Le mois dernier, lors de NVIDIA GTC 2019, NVIDIA a présenté une nouvelle application qui transforme des boules colorées simples dessinées par l'utilisateur en images superbes et photo-réalistes.
L'application est construite sur la technologie des
réseaux génératifs compétitifs (GAN), qui est basée sur l'apprentissage en profondeur. NVIDIA lui-même l'appelle GauGAN - un jeu de mots destiné à désigner l'artiste Paul Gauguin. La fonctionnalité GauGAN est basée sur le nouvel algorithme SPADE.
Dans cet article, je vais expliquer comment fonctionne ce chef-d'œuvre d'ingénierie. Et afin d'attirer autant de lecteurs intéressés que possible, je vais essayer de donner une description détaillée du fonctionnement des réseaux de neurones convolutifs. Étant donné que SPADE est un réseau génératif-compétitif, je vais vous en dire plus à leur sujet. Mais si vous connaissez déjà ce terme, vous pouvez immédiatement vous rendre dans la section «Diffusion image à image».
Génération d'images
Commençons par comprendre: dans la plupart des applications modernes d'apprentissage en profondeur, le type discriminant neural (discriminateur) est utilisé, et SPADE est un réseau neuronal génératif (générateur).
Discriminateurs
Le discriminateur classe les données d'entrée. Par exemple, un classificateur d'image est un discriminateur qui prend une image et sélectionne une étiquette de classe appropriée, par exemple, définit l'image comme «chien», «voiture» ou «feu de circulation», c'est-à-dire qu'il sélectionne une étiquette qui décrit l'image entière. La sortie obtenue par le classificateur est généralement présentée comme un vecteur de nombres
où
Est un nombre de 0 à 1, exprimant la confiance du réseau que l'image appartient à la sélection
classe.
Le discriminateur peut également compiler une liste de classifications. Il peut classer chaque pixel d'une image comme appartenant à la classe des «personnes» ou des «machines» (la soi-disant «segmentation sémantique»).
 Le classificateur prend une image à 3 canaux (rouge, vert et bleu) et la compare avec un vecteur de confiance dans chaque classe possible que l'image peut représenter.
Le classificateur prend une image à 3 canaux (rouge, vert et bleu) et la compare avec un vecteur de confiance dans chaque classe possible que l'image peut représenter.Étant donné que la connexion entre l'image et sa classe est très complexe, les réseaux de neurones la traversent à travers une pile de plusieurs couches, dont chacune la traite «légèrement» et transfère sa sortie au niveau d'interprétation suivant.
Générateurs
Un réseau génératif comme SPADE reçoit un ensemble de données et cherche à créer de nouvelles données originales qui semblent appartenir à cette classe de données. Dans le même temps, les données peuvent être n'importe quoi: sons, langue ou autre chose, mais nous nous concentrerons sur les images. En général, la saisie de données dans un tel réseau est simplement un vecteur de nombres aléatoires, chacun des ensembles possibles de données d'entrée créant sa propre image.
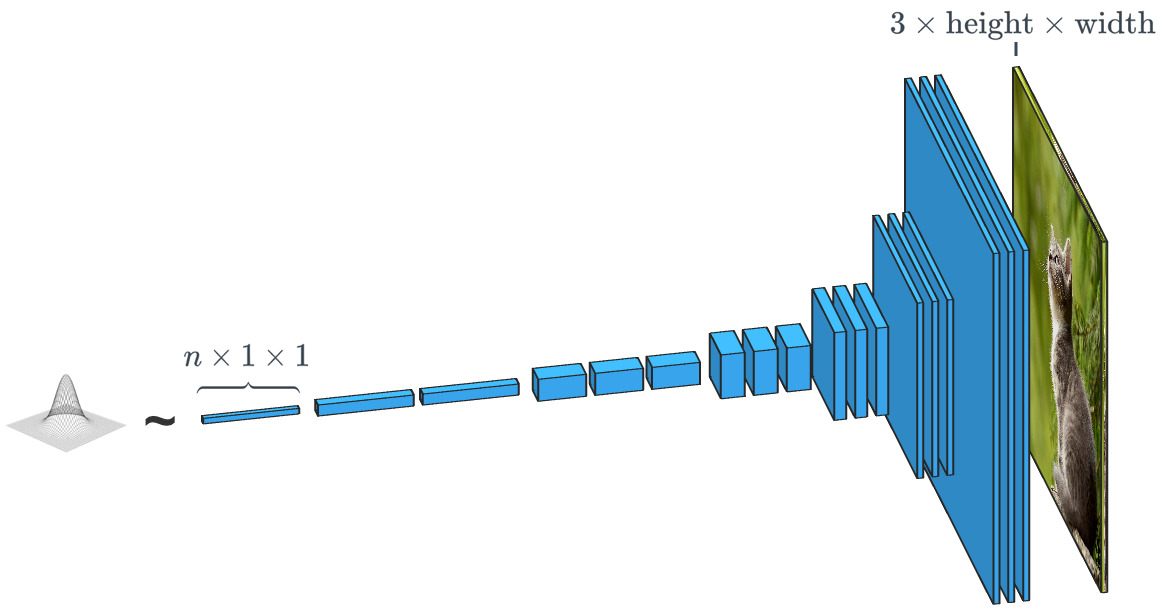 Un générateur basé sur un vecteur d'entrée aléatoire fonctionne pratiquement à l'opposé du classificateur d'images. Dans les générateurs de «classe conditionnelle», le vecteur d'entrée est, en fait, le vecteur d'une classe de données entière.
