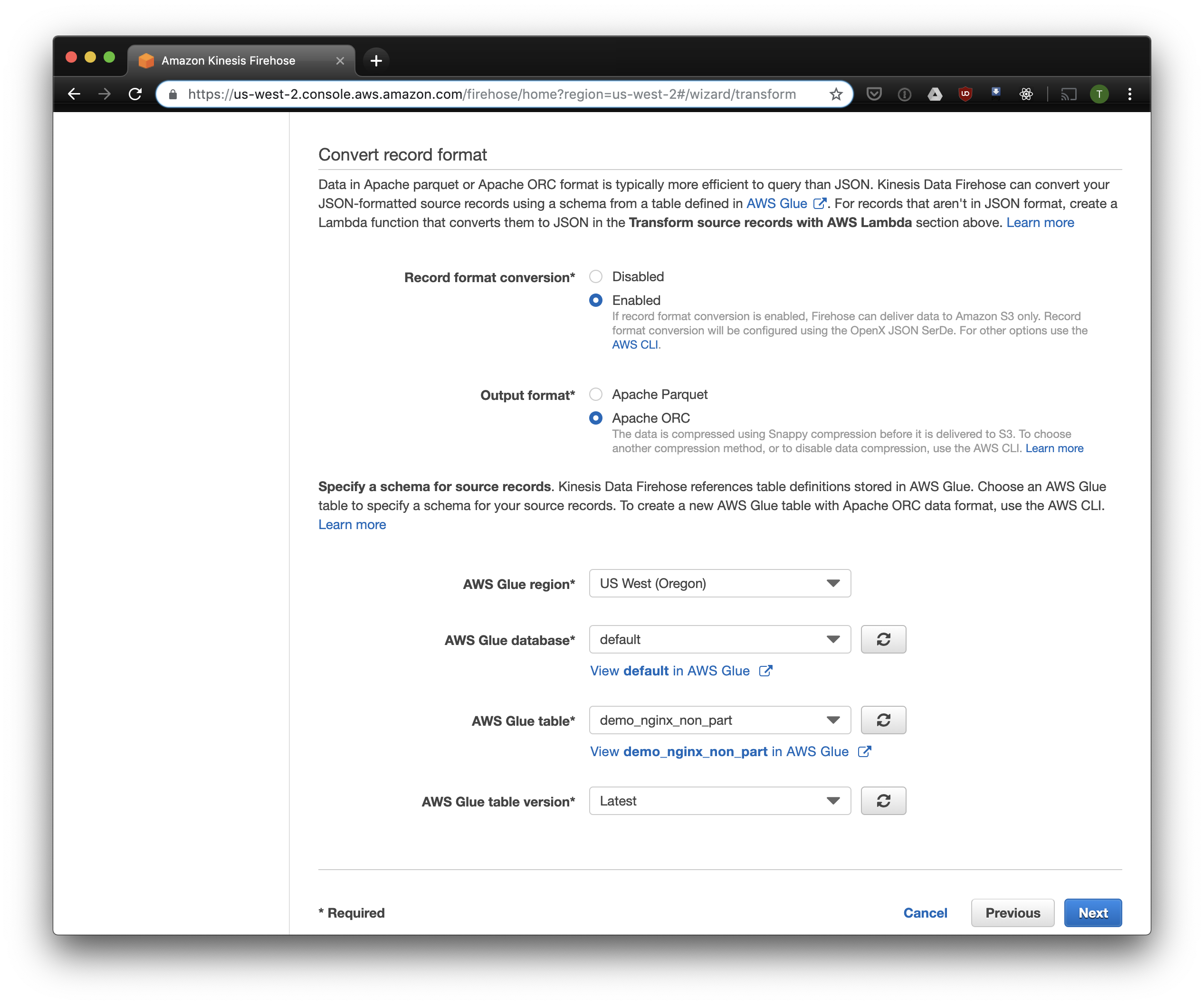
Nous choisissons S3 pour le stockage et le seau que nous avons créé précédemment. Aws Glue Crawler, dont je parlerai un peu plus tard, ne sait pas comment travailler avec les préfixes dans le compartiment S3, il est donc important de le laisser vide.

Les options restantes peuvent être modifiées en fonction de votre charge, j'utilise généralement celles par défaut. Notez que la compression S3 n'est pas disponible, mais ORC utilise la compression native par défaut.
