Il n'y a pas si longtemps, je suis tombé sur une tâche assez simple et en même temps intéressante: implémenter un terminal en lecture seule dans une application Web. L'intérêt pour la tâche a été donné par trois aspects importants:
- prise en charge des séquences d'échappement ANSI de base
- prise en charge d'au moins 50 000 lignes de données
- afficher les données dès qu'elles deviennent disponibles.
Dans cet article, je parlerai de la façon dont il a été mis en œuvre et comment il a ensuite optimisé le tout.
Avertissement: Je ne suis pas un développeur Web expérimenté, donc certaines choses peuvent vous sembler évidentes et les conclusions ou décisions sont erronées. Pour les corrections et clarifications, je vous en serai reconnaissant.
Pourquoi était-ce
Toute la tâche est la suivante: un script s'exécute sur le serveur (bash, python, etc.) et écrit quelque chose sur stdout. Et cette conclusion doit être affichée sur la page Web à mesure qu'elle arrive. En même temps, il devrait ressembler au terminal (avec formatage, transferts de curseur, etc.)
Je ne contrôle en aucune façon le script lui-même et sa sortie et je ne l'affiche pas sous une forme pure.
Bien sûr, entre l'interface Web et le script, il devrait y avoir un intermédiaire - un serveur Web. Et si ce n'est pas pour dissimuler - j'ai déjà une application web et un serveur, et je travaille en quelque sorte. Le schéma ressemble à ceci:

Mais auparavant, le serveur était responsable du traitement et du formatage. Et je voulais l'améliorer pour un grand nombre de raisons:
- double traitement des données - première analyse sur le serveur, puis transformation en composants html sur le client
- algorithme non optimal dû à la préparation des données pour le client
- forte charge sur le serveur - le traitement de la sortie d'un seul script peut charger complètement un seul thread sur le serveur
- prise en charge incomplète des séquences d'échappement ANSI
- bogues subtils
- le client a très mal réussi à afficher même des lignes au format 10k
Par conséquent, il a été décidé de transférer l'intégralité de la logique d'analyse à l'application Web et de ne laisser que le streaming des données brutes au serveur
Énoncé du problème
Des parties du texte parviennent au client. Le client doit les analyser en composants: texte brut, saut de ligne, retour chariot et commandes ANSI spéciales. Il n'y a aucune garantie quant à l'intégrité des pièces - une commande ou un mot peut provenir de différents packages.
Les commandes ANSI peuvent affecter le format du texte (couleur, arrière-plan, style), la position du curseur (d'où le texte suivant doit être affiché) ou pour effacer une partie de l'écran.
Un exemple de ce à quoi il ressemble:

