Bonjour, je suis Sergey Elantsev, je développe un
équilibreur de charge réseau dans Yandex.Cloud. Auparavant, j'ai dirigé le développement de l'équilibreur L7 du portail Yandex - mes collègues plaisantent que peu importe ce que je fais, j'obtiens un équilibreur. Je dirai aux lecteurs de Habr comment gérer la charge dans la plateforme cloud, comment nous voyons l'outil idéal pour atteindre cet objectif et comment nous nous dirigeons vers la construction de cet outil.
Tout d'abord, nous introduisons quelques termes:
- VIP (IP virtuelle) - adresse IP de l'équilibreur
- Serveur, backend, instance - une machine virtuelle avec une application en cours d'exécution
- RIP (Real IP) - adresse IP du serveur
- Healthcheck - contrôle de disponibilité du serveur
- Zone de disponibilité, AZ - infrastructure isolée dans le centre de données
- Région - l'union de différents AZ
Les équilibreurs de charge résolvent trois tâches principales: ils effectuent l'équilibrage lui-même, améliorent la tolérance aux pannes du service et simplifient sa mise à l'échelle. La tolérance aux pannes est assurée par le contrôle automatique du trafic: l'équilibreur surveille l'état de l'application et exclut les instances de l'équilibrage qui échouent au test de vivacité. La mise à l'échelle est assurée par une distribution uniforme de la charge entre les instances, ainsi que par la mise à jour de la liste des instances à la volée. Si l'équilibrage n'est pas suffisamment uniforme, certaines des instances obtiendront une charge dépassant leur limite de capacité de travail et le service deviendra moins fiable.
L'équilibreur de charge est souvent classé par niveau de protocole à partir du modèle OSI sur lequel il s'exécute. Le Cloud Balancer opère au niveau TCP, ce qui correspond au quatrième niveau, L4.
Passons à un examen de l'architecture de l'équilibreur de cloud. Nous augmenterons progressivement le niveau de détail. Nous divisons les composants de l'équilibreur en trois classes. La classe de plan de configuration est responsable de l'interaction avec l'utilisateur et stocke l'état cible du système. Le plan de contrôle stocke l'état actuel du système et gère les systèmes de la classe du plan de données, qui sont directement responsables de l'acheminement du trafic des clients vers vos instances.
Plan de données
Le trafic tombe sur des appareils coûteux appelés routeurs frontaliers. Pour augmenter la tolérance aux pannes, plusieurs de ces appareils fonctionnent simultanément dans un même centre de données. Ensuite, le trafic va aux équilibreurs, qui annoncent l'adresse IP anycast à tous les AZ via BGP pour les clients.
