¡Hola! nous continuons une série de publications dédiées au lancement du cours
"Développeur Web en Python" et en ce moment nous partageons avec vous la traduction d'un autre article intéressant.
Chez Zendesk, nous utilisons Python pour créer des produits d'apprentissage automatique. Dans les applications d'apprentissage automatique, l'un des problèmes les plus courants que nous avons rencontrés est les fuites de mémoire et les pics. Le code Python est généralement exécuté dans des conteneurs à l'aide de structures de traitement réparties telles que
Hadoop ,
Spark et
AWS Batch . Chaque conteneur se voit allouer une quantité fixe de mémoire. Dès que l'exécution du code dépasse la limite de mémoire spécifiée, le conteneur cesse de fonctionner en raison d'erreurs qui se produisent en raison d'un manque de mémoire.

Vous pouvez résoudre rapidement le problème en allouant encore plus de mémoire. Cependant, cela peut entraîner un gaspillage de ressources et affecter la stabilité des applications en raison de rafales de mémoire imprévisibles. Les causes d'une fuite de mémoire peuvent être
les suivantes :
- Stockage long d'objets volumineux qui ne sont pas supprimés;
- Liens de bouclage dans le code;
- Bibliothèques / extensions de base C entraînant une fuite de mémoire;
Il est recommandé de profiler l'utilisation de la mémoire avec les applications pour mieux comprendre l'efficacité de l'espace de code et des packages utilisés.
Cet article traite des aspects suivants:
- Profilage de l'utilisation de la mémoire des applications au fil du temps;
- Comment vérifier l'utilisation de la mémoire dans une partie spécifique du programme;
- Conseils pour déboguer les erreurs causées par des problèmes de mémoire.
Profilage de la mémoire au fil du tempsVous pouvez jeter un œil à l'utilisation de la mémoire variable lors de l'exécution d'un programme Python à l'aide du package
memory-profiler .
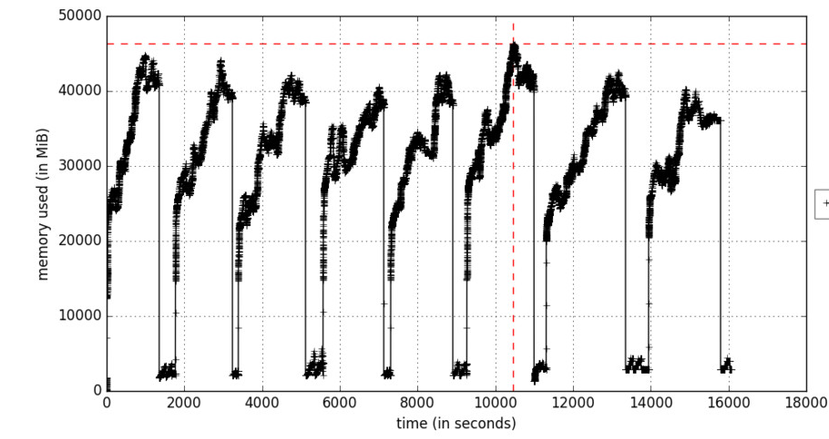 Figure A. Profilage de la mémoire en fonction du temps
Figure A. Profilage de la mémoire en fonction du tempsL'
option include-children permettra l'utilisation de la mémoire par tous les processus enfants générés par les processus parents. La figure A reflète le processus d'apprentissage itératif, qui entraîne une augmentation de la mémoire en cycles aux moments où les paquets de données d'apprentissage sont traités. Les objets sont supprimés lors de la récupération de place.
Si l'utilisation de la mémoire augmente constamment, cela est considéré comme une menace potentielle de fuite de mémoire.