Un générateur basé sur un vecteur d'entrée aléatoire fonctionne pratiquement à l'opposé du classificateur d'images. Dans les générateurs de «classe conditionnelle», le vecteur d'entrée est, en fait, le vecteur d'une classe de données entière.Comme nous l'avons déjà vu, SPADE utilise bien plus qu'un simple «vecteur aléatoire». Le système est guidé par une sorte de dessin appelé «carte de segmentation». Ce dernier indique quoi et où poster. SPADE conduit le processus opposé à la segmentation sémantique que nous avons mentionnée ci-dessus. En général, une tâche discriminatoire qui convertit un type de données en un autre a une tâche similaire, mais elle prend un chemin différent et inhabituel.
Les générateurs et discriminateurs modernes utilisent généralement des réseaux convolutionnels pour traiter leurs données. Pour une introduction plus complète aux réseaux de neurones convolutifs (CNN), voir le post
Chew on Karna ou le
travail d'Andrei Karpati .
Il existe une différence importante entre le classificateur et le générateur d'images, et elle réside dans la façon dont ils modifient exactement la taille de l'image pendant son traitement. Le classificateur d'image doit la réduire jusqu'à ce que l'image perde toutes les informations spatiales et qu'il ne reste que les classes. Ceci peut être réalisé en combinant des couches ou en utilisant des réseaux convolutionnels à travers lesquels des pixels individuels sont passés. Le générateur, d'autre part, crée une image en utilisant le processus inverse de «convolution», qui est appelé transposition convolutionnelle. Il est souvent confondu avec «déconvolution» ou
«convolution inverse» .
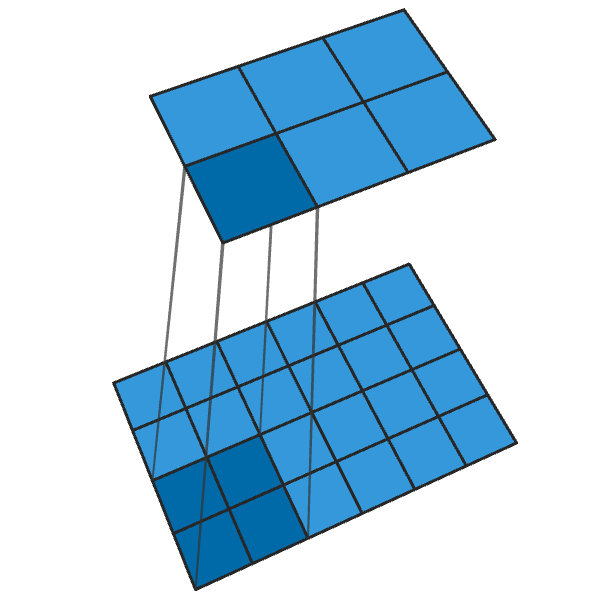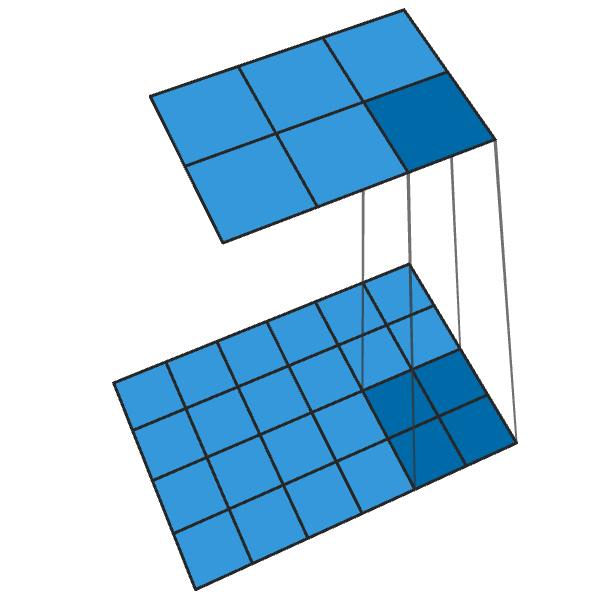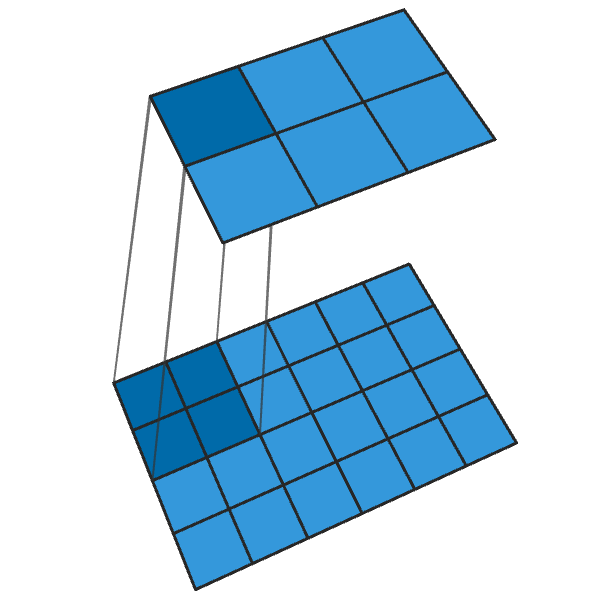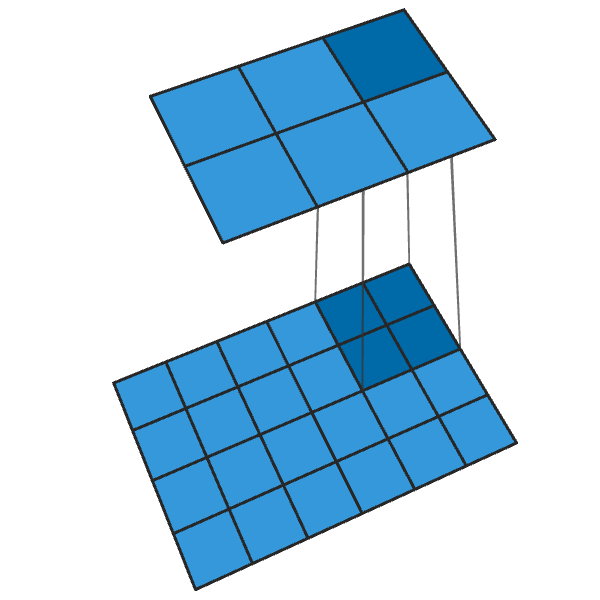
La convolution 2x2 conventionnelle avec un pas de «2» transforme chaque bloc 2x2 en un point, réduisant la taille de sortie de 1/2.