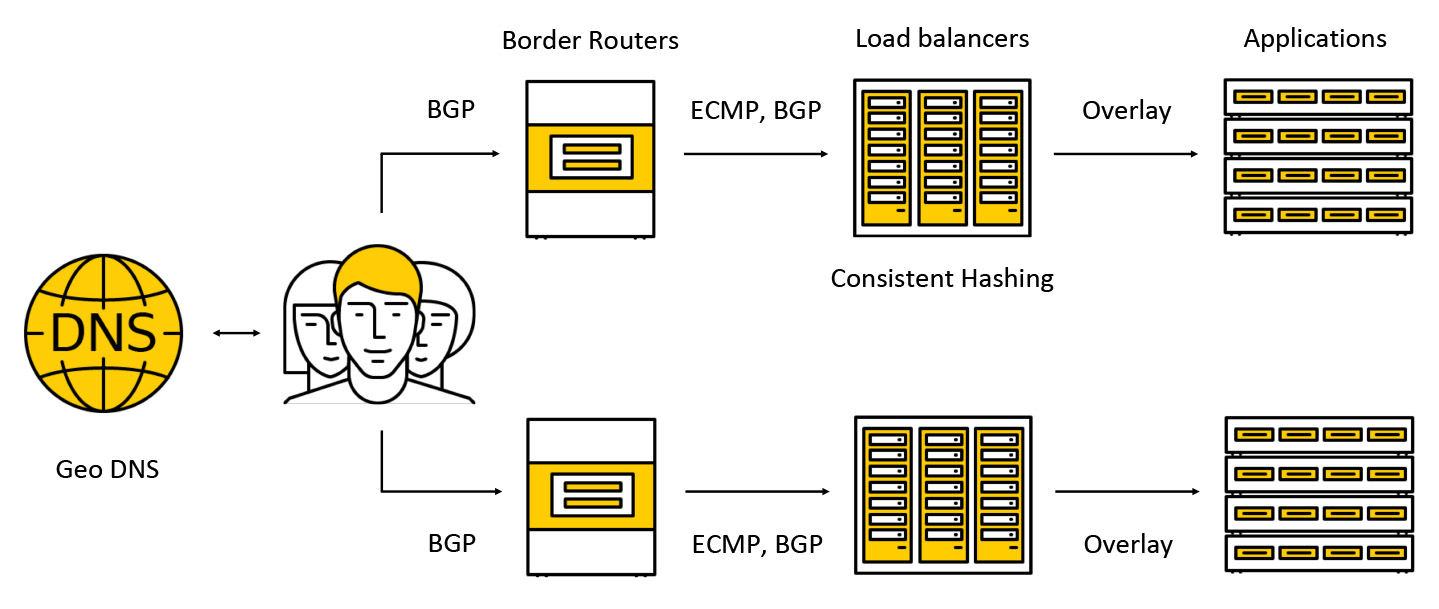
Le trafic est transmis via ECMP - il s'agit d'une stratégie de routage selon laquelle il peut y avoir plusieurs itinéraires tout aussi bons vers la destination (dans notre cas, la destination sera l'adresse IP de destination) et des paquets peuvent être envoyés à l'un d'eux. Nous prenons également en charge les travaux dans plusieurs zones d'accès selon le schéma suivant: nous annonçons l'adresse dans chacune des zones, le trafic tombe dans la plus proche et ne la dépasse pas déjà. Plus loin dans l'article, nous examinerons plus en détail ce qui arrive au trafic.
Avion de configuration
Le composant clé du plan de configuration est l'API à travers laquelle les opérations de base avec les équilibreurs sont effectuées: création, suppression, modification de la composition des instances, obtention des résultats des contrôles de santé, etc. D'une part, il s'agit d'une API REST, et d'autre part, nous utilisons souvent le cadre dans le Cloud gRPC, donc nous «traduisons» REST en gRPC, puis utilisons uniquement gRPC. Toute demande conduit à la création d'une série de tâches asynchrones idempotentes qui sont effectuées sur un pool partagé de travailleurs Yandex.Cloud. Les tâches sont écrites de manière à pouvoir être suspendues à tout moment, puis redémarrées. Cela fournit des opérations d'évolutivité, de répétabilité et de journalisation.

Par conséquent, la tâche de l'API fera une demande au contrôleur de service d'équilibrage, qui est écrite dans Go. Il peut ajouter et supprimer des équilibreurs, modifier la composition des backends et les paramètres.
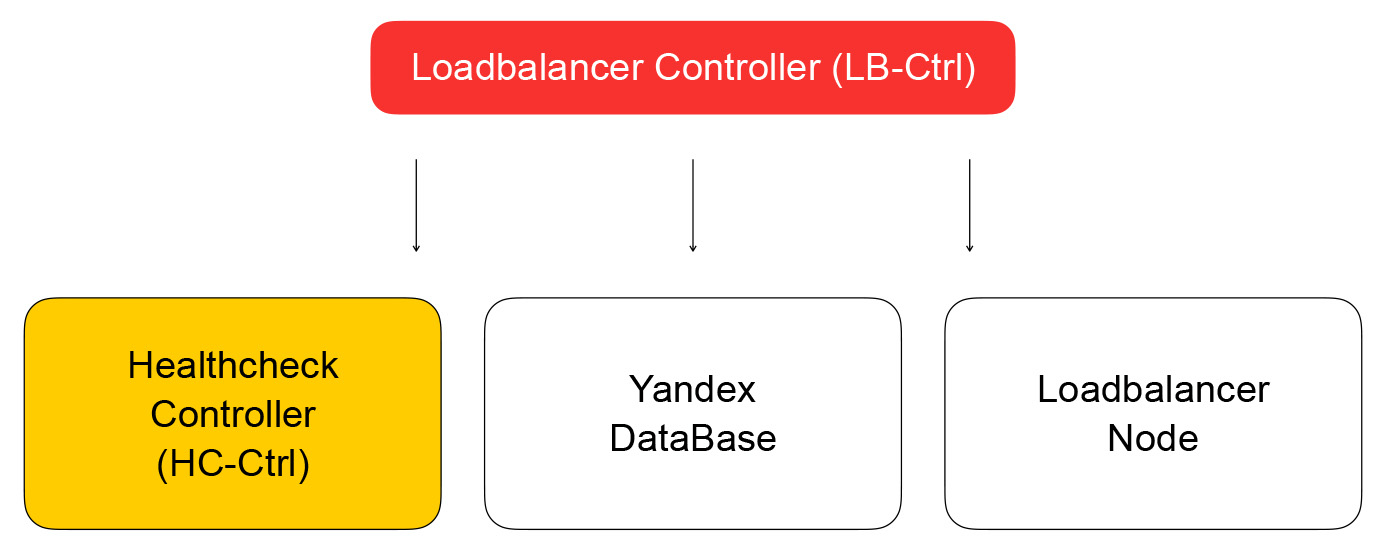
Le service stocke son état dans Yandex Database - une base de données gérée distribuée que vous pourrez bientôt utiliser également. Chez Yandex.Cloud, comme nous l'avons déjà
dit , le concept de la nourriture pour chiens fonctionne: si nous utilisons nous-mêmes nos services, nos clients seront également heureux de les utiliser. La base de données Yandex est un exemple de mise en œuvre d'un tel concept. Nous stockons toutes nos données dans YDB, et nous n'avons pas à penser à la maintenance et à la mise à l'échelle de la base de données: ces problèmes sont résolus pour nous, nous utilisons la base de données comme un service.
Nous revenons au contrôleur d'équilibrage. Sa tâche consiste à enregistrer des informations sur l'équilibreur, à envoyer la tâche de vérification de l'état de préparation de la machine virtuelle au contrôleur de contrôle de santé.
Contrôleur Healthcheck