De plus, il peut y avoir des URL dans le texte qui doivent également être reconnues et mises en évidence.
Nous prenons la bibliothèque terminée et ...
J'ai compris que le traitement correct et rapide de toutes les commandes n'est pas une tâche facile. J'ai donc décidé de chercher une bibliothèque toute faite. Et voilà , je suis immédiatement tombé sur xterm.js . Un composant prêt à l'emploi du terminal, qui est déjà utilisé dans de nombreux endroits et, en plus, "est vraiment rapide, il inclut même un moteur de rendu accéléré par GPU" . Ce dernier était le plus important pour moi, car Je voulais enfin avoir un client très rapide.
Malgré le fait que j'aime écrire mes propres vélos, j'étais extrêmement heureux de pouvoir non seulement gagner du temps, mais également obtenir un tas de fonctionnalités utiles gratuitement.
Il m'a fallu 14 heures pour essayer de connecter le terminal et je n'ai pas pu y faire face. Absolument.
Différentes hauteurs de ligne, sélection tordue, taille adaptative du terminal, une API très étrange, manque de documentation saine ...
Mais j'avais encore un peu d'inspiration et je pensais pouvoir faire face à ces problèmes.
Jusqu'à ce que j'alimente mes 10 000 lignes de test au terminal ... Il est mort. Et enterré avec moi les restes de mes espoirs.
Description de l'algorithme final
Tout d'abord, j'ai copié l'algorithme actuel implémenté en python et l'ai adapté pour javascript (en supprimant simplement les accolades et un autre pour la syntaxe).
Je connaissais tous les principaux avantages et inconvénients de l'ancien algorithme, donc je n'avais qu'à améliorer les endroits inefficaces.
Après délibération, essais et erreurs, j'ai opté pour l'option suivante: on divise l'algorithme en 2 composantes:
- modèle pour analyser le texte et stocker l'état actuel du "terminal"
- mappage qui traduit le modèle en HTML
Modèle (structure et algorithme)
- Toutes les lignes sont stockées dans un tableau (numéro de ligne = index dans le tableau)
- Les styles de texte sont stockés dans un tableau séparé.
- La position actuelle du curseur est stockée et peut être modifiée par des commandes
- L'algorithme lui-même vérifie les données d'entrée caractère par caractère:
- Si ce n'est que du texte, ajoutez à la ligne actuelle
- En cas de saut de ligne, augmentez l'index de ligne en cours
- S'il s'agit d'un des caractères de commande, nous le mettons dans le tampon de commande et attendons le caractère suivant
- Si le tampon de commande est correct, exécutez cette commande, sinon nous écrivons ce tampon sous forme de texte
- Le modèle informe les auditeurs des lignes qui ont changé après le traitement du texte entrant
Dans mon implémentation, la complexité de l'algorithme est O ( n log n ), où log n est la préparation des lignes modifiées pour la notification (unicité et tri). Au moment d'écrire ces lignes, j'ai réalisé que pour un cas particulier, vous pouvez vous débarrasser de log n , car les lignes sont le plus souvent ajoutées à la fin.
Affichage
- Affiche le texte sous forme d'éléments HTML
- Si la chaîne a changé, remplace complètement tous les éléments de la chaîne
- Coupe chaque ligne en fonction des styles: chaque segment stylisé a son propre élément
Avec une telle structure, le test est une tâche assez simple - nous transférons le texte vers le modèle (dans un seul package ou en parties) et vérifions simplement l'état actuel de toutes les lignes et styles qu'il contient. Et pour n'afficher que quelques tests, car il redessine toujours les lignes modifiées.
Un avantage important est également une certaine paresse de l'affichage. Si, dans un morceau de texte, nous remplaçons la même ligne (par exemple, la barre de progression), après que le modèle fonctionne, pour l'affichage, il ressemblera à une ligne modifiée.
DOM vs Canvas
Je voudrais insister un peu sur la raison pour laquelle j'ai choisi le DOM, bien que l'objectif soit la performance. La réponse est simple - la paresse. Pour moi, le rendu de tout dans Canvas par moi-même semble être une tâche assez intimidante. Tout en conservant la convivialité: mise en évidence, copie, redimensionnement de l'écran, apparence soignée, etc. L'exemple xterm.js m'a clairement montré que ce n'est pas facile du tout. Leur rendu sur toile était loin d'être idéal.
De plus, le débogage de l'arborescence DOM dans le navigateur et la possibilité de couvrir les tests unitaires est un avantage important.
Au final, mon objectif était de 50k lignes, et je savais que le DOM devait y faire face, basé sur le travail de l'ancien algorithme.
Optimisations
L'algorithme était prêt, débogué et fonctionnait lentement mais sûrement. Il était temps d'ouvrir le profileur et d'optimiser. Pour l'avenir, je dirai que la plupart des optimisations ont été une surprise pour moi (comme cela arrive généralement).
Le profilage a été effectué sur 10 000 lignes, chacune contenant des éléments stylisés. Le nombre total d'éléments DOM est d'environ 100k.
Aucune approche et aucun outil spécial n'ont été utilisés. Seulement Chrome Dev Tools et quelques lancements pour chaque mesure. En pratique, lors des lancements, seules les valeurs absolues des mesures (combien de secondes à compléter) différaient, mais pas le rapport en pourcentage entre les méthodes. Par conséquent, je considère que cette technique est conditionnellement suffisante.
Ci-dessous, je voudrais m'attarder plus en détail sur les améliorations les plus intéressantes. Et pour commencer, un graphique de ce qui était:

Tous les graphiques de profilage ont été créés après la mise en œuvre, en désoptimisant le code de la mémoire.
string.trim
Tout d'abord, je suis tombé sur un string.trim incompréhensible qui consommait une quantité très importante de CPU (il me semble que c'était environ 10-20%)

trim () est la fonction de base du langage. Pourquoi utilise-t-il une sorte de bibliothèque? Et même s'il s'agit d'une sorte de polyfill, pourquoi a-t-il activé la dernière version de Chrome?
Un peu sur Google et la réponse se trouve: https://babeljs.io/docs/en/babel-preset-env . Par défaut, il active le polyfill pour un nombre assez important de navigateurs, et le fait au stade de la compilation. La solution pour moi était de spécifier des 'targets': '> 0.25%, not dead'
Mais à la fin, j'ai supprimé complètement l'appel de trim, car inutile.
Vue.js
L'année dernière, j'ai transféré le composant terminal vers Vue.js. Maintenant, je devais le transférer à vanilla, la raison est dans la capture d'écran ci-dessous (voir le nombre de lignes impliquant Vue.js):
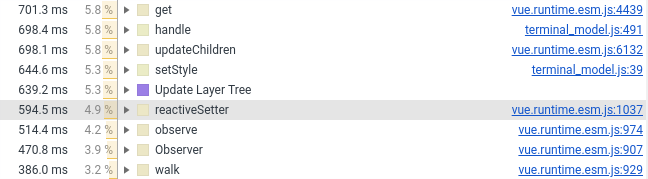
Je n'ai laissé que le wrapper, les styles et le traitement de la souris dans le composant Vue. Tout ce qui concerne la création d'éléments DOM est entré dans JS pur, qui est connecté au composant Vue comme un champ normal (qui n'est pas surveillé par le framework).
created() { this.terminalModel = new TerminalModel(); this.terminal = new Terminal(this.terminalModel); },
Je ne considère pas cela comme un inconvénient ou un défaut dans Vue.js. C'est juste que les frameworks et les performances eux-mêmes ne se mélangent pas bien. Eh bien, lorsque vous déposez des dizaines et des centaines de milliers d'objets dans un cadre réactif, il est très difficile de s'attendre à un traitement de celui-ci en quelques millisecondes. Et pour être honnête, je suis même surpris que Vue.js se soit plutôt bien débrouillé.
Ajout de nouveaux éléments
Tout est simple ici - si vous avez plusieurs milliers de nouveaux éléments et que vous souhaitez les ajouter au composant parent, faire appendChild n'est pas une bonne idée. Le navigateur doit effectuer le traitement un peu plus souvent et consacrer plus de temps au rendu. L'un des effets secondaires de mon cas a été un ralentissement du défilement automatique, il force un recomptage de tous les composants ajoutés.

Pour résoudre le problème, il existe un DocumentFragment. Tout d'abord, nous y ajoutons tous les éléments, puis nous l'ajoutons au composant parent. Le navigateur s'occupera de l'inline des composants entrants.
Cette approche réduit le temps que le navigateur passe à rendre et à organiser les éléments.
J'ai également essayé d'autres façons d'accélérer l'ajout d'éléments. Aucun d'entre eux n'a pu ajouter quoi que ce soit au-dessus du DocumentFragment.
span vs div
En fait, cela pourrait être appelé display:inline (span) vs display:block (div).
Au départ, j'avais toutes les lignes de l'intervalle et je me suis terminé avec un caractère de saut de ligne. Cependant, en termes de performances, ce n'est pas très efficace: le navigateur doit déterminer où l'élément commence et se termine. Avec display: block, ces calculs sont beaucoup plus simples.
Remplacer par un rendu accéléré par div de près de 2 fois.
Malheureusement, dans le cas de l' display:block mise en surbrillance de plusieurs lignes de texte semble pire:

Pendant longtemps, je n'ai pas pu décider ce qui est le mieux - 2 secondes supplémentaires de rendu ou de sélection humaine. En conséquence, l'aspect pratique a vaincu la beauté.
Assistant CSS de niveau 10
Un autre ~ 10% du temps de rendu a été coupé par l '"optimisation" CSS, que j'utilise pour formater le texte.
L'inexpérience dans le développement Web et la compréhension des bases ont joué contre moi. Je pensais que plus les sélecteurs étaient précis, mieux c'était, mais spécifiquement dans mon cas, ce n'était pas le cas.
Pour formater le texte dans le terminal, j'ai utilisé les sélecteurs suivants:
#script-panel-container .log-content > div > span.text_color_green,
Mais (en chrome), l'option suivante est un peu plus rapide:
span.text_color_green
Je n'aime pas vraiment ce sélecteur, car trop global, mais les performances sont plus chères.
string.split
Si vous avez un déjà-vu dû à l'un des points précédents, alors c'est faux. Cette fois, il ne s'agit pas de polyfill, mais de l'implémentation standard dans Chrome:

