Préface
Très souvent, les utilisateurs, les développeurs et les administrateurs de SGBD MS SQL Server sont confrontés à des problèmes de performances de base de données ou de SGBD en général, donc la surveillance de MS SQL Server est très pertinente.
Cet article est un ajout à l'article
Utilisation de Zabbix pour surveiller la base de données MS SQL Server et il examinera certains aspects de la surveillance de MS SQL Server, en particulier: comment déterminer rapidement les ressources manquantes, ainsi que des recommandations pour définir des indicateurs de trace.
Pour que les scripts suivants fonctionnent, vous devez créer le schéma inf dans la base de données souhaitée comme suit:
Création d'un schéma infuse <_>; go create schema inf;
Méthode pour détecter une pénurie de RAM
Le premier indicateur d'un manque de RAM est le cas lorsqu'une instance de MS SQL Server mange toute la RAM qui lui est allouée.
Pour ce faire, créez la vue inf.vRAM suivante:
Création d'une vue inf.vRAM CREATE view [inf].[vRAM] as select a.[TotalAvailOSRam_Mb]
Ensuite, vous pouvez déterminer que l'instance de MS SQL Server consomme toute la mémoire qui lui est allouée par la requête suivante:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb from [inf].[vRAM];
Si l'indicateur SQL_server_physical_memory_in_use_Mb n'est pas constamment inférieur à SQL_server_committed_target_Mb, vous devez vérifier les statistiques des attentes.
Pour déterminer le manque de RAM via les statistiques d'attente, créez une vue inf.vWaits:
Création d'une vue inf.vWaits CREATE view [inf].[vWaits] as WITH [Waits] AS (SELECT [wait_type],
Dans ce cas, vous pouvez déterminer le manque de RAM par la requête suivante:
SELECT [Percentage] ,[AvgWait_S] FROM [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Ici, vous devez faire attention aux performances de Pourcentage et AvgWait_S. S'ils sont significatifs dans leur totalité, alors il y a une très forte probabilité que la RAM ne soit pas suffisante pour une instance de MS SQL Server. Les valeurs essentielles sont déterminées individuellement pour chaque système. Cependant, vous pouvez commencer avec la métrique suivante: Pourcentage> = 1 et AvgWait_S> = 0,005.
Pour générer des indicateurs vers un système de surveillance (par exemple, Zabbix), vous pouvez créer les deux requêtes suivantes:
- combien en pourcentage les types d'attentes pour la RAM occupent (la somme de tous ces types d'attentes):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
- combien de millisecondes occupent les types d'attentes pour la RAM (la valeur maximale de tous les retards moyens pour tous ces types d'attentes):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Sur la base de la dynamique des valeurs obtenues pour ces deux indicateurs, nous pouvons conclure s'il y a suffisamment de RAM pour l'instance de MS SQL Server.
Méthode de détection de surcharge du processeur
Pour identifier le manque de temps CPU, utilisez simplement la vue système sys.dm_os_schedulers. Ici, si l'indicateur runnable_tasks_count est constamment supérieur à 1, il y a une forte probabilité que le nombre de cœurs ne soit pas suffisant pour une instance de MS SQL Server.
Pour afficher l'indicateur dans un système de surveillance (par exemple, Zabbix), vous pouvez créer la requête suivante:
select max([runnable_tasks_count]) as [runnable_tasks_count] from sys.dm_os_schedulers where scheduler_id<255;
Sur la base de la dynamique des valeurs obtenues pour cet indicateur, nous pouvons conclure s'il y a suffisamment de temps processeur (le nombre de cœurs CPU) pour une instance de MS SQL Server.
Cependant, il est important de se rappeler que les requêtes elles-mêmes peuvent demander plusieurs threads à la fois. Et parfois, l'optimiseur ne peut pas évaluer correctement la complexité de la demande elle-même. Ensuite, la demande peut se voir allouer trop de threads qui, à un moment donné, ne peuvent pas être traités simultanément. Et cela provoque également un type d'attente associé à un manque de temps processeur, et la croissance de la file d'attente pour les planificateurs qui utilisent des cœurs de processeur spécifiques, c'est-à-dire que l'indicateur runnable_tasks_count augmentera dans de telles conditions.