Une convolution 2x2 transposée avec un pas de «2» génère un bloc 2x2 à partir de chaque point, augmentant la taille de sortie de 2 fois.
Formation de générateur
Théoriquement, un réseau neuronal convolutionnel peut générer des images comme décrit ci-dessus. Mais comment la former? Autrement dit, si nous prenons en compte l'ensemble des données d'image d'entrée, comment pouvons-nous ajuster les paramètres du générateur (dans notre cas, SPADE) afin qu'il crée de nouvelles images qui semblent correspondre à l'ensemble de données proposé?
Pour ce faire, vous devez comparer avec les classificateurs d'images, où chacun d'eux a l'étiquette de classe correcte. Connaissant le vecteur de prédiction du réseau et la classe correcte, nous pouvons utiliser l'algorithme de rétropropagation pour déterminer les paramètres de mise à jour du réseau. Cela est nécessaire pour augmenter sa précision dans la détermination de la classe souhaitée et réduire l'influence des autres classes.
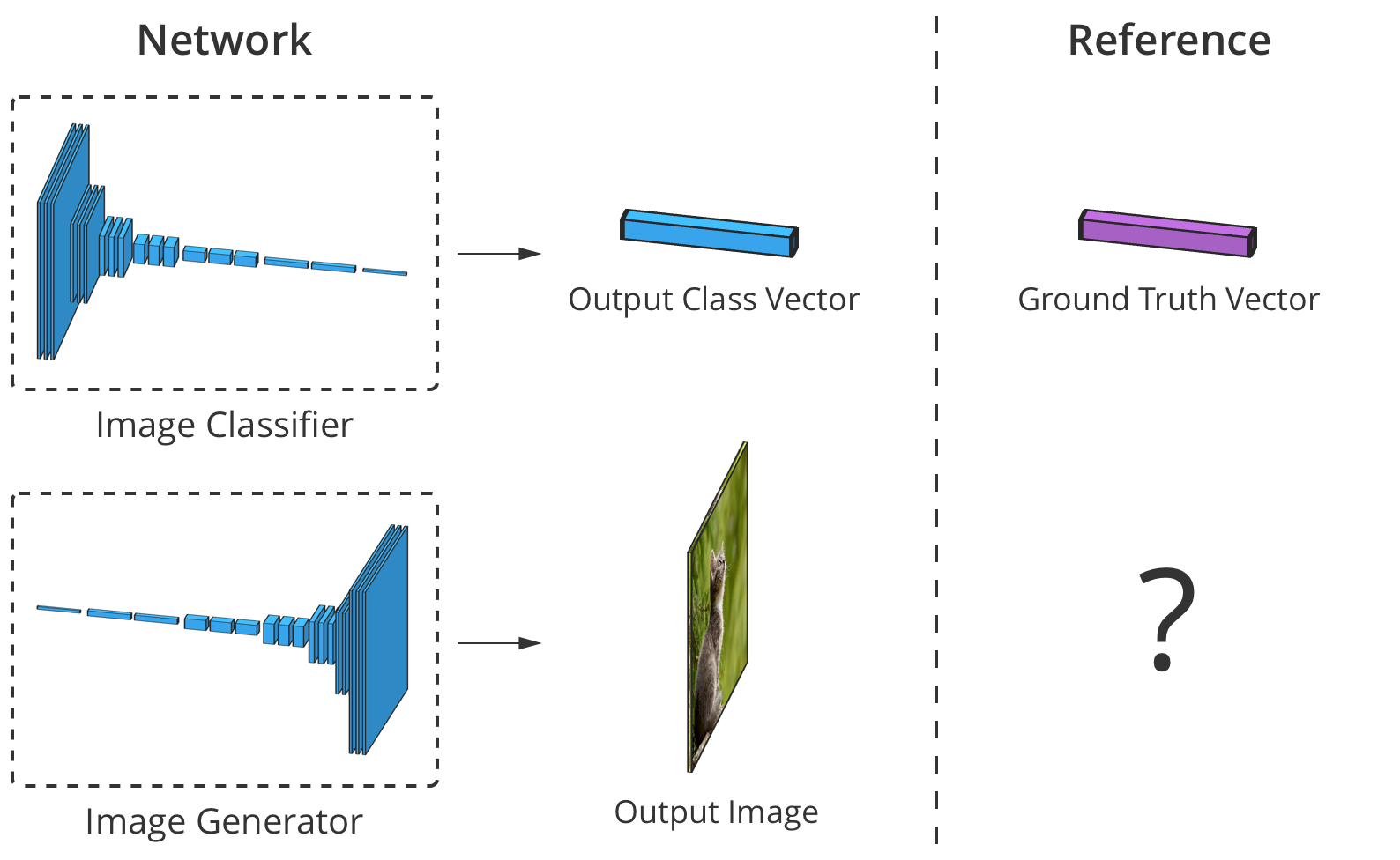 La précision du classificateur d'image peut être estimée en comparant son élément de sortie par élément avec le vecteur de classe correct. Mais pour les générateurs, il n'y a pas d'image de sortie «correcte».
La précision du classificateur d'image peut être estimée en comparant son élément de sortie par élément avec le vecteur de classe correct. Mais pour les générateurs, il n'y a pas d'image de sortie «correcte».Le problème est que lorsque le générateur crée une image, il n'y a pas de valeurs «correctes» pour chaque pixel (on ne peut pas comparer le résultat, comme dans le cas d'un classifieur basé sur une base préalablement préparée, environ Trans.). Théoriquement, toute image qui semble crédible et similaire aux données cibles est valide, même si ses valeurs de pixels sont très différentes des images réelles.
