
Depuis 2008, notre entreprise est principalement engagée dans la gestion des infrastructures et le support technique 24h / 24 pour les projets web: nous avons plus de 400 clients, soit environ 15% du e-commerce en Russie. En conséquence, une architecture très diversifiée est prise en charge. Si quelque chose tombe, nous devons le réparer dans les 15 minutes. Mais pour comprendre qu'un accident est survenu, vous devez surveiller le projet et répondre aux incidents. Comment faire
Je pense que l'organisation du bon système de surveillance est en difficulté. S'il n'y a pas eu de problème, mon discours a consisté en une thèse: "Veuillez installer Prometheus + Grafana et les plugins 1, 2, 3." Malheureusement, cela ne fonctionne pas maintenant. Et le principal problème est que tout le monde continue de croire en quelque chose qui existait en 2008, en termes de composants logiciels.
Concernant l'organisation du système de suivi, je risque de dire que ... des projets avec un suivi compétent n'existent pas. Et la situation est si mauvaise si quelque chose tombe, il y a un risque qu'elle passe inaperçue - tout le monde est sûr que «tout est surveillé».
Peut-être que tout est surveillé. Mais comment?
Nous sommes tous tombés sur une histoire similaire à la suivante: un certain devoop, un certain administrateur travaille, une équipe de développement vient vers eux et dit: «nous l'avons, maintenant c'est surveillé.» Quel moniteur? Comment ça marche?
Ok Nous surveillons à l'ancienne. Mais cela est déjà en train de changer, et il s'avère que vous avez surveillé le service A, devenu le service B, qui interagit avec le service C. Mais l'équipe de développement vous dit: "Installez le logiciel, il faut tout surveiller!"
Alors qu'est-ce qui a changé? - Tout a changé!
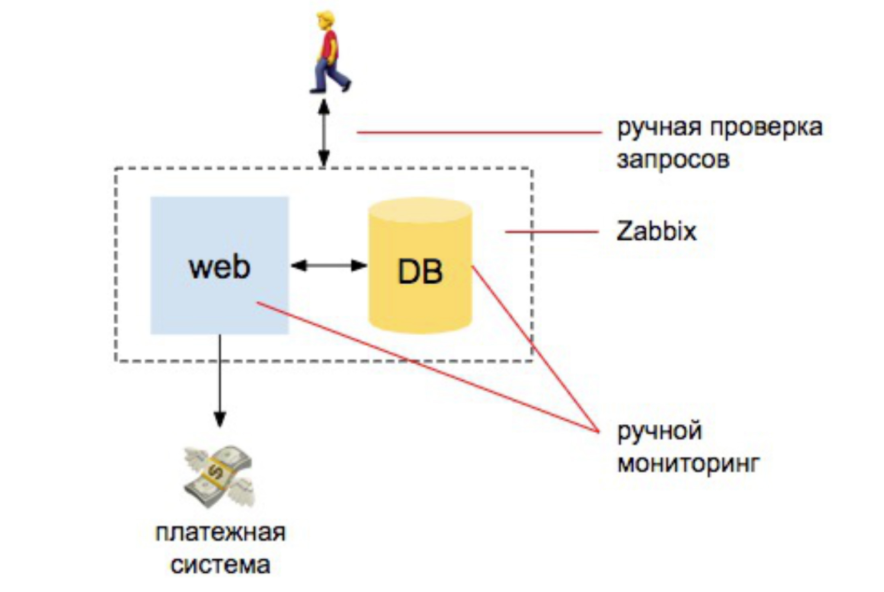
2008 année. Tout va bien
Il y a deux développeurs, un serveur, un serveur de base de données. De là, tout se passe. Nous avons quelques INFA, nous mettons zabbix, Nagios, cactus. Et puis nous avons défini des alertes claires sur le CPU, sur le fonctionnement des disques, sur la place sur les disques. Nous effectuons également quelques vérifications manuelles que le site répond que les commandes arrivent dans la base de données. Et c'est tout - nous sommes plus ou moins protégés.