Dans ce cas, avant d'augmenter le nombre de cœurs de CPU, vous devez configurer correctement les propriétés de parallélisme de l'instance de MS SQL Server, et à partir de la version 2016, configurer correctement les propriétés de parallélisme des bases de données requises:

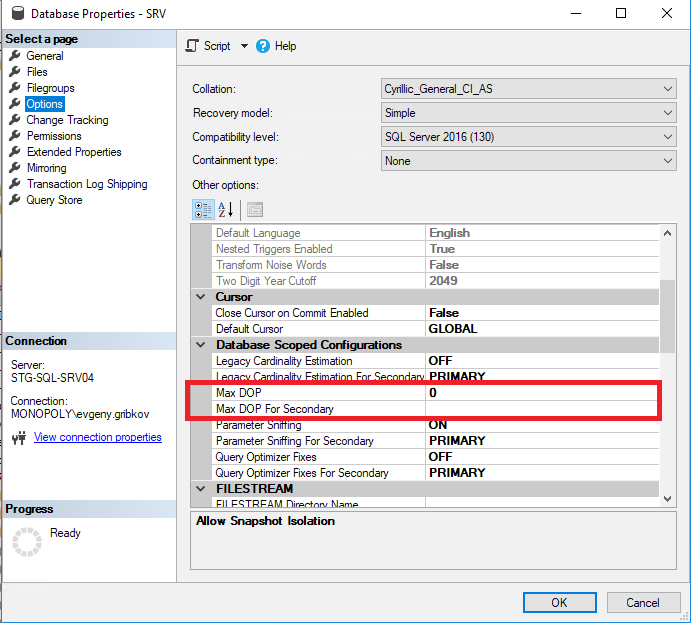
Ici, il convient de prêter attention aux paramètres suivants:
- Degré maximal de parallélisme: définit le nombre maximal de threads pouvant être alloués à chaque demande (la valeur par défaut est 0-restriction uniquement par le système d'exploitation et l'édition MS SQL Server)
- Seuil de coût pour le parallélisme - coût estimé du parallélisme (la valeur par défaut est 5)
- Max DOP-définit le nombre maximal de threads qui peuvent être alloués à chaque requête au niveau de la base de données (mais pas plus que la valeur de la propriété "Max Degree of Parallelism") (la valeur par défaut est 0-restriction uniquement par le système d'exploitation et l'édition MS SQL Server, ainsi que la restriction sur la propriété "Max Degree of Parallelism" de toute l'instance MS SQL Server)
Il est impossible de donner une recette aussi bonne pour tous les cas, c'est-à-dire que vous devez analyser les demandes difficiles.
D'après ma propre expérience, je recommande l'algorithme d'actions suivant pour les systèmes OLTP pour configurer les propriétés de parallélisme:
- interdire d'abord la concurrence en définissant le niveau de l'instance entière de Max Degree of Parallelism sur 1
- analyser les requêtes les plus difficiles et choisir le nombre optimal de threads pour elles
- définir le degré maximal de parallélisme au nombre optimal sélectionné de threads obtenus à partir de l'élément 2, et pour des bases de données spécifiques définir la valeur DOP maximale obtenue à partir de l'élément 2 pour chaque base de données
- analyser les demandes les plus difficiles et identifier l'effet négatif du multithreading. Si tel est le cas, augmentez le seuil de coût pour le parallélisme.
Pour des systèmes tels que 1C, Microsoft CRM et Microsoft NAV, dans la plupart des cas, l'interdiction du multithreading convient.
De plus, si l'édition Standard est installée, alors dans la plupart des cas, l'interdiction du multithreading convient étant donné que cette édition est limitée par le nombre de cœurs de processeur.
Pour les systèmes OLAP, l'algorithme décrit ci-dessus ne convient pas.
D'après ma propre expérience, je recommande l'algorithme d'actions suivant pour les systèmes OLAP pour définir les propriétés de parallélisme:
- analyser les requêtes les plus difficiles et choisir le nombre optimal de threads pour elles
- définir le degré maximal de parallélisme au nombre optimal sélectionné de threads obtenus à partir de l'élément 1, ainsi que pour des bases de données spécifiques définir la valeur DOP maximale obtenue à partir de l'élément 1 pour chaque base de données
- analyser les demandes les plus difficiles et identifier l'effet négatif de la limite de concurrence. Si tel est le cas, réduisez la valeur du seuil de coût pour le parallélisme ou répétez les étapes 1 à 2 de cet algorithme.
Autrement dit, pour les systèmes OLTP, nous passons du simple thread au multithread, et pour les systèmes OLAP, au contraire, nous passons du multithreading au single thread. Ainsi, il est possible de sélectionner les paramètres de concurrence optimale pour à la fois une base de données spécifique et l'ensemble de l'instance MS SQL Server.
Il est également important de comprendre que les paramètres des propriétés de concurrence doivent être modifiés au fil du temps en fonction des résultats de la surveillance des performances de MS SQL Server.