Il reçoit les demandes de modification des règles d'inspection, les enregistre dans YDB, distribue les tâches aux nœuds de vérification et agrège les résultats, qui sont ensuite enregistrés dans la base de données et envoyés au contrôleur de l'équilibreur de charge. À son tour, il envoie une demande de modification de la composition du cluster dans le plan de données à loadbalancer-node, dont je parlerai ci-dessous.

Parlons plus des contrôles de santé. Ils peuvent être divisés en plusieurs classes. Les audits ont des critères de réussite différents. Les vérifications TCP doivent établir avec succès une connexion dans un délai fixe. Les vérifications HTTP nécessitent à la fois une connexion réussie et une réponse avec un code d'état de 200.
En outre, les contrôles diffèrent dans la classe d'action - ils sont actifs et passifs. Les contrôles passifs surveillent simplement ce qui arrive au trafic sans prendre aucune mesure spéciale. Cela ne fonctionne pas très bien sur L4, car cela dépend de la logique des protocoles de niveau supérieur: sur L4, il n'y a aucune information sur la durée de l'opération et si la connexion était bonne ou mauvaise. Les vérifications actives nécessitent que l'équilibreur envoie des demandes à chaque instance de serveur.
La plupart des équilibreurs de charge effectuent eux-mêmes des contrôles de vivacité. Chez Cloud, nous avons décidé de séparer ces parties du système pour augmenter l'évolutivité. Cette approche nous permettra d'augmenter le nombre d'équilibreurs, tout en maintenant le nombre de demandes de contrôle de santé au service. Les contrôles sont effectués par des nœuds de contrôle de santé distincts, qui sont utilisés pour partager et répliquer les cibles de test. Il est impossible d'effectuer des vérifications à partir d'un hôte, car il peut échouer. Ensuite, nous n'obtiendrons pas l'état des instances qu'il a vérifiées. Nous effectuons des vérifications sur toute instance provenant d'au moins trois nœuds de contrôle de santé. Les cibles des vérifications que nous répartissons entre les nœuds à l'aide d'algorithmes de hachage cohérents.

La séparation de l'équilibrage et du bilan de santé peut entraîner des problèmes. Si le nœud Healthcheck fait des requêtes à l'instance, en contournant l'équilibreur (qui ne sert pas actuellement le trafic), une situation étrange se produit: la ressource semble être vivante, mais le trafic ne l'atteindra pas. Nous résolvons ce problème de cette façon: nous sommes assurés d'obtenir du trafic de bilan de santé via des équilibreurs. En d'autres termes, le schéma de déplacement des paquets avec le trafic des clients et des contrôles de santé diffère de façon minimale: dans les deux cas, les paquets iront aux équilibreurs, qui les livreront aux ressources cibles.