Alors, comment pouvons-nous dire au générateur dans quels pixels il doit changer sa sortie et comment il peut créer des images plus réalistes (c'est-à-dire comment donner un «signal d'erreur»)? Les chercheurs ont beaucoup réfléchi à cette question, et en fait, c'est assez difficile. La plupart des idées, telles que le calcul d'une certaine «distance» moyenne à des images réelles, produisent des images floues et de mauvaise qualité.
Idéalement, nous pourrions «mesurer» à quel point les images générées sont réalistes en utilisant un concept de «haut niveau», tel que «Est-il difficile de distinguer cette image de la vraie?» ...
Réseaux contradictoires génératifs
C'est exactement ce qui a été mis en œuvre dans le cadre de
Goodfellow et al., 2014 . L'idée est de générer des images en utilisant deux réseaux de neurones au lieu d'un: un réseau -
générateur, le second est un classificateur d'images (discriminateur). La tâche du discriminateur est de distinguer les images de sortie du générateur des images réelles de l'ensemble de données primaires (les classes de ces images sont désignées comme «fausses» et «réelles»). Le travail du générateur consiste à tromper le discriminateur en créant des images aussi similaires que possible aux images de l'ensemble de données. On peut dire que le générateur et le discriminateur sont des opposants dans ce processus. D'où le nom:
réseau génératif-contradictoire .
Comment cela nous aide-t-il? Nous pouvons maintenant utiliser un message d'erreur basé uniquement sur la prédiction du discriminateur: une valeur de 0 ("faux") à 1 ("réel"). Le discriminateur étant un réseau neuronal, nous pouvons partager ses conclusions sur les erreurs avec le générateur d'images. Autrement dit, le discriminateur peut dire au générateur où et comment il doit ajuster ses images afin de mieux «tromper» le discriminateur (c'est-à-dire, comment augmenter le réalisme de ses images).
En train d'apprendre à trouver de fausses images, le discriminateur donne au générateur de meilleurs retours sur la façon dont ce dernier peut améliorer son travail. Ainsi, le discriminateur effectue une fonction
"apprendre une perte" pour le générateur.
