
Le 1er avril, la finale du SNA Hackathon 2019 s'est terminée, dont les participants ont concouru pour trier le flux des réseaux sociaux en utilisant les technologies modernes d'apprentissage automatique, la vision par ordinateur, le traitement des tests et les systèmes de recommandation. Une sélection en ligne et deux jours de travail acharné sur 160 gigaoctets de données n'ont pas été vains :). Nous parlons de ce qui a aidé les participants à réussir et d'autres observations intéressantes.
À propos des données et de la tâche
Le concours a présenté les données des mécanismes de préparation du flux pour les utilisateurs du réseau social OK , qui se compose de trois parties:
- les journaux d'affichage de contenu dans les flux utilisateur avec un grand nombre d'attributs décrivant l'utilisateur, le contenu, l'auteur et d'autres propriétés;
- textes liés au contenu affiché;
- corps d'images utilisés dans le contenu.
La quantité totale de données dépasse 160 gigaoctets, dont plus de 3 pour les journaux, 3 de plus pour les textes et le reste pour les images. La grande quantité de données n'a pas effrayé les participants: selon les statistiques de ML Bootcamp , près de 200 personnes ont participé au concours, qui ont envoyé plus de 3000 soumissions, et les plus actives ont réussi à dépasser la barre des 100 solutions envoyées. Peut-être étaient-ils motivés par la cagnotte de 700 000 roubles + 3 cartes graphiques GTX 2080 Ti.

