Parfois, lors du développement d'un produit à haute charge, une situation survient lorsqu'il est nécessaire de traiter non autant de demandes que possible, mais plutôt de limiter le nombre de demandes par unité de temps. Dans notre cas, il s'agit du nombre de notifications push envoyées aux utilisateurs finaux. En savoir plus sur les algorithmes de limitation de débit, leurs avantages et leurs inconvénients - sous la coupe.
D'abord, un peu de nous. Pushwoosh est un service B2B de communication entre nos clients et leurs utilisateurs. Nous proposons aux entreprises des solutions complètes pour communiquer avec les utilisateurs via des notifications push, des e-mails et d'autres canaux de communication. En plus d'envoyer réellement des messages, nous proposons des outils pour segmenter l'audience, collecter et traiter des statistiques, et bien plus encore. Pour ce faire, nous avons créé à partir de zéro un produit à haute charge à la jonction de nombreuses technologies, dont seulement une petite partie sont PHP, Golang, PostgreSQL, MongoDB, Apache Kafka. Beaucoup de nos solutions sont uniques, par exemple, les notifications à haut débit. Nous traitons plus de 2 milliards de demandes d'API par jour, nous avons plus de 3 milliards d'appareils dans notre base de données et, pendant toute la durée, nous avons envoyé plus de 500 milliards de notifications à ces appareils.
Et ici, nous arrivons à une situation où les notifications doivent être envoyées à des millions d'appareils pas aussi rapidement que possible (comme dans le haut débit déjà mentionné), mais en limitant artificiellement la vitesse afin que les serveurs de nos clients auxquels les utilisateurs se rendent lorsqu'ils ouvrent la notification ne tombent pas dans le même temps charge.
Ici, divers algorithmes de limitation de débit viennent à notre aide, ce qui nous permet de limiter le nombre de requêtes par unité de temps. En règle générale, cela est utilisé, par exemple, lors de la conception d'une API, car nous pouvons ainsi protéger le système contre les excès accidentels ou malveillants de demandes, ce qui entraîne un retard ou un déni de service à d'autres clients. Si la limitation de débit est mise en œuvre, tous les clients sont limités à un nombre fixe de demandes par unité de temps. De plus, la limitation de débit peut être utilisée lors de l'accès à des parties du système associées à des données sensibles; Ainsi, si un attaquant y accède, il ne pourra pas accéder rapidement à toutes les données.
Il existe de nombreuses façons d'implémenter la limitation de débit. Dans cet article, nous examinerons les avantages et les inconvénients de divers algorithmes, ainsi que les problèmes pouvant survenir lors de la mise à l'échelle de ces solutions.
Algorithmes de limite de vitesse de traitement des demandes
Seau qui fuit (Seau qui fuit)
Leaky Bucket est un algorithme qui fournit l'approche la plus simple et la plus intuitive pour limiter la vitesse de traitement à l'aide d'une file d'attente, qui peut être représentée comme un "bucket" contenant des requêtes. Lorsqu'une demande est reçue, elle est ajoutée à la fin de la file d'attente. À intervalles réguliers, le premier élément de la file d'attente est traité. Ceci est également connu comme la file d'attente FIFO . Si la file d'attente est pleine, les demandes supplémentaires sont rejetées (ou «fuite»).

L'avantage de cet algorithme est qu'il lisse les explosions et traite les demandes à environ la même vitesse, qu'il est facile à implémenter sur un seul serveur ou équilibreur de charge, qu'il est efficace dans l'utilisation de la mémoire, car la taille de la file d'attente pour chaque utilisateur est limitée.
Cependant, avec une forte augmentation du trafic, la file d'attente peut être remplie d'anciennes demandes et priver le système de la possibilité de traiter des demandes plus récentes. Il ne garantit pas non plus que les demandes seront traitées dans un délai déterminé. De plus, si vous chargez des équilibreurs pour fournir une tolérance aux pannes ou augmenter le débit, vous devez mettre en œuvre une stratégie de coordination et garantir une restriction globale entre eux.
Il existe une variante de cet algorithme - Token Bucket («bucket with tokens» ou «marker basket algorithm»).
Dans une telle implémentation, les jetons sont ajoutés au «compartiment» à une vitesse constante, et lors du traitement de la demande, le jeton du «compartiment» est supprimé; s'il n'y a pas assez de jetons, la demande est rejetée. Vous pouvez simplement utiliser l'horodatage comme jetons.