Glorious Small GAN
Le GAN que nous considérons dans ses travaux suit la logique décrite ci-dessus. Son discriminateur
analyse l'image
et obtient la valeur
de 0 à 1, ce qui reflète son degré de confiance que l'image est réelle ou truquée par le générateur. Son générateur
obtient un vecteur aléatoire de nombres normalement distribués
et affiche l'image
qui peut être trompé par le discriminateur (en fait, cette image
)
L'un des problèmes que nous n'avons pas abordés est de savoir comment former le GAN et quelle
fonction de perte les développeurs utilisent pour mesurer les performances du réseau. En général, la fonction de perte devrait augmenter à mesure que le discriminateur est entraîné et diminuer à mesure que le générateur est entraîné. La fonction de perte du GAN source utilise les deux paramètres suivants. Le premier est
représente le degré auquel le discriminateur classe correctement les images réelles comme réelles. La seconde est la capacité du discriminateur à détecter les fausses images:
$ inline $ \ begin {equation *} \ mathcal {L} _ \ text {GAN} (D, G) = \ underbrace {E _ {\ vec {x} \ sim p_ \ text {data}} [\ log D ( \ vec {x})]} _ {\ text {précision sur des images réelles}} + \ underbrace {E _ {\ vec {z} \ sim \ mathcal {N}} [\ log (1 - D (G (\ vec {z}))]} _ {\ text {précision sur les contrefaçons}} \ end {équation *} $ inline $
Discriminateur
tire son affirmation que l'image est réelle. Cela a du sens puisque
augmente lorsque le discriminateur considère x réel. Lorsque le discriminateur détecte mieux les fausses images, la valeur de l'expression augmente également.
(commence à viser 1), car
tendra vers 0.
En pratique, nous évaluons la précision à l'aide de lots d'images entiers. Nous prenons beaucoup (mais en aucun cas tous) d'images réelles
et de nombreux vecteurs aléatoires
pour obtenir les moyennes selon la formule ci-dessus. Ensuite, nous sélectionnons les erreurs courantes et un ensemble de données.
Au fil du temps, cela conduit à des résultats intéressants:
 Goodfellow GAN simulant des ensembles de données MNIST, TFD et CIFAR-10. Les images de contour sont les plus proches dans l'ensemble de données des contrefaçons adjacentes.
Goodfellow GAN simulant des ensembles de données MNIST, TFD et CIFAR-10. Les images de contour sont les plus proches dans l'ensemble de données des contrefaçons adjacentes.Tout cela était fantastique il y a seulement 4,5 ans. Heureusement, comme SPADE et d'autres réseaux le montrent, l'apprentissage automatique continue de progresser rapidement.
Problèmes de formation
Les réseaux génératifs-compétitifs sont connus pour leur complexité dans la préparation et l'instabilité du travail. L'un des problèmes est que si le générateur est trop en avance sur le discriminateur dans le rythme d'entraînement, alors sa sélection d'images est réduite à celles qui l'aident à tromper le discriminateur. En fait, en conséquence, la formation du générateur revient à créer une image unique et universelle pour tromper le discriminateur. Ce problème est appelé le «mode d'effondrement».

Le mode d'effondrement GAN est similaire à celui de Goodfellow. Veuillez noter que beaucoup de ces images de chambre à coucher se ressemblent beaucoup.
SourceUn autre problème est que lorsque le générateur trompe efficacement le discriminateur
, il fonctionne avec un très faible gradient, donc
ne peut pas obtenir suffisamment de données pour trouver la vraie réponse, dans laquelle cette image serait plus réaliste.
Les efforts des chercheurs pour résoudre ces problèmes visaient principalement à modifier la structure de la fonction de perte. L'un des changements simples proposés par
Xudong Mao et al., 2016 est le remplacement de la fonction de perte
pour quelques fonctions simples
, qui sont basés sur des carrés de plus petite surface. Cela conduit à la stabilisation du processus de formation, à l'obtention de meilleures images et à moins de risques d'effondrement en utilisant des dégradés non amortis.
Un autre problème rencontré par les chercheurs est la difficulté d'obtenir des images haute résolution, en partie parce qu'une image plus détaillée donne au discriminateur plus d'informations pour détecter de fausses images. Les GAN modernes commencent à former le réseau avec des images à basse résolution et à ajouter progressivement de plus en plus de couches jusqu'à ce que la taille d'image souhaitée soit atteinte.
 L'ajout progressif de couches avec une résolution plus élevée pendant la formation GAN augmente considérablement la stabilité de l'ensemble du processus, ainsi que la vitesse et la qualité de l'image résultante.
L'ajout progressif de couches avec une résolution plus élevée pendant la formation GAN augmente considérablement la stabilité de l'ensemble du processus, ainsi que la vitesse et la qualité de l'image résultante.Diffusion image à image
Jusqu'à présent, nous avons expliqué comment générer des images à partir d'ensembles aléatoires de données d'entrée. Mais SPADE n'utilise pas seulement des données aléatoires. Ce réseau utilise une image appelée carte de segmentation: il attribue une classe de matériau à chaque pixel (par exemple, herbe, bois, eau, pierre, ciel). À partir de cette image, la carte est SPADE et génère ce qui ressemble à une photo. C'est ce qu'on appelle la «diffusion d'image à image».