Si nous comparons la quantité de travail que l'administrateur a fait pour assurer la surveillance, alors c'était 98% automatique: la personne qui surveille devrait comprendre comment installer Zabbix, comment le configurer et configurer les alertes. Et 2% - pour les contrôles externes: que le site réponde et demande à la base de données que de nouvelles commandes sont arrivées.
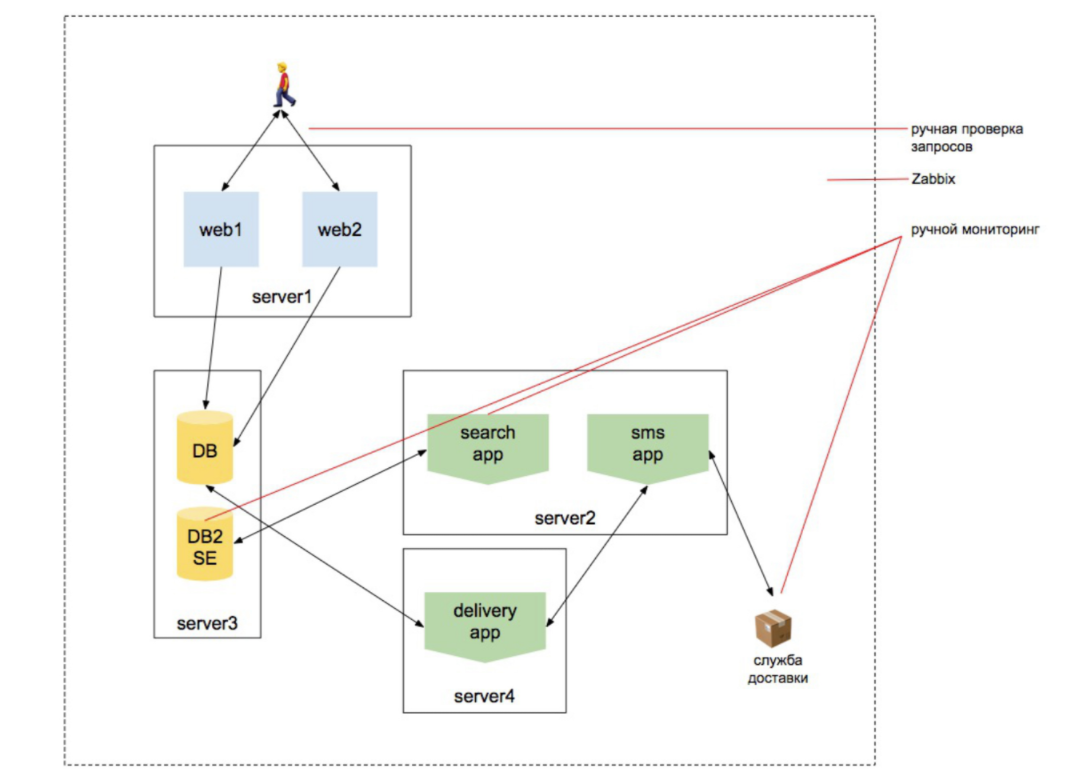
2010 année. La charge augmente
Nous commençons à faire évoluer le Web, à ajouter un moteur de recherche. Nous voulons être sûrs que le catalogue de produits contient tous les produits. Et cette recherche de produit fonctionne. Que la base de données fonctionne, que des commandes sont en cours, que le site répond en externe et répond à partir de deux serveurs, et que l'utilisateur n'est pas expulsé du site pendant qu'il se rééquilibre vers un autre serveur, etc. Il y a plus d'entités.
De plus, l’entité associée à l’infrastructure reste la plus importante de la tête du gestionnaire. L'idée me vient encore à l'esprit que la personne qui surveille est la personne qui va installer zabbix et pouvoir le configurer.