Les participants au concours devaient résoudre le problème du tri de la bande: pour chaque utilisateur individuel, triez les objets affichés de manière à ce que ceux qui ont obtenu la marque «Classe!» Soient plus proches du début de la liste.
ROC-AUC a été utilisé comme métrique d'évaluation de la qualité. Dans le même temps, la métrique n'a pas été prise en compte pour toutes les données dans leur ensemble, mais séparément pour chaque utilisateur, puis moyenne. Cette option de calcul est remarquable en ce que les algorithmes qui ont appris à distinguer les utilisateurs qui mettent dans de nombreuses classes ne bénéficient pas d'avantages. D'un autre côté, il n'y a pas une telle option dans les packages Python standard, ce qui a révélé certains points intéressants, qui sont discutés ci-dessous.
À propos de la technologie
Traditionnellement, SNA Hackathon n'est pas seulement des algorithmes, mais aussi des technologies - le volume de données expédiées dépasse 160 gigaoctets, ce qui place les participants devant des tâches techniques intéressantes.
Parquet vs. Csv
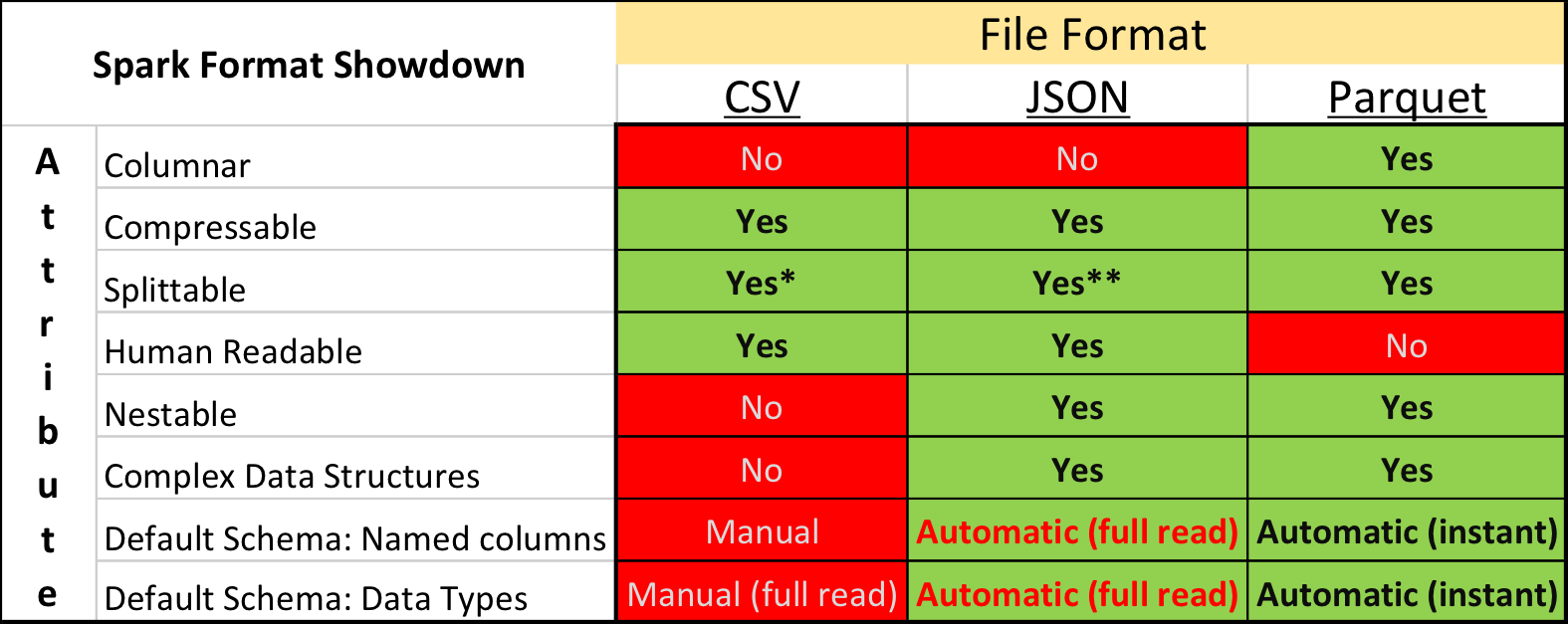
Dans la recherche universitaire et sur Kaggle, le format de données dominant est le CSV , ainsi que d'autres formats de texte brut. Cependant, la situation dans l'industrie est quelque peu différente - beaucoup plus compacte et des vitesses de traitement peuvent être atteintes en utilisant des formats de stockage "binaires".
En particulier, dans l'écosystème construit sur la base d' Apache Spark , Apache Parquet est le plus populaire - un format de stockage de données de colonne prenant en charge de nombreuses fonctionnalités opérationnelles importantes:
- un circuit explicitement spécifié avec support d'évolution;
- lire uniquement les colonnes nécessaires du disque;
- prise en charge de base des index et des filtres lors de la lecture;
- compression de chaîne.
Mais malgré les avantages évidents, la soumission des données pour le concours au format Apache Parquet a été vivement critiquée par certains participants. En plus du conservatisme et de la réticence à passer du temps à développer quelque chose de nouveau, il y a eu plusieurs moments vraiment désagréables.
Premièrement, la prise en charge du format dans la bibliothèque Apache Arrow , l'outil principal pour travailler avec Parquet de Python, est loin d'être parfaite. Lors de la préparation des données, tous les champs structurels ont dû être étendus à plat, et pourtant, lors de la lecture des textes, de nombreux participants ont rencontré un bogue et ont été obligés d'installer l'ancienne version de la bibliothèque 0.11.1 au lieu de la version actuelle 0.12 à l'époque. Deuxièmement, vous ne regarderez pas le fichier Parquet en utilisant des utilitaires de console simples: cat, less, etc. Cependant, cet inconvénient est relativement facile à compenser pour l'utilisation de l'ensemble parquet-outillage .
Néanmoins, ceux qui ont d'abord essayé de convertir toutes les données en CSV, puis de travailler dans l'environnement familier, ont finalement abandonné cette idée - après tout, Parquet fonctionne beaucoup plus rapidement.
Boosting et GPU

Lors de la conférence SmartData à Saint-Pétersbourg, «largement connue dans les milieux étroits», Alexey Natekin a comparé les performances de plusieurs outils de boosting populaires tout en travaillant sur le CPU / GPU et est arrivé à la conclusion que le GPU ne donne pas de gain tangible. Mais même alors, cette conclusion a conduit à une polémique active, principalement avec les développeurs de l' outil domestique CatBoost .
Au cours des deux dernières années, les progrès dans le développement de GPU et l'adaptation d'algorithmes ne se sont pas arrêtés et la finale du SNA Hackathon peut être considérée comme un triomphe de la paire CatBoost + GPU - tous les gagnants l'ont utilisé et ont tiré la métrique principalement en raison de la capacité de faire pousser plus d'arbres par unité de temps.
L'implémentation intégrée du codage cible moyen a également contribué au résultat élevé des solutions basées sur CatBoost, mais le nombre et la profondeur des arbres ont donné une augmentation plus significative.
D'autres outils de renforcement évoluent dans la même direction, ajoutant et améliorant la prise en charge du GPU. Cultivez donc plus d'arbres!
Spark vs. Pyspark