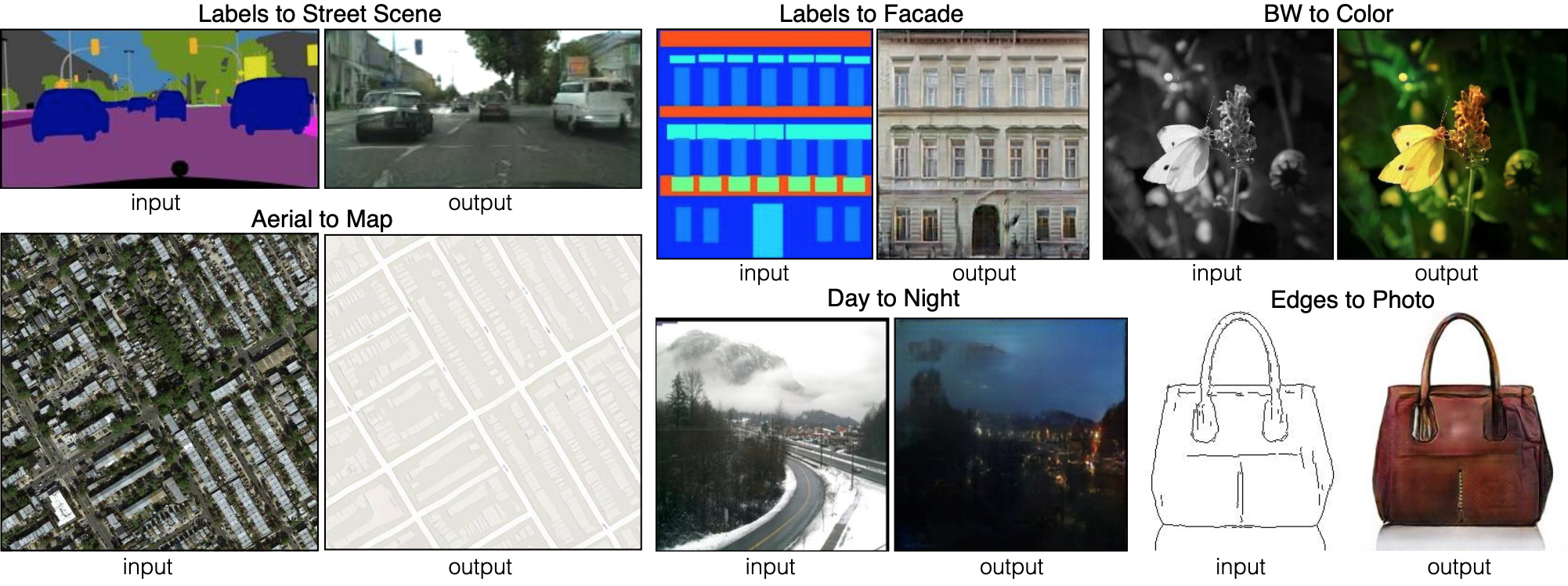 Pix2pix propose six types différents de diffusions d'image à image. Pix2pix est le prédécesseur des deux réseaux, dont nous parlerons plus loin: pix2pixHD et SPADE.
Pix2pix propose six types différents de diffusions d'image à image. Pix2pix est le prédécesseur des deux réseaux, dont nous parlerons plus loin: pix2pixHD et SPADE.Pour que le générateur apprenne cette approche, il a besoin d'un ensemble de cartes de segmentation et de photos correspondantes. Nous modifions l'architecture GAN pour que le générateur et le discriminateur reçoivent une carte de segmentation. Le générateur, bien sûr, a besoin d'une carte pour savoir "de quelle manière dessiner". Le discriminateur en a également besoin pour s'assurer que le générateur place les bonnes choses aux bons endroits.
Pendant la formation, le générateur apprend à ne pas mettre de l'herbe là où «ciel» est indiqué sur la carte de segmentation, car sinon le discriminateur peut facilement détecter une fausse image, etc.