Mais en même temps, il y a des travaux sur la réalisation de contrôles externes, sur la création d'un ensemble de scripts pour interroger l'indexeur de recherche, un ensemble de scripts pour vérifier que la recherche change au cours du processus d'indexation, un ensemble de scripts qui vérifient que les marchandises sont transférées au service de livraison, etc. etc.

Remarque: j'ai écrit un «ensemble de scripts» 3 fois. Autrement dit, la personne responsable de la surveillance n'est plus celle qui installe simplement zabbix. C'est la personne qui commence à coder. Mais rien n'a encore changé dans l'esprit de l'équipe.
Mais le monde change, devenant de plus en plus compliqué. Une couche de virtualisation, plusieurs nouveaux systèmes sont ajoutés. Ils commencent à interagir les uns avec les autres. Qui a dit "ça sent bon les microservices?" Mais chaque service ressemble toujours individuellement à un site. Nous pouvons nous tourner vers lui et comprendre qu'il donne les informations nécessaires et travaille seul. Et si vous êtes un administrateur qui est constamment engagé dans un projet qui se développe depuis 5-7-10 ans, vous avez accumulé cette connaissance: un nouveau niveau apparaît - vous vous en êtes rendu compte, un autre niveau apparaît - vous l'avez réalisé ...
Mais rarement quelqu'un accompagne le projet pendant 10 ans.
Résumé de surveillance de l'homme
Supposons que vous soyez arrivé à une nouvelle startup qui a immédiatement marqué 20 développeurs, écrit 15 microservices et que vous êtes l'administrateur à qui on a dit: «Créez un CI / CD. S'il te plait. " Vous avez construit un CI / CD et soudain vous entendez: "Il est difficile pour nous de travailler avec la production dans le" cube "sans comprendre comment l'application fonctionnera. Faites-nous un bac à sable dans le même "cube".
Vous faites un bac à sable dans ce cube. Ils vous disent immédiatement: «Nous voulons une base de données de scène, qui est mise à jour quotidiennement à partir de la production, afin de comprendre qu'elle fonctionne sur la base de données, mais en même temps ne pas gâcher la base de données de production.»
Vous vivez dans tout cela. Il reste 2 semaines avant la sortie, ils vous disent: "Maintenant, tout serait surveillé ..." surveiller l'infrastructure de cluster, surveiller l'architecture des microservices, surveiller le travail avec les services externes ...
Et des collègues leur sortent un schéma si familier et disent: «Alors ici, tout est clair! Installez un programme qui surveille tout. » Oui: Prometheus + Grafana + plugins.
Et ils ajoutent en même temps: "Vous avez deux semaines, assurez-vous que tout est fiable."
Dans le tas de projets que nous voyons, une personne est affectée au suivi. Imaginez que nous voulons embaucher une personne pendant 2 semaines pour surveiller, et nous lui rédigerons un curriculum vitae. Quelles compétences cette personne devrait-elle posséder - compte tenu de tout ce que nous avons dit auparavant?
- Il doit comprendre le suivi et les spécificités du travail de l'infrastructure sidérurgique.
- Il doit comprendre les spécificités de la surveillance de Kubernetes (et tout le monde veut un «cube», car vous pouvez tout ignorer, vous cacher, car l'administrateur le comprendra) - en lui-même, son infrastructure et comprendre comment surveiller les applications à l'intérieur.
- Il doit comprendre que les services communiquent entre eux de façon particulière et connaître les spécificités de l'interaction des services entre eux. Il est assez réaliste de voir un projet dans lequel certains services communiquent de manière synchrone, car il n'y a pas d'autre moyen. Par exemple, le backend passe sur REST, sur gRPC au service de catalogue, reçoit une liste de marchandises et retourne. Vous ne pouvez pas attendre ici. Et avec d'autres services, il fonctionne de manière asynchrone. Transférer la commande au service de livraison, envoyer une lettre, etc.
Vous avez probablement déjà navigué de tout cela? Et l'administrateur, qui doit surveiller cela, a nagé encore plus. - Il doit être capable de planifier et de planifier correctement - car le travail devient de plus en plus.