Il existe des variantes utilisant plusieurs «seaux», tandis que les tailles et le taux de réception des jetons peuvent être différents pour des «seaux» individuels. S'il n'y a pas assez de jetons dans le premier "compartiment" pour traiter la demande, alors leur présence dans le second, etc., est vérifiée, mais la priorité du traitement de la demande est réduite (en règle générale, cela est utilisé dans la conception des interfaces réseau lorsque, par exemple, vous pouvez modifier la valeur du champ Paquet traité par DSCP ).
La principale différence avec l'implémentation de Leaky Bucket est que les jetons peuvent s'accumuler lorsque le système est inactif et que des rafales peuvent se produire plus tard, tandis que les demandes seront traitées (car il y a suffisamment de jetons), tandis que Leaky Bucket est garanti pour lisser la charge même en cas de panne.
Fenêtre fixe
Cet algorithme utilise une fenêtre de n secondes pour suivre les demandes. En règle générale, des valeurs telles que 60 secondes (minutes) ou 3600 secondes (heures) sont utilisées. Chaque demande entrante augmente le compteur de cette fenêtre. Si le compteur dépasse une certaine valeur de seuil, la demande est rejetée. En règle générale, la fenêtre est déterminée par la limite inférieure de l'intervalle de temps actuel, c'est-à-dire que lorsque la fenêtre a une largeur de 60 secondes, la demande arrivant à 12:00:03 ira à la fenêtre 12:00:00.
L'avantage de cet algorithme est qu'il permet le traitement des requêtes les plus récentes, sans dépendre du traitement des anciennes. Cependant, une seule rafale de trafic près de la bordure de la fenêtre peut doubler le nombre de demandes traitées, car elle autorise les demandes pour la fenêtre actuelle et la fenêtre suivante pendant une courte période. De plus, si de nombreux utilisateurs attendent la réinitialisation du compteur de fenêtres, par exemple, à la fin de l'heure, ils peuvent provoquer une augmentation de la charge à ce moment du fait qu'ils accéderont à l'API en même temps.
Bûche coulissante
Cet algorithme implique le suivi des horodatages de chaque demande utilisateur. Ces enregistrements sont stockés, par exemple, dans un ensemble ou une table de hachage et triés par heure; les enregistrements en dehors de l'intervalle surveillé sont rejetés. Lorsqu'une nouvelle demande arrive, nous calculons le nombre d'enregistrements pour déterminer la fréquence des demandes. Si la demande est en dehors de la quantité autorisée, elle est rejetée.
L'avantage de cet algorithme est qu'il n'est pas soumis à des problèmes qui se posent aux bords de la fenêtre fixe , c'est-à-dire que la limite de vitesse sera strictement respectée. De plus, étant donné que les demandes de chaque client sont surveillées individuellement, il n'y a pas de croissance de charge maximale à certains points, ce qui est un autre problème de l'algorithme précédent.
Cependant, le stockage d'informations sur chaque demande peut être coûteux.En outre, chaque demande nécessite de calculer le nombre de demandes précédentes, potentiellement sur l'ensemble du cluster, ce qui fait que cette approche ne s'adapte pas bien pour gérer de grandes quantités de trafic et les attaques par déni de service.
Fenêtre coulissante
Il s'agit d'une approche hybride qui combine le faible coût de traitement d'une fenêtre fixe et la gestion avancée des situations limites Sliding Log . Comme dans la fenêtre fixe simple, nous suivons le compteur de chaque fenêtre, puis prenons en compte la valeur pondérée de la fréquence de demande de la fenêtre précédente en fonction de l'horodatage actuel pour lisser les rafales de trafic. Par exemple, si 25% du temps de la fenêtre courante s'est écoulé, alors nous prenons en compte 75% des demandes de la précédente. La quantité relativement faible de données nécessaires pour le suivi de chaque clé nous permet d'évoluer et de travailler dans un grand cluster.

Cet algorithme vous permet de mettre à l'échelle la limitation de débit tout en conservant de bonnes performances. De plus, c'est un moyen compréhensible de transmettre aux clients des informations sur la limitation du nombre de demandes, et évite également les problèmes qui surviennent lors de la mise en œuvre d'autres algorithmes de limitation de débit.