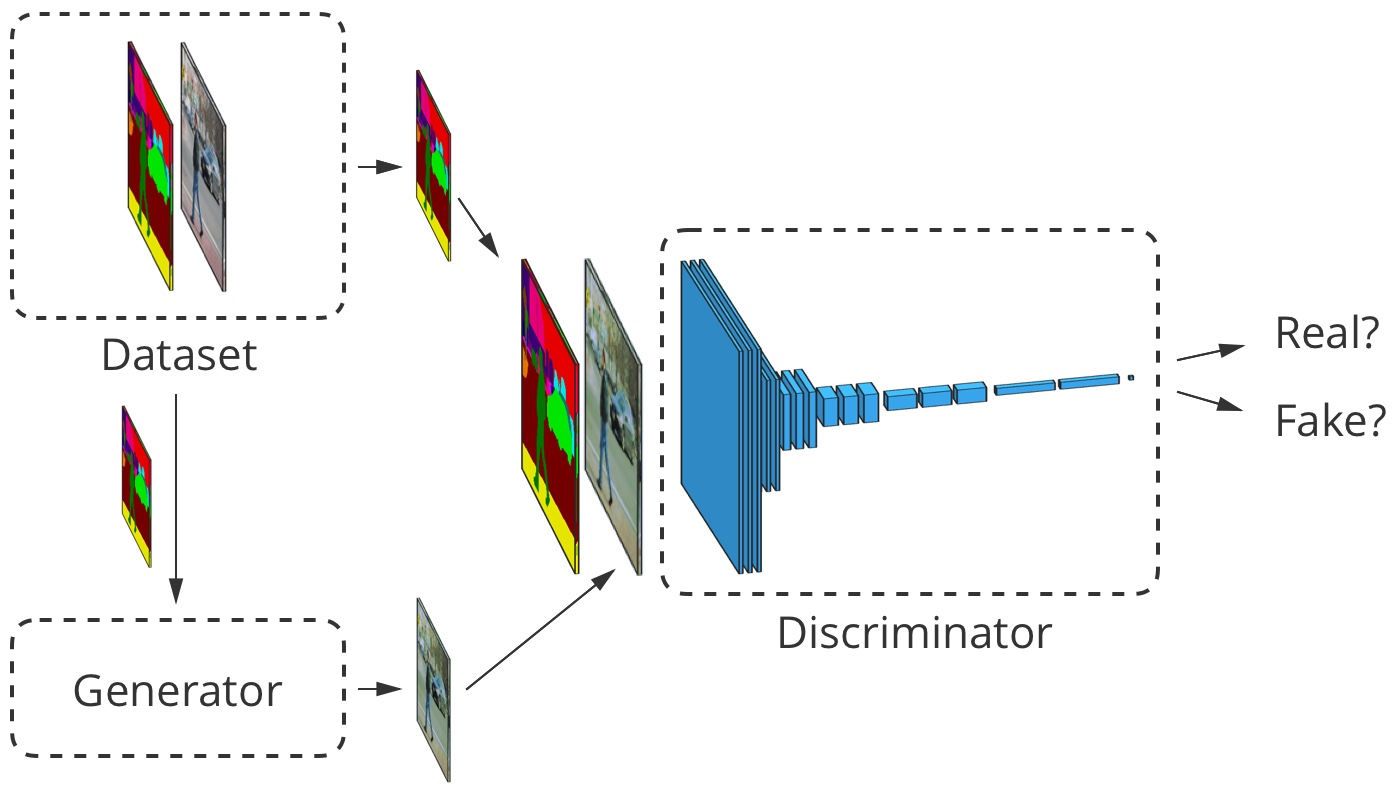 Pour la traduction d'image à image, l'image d'entrée est acceptée à la fois par le générateur et le discriminateur. Le discriminateur reçoit en outre soit la sortie du générateur, soit la sortie réelle de l'ensemble de données d'apprentissage. Exemple
Pour la traduction d'image à image, l'image d'entrée est acceptée à la fois par le générateur et le discriminateur. Le discriminateur reçoit en outre soit la sortie du générateur, soit la sortie réelle de l'ensemble de données d'apprentissage. ExempleDéveloppement d'un traducteur image-à-image
Regardons un vrai traducteur image-à-image:
pix2pixHD . Soit dit en passant, SPADE est conçu pour l'essentiel à l'image et à la ressemblance de pix2pixHD.
Pour un traducteur image-image, notre générateur crée une image et l'accepte comme entrée. Nous pourrions simplement utiliser une carte de couches convolutionnelles, mais comme les couches convolutionnelles combinent des valeurs uniquement dans de petites zones, nous avons besoin de trop de couches pour transmettre des informations d'image haute résolution.
pix2pixHD résout ce problème plus efficacement à l'aide de l '"Encodeur", qui réduit l'échelle de l'image d'entrée, suivi du "Décodeur", qui augmente l'échelle pour obtenir l'image de sortie. Comme nous le verrons bientôt, SPADE a une solution plus élégante qui ne nécessite pas d'encodeur.
 Diagramme de réseau Pix2pixHD à un niveau "élevé". Les blocs «résiduels» et «opération +» font référence à la technologie «sauter les connexions» du réseau neuronal résiduel . Il existe des blocs de saut dans le réseau, qui sont interconnectés dans l'encodeur et le décodeur.
Diagramme de réseau Pix2pixHD à un niveau "élevé". Les blocs «résiduels» et «opération +» font référence à la technologie «sauter les connexions» du réseau neuronal résiduel . Il existe des blocs de saut dans le réseau, qui sont interconnectés dans l'encodeur et le décodeur.La normalisation des lots est un problème
Presque tous les réseaux de neurones convolutifs modernes utilisent la normalisation par lots ou l'un de ses analogues pour accélérer et stabiliser le processus de formation. L'activation de chaque canal fait passer la moyenne à 0 et l'écart type à 1 avant une paire de paramètres de canal
et
laissez-les se dénormaliser à nouveau.