- Il doit donc créer une stratégie à partir du service créé afin de comprendre comment le surveiller spécifiquement. Il a besoin d'une compréhension de l'architecture du projet et de son développement + compréhension des technologies utilisées dans le développement.
Rappelons un cas tout à fait normal: une partie des services en php, une partie des services en Go, une partie des services en JS. Ils travaillent en quelque sorte entre eux. C'est de là que vient le terme «microservice»: il y a tellement de systèmes séparés que les développeurs ne peuvent pas comprendre le projet dans son ensemble. Une partie de l'équipe écrit des services dans JS qui fonctionnent seuls et ne savent pas comment fonctionne le reste du système. L'autre partie écrit des services en Python et n'entre pas dans le fonctionnement des autres services, ils sont isolés dans leur domaine. Troisième - écrit des services en php ou autre chose.
Toutes ces 20 personnes sont divisées en 15 services, et il n'y a qu'un seul administrateur qui devrait comprendre tout cela. Arrête ça! nous venons de diviser le système en 15 microservices, car 20 personnes ne peuvent pas comprendre l'ensemble du système.
Mais cela doit être surveillé d'une manière ou d'une autre ...
Quel est le résultat? En conséquence, il y a une personne qui comprend tout ce que toute une équipe de développeurs ne peut pas comprendre, et pourtant il doit également savoir et être en mesure de ce que nous avons indiqué ci-dessus - infrastructure de fer, infrastructure de Kubernetes, etc.
Que puis-je dire ... Houston, nous avons des problèmes.
Le suivi d'un projet logiciel moderne est un projet logiciel en soi
Partant d'une fausse croyance selon laquelle la surveillance est un logiciel, nous croyons aux miracles. Mais les miracles, hélas, ne se produisent pas. Vous ne pouvez pas installer zabbix et attendre que tout fonctionne. Cela n'a aucun sens de mettre Grafana et d'espérer que tout ira bien. La plupart du temps sera consacré à l'organisation de contrôles sur le fonctionnement des services et leur interaction les uns avec les autres, sur le fonctionnement des systèmes externes. En fait, 90% du temps sera consacré non pas à l'écriture de scripts, mais au développement de logiciels. Et ce devrait être une équipe qui comprend le travail du projet.
Si, dans cette situation, une personne est renvoyée pour surveillance, des problèmes se produiront. Ce qui se passe partout.
Par exemple, il existe plusieurs services qui communiquent entre eux via Kafka. Une commande est arrivée, nous avons envoyé un message sur la commande à Kafka. Il existe un service qui écoute les informations sur la commande et effectue l'expédition des marchandises. Il existe un service qui écoute les informations sur la commande et envoie une lettre à l'utilisateur. Et puis il y a encore un tas de services, et on commence à se confondre.
Et si vous le donnez toujours à l'administrateur et aux développeurs à un stade où il reste peu de temps avant la sortie, une personne devra comprendre tout ce protocole. C'est-à-dire un projet de cette envergure prend beaucoup de temps et doit être intégré dans le développement du système.
Mais très souvent, en particulier lors de la gravure, dans les startups, nous voyons comment la surveillance est remise à plus tard. «Maintenant, nous allons faire la preuve de concept, nous allons commencer avec elle, la laisser tomber - nous sommes prêts à sacrifier. Et puis nous surveillerons tout cela. » Quand (ou si) le projet commence à gagner de l'argent, l'entreprise veut réduire encore plus de fonctionnalités - car il a commencé à fonctionner, vous devez donc aller plus loin! Et vous êtes au point où au début vous devez surveiller tout ce qui précède, ce qui ne prend pas 1% du temps, mais beaucoup plus. Et en passant, les développeurs auront besoin d'une surveillance, et il est plus facile de les intégrer dans de nouvelles fonctionnalités. En conséquence, de nouvelles fonctionnalités sont écrites, tout est terminé et vous êtes dans une impasse sans fin.
Alors, comment contrôlez-vous un projet depuis le début, et si vous avez un projet que vous devez surveiller, mais vous ne savez pas par où commencer?