L'outil Apache Spark est un leader incontournable de la Data Science industrielle, grâce en partie à l'API Python. Cependant, l'utilisation de Python s'accompagne d'une surcharge supplémentaire pour l'intégration entre différents runtimes et le travail d'interpréteur.
Cela en soi n'est pas un problème si l'utilisateur est conscient de la mesure dans laquelle le montant des coûts supplémentaires conduit à une action particulière. Cependant, il s'est avéré que beaucoup ne réalisent pas l'ampleur du problème - malgré le fait que les participants n'aient pas utilisé Apache Spark, les discussions sur Python vs Scala est apparu régulièrement dans le chat du hackathon, ce qui a conduit à l'apparition du poste analysé correspondant.
En bref, le ralentissement de l'utilisation de Spark via Python par rapport à l'utilisation de Spark via Scala / Java peut être décomposé en les niveaux suivants:
- seule l'API Spark SQL est utilisée sans fonctions définies par l'utilisateur (UDF) - dans ce cas, il n'y a pratiquement pas de frais généraux, car le plan d'exécution de la requête dans son intégralité est calculé dans le cadre de la JVM;
- UDF est utilisé en Python sans appeler de packages avec du code C ++ - dans ce cas, les performances de l'étape à laquelle UDF est calculé chutent 7 à 10 fois ;
- UDF est utilisé en Python avec accès au package C ++ (numpy, sklearn, etc.) - dans ce cas, les performances chutent de 10 à 50 fois .
En partie, l'effet négatif peut être compensé pour l'utilisation de PyPy (JIT pour Python) et des FDU vectorisés , cependant, même dans ces cas, la différence de performances est multiple, et la complexité de la mise en œuvre et du déploiement s'accompagne d'un «bonus» supplémentaire.
À propos des algorithmes
Mais la chose la plus intéressante à propos des hackathons Data Science n'est bien sûr pas les technologies, mais les nouveaux algorithmes à la mode et éprouvés. CatBoost a dominé le SNA Hackathon cette année, mais il y avait plusieurs approches alternatives. Nous en parlerons :).
Graphes différenciables

L'une des premières publications de décisions basées sur les résultats du tour de qualification a été consacrée non pas aux arbres, mais aux graphiques différenciables (également appelés réseaux de neurones artificiels). L'auteur est un employé de OK, il ne peut donc pas se permettre de courir après des prix, mais plutôt de construire une solution prometteuse sur la base d'une base mathématique solide.
L'idée principale de la solution proposée était de construire un graphique différenciable de calcul unique qui traduit les fonctionnalités disponibles en une prévision qui prend en compte divers aspects des données d'entrée:
- les unions d'objets et d'utilisateurs vous permettent d'ajouter un élément de recommandations collaboratives classiques;
- la transition de l'intégration scalaire à l'agrégation via MLP vous permet d'ajouter des caractéristiques arbitraires;
- L'attention par clé-valeur de requête a permis au modèle de s'adapter dynamiquement au comportement même d'un utilisateur qui ne connaissait pas son historique récent.
Ce modèle s'est révélé très bon pour la sélection en ligne pour résoudre le problème de la recommandation de contenu textuel, de sorte que plusieurs équipes ont essayé de le jouer en finale à la fois, mais elles n'ont pas réussi. Cela est dû en partie au fait que cela demande du temps et de l'expérience, et en partie au fait que le nombre d'attributs dans la finale était beaucoup plus important et que les méthodes basées sur les arbres ont reçu un avantage significatif grâce à elles.
Collaborative dominant

Bien sûr, lors de l'organisation du concours, nous savions qu'il y avait un signal assez fort dans les journaux, car les panneaux collectés là-bas reflètent une partie importante du travail effectué dans OK pour classer le flux. Néanmoins, jusqu'à la fin, ils espéraient que les participants réussiraient à faire face à la «malédiction du troisième personnage» - des situations où d'énormes ressources humaines et machines investies dans le développement d'un modèle d'extraction d'attributs du contenu (textes et photos) entraîneraient des gains de qualité extrêmement modestes par rapport à déjà traits préparés, principalement collaboratifs.
Connaissant ce problème, nous avons initialement divisé la tâche en trois pistes dans le tour de qualification et formé un ensemble de données combinées uniquement lors de la finale, mais au format hackathon avec une métrique fixe, les équipes qui ont investi dans le développement de modèles de contenu se sont retrouvées dans une situation délibérément perdante par rapport aux équipes développant une collaboration partie.
Le prix du jury a permis de compenser cette injustice ...
Grappe profonde