Malheureusement, la normalisation par lots nuit aux générateurs, ce qui rend difficile pour le réseau de mettre en œuvre certains types de traitement d'image. Au lieu de normaliser un lot d'images, pix2pixHD utilise un
standard de normalisation , qui normalise chaque image individuellement.
Formation Pix2pixHD
Les GAN modernes, tels que pix2pixHD et SPADE, mesurent le réalisme de leurs images de sortie un peu différemment de ce qui a été décrit pour la conception originale des réseaux générateurs de conflits.
Pour résoudre le problème de la génération d'images haute résolution, pix2pixHD utilise trois discriminateurs de même structure, chacun recevant l'image de sortie à une échelle différente (taille normale, réduite de 2 fois et réduite de 4 fois).
Pix2pixHD utilise
, et inclut également un autre élément conçu pour rendre les conclusions du générateur plus réalistes (que cela contribue à tromper le discriminateur). Cet article
appelé «mise en correspondance des fonctionnalités» - il encourage le générateur à rendre la distribution des couches identique lors de la simulation de la discrimination entre les données réelles et les sorties du générateur, en minimisant
entre eux.
Ainsi, l'optimisation se résume à ce qui suit:
$$ afficher $$ \ commencer {équation *} \ min_G \ bigg (\ lambda \ sum_ {k = 1,2,3} V_ \ text {LSGAN} (G, D_k) + \ big (\ max_ {D_1, D_2 , D_3} \ sum_ {k = 1,2,3} \ mathcal {L} _ \ text {FM} (G, D_k) \ big) \ bigg) \ end {equation *}, $$ display $$
où les pertes sont résumées par trois facteurs et coefficient discriminatoires
, qui contrôle la priorité des deux éléments.
 pix2pixHD utilise une carte de segmentation composée d'une vraie chambre (à gauche dans chaque exemple) pour créer une fausse chambre (à droite).
pix2pixHD utilise une carte de segmentation composée d'une vraie chambre (à gauche dans chaque exemple) pour créer une fausse chambre (à droite).Bien que les discriminateurs réduisent l'échelle de l'image jusqu'à ce qu'ils démontent l'image entière, ils s'arrêtent à des «points» de taille 70 × 70 (aux échelles appropriées). Ensuite, ils résument simplement toutes les valeurs de ces «taches» pour l'image entière.
Et cette approche fonctionne bien, car la fonction
, ,
. , .
 pix2pixHD . CelebA , .
pix2pixHD . CelebA , .pix2pixHD?
, . , pix2pixHD .
, pix2pixHD , , , . , . «» ()
. β- , : , «», «», «» - .
pix2pixHD . , , .— SPADE.
: SPADE
- : - () (SPADE).
SPADE , , γ, β, , . , 2 .
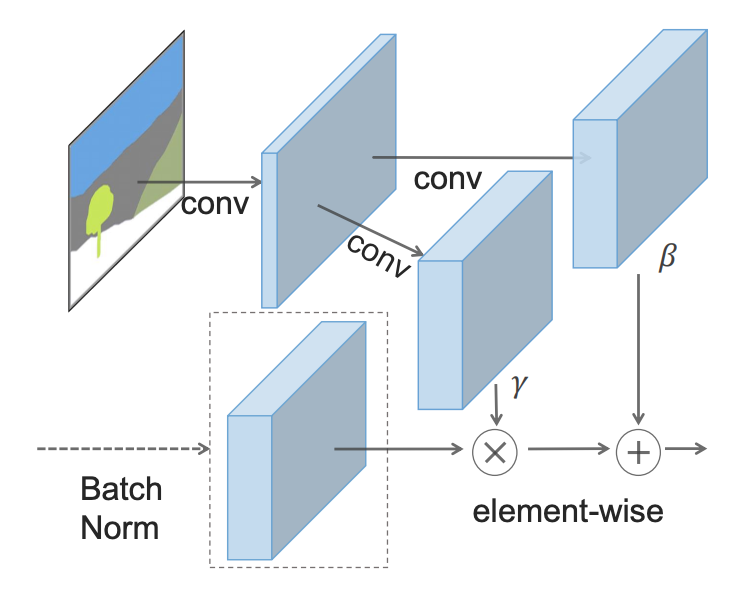 , SPADE .
, SPADE .SPADE « », ( ):
 SPADE pix2pixHD
SPADE pix2pixHD, «» , . GAN, . (« »). «» pix2pixHD, .
SPADE , pix2pixHD, :
hinge loss .
:
 SPADE pix2pixHD
SPADE pix2pixHD, SPADE . . GauGAN «» , . , - SPADE , «» , .
, SPADE , «» .
, , «». SPADE , , ? 55, «».
, , 5x5 . , .
SPADE , , , , pix2pixHD. , .
SPADE — (, , , ).
 SPADE , .
SPADE , .: ,
, . , , SPADE , , .
, . , ,
.
C'est ainsi que SPADE / GaiGAN fonctionne. J'espère que cet article a satisfait votre curiosité sur le fonctionnement du nouveau système NVIDIA. Vous pouvez me contacter via Twitter @AdamDanielKin ou par e-mail adam@AdamDKing.com.