Tout d'abord, vous devez planifier.
Digression lyrique: commence très souvent par la surveillance des infrastructures. Par exemple, nous avons Kubernetes. Pour commencer, nous mettons Prometheus avec Grafana, mettons les plugins sous la surveillance du "cube". Non seulement les développeurs, mais aussi les administrateurs ont une pratique malheureuse: "Nous allons installer ce plug-in, et le plug-in sait probablement comment le faire." Les gens aiment commencer par des actions simples et compréhensibles, plutôt que des actions importantes. Et la surveillance de l'infrastructure est facile.D'abord, décidez quoi et comment vous voulez surveiller, puis prenez l'instrument, car les autres ne peuvent pas penser à votre place. Oui, et devraient-ils? D'autres personnes ont pensé au système universel - ou n'ont pas pensé du tout quand ce plugin a été écrit. Et le fait que ce plugin compte 5 000 utilisateurs ne signifie pas qu'il apporte un quelconque avantage. Peut-être deviendrez-vous le 5001e simplement parce qu'il y avait déjà 5 000 personnes auparavant.
Si vous avez commencé à surveiller l'infrastructure et que le backend de votre application a cessé de répondre, tous les utilisateurs perdront le contact avec l'application mobile. Une erreur s'envolera. Ils viendront vers vous et vous diront: "L'application ne fonctionne pas, que faites-vous ici?" "Nous surveillons." - "Comment surveillez-vous si vous ne voyez pas que l'application ne fonctionne pas?!"
- Je pense qu'il est nécessaire de commencer la surveillance à partir du point d'entrée de l'utilisateur. Si l'utilisateur ne voit pas que l'application fonctionne - c'est tout, c'est un échec. Et le système de surveillance devrait en avertir en premier lieu.
- Et ce n'est qu'alors que nous pourrons surveiller l'infrastructure. Ou faites-le en parallèle. L'infrastructure est plus simple - ici, nous pouvons enfin simplement installer zabbix.
- Et maintenant, vous devez aller aux racines de l'application pour comprendre où cela ne fonctionne pas.
Ma principale pensée est que le suivi devrait aller en parallèle avec le processus de développement. Si vous détachez l'équipe de surveillance pour d'autres tâches (création d'un CI / CD, bacs à sable, réorganisation de l'infrastructure), la surveillance commencera à être à la traîne et vous ne pourrez jamais rattraper le développement (ou tôt ou tard, il devra être arrêté).
Tout par niveaux
C'est ainsi que je vois l'organisation du système de surveillance.
1) Niveau d'application:
- surveiller la logique métier de l'application;
- surveiller les paramètres de santé des services;
- surveillance de l'intégration.
2) Niveau d'infrastructure:
- surveiller le niveau d'orchestration;
- logiciel de système de surveillance;
- surveiller le niveau de "fer".
3) Encore une fois, le niveau d'application - mais en tant que produit d'ingénierie:
- collecte et surveillance des journaux d'application;
- APM
- traçage.
4) Alerte:
- organisation d'un système d'alerte;
- organisation d'un système de veille;
- organisation d'une "base de connaissances" et traitement des incidents de workflow.
Important : nous arrivons à l'alerte non pas après, mais immédiatement! Il n'est pas nécessaire de commencer la surveillance et «en quelque sorte plus tard» de penser à qui recevra les alertes. Après tout, quelle est la tâche de surveillance: comprendre où quelque chose ne fonctionne pas dans le système et en informer les bonnes personnes. Si cela est laissé à la fin, les bonnes personnes découvriront que quelque chose ne va pas, seulement en appelant "rien ne fonctionne pour nous".
Couche d'application - Surveillance de la logique métier
Ici, nous parlons de vérifier le fait que l'application fonctionne pour l'utilisateur.
Ce niveau doit être effectué au stade de la conception. Par exemple, nous avons un Prométhée conditionnel: il rampe vers le serveur qui est engagé dans les vérifications, extrait le point de terminaison et le point de terminaison va vérifier l'API.