La différence est que les clients font des demandes de VIP et que les contrôles de santé se réfèrent à chaque RIP individuel. Ici, un problème intéressant se pose: nous donnons à nos utilisateurs la possibilité de créer des ressources dans des réseaux IP gris. Imaginez qu'il existe deux propriétaires de cloud différents qui ont caché leurs services pour les équilibreurs. De plus, chacun d'eux a des ressources dans le sous-réseau 10.0.0.1/24 avec les mêmes adresses. Vous devez être en mesure de les distinguer d'une manière ou d'une autre, et ici vous devez plonger dans l'appareil du réseau virtuel Yandex.Cloud. Pour plus de détails, consultez la
vidéo de l'événement about: cloud , il est important pour nous maintenant que le réseau soit multicouche et possède des tunnels qui peuvent être distingués par l'ID de sous-réseau.
Les nœuds Healthcheck accèdent aux équilibreurs à l'aide d'adresses dites quasi-IPv6. Une quasi-adresse est une adresse IPv6 dans laquelle l'adresse IPv4 et l'ID de sous-réseau utilisateur sont protégés. Le trafic tombe sur l'équilibreur, il en extrait l'adresse IPv4 de la ressource, remplace IPv6 par IPv4 et envoie le paquet au réseau de l'utilisateur.
Le trafic inverse va de la même manière: l'équilibreur voit que la destination est un réseau gris provenant des vérificateurs de santé et convertit IPv4 en IPv6.
VPP - le cœur du plan de données
L'équilibreur est implémenté sur la technologie de Vector Packet Processing (VPP) - un framework de Cisco pour le traitement des paquets du trafic réseau. Dans notre cas, le cadre fonctionne au-dessus de la bibliothèque de gestion de l'espace utilisateur des périphériques réseau - Kit de développement de plan de données (DPDK). Cela fournit des performances de traitement de paquets élevées: il y a beaucoup moins d'interruptions dans le noyau, il n'y a pas de changement de contexte entre l'espace du noyau et l'espace utilisateur.
VPP va encore plus loin et réduit encore plus les performances du système en combinant des packages en lots. La productivité accrue est due à l'utilisation agressive des caches des processeurs modernes. Les deux caches de données sont utilisés (les paquets sont traités par des "vecteurs", les données sont proches les uns des autres) et les caches d'instructions: dans VPP, le traitement des paquets suit un graphique, dans les nœuds dont il existe des fonctions qui effectuent une tâche.
Par exemple, le traitement des paquets IP dans VPP se déroule dans l'ordre suivant: d'abord, les en-têtes de paquets sont analysés dans le nœud d'analyse, puis ils sont envoyés au nœud qui transfère les paquets en fonction des tables de routage.
Un peu de hardcore. Les auteurs de VPP ne font aucun compromis sur l'utilisation des caches de processeur, donc un code de traitement vectoriel de package typique contient une vectorisation manuelle: il y a un cycle de traitement dans lequel la situation comme «nous avons quatre paquets dans la file d'attente» est traitée, puis la même chose pour deux, puis - pour un. Souvent, des instructions de prélecture sont utilisées pour charger les données dans les caches afin d'accélérer leur accès aux itérations suivantes.
n_left_from = frame->n_vectors; while (n_left_from > 0) { vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
Ainsi, Healthchecks transforme IPv6 en VPP, qui les transforme en IPv4. Cela se fait par le nœud de graphe, que nous appelons NAT algorithmique. Pour le trafic inverse (et la conversion d'IPv6 en IPv4), il existe le même nœud de NAT algorithmique.