Ce qui a été presque unanimement attribué pour le travail sur la reproduction et le test de l'algorithme Deep Cluster de Facebook. La méthode de balisage initiale simple et ne nécessitant pas de création de grappes et d'images incorporées impressionne par des idées de nouveauté et des résultats prometteurs.
L'essence de la méthode est extrêmement simple:
- calculer des vecteurs d'intégration pour les images avec n'importe quel réseau neuronal significatif;
- regrouper les vecteurs dans l'espace résultant avec k-moyennes;
- former un classificateur de réseau neuronal pour prédire un groupe d'images;
- répétez les étapes 2 et 3 jusqu'à la convergence (si vous avez 800 GPU) ou tant qu'il y a suffisamment de temps.
Avec un minimum d'efforts, nous avons réussi à obtenir un regroupement d'images OK de haute qualité, de bons incorporations et une augmentation métrique au troisième chiffre.
Regardez vers l'avenir

Dans toutes les données, vous pouvez trouver des "failles" pour améliorer les prévisions. En soi, ce n'est pas si mal, c'est bien pire si les failles se trouvent et n'apparaissent longtemps que sous la forme de divergences incompréhensibles entre les résultats de la validation sur les données historiques et les tests A / B.
L'une des failles les plus répandues de ce type est l'utilisation des informations du futur. Ces informations sont souvent un signal très fort et l'algorithme d'apprentissage automatique, s'il est activé, commencera à les utiliser en toute confiance. Lorsque vous créez un modèle pour votre produit, vous essayez de toutes les manières possibles d'éviter les fuites d'informations de l'avenir, mais lors du hackathon, c'est une bonne occasion d'augmenter la métrique, qui a été utilisée par les participants.
L'échappatoire la plus évidente était la présence de numLikes et numDislikes dans ces champs avec le nombre de réactions sur l'objet au moment du spectacle. En comparant les deux événements les plus proches dans le temps liés au même objet, il a été possible de déterminer avec une grande précision quelle était la réaction à l'objet dans le premier d'entre eux. Il y avait plusieurs compteurs similaires dans les données, et leur utilisation a donné un avantage notable. Naturellement, en utilisation réelle, ces informations ne seront pas disponibles.
Dans la vie, un problème similaire peut être rencontré sans le savoir, généralement avec des résultats négatifs. Par exemple, compter les statistiques sur le nombre de points "Classe!" pour l'objet en fonction de toutes les données et en le prenant comme un attribut séparé. Ou, comme ils l'ont fait dans l'une des équipes participantes, en ajoutant un identifiant d'objet au modèle en tant qu'attribut catégorique. Sur un ensemble d'entraînement, un modèle doté d'une telle fonctionnalité fonctionne bien, mais ne peut pas être généralisé à un ensemble de test.
Au lieu d'une conclusion

Tous les documents du concours, y compris les données et les présentations des décisions des participants, sont disponibles dans le Cloud Mail.ru. Les données peuvent être utilisées par des projets de recherche sans restrictions, à l'exception de la disponibilité de liens. Pour l'histoire, quittons la table finale ici avec les métriques des équipes finales:
- Scala accroupi, cachant Python - 0.7422, analysant la solution est disponible ici , et le code est ici et ici .
- Magic City - 0,7256
- Kéfir - 0,7226
- Équipe 6 - 0,7205
- Trois dans un bateau - 0,7188
- Hall # 14 - 0.7167 et prix du jury
- BezSNA - 0.7147
- PONGA - 0.7117
- Équipe 5 - 0,7112
Le SNA Hackathon 2019, comme les précédents événements de la série, a été un succès dans tous les sens. Nous avons réussi à rassembler des professionnels sympas dans différents domaines sous un même toit et à passer un moment fructueux, dont un grand merci aux participants eux-mêmes et à tous ceux qui ont aidé l'organisation.
Aurait-on pu faire encore mieux? Bien sûr que oui! Chaque concours organisé nous enrichit d'une nouvelle expérience, dont nous tenons compte lors de la préparation du prochain et qui ne s'arrêtera pas là. Alors à bientôt au SNA Hackathon!