Fluentd
Maintenant que nous avons configuré le stockage et la réception des journaux, vous devez configurer l'envoi. Nous utiliserons Fluentd parce que j'aime Ruby, mais vous pouvez utiliser Logstash ou envoyer des journaux directement à kinésis. Vous pouvez démarrer le serveur Fluentd de plusieurs manières, je vais parler de docker, car il est simple et pratique.
Tout d'abord, nous avons besoin du fichier de configuration fluent.conf. Créez-le et ajoutez la source:
taper en avant
port 24224
lier 0.0.0.0
Vous pouvez maintenant démarrer le serveur Fluentd. Si vous avez besoin d'une configuration plus avancée, le Docker Hub dispose d'un guide détaillé, y compris comment assembler votre image.
$ docker run \ -d \ -p 24224:24224 \ -p 24224:24224/udp \ -v /data:/fluentd/log \ -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd \ -c /fluentd/etc/fluent.conf fluent/fluentd:stable
Cette configuration utilise le /fluentd/log pour mettre en cache les journaux avant l'envoi. Vous pouvez vous en passer, mais lorsque vous redémarrez, vous pouvez tout perdre mis en cache par un travail excessif. N'importe quel port peut également être utilisé, 24224 est le port Fluentd par défaut.
Maintenant que Fluentd est en cours d'exécution, nous pouvons y envoyer des journaux Nginx. Nous exécutons généralement Nginx dans un conteneur Docker, auquel cas Docker a un pilote de journal natif pour Fluentd:
$ docker run \ --log-driver=fluentd \ --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>\ --log-opt tag=\"{{.Name}}\" \ -v /some/content:/usr/share/nginx/html:ro \ -d \ nginx
Si vous exécutez Nginx différemment, vous pouvez utiliser les fichiers journaux, Fluentd a un plugin file tail .
Ajoutez l'analyse de journal configurée ci-dessus à la configuration Fluent:
<filter YOUR-NGINX-TAG.*> @type parser key_name log emit_invalid_record_to_error false <parse> @type json </parse> </filter>
Et l'envoi de journaux à Kinesis à l'aide du plugin firehose kinesis :
<match YOUR-NGINX-TAG.*> @type kinesis_firehose region region delivery_stream_name <YOUR-KINESIS-STREAM-NAME> aws_key_id <YOUR-AWS-KEY-ID> aws_sec_key <YOUR_AWS-SEC_KEY> </match>
Athéna
Si vous avez tout configuré correctement, après un certain temps (par défaut, Kinesis écrit les données reçues toutes les 10 minutes), vous devriez voir les fichiers journaux dans S3. Dans le menu "Surveillance" de Kinesis Firehose, vous pouvez voir la quantité de données écrites sur S3, ainsi que les erreurs. N'oubliez pas de donner un accès en écriture au compartiment S3 pour le rôle Kinesis. Si Kinesis n'a pas pu analyser quelque chose, il ajoutera des erreurs dans le même compartiment.
Vous pouvez maintenant voir les données dans Athena. Trouvons quelques nouvelles requêtes auxquelles nous avons donné des erreurs:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;
Analyser tous les enregistrements pour chaque demande
Maintenant, nos journaux sont traités et empilés dans S3 en ORC, compressés et prêts à être analysés. Kinesis Firehose les a même placés dans des répertoires toutes les heures. Cependant, bien que la table ne soit pas partitionnée, Athena chargera des données absolues pour chaque requête, à de rares exceptions près. C'est un gros problème pour deux raisons:
- La quantité de données augmente constamment, ce qui ralentit les requêtes;
- Athena est facturée en fonction de la quantité de données analysées, avec un minimum de 10 Mo pour chaque demande.
Pour résoudre ce problème, nous utilisons AWS Glue Crawler, qui analysera les données dans S3 et enregistrera les informations de partition dans Glue Metastore. Cela nous permettra d'utiliser des partitions comme filtre pour les demandes dans Athena, et il analysera uniquement les répertoires spécifiés dans la demande.
Personnaliser Amazon Glue Crawler
Amazon Glue Crawler analyse toutes les données du compartiment S3 et crée des tables de partition. Créez un robot Glue à partir de la console AWS Glue et ajoutez le compartiment dans lequel vous stockez les données. Vous pouvez utiliser un robot pour plusieurs compartiments, dans ce cas, il créera des tables dans la base de données spécifiée avec des noms qui correspondent aux noms des compartiments. Si vous prévoyez d'utiliser ces données tout le temps, assurez-vous d'ajuster le calendrier de lancement du robot en fonction de vos besoins. Nous utilisons un robot pour toutes les tables, qui s'exécute toutes les heures.