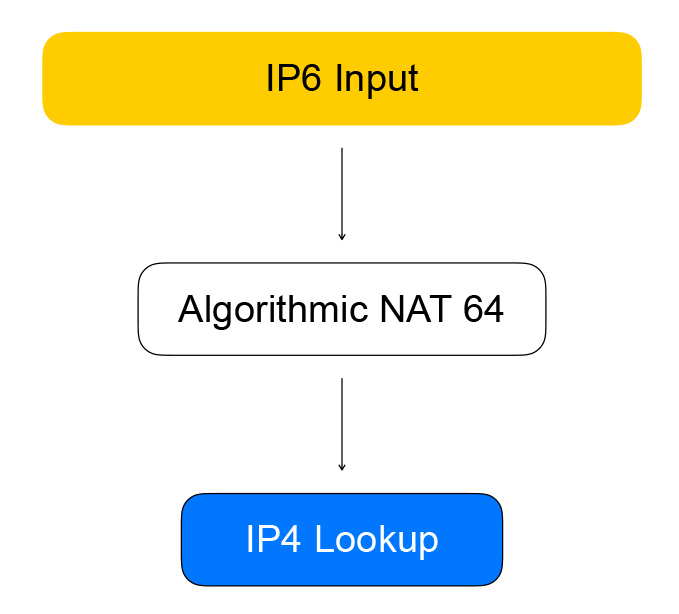
Le trafic direct des clients de l'équilibreur passe par les nœuds du graphique, qui effectuent l'équilibrage lui-même.

Le premier nœud est les sessions persistantes. Il stocke un hachage de
5 tuples pour les sessions établies. Le 5-tuple comprend l'adresse et le port du client à partir duquel les informations sont transmises, l'adresse et les ports des ressources disponibles pour recevoir le trafic, ainsi que le protocole réseau.
Le hachage à 5 tuples nous aide à effectuer moins de calculs dans le nœud de hachage cohérent suivant et à mieux gérer le changement dans la liste des ressources derrière l'équilibreur. Lorsqu'un paquet arrive sur l'équilibreur pour lequel il n'y a pas de session, il est envoyé au nœud de hachage cohérent. C'est là que l'équilibrage se produit à l'aide d'un hachage cohérent: nous sélectionnons une ressource dans la liste des ressources "actives" disponibles. Ensuite, les paquets sont envoyés au nœud NAT, qui remplace réellement l'adresse de destination et recalcule les sommes de contrôle. Comme vous pouvez le voir, nous suivons les règles de VPP - similaires à similaires, regrouper des calculs similaires pour augmenter l'efficacité des caches de processeur.
Hachage cohérent
Pourquoi l'avons-nous choisi et de quoi s'agit-il? Pour commencer, considérez la tâche précédente - sélectionner une ressource dans la liste.
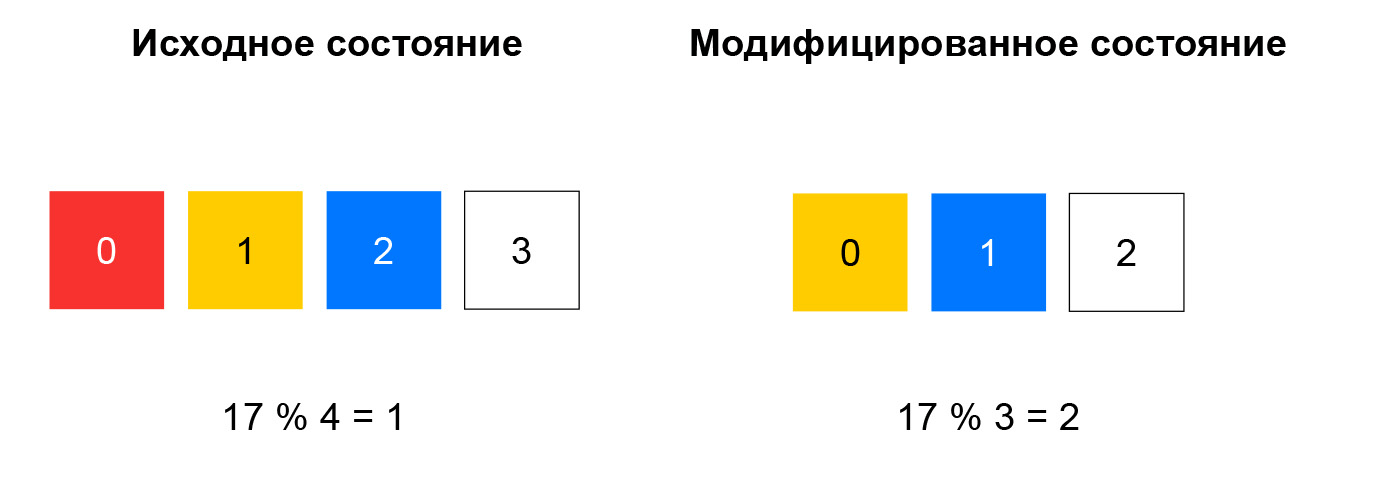
Avec un hachage non cohérent, le hachage du paquet entrant est calculé et la ressource est sélectionnée dans la liste par le reste de la division de ce hachage par le nombre de ressources. Tant que la liste reste inchangée, un tel schéma fonctionne bien: nous envoyons toujours des paquets avec le même 5-tuple à la même instance. Si, par exemple, une ressource cesse de répondre aux contrôles de santé, alors pour une partie importante des hachages, le choix changera. Les connexions TCP seront rompues au niveau du client: un paquet qui était auparavant passé à l'instance A peut commencer à tomber dans l'instance B, qui n'est pas familière avec la session pour ce paquet.