(J'ai enveloppé string.split dans defSplit pour que la fonction apparaisse dans le profileur)
1% sont des bagatelles. Mais le cycliste idéaliste en moi était hanté. Dans mon cas, le split se fait toujours un caractère à la fois et sans habitués. Par conséquent, j'ai implémenté une option simple. Voici le résultat:

fastSplit function fastSplit(str, separatorChar) { if (str === '') { return ['']; } let result = []; let lastIndex = 0; for (let i = 0; i < str.length; i++) { const char = str[i]; if (char === separatorChar) { const chunk = str.substr(lastIndex, i - lastIndex); lastIndex = i + 1; result.push(chunk); } } if (lastIndex < str.length) { const lastChunk = str.substr(lastIndex, str.length - lastIndex); result.push(lastChunk); } return result; }
Je pense qu'après cela, ils sont obligés de m'emmener dans l'équipe Google Chrome sans entretien.
Optimisation, postface
L'optimisation est un processus sans fin et quelque chose peut être amélioré indéfiniment. Surtout si l'on considère que les différents cas d'utilisation nécessitent des optimisations différentes (et conflictuelles).
Pour mon cas, j'ai choisi le cas d'utilisation principal et optimisé son temps de fonctionnement de 15 secondes à 5 secondes. Sur ce, j'ai décidé d'arrêter.

Il y a encore quelques endroits que je prévois d'améliorer, mais c'est grâce à l'expérience acquise.
Bonus Test de mutation.
Il est arrivé qu'au cours des derniers mois, je suis souvent tombé sur le terme «test mutationnel». Et j'ai décidé que cette tâche était un excellent moyen d'essayer cette bête. Surtout après que je n'ai pas eu de couverture de code dans Webstorm, pour des tests sur le karma.
Comme la technique et la bibliothèque sont nouvelles pour moi, j'ai décidé de m'en sortir avec un peu de sang: pour tester un seul composant - le modèle. Dans ce cas, vous pouvez clairement indiquer quel fichier nous testons et quelle suite de tests lui est destinée.
Mais quoi qu'on en dise, j'ai dû beaucoup bricoler pour réussir l'intégration avec le karma et le webpack.
Finalement, tout a commencé et après une demi-heure, j'ai vu de tristes résultats: environ la moitié des mutants ont survécu. J'ai tué une partie immédiatement, une partie laissée pour l'avenir (lorsque j'ai implémenté les commandes ANSI manquantes).
Après cela, la paresse a gagné, et pour le moment les résultats sont les suivants (pour 128 tests):
Ran 79.04 tests per mutant on average. ------------------|---------|----------|-----------|------------|---------| File | % score | # killed | # timeout | # survived | # error | ------------------|---------|----------|-----------|------------|---------| terminal_model.js | 73.10 | 312 | 25 | 124 | 1 | ------------------|---------|----------|-----------|------------|---------| 23:01:08 (18212) INFO Stryker Done in 26 minutes 32 seconds.
En général, cette approche m'a semblé très utile (évidemment meilleure que la couverture du code) et drôle. Le seul point négatif est un temps terriblement long - 30 minutes par classe, c'est trop.
Et surtout, cette approche m'a fait repenser à 100% de couverture et à savoir s'il vaut la peine de tout couvrir avec des tests: maintenant mon avis est encore plus proche de «oui» en répondant à cette question.
Conclusion
L'optimisation des performances, à mon avis, est un bon moyen d'apprendre plus profondément. C'est aussi un bon entraînement pour le cerveau. Et il est très regrettable que cela soit rarement vraiment nécessaire (au moins dans mes projets).
Et comme toujours, l'approche «premier profilage, puis optimisation» fonctionne bien mieux que l'intuition.
Les références
Ancienne implémentation:
Nouvelle implémentation:
Malheureusement, il n'y a pas de démonstration de composant Web, vous ne pourrez donc pas le faire. Je m'excuse donc à l'avance
Merci pour votre temps, je serai heureux de commentaires, suggestions et critiques raisonnables!