Limitation de débit dans les systèmes distribués
Politiques de synchronisation
Si vous souhaitez définir la limitation de débit globale lors de l'accès à un cluster composé de plusieurs nœuds, vous devez mettre en œuvre une stratégie de restriction. Si chaque nœud ne suivait que sa propre restriction, l'utilisateur pouvait la contourner en envoyant simplement des demandes à différents nœuds. En fait, plus le nombre de nœuds est élevé, plus la probabilité que l'utilisateur soit en mesure de dépasser la limite globale est grande.
Le moyen le plus simple de définir des limites consiste à configurer une «session persistante» sur l'équilibreur afin que l'utilisateur soit dirigé vers le même nœud. Les inconvénients de cette méthode sont le manque de tolérance aux pannes et les problèmes de mise à l'échelle lorsque les nœuds de cluster sont surchargés.
La meilleure solution, qui permet des règles plus flexibles pour l'équilibrage de charge, est d'utiliser un entrepôt de données centralisé (de votre choix). Il peut stocker des compteurs du nombre de demandes pour chaque fenêtre et utilisateur. Les principaux problèmes de cette approche sont l'augmentation du temps de réponse due aux demandes de stockage et aux conditions de concurrence.
Conditions de course
Un des plus gros problèmes avec un entrepôt de données centralisé est la possibilité de conditions de course en compétition. Cela se produit lorsque vous utilisez l'approche get-then-set naturelle, dans laquelle vous extrayez le compteur actuel, l'incrémentez, puis renvoyez la valeur résultante au magasin. Le problème avec ce modèle est que pendant le temps nécessaire pour terminer le cycle complet de ces opérations (c'est-à-dire lire, incrémenter et écrire), d'autres demandes peuvent arriver, à chacune desquelles le compteur sera stocké avec une valeur non valide (inférieure). Cela permet à l'utilisateur d'envoyer plus de demandes que l'algorithme de limitation de débit ne fournit.
Une façon d'éviter ce problème consiste à définir un verrou autour de la clé en question, empêchant ainsi l'accès à la lecture ou à l'écriture de tout autre processus sur le compteur. Cependant, cela peut rapidement devenir un goulot d'étranglement des performances et n'évolue pas bien, en particulier lors de l'utilisation de serveurs distants, tels que Redis, comme magasin de données supplémentaire.
Une bien meilleure approche est «set - then - get», basée sur les opérateurs atomiques, qui vous permet d'augmenter et de vérifier rapidement les valeurs du compteur sans interférer avec les opérations atomiques.
Optimisation des performances
Un autre inconvénient de l'utilisation d'un entrepôt de données centralisé est l'augmentation du temps de réponse en raison du retard dans la vérification des compteurs utilisés pour mettre en œuvre la limitation de débit (temps aller-retour , ou «retard aller-retour »). Malheureusement, même la vérification d'un stockage rapide tel que Redis entraînera des retards supplémentaires de quelques millisecondes par demande.
Pour faire la définition d'une contrainte avec un délai minimum, il est nécessaire d'effectuer des vérifications en mémoire locale. Cela peut être fait en assouplissant les conditions de vérification de la vitesse et éventuellement en utilisant un modèle cohérent.
Par exemple, chaque nœud peut créer un cycle de synchronisation des données dans lequel il se synchronisera avec le référentiel. Chaque nœud transmet périodiquement la valeur du compteur pour chaque utilisateur et la fenêtre affectée, au magasin, qui mettra à jour atomiquement les valeurs. Ensuite, le nœud peut recevoir de nouvelles valeurs et mettre à jour les données dans la mémoire locale. Ce cycle permettra à terme à tous les nœuds du cluster d'être à jour.
La période pendant laquelle les nœuds sont synchronisés doit être personnalisable. Des intervalles de synchronisation plus courts entraîneront moins de divergence de données lorsque la charge est répartie uniformément sur plusieurs nœuds du cluster (par exemple, dans le cas où l'équilibreur détermine les nœuds selon le principe du «round-robin»), tandis que des intervalles plus longs créent moins de charge de lecture / écriture pour le stockage et réduire le coût à chaque nœud pour recevoir des données synchronisées.