Recommandations pour définir des indicateurs de trace
D'après ma propre expérience et celle de mes collègues, je recommande de définir les indicateurs de trace suivants au niveau du démarrage du service MS SQL Server pour les versions 2008-2016 pour des performances optimales:
- 610 - Réduction de la journalisation des insertions dans les tables indexées. Il peut aider avec des insertions dans des tables avec un grand nombre d'enregistrements et de nombreuses transactions, avec de longues attentes fréquentes de WRITELOG pour les changements d'index
- 1117 - Si un fichier d'un groupe de fichiers atteint le seuil de croissance automatique, tous les fichiers du groupe de fichiers sont développés
- 1118 - Force tous les objets à se trouver dans différentes étendues (interdiction des extensions mixtes), ce qui minimise la nécessité de numériser la page SGAM, qui est utilisée pour suivre les extensions mixtes
- 1224 - Désactive l'escalade des verrous en fonction du nombre de verrous. Une utilisation excessive de la mémoire peut inclure une escalade des verrous.
- 2371 - Change le seuil pour les mises à jour automatiques de statistiques fixes en seuil pour les mises à jour dynamiques de statistiques automatiques. Il est important de mettre à jour les plans de requête pour les grandes tables où la détermination incorrecte du nombre d'enregistrements conduit à des plans d'exécution erronés
- 3226 - Supprime les messages de sauvegarde réussis dans le journal des erreurs
- 4199 - Inclut les modifications apportées à l'optimiseur de requêtes publié dans la mise à jour cumulative et les service packs SQL Server
- 6532-6534 - Comprend des performances de requête améliorées pour les types de données spatiales
- 8048 - Convertit les objets de mémoire partitionnée NUMA en CPU partitionné
- 8780 - Permet une allocation de temps supplémentaire pour la planification d'une demande. Certaines demandes sans cet indicateur peuvent être rejetées car elles n'ont pas de plan de demande (erreur très rare)
- 9389 - Comprend un tampon de mémoire dynamique supplémentaire temporairement fourni pour les opérateurs en mode batch, qui permet à l'opérateur en mode batch de demander de la mémoire supplémentaire et d'éviter de transférer des données vers tempdb si de la mémoire supplémentaire est disponible
Avant la version 2016, il est utile d'inclure l'indicateur de trace 2301, qui inclut l'optimisation de l'aide à la décision étendue et aide ainsi à choisir des plans de requête plus corrects. Cependant, à partir de la version 2016, cela a souvent un effet négatif dans un temps d'exécution de requête global assez long.
De plus, pour les systèmes dans lesquels il y a beaucoup d'index (par exemple, pour les bases de données 1C), je vous recommande d'activer l'indicateur de trace 2330, qui désactive la collecte sur l'utilisation des index, ce qui a généralement un effet positif sur le système.
En savoir plus sur les indicateurs de trace
ici .
En utilisant le lien ci-dessus, il est également important de prendre en compte les versions et les assemblys de MS SQL Server, car pour les versions plus récentes, certains indicateurs de trace sont activés par défaut ou n'ont aucun effet. Par exemple, dans la version 2017, il est pertinent de définir uniquement les 5 indicateurs de trace suivants: 1224, 3226, 6534, 8780 et 9389.
Vous pouvez activer ou désactiver l'indicateur de trace à l'aide des commandes DBCC TRACEON et DBCC TRACEOFF, respectivement. Voir
ici pour plus de détails.
Vous pouvez obtenir l'état des indicateurs de trace à l'aide de la commande DBCC TRACESTATUS:
plus .
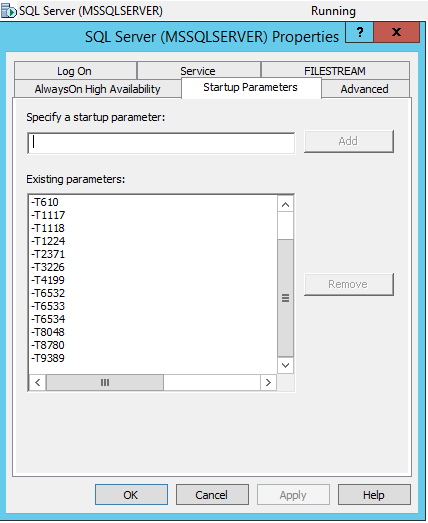
Pour que les indicateurs de trace soient inclus dans l'exécution automatique du service MS SQL Server, vous devez accéder au Gestionnaire de configuration SQL Server et ajouter ces indicateurs de trace dans les propriétés du service via -T:
Résumé
Dans cet article, certains aspects de la surveillance de MS SQL Server ont été examinés, à l'aide desquels vous pouvez rapidement identifier un manque de RAM et de temps libre CPU, ainsi qu'un certain nombre d'autres problèmes moins évidents. Les indicateurs de trace les plus couramment utilisés ont été pris en compte.
Les sources
»
Statistiques de mise en veille de SQL Server»
Statistiques sur les attentes de SQL Server ou dites-moi où ça fait mal»
Vue système sys.dm_os_schedulers»
Utilisation de Zabbix pour suivre la base de données MS SQL Server»
Mode de vie SQL»
Trace drapeaux»
Sql.ru