Un hachage cohérent résout le problème décrit. La façon la plus simple d'expliquer ce concept est la suivante: imaginez que vous disposez d'un anneau dans lequel vous distribuez les ressources par hachage (par exemple, par IP: port). Le choix d'une ressource est la rotation de la roue d'un angle, qui est déterminé par le hachage du paquet.
Cela minimise la redistribution du trafic lors du changement de la composition des ressources. La suppression d'une ressource n'affectera que la partie de l'anneau de hachage cohérent sur laquelle se trouvait la ressource donnée. L'ajout d'une ressource modifie également la distribution, mais nous avons un nœud de sessions collantes qui nous permet de ne pas basculer les sessions déjà établies vers de nouvelles ressources.
Nous avons examiné ce qui arrive au trafic direct entre l'équilibreur et les ressources. Voyons maintenant le trafic inverse. Il suit le même modèle que le trafic de vérification - via NAT algorithmique, c'est-à-dire via NAT inverse 44 pour le trafic client et via NAT 46 pour le trafic de vérification de l'état. Nous adhérons à notre propre schéma: nous unifions le trafic des contrôles de santé et le trafic réel des utilisateurs.
Assemblage de noeud d'équilibrage de charge et de composants
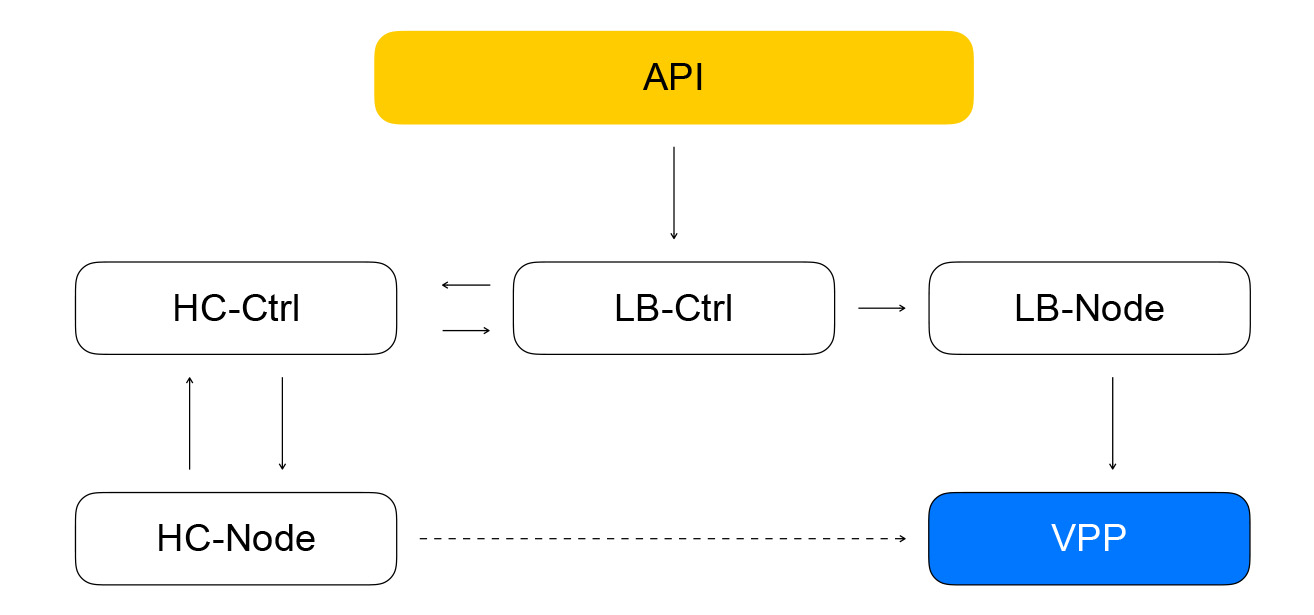
La composition des équilibreurs et des ressources dans VPP est signalée par le service local - loadbalancer-node. Il souscrit au flux d'événements du contrôleur d'équilibrage de charge, est capable de créer la différence entre l'état actuel du VPP et l'état cible reçu du contrôleur. Nous obtenons un système fermé: les événements de l'API arrivent au contrôleur d'équilibrage, qui définit les tâches du contrôleur de contrôle de santé pour vérifier la «vivacité» des ressources. Cela, à son tour, définit les tâches dans le nœud de vérification de santé et agrège les résultats, après quoi il les renvoie au contrôleur d'équilibrage. Le nœud d'équilibrage de charge s'abonne aux événements du contrôleur et modifie l'état du VPP. Dans un tel système, chaque service ne sait que ce dont il a besoin concernant les services voisins. Le nombre de connexions est limité et nous avons la possibilité d'exploiter et de dimensionner indépendamment les différents segments.
Quelles questions ont été évitées