Tables partitionnées
Après le premier démarrage du robot, les tables de chaque compartiment analysé doivent apparaître dans la base de données spécifiée dans les paramètres. Ouvrez la console Athena et trouvez la table avec les journaux Nginx. Essayons de lire quelque chose:
SELECT * FROM "default"."part_demo_kinesis_bucket" WHERE( partition_0 = '2019' AND partition_1 = '04' AND partition_2 = '08' AND partition_3 = '06' );
Cette requête sélectionnera tous les enregistrements reçus de 6 h à 7 h le 8 avril 2019. Mais combien plus efficace que la simple lecture d'une table non partitionnée? Découvrons et sélectionnons les mêmes enregistrements en les filtrant par horodatage:
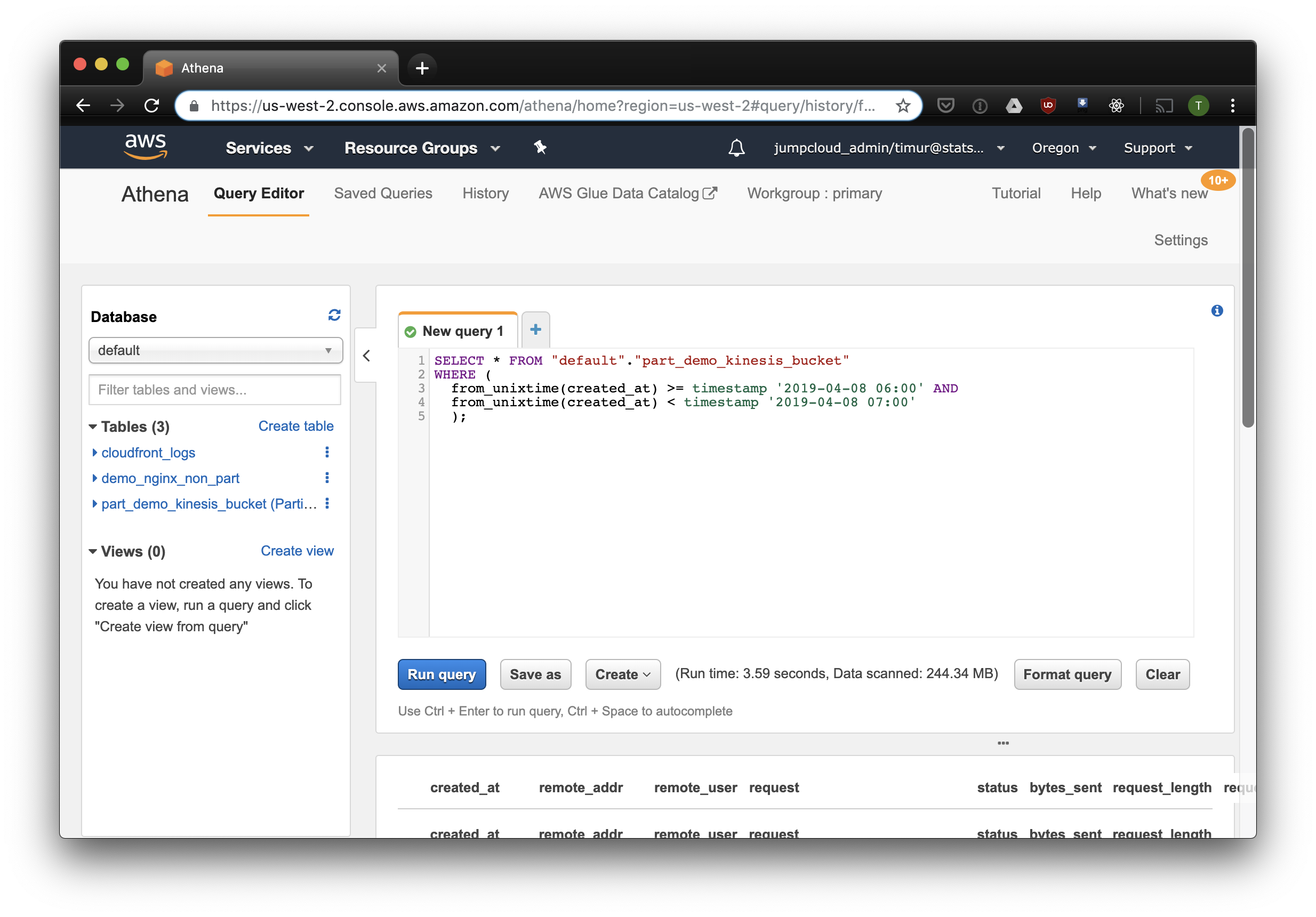
3,59 secondes et 244,34 mégaoctets de données sur l'ensemble de données, dans lequel il n'y a qu'une semaine de journaux. Essayons le filtre par partitions:
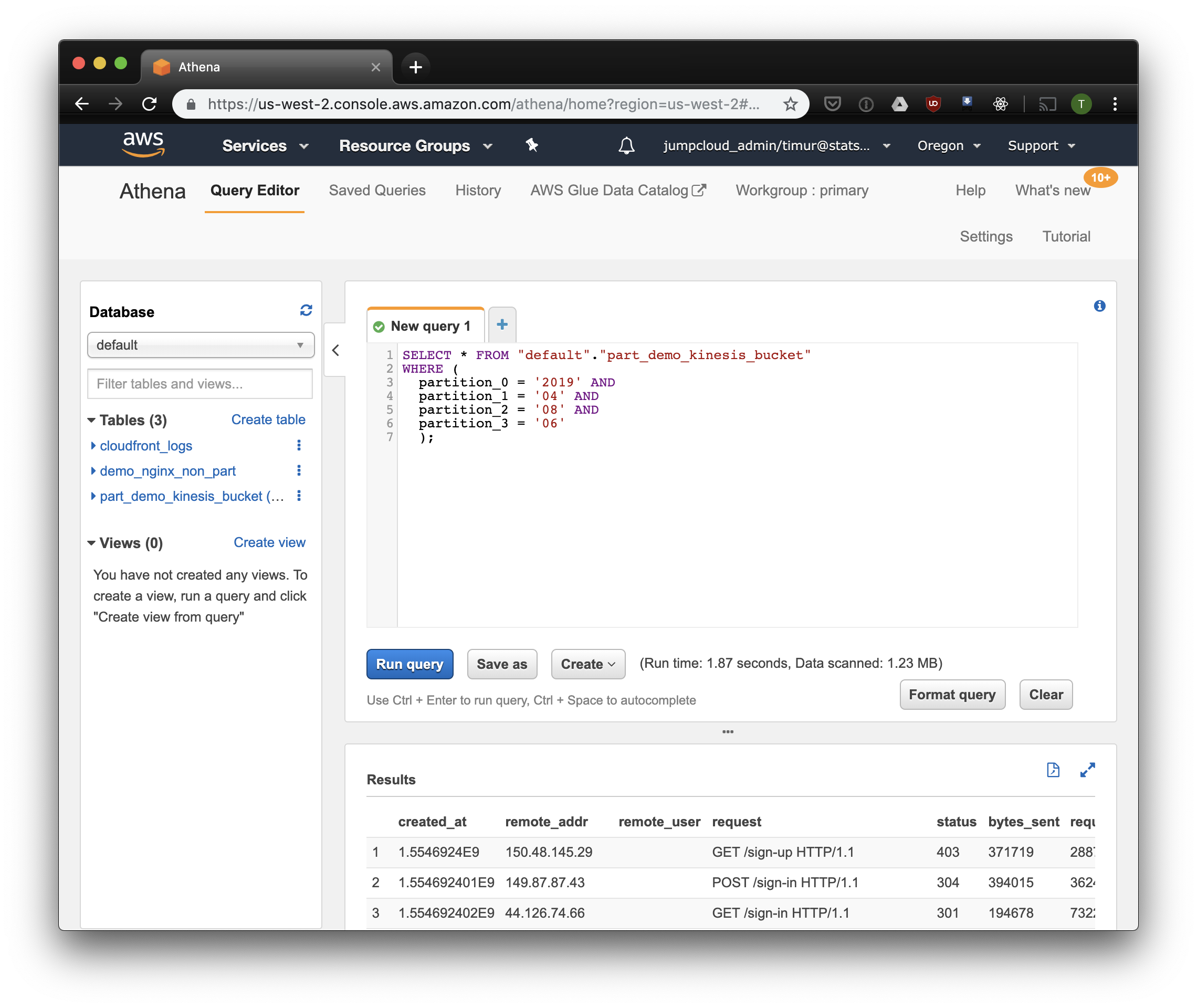
Un peu plus vite, mais surtout - seulement 1,23 mégaoctets de données! Ce serait beaucoup moins cher sans le minimum de 10 mégaoctets par demande de prix. Mais c'est bien mieux de toute façon, et sur de grands ensembles de données, la différence sera beaucoup plus impressionnante.