Voici un exemple de code qui reflète cela:
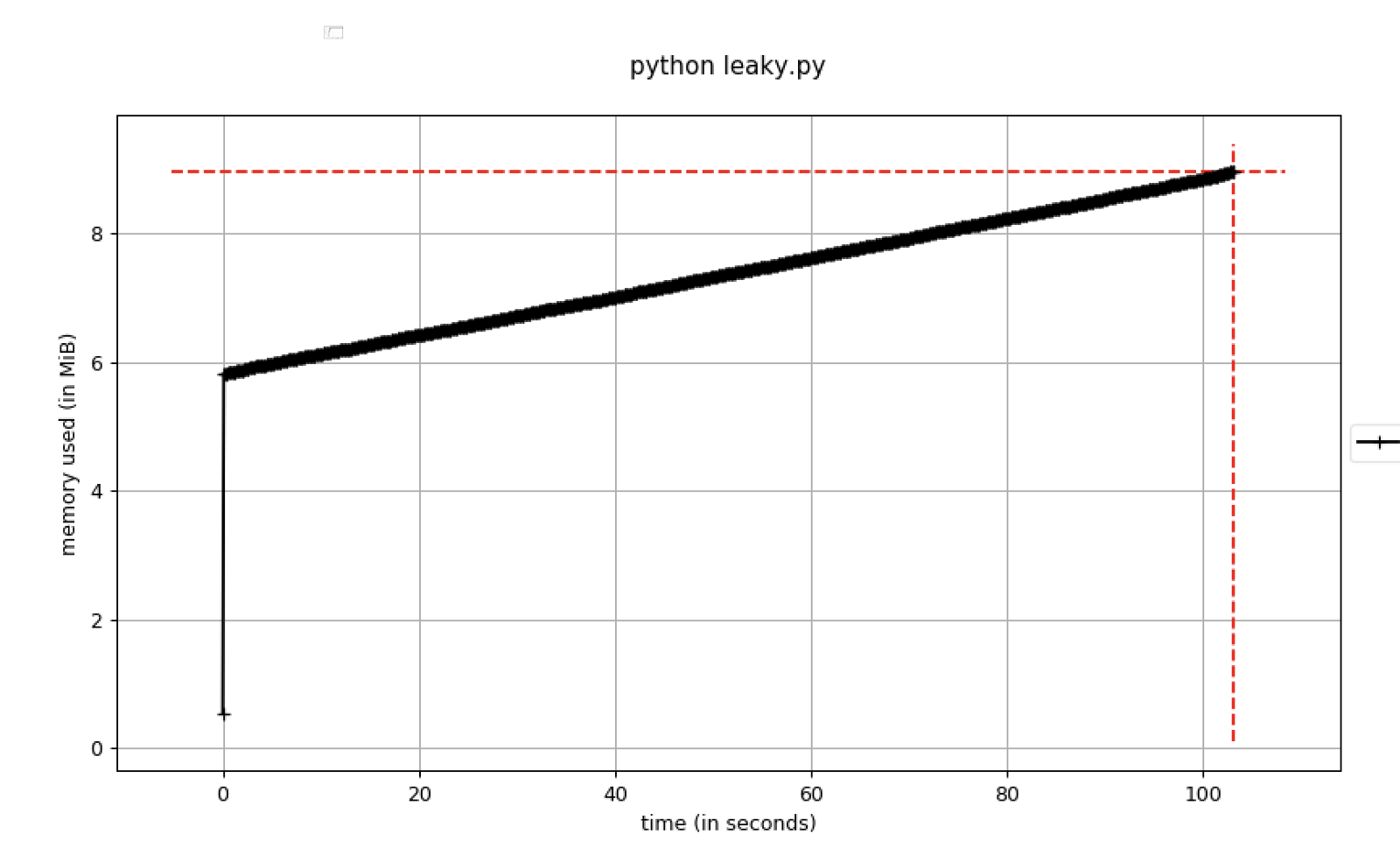 Figure B. L'utilisation de la mémoire augmente avec le temps
Figure B. L'utilisation de la mémoire augmente avec le tempsVous devez définir des points d'arrêt dans le débogueur dès que l'utilisation de la mémoire dépasse un certain seuil. Pour ce faire, vous pouvez utiliser le
paramètre pdb-mmem , qui est pratique lors du dépannage.
Vidage de la mémoire à un moment précisIl est utile d'estimer le nombre prévu de gros objets dans le programme et s'ils doivent être dupliqués et / ou convertis en différents formats.
Pour une analyse plus approfondie des objets en mémoire, vous pouvez créer un tas de vidage dans certaines lignes du programme à l'aide de
muppy .