Lorsqu'on leur demande souvent de surveiller la page principale pour s'assurer que le site fonctionne, les programmeurs donnent un stylo qui peut être tiré à chaque fois que vous devez vous assurer que l'API fonctionne. Et les programmeurs en ce moment prennent et écrivent toujours / api / test / helloworld
La seule façon de vous assurer que tout fonctionne? - Non!
- La création de tels contrôles est essentiellement la tâche des développeurs. Les tests unitaires doivent être écrits par des programmeurs qui écrivent du code. Parce que si vous fusionnez cela dans l'admin "Mec, voici une liste de protocoles API pour les 25 fonctions, veuillez tout surveiller!" - rien ne fonctionnera.
- Si vous imprimez «bonjour le monde», personne ne saura jamais que l'API devrait et fonctionne vraiment. Chaque modification de l'API doit entraîner une modification des contrôles.
- Si vous avez déjà une telle catastrophe, arrêtez les fonctionnalités et sélectionnez les développeurs qui écriront ces chèques, ou conciliez avec les pertes, conciliez que rien n'est vérifié et tombera.
Conseils techniques:
- Assurez-vous d'organiser un serveur externe pour organiser les inspections - vous devez être sûr que votre projet est accessible au monde extérieur.
- Organisez la validation sur l'ensemble du protocole API, pas seulement sur les points de terminaison individuels.
- Créez un point final prometheus avec les résultats des tests.
Niveau d'application - Surveillance des métriques d'intégrité
Nous parlons maintenant de mesures de santé externes des services.
Nous avons décidé de surveiller tous les «stylos» de l'application à l'aide de vérifications externes que nous appelons à partir d'un système de surveillance externe. Mais ce sont précisément les «stylos» que l'utilisateur «voit». Nous voulons être sûrs que les services eux-mêmes fonctionnent pour nous. Voici une meilleure histoire: K8s a des contrôles de santé afin qu'au moins le cube s'assure que le service fonctionne. Mais la moitié des chèques que j'ai vus sont la même impression «bonjour le monde». C'est-à-dire ici il tire une fois après le déploiement, il lui a répondu que tout allait bien - et c'est tout. Et le service, s'il repose sur sa propre API, possède un grand nombre de points d'entrée pour la même API, qui doit également être surveillée, car nous voulons savoir qu'elle fonctionne. Et nous le surveillons déjà à l'intérieur.
Comment l'implémenter correctement techniquement: chaque service définit un point de terminaison sur ses performances actuelles, et dans les graphiques de Grafana (ou de toute autre application), nous voyons l'état de tous les services.
- Chaque modification de l'API doit entraîner une modification des contrôles.
- Créez immédiatement un nouveau service avec des mesures de santé.
- L'administrateur peut s'adresser aux développeurs et demander "ajoutez-moi quelques fonctionnalités pour que je comprenne tout et ajoute des informations à ce sujet à mon système de surveillance". Mais les développeurs répondent généralement: «Nous n’ajouterons rien deux semaines avant la sortie.»
Faites savoir aux responsables du développement qu'il y aura de telles pertes, informez également les patrons des responsables du développement. Parce que quand tout tombera, quelqu'un continuera d'appeler et d'exiger de surveiller le "service en baisse constante" (c) - Soit dit en passant, sélectionnez les développeurs pour écrire des plugins pour Grafana - ce sera une bonne aide pour les administrateurs.
Couche d'application - Surveillance de l'intégration
La surveillance de l'intégration se concentre sur la surveillance de la communication entre les systèmes critiques de l'entreprise.
Par exemple, 15 services communiquent entre eux. Ce ne sont plus des sites individuels. C'est-à-dire nous ne pouvons pas tirer le service seul, obtenir / helloworld et comprendre que le service fonctionne. Parce que le service Web pour passer une commande doit envoyer des informations sur la commande au bus - le service d'entrepôt doit recevoir ce message du bus et travailler avec lui. Et le service de distribution de courrier électronique devrait gérer cela d'une manière ou d'une autre, etc.