Tous nos services dans le plan de contrôle sont écrits en Go et ont de bonnes fonctionnalités de mise à l'échelle et de fiabilité. Go possède de nombreuses bibliothèques open source pour la construction de systèmes distribués. Nous utilisons activement GRPC, tous les composants contiennent une implémentation open source de la découverte de services - nos services surveillent les performances des uns et des autres, peuvent changer leur composition de manière dynamique, et nous l'avons lié avec l'équilibrage GRPC. Pour les métriques, nous utilisons également une solution open source. Dans le plan des données, nous avons obtenu des performances décentes et une grande réserve de ressources: il s'est avéré très difficile d'assembler un support sur lequel on pouvait s'appuyer sur les performances de VPP, et non une carte réseau en fer.
Problèmes et solutions
Qu'est-ce qui n'a pas très bien fonctionné? Dans Go, la gestion de la mémoire est automatique, mais des fuites de mémoire se produisent. Le moyen le plus simple de les gérer est de lancer des goroutines et n'oubliez pas de les compléter. Conclusion: surveillez la consommation de mémoire des programmes Go. Souvent, un bon indicateur est la quantité de goroutine. Il y a un plus dans cette histoire: dans Go, il est facile d'obtenir des données sur l'exécution - sur la consommation de mémoire, sur le nombre de goroutines lancées et sur de nombreux autres paramètres.
De plus, Go n'est peut-être pas le meilleur choix pour les tests fonctionnels. Ils sont assez verbeux, et l'approche standard «tout exécuter dans le package CI» ne leur convient pas très bien. Le fait est que les tests fonctionnels sont plus exigeants sur les ressources, avec eux il y a de vrais timeouts. De ce fait, les tests peuvent échouer car le processeur est occupé par des tests unitaires. Conclusion: si possible, effectuez des tests «lourds» séparément des tests unitaires.
L'architecture d'événements de microservice est plus compliquée qu'un monolithe: récupérer des journaux sur des dizaines de machines différentes n'est pas très pratique. Conclusion: si vous faites des microservices, pensez immédiatement au traçage.
Nos plans
Nous lancerons l'équilibreur interne, IPv6-équilibreur, ajouterons la prise en charge des scripts Kubernetes, continuerons de partager nos services (désormais seuls les nœuds de contrôle de santé et de contrôle de santé-ctrl sont ombrés), ajouterons de nouveaux contrôles de santé et implémenterons également l'agrégation de vérification intelligente. Nous envisageons la possibilité de rendre nos services encore plus indépendants - afin qu'ils ne communiquent pas directement entre eux, mais en utilisant une file d'attente de messages. Le service
Yandex Message Queue compatible SQS est récemment apparu dans le cloud.
Récemment, Yandex Load Balancer a été rendu public. Étudiez la
documentation du service, gérez les équilibreurs d'une manière qui vous convient et augmentez la tolérance aux pannes de vos projets!