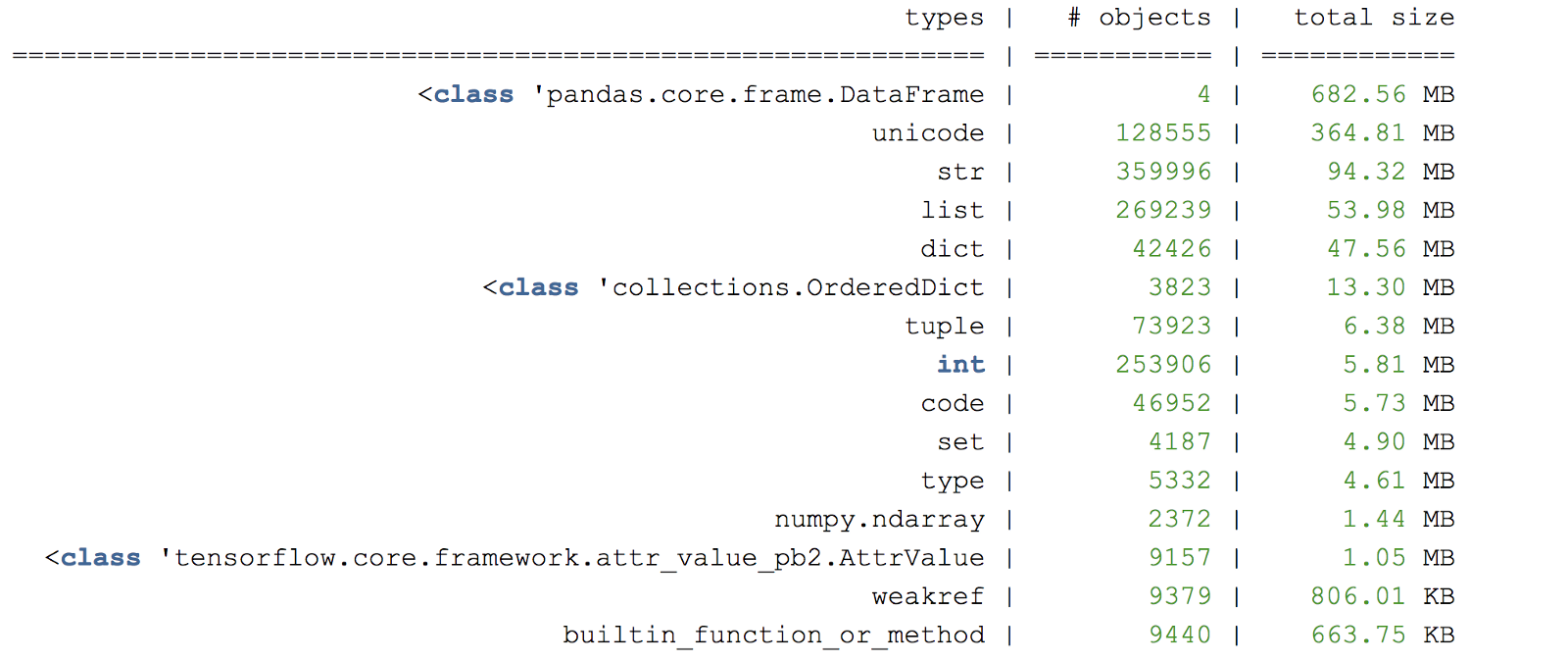 Figure C. Exemple de vidage de tas de vidage
Figure C. Exemple de vidage de tas de vidageUne autre bibliothèque de profilage de mémoire utile est
objgraph , qui vous permet de générer des graphiques pour vérifier l'origine des objets.
Pointeurs utilesUne approche utile consiste à créer un petit «cas de test» qui exécute le code approprié qui provoque une fuite de mémoire. Envisagez d'utiliser un sous-ensemble de données sélectionnées de manière aléatoire si le traitement d'une entrée à part entière prendra du temps.
Effectuer des tâches avec une charge de mémoire élevée dans un processus distinctPython ne libère pas nécessairement de la mémoire immédiatement pour le système d'exploitation. Pour vous assurer que la mémoire a été libérée, vous devez démarrer un processus distinct après avoir exécuté un morceau de code. Vous pouvez en savoir plus sur le garbage collector en Python
ici .
Le débogueur peut ajouter des références aux objets.Si vous utilisez un débogueur de point d'arrêt tel que
pdb , tous les objets créés qui sont référencés manuellement par le débogueur resteront en mémoire. Cela peut créer un faux sentiment de fuite de mémoire, car les objets ne sont pas supprimés en temps opportun.
Méfiez-vous des packages qui peuvent provoquer une fuite de mémoire.Certaines bibliothèques en Python peuvent potentiellement provoquer une fuite, par exemple
pandas a plusieurs problèmes connus de
fuite de mémoire .
Bonne chasse aux fuites!
Liens utiles:docs.python.org/3/c-api/memory.htmldocs.python.org/3/library/debug.htmlÉcrivez dans les commentaires si cet article vous a été utile. Et ceux qui veulent en savoir plus sur notre cours, nous vous invitons à la
journée portes ouvertes , qui se tiendra le 22 avril.