Comparaison des algorithmes de limitation de débit
Plus précisément, dans notre cas, nous ne devons pas rejeter les demandes des clients pour l'API, mais sur la base des données, au contraire, ne les créons pas; cependant, nous n'avons pas le droit de «perdre» les demandes. Pour ce faire, lors de l'envoi d'une notification, nous utilisons le paramètre send_rate, qui indique le nombre maximum de notifications que nous enverrons par seconde lors de l'envoi.
Ainsi, un certain Worker effectue un travail dans le temps imparti (dans mon exemple, la lecture d'un fichier), qui reçoit l'interface RateLimitingInterface en entrée, indiquant s'il est possible d'exécuter une demande à un moment donné et combien de temps elle s'exécutera.
interface RateLimitingInterface { public function __construct(int $rate); public function canDoWork(float $currentTime): bool; }
Tous les exemples de code peuvent être trouvés sur GitHub ici .
Je vais immédiatement expliquer pourquoi vous devez transférer une tranche de temps vers Worker. Le fait est qu'il est trop coûteux d'exécuter un démon distinct pour traiter l'envoi d'un message avec une limite de vitesse, donc send_rate est en fait utilisé comme paramètre "nombre de notifications par unité de temps", qui est de 0,01 à 1 seconde selon la charge.
En fait, nous traitons jusqu'à 100 requêtes différentes avec send_rate par seconde, allouant 1 / N secondes pour chaque quantum de temps, où N est le nombre de push traités par ce démon. Le paramètre qui nous intéresse le plus lors du traitement est de savoir si send_rate sera respecté (les petites erreurs sont autorisées dans un sens ou dans l'autre) et la charge sur notre matériel (nombre minimum d'accès au stockage, consommation CPU et mémoire).
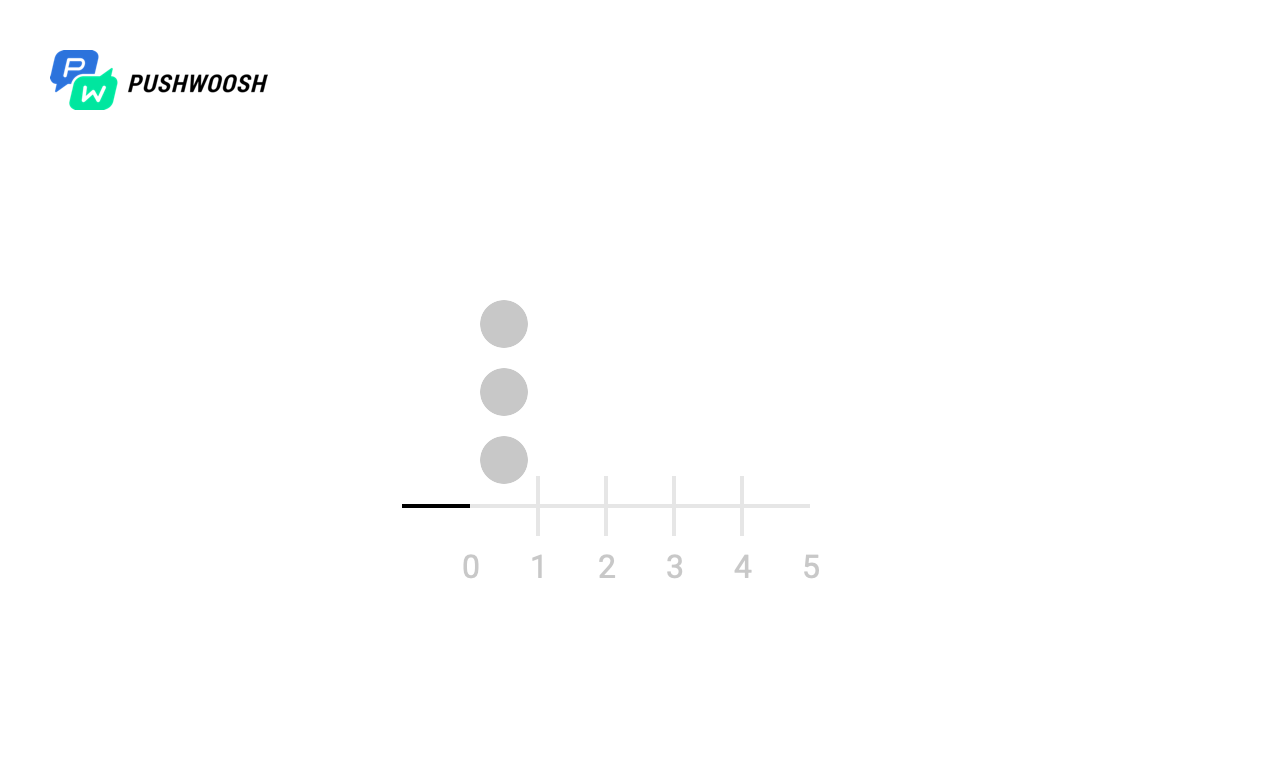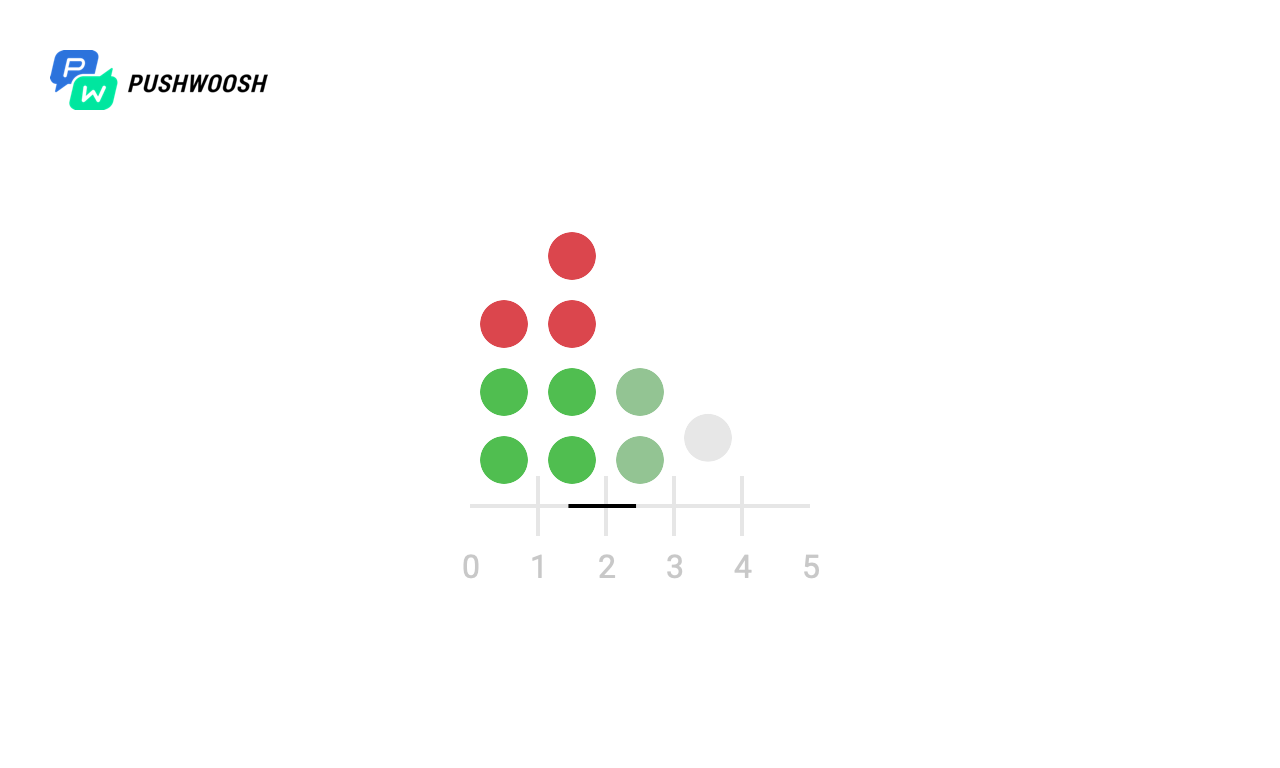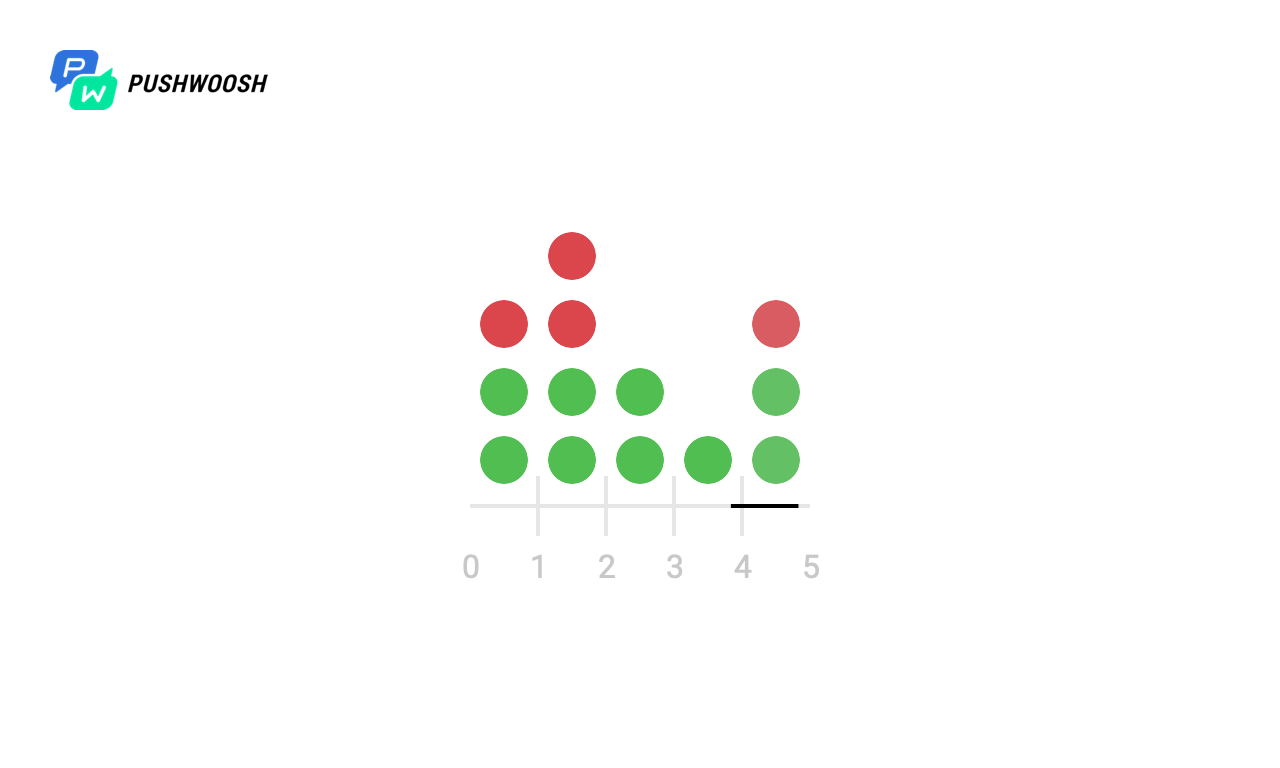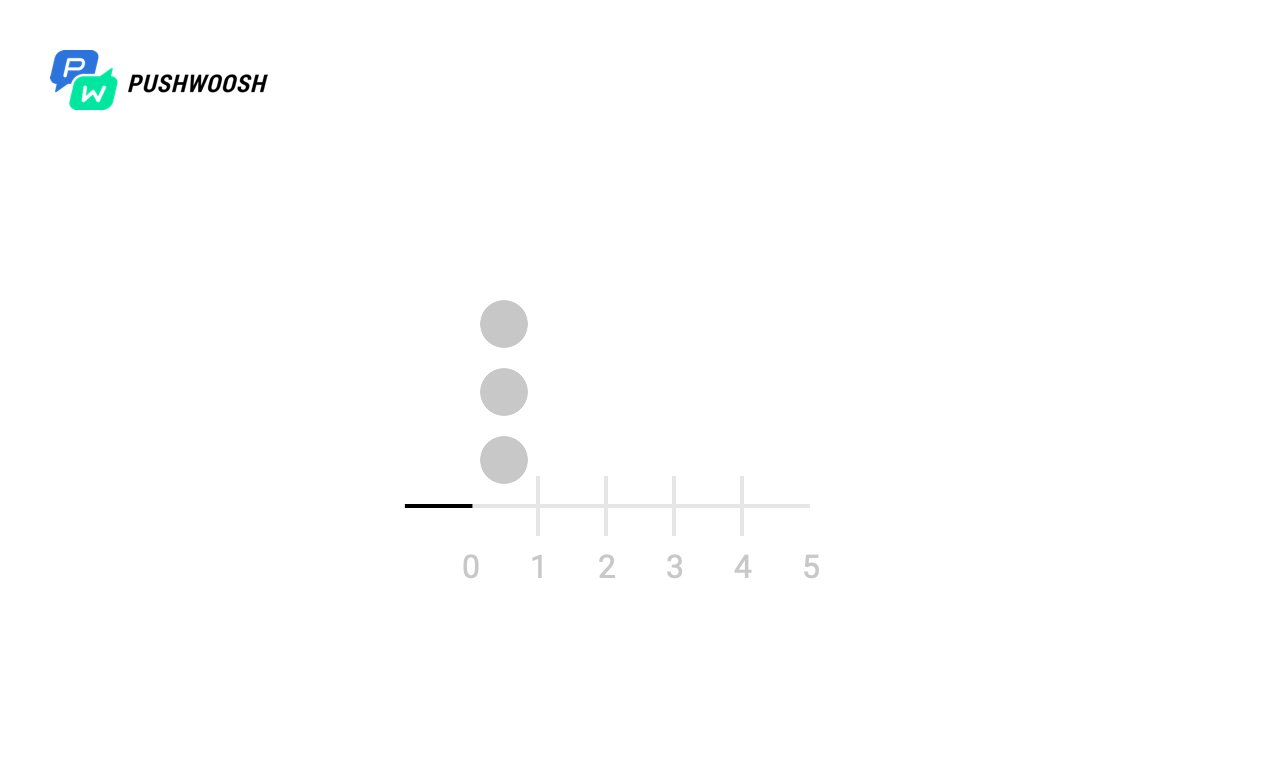
Pour commencer, essayons de déterminer à quels moments Worker fonctionne vraiment. Pour simplifier, cet exemple a traité un fichier de 10 000 lignes avec send_rate = 1000 (c'est-à-dire que nous lisons 1 000 lignes par seconde dans le fichier).