Créez un tableau de bord à l'aide de Cube.js
Pour créer un tableau de bord, nous utilisons le cadre analytique Cube.js. Il a plusieurs fonctions, mais nous nous intéressons à deux: la possibilité d'utiliser automatiquement des filtres sur les partitions et la pré-agrégation des données. Il utilise un schéma de données écrit en Javascript pour générer du SQL et exécuter une requête de base de données. Il nous suffit d'indiquer comment utiliser le filtre de partition dans le schéma de données.
Créons une nouvelle application Cube.js. Comme nous utilisons déjà AWS-stack, il est logique d'utiliser Lambda pour le déploiement. Vous pouvez utiliser le modèle express pour la génération si vous prévoyez d'héberger le backend Cube.js dans Heroku ou Docker. La documentation décrit d'autres méthodes d'hébergement .
$ npm install -g cubejs-cli $ cubejs create nginx-log-analytics -t serverless -d athena
Les variables d'environnement sont utilisées pour configurer l'accès à la base de données dans cube.js. Le générateur créera un fichier .env dans lequel vous pourrez spécifier vos clés pour Athena .
Nous avons maintenant besoin d' un schéma de données dans lequel nous indiquons comment nos journaux sont stockés. Vous pouvez y spécifier comment lire les métriques des tableaux de bord.
Dans le répertoire du schema , créez le fichier Logs.js Voici un exemple de modèle de données pour nginx:
Code modèle const partitionFilter = (from, to) => ` date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') ` cube(`Logs`, { sql: ` select * from part_demo_kinesis_bucket WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)} `, measures: { count: { type: `count`, }, errorCount: { type: `count`, filters: [ { sql: `${CUBE.isError} = 'Yes'` } ] }, errorRate: { type: `number`, sql: `100.0 * ${errorCount} / ${count}`, format: `percent` } }, dimensions: { status: { sql: `status`, type: `number` }, isError: { type: `string`, case: { when: [{ sql: `${CUBE}.status >= 400`, label: `Yes` }], else: { label: `No` } } }, createdAt: { sql: `from_unixtime(created_at)`, type: `time` } } });
Ici, nous utilisons la variable FILTER_PARAMS pour générer une requête SQL avec un filtre de partition.
Nous spécifions également les métriques et les paramètres que nous voulons afficher sur le tableau de bord et spécifions les pré-agrégations. Cube.js créera des tables supplémentaires avec des données pré-agrégées et mettra automatiquement à jour les données dès qu'elles seront disponibles. Cela accélère non seulement les demandes, mais réduit également le coût d'utilisation d'Athena.
Ajoutez ces informations au fichier de schéma de données:
preAggregations: { main: { type: `rollup`, measureReferences: [count, errorCount], dimensionReferences: [isError, status], timeDimensionReference: createdAt, granularity: `day`, partitionGranularity: `month`, refreshKey: { sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) => `select CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now() THEN date_trunc('hour', now()) END` ) } } }
Dans ce modèle, nous indiquons qu'il est nécessaire de pré-agréger les données pour toutes les métriques utilisées et d'utiliser un partitionnement mensuel. Le partitionnement des pré-agrégations peut accélérer considérablement la collecte et la mise à jour des données.
Nous pouvons maintenant créer un tableau de bord!
Le backend Cube.js fournit une API REST et un ensemble de bibliothèques client pour les frameworks frontaux populaires. Nous utiliserons la version React du client pour construire le tableau de bord. Cube.js ne fournit que des données, nous avons donc besoin d'une bibliothèque de visualisations - j'aime les recharges , mais vous pouvez en utiliser n'importe quelle.
Le serveur Cube.js accepte la demande au format JSON , qui indique les mesures nécessaires. Par exemple, pour calculer le nombre d'erreurs Nginx par jour, vous devez envoyer la demande suivante:
{ "measures": ["Logs.errorCount"], "timeDimensions": [ { "dimension": "Logs.createdAt", "dateRange": ["2019-01-01", "2019-01-07"], "granularity": "day" } ] }
Installez le client Cube.js et la bibliothèque de composants React via NPM:
$ npm i --save @cubejs-client/core @cubejs-client/react
Nous importons des composants cubejs et QueryRenderer pour décharger les données et collecter le tableau de bord:
Code du tableau de bord import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) }
Les sources du tableau de bord sont disponibles sur CodeSandbox .