Dans les captures d'écran, les marqueurs marquent les moments et le nombre d'appels de fgets pour tous les algorithmes. En réalité, cela peut être un appel à une base de données, à une ressource tierce ou à toute autre requête, dont nous voulons limiter le nombre par unité de temps.
Sur l'échelle X - le temps depuis le début du traitement, de 0 à 10 secondes, chaque seconde est divisée en dixièmes, donc le calendrier est de 0 à 100).
Nous voyons que malgré le fait que tous les algorithmes gèrent l'observance de send_rate (pour cela, ils sont destinés), la fenêtre fixe et le journal coulissant "distribuent" la charge entière presque simultanément, ce qui ne nous convient pas beaucoup, tandis que Token Bucket et Sliding Windows le répartit uniformément par unité de temps (à l'exception de la charge de pointe au moment du démarrage, en raison du manque de données sur la charge aux heures précédentes).
En raison du fait qu'en réalité, le code ne fonctionne généralement pas avec le système de fichiers local, mais avec un stockage tiers, la réponse peut être retardée, il peut y avoir des problèmes de réseau et de nombreux autres problèmes, nous allons essayer de vérifier comment tel ou tel algorithme se comportera lorsque les demandes prendront un certain temps n'était pas. Par exemple, après 4 et 6 secondes.
Ici, il peut sembler que la fenêtre fixe ne fonctionne pas correctement et traite 2 fois plus que les requêtes attendues dans les premières et de 7 à 8 secondes, mais en fait ce n'est pas le cas, car le temps est compté à partir du moment du lancement sur le graphique, et l'algorithme utilise le timestamp Unix actuel .
En général, rien n'a fondamentalement changé, mais nous voyons que le seau à jetons lisse la charge plus en douceur et ne dépasse jamais la limite de débit spécifiée, mais le journal de glissement en cas d'indisponibilité peut dépasser la valeur autorisée.
Conclusion
Nous avons examiné tous les algorithmes de base pour implémenter la limitation de débit, chacun ayant ses avantages et ses inconvénients et convenant à diverses tâches. Nous espérons qu'après avoir lu cet article, vous choisirez l'algorithme le plus approprié pour résoudre votre problème.