En conséquence, nous ne pouvons pas comprendre, en poussant à chaque service individuel, que tout cela fonctionne. Parce que nous avons un certain bus à travers lequel tout communique et interagit.
Par conséquent, cette étape doit indiquer l'étape de test des services pour interagir avec d'autres services. Après avoir surveillé un courtier de messages, vous ne pouvez pas organiser la surveillance de la communication. S'il existe un service qui émet des données et un service qui les reçoit, lors de la surveillance d'un courtier, nous ne verrons que les données qui volent d'un côté à l'autre. Même si nous avons réussi à surveiller l'interaction de ces données à l'intérieur - que certains producteurs publient les données, quelqu'un les lit, ce flux continue à aller à Kafka - il ne nous donnera toujours pas d'informations si un service a donné un message dans une version, mais un autre service ne s'attendait pas à cette version et l'a sautée. Nous ne le saurons pas, car les services nous diront que tout fonctionne.
Comme je le recommande:
- Pour la communication synchrone: le point d'extrémité exécute les demandes de services associés. C'est-à-dire nous prenons ce point de terminaison, tirons le script à l'intérieur du service, qui va à tous les points et dit "Je peux y tirer et tirer là, je peux tirer ..."
- Pour la communication asynchrone: messages entrants - le point final vérifie le bus pour les messages de test et affiche l'état du traitement.
- Pour la communication asynchrone: messages sortants - le point d'extrémité envoie des messages de test au bus.
Comme d'habitude: nous avons un service qui envoie des données sur le bus. Nous venons à ce service et vous demandons de parler de sa santé d'intégration. Et si le service doit vendre un message quelque part plus loin (WebApp), il produira ce message de test. Et si nous tirons le service du côté du traitement des commandes, il publie d'abord quelque chose qu'il peut publier indépendamment, et s'il y a des choses dépendantes, il lit ensuite un ensemble de messages de test à partir du bus, comprend qu'il peut les traiter, le signaler et , si nécessaire, postez-les plus loin, et à ce sujet, il dit - tout va bien, je suis vivant.
Très souvent, nous entendons la question "comment pouvons-nous tester cela sur les données de combat?" Par exemple, nous parlons du même service de commande. La commande envoie des messages à l'entrepôt où les marchandises sont débitées: nous ne pouvons pas tester cela sur les données de combat, car "mes marchandises seront débitées!" Quitter: au stade initial, planifier tout ce test. Vous avez des tests unitaires qui se moquent. Alors, faites-le à un niveau plus profond, où vous aurez un canal de communication qui ne nuira pas à l'entreprise.
Niveau infrastructure
La surveillance des infrastructures est ce qui a longtemps été considéré comme la surveillance elle-même.
- La surveillance des infrastructures peut et doit être lancée en tant que processus distinct.
- Vous ne devez pas commencer par surveiller l'infrastructure d'un projet en cours, même si vous le souhaitez vraiment. C'est une plaie pour tous les devops. «Je surveille d'abord le cluster, je surveille l'infrastructure» - c'est-à-dire Tout d'abord, il surveillera ce qui se trouve en dessous, mais il ne montera pas dans l'application. Parce que l'application est une chose incompréhensible pour la devopa. Ils lui ont divulgué cette information et il ne comprend pas comment cela fonctionne. Et il comprend l'infrastructure et commence par elle. Mais non - vous devez toujours surveiller l'application en premier.
- . , , - . on-call, , « ». .
-
:
- ELK. . - , .
- APM. APM (NewRelic, BlackFire, Datadog). , - , .
- Tracing. , . , tracing — . – ! . Jaeger/Zipkin
- : . Grafana. PagerDuty. (, …). ,
- : ( , ). Oncall : , , , — ( — , : , ). , — (« — »), .
- « » workflow : , , . , — ; .
, :
- — Prometheus + Grafana;
- — ELK;
- APM Tracing — Jaeger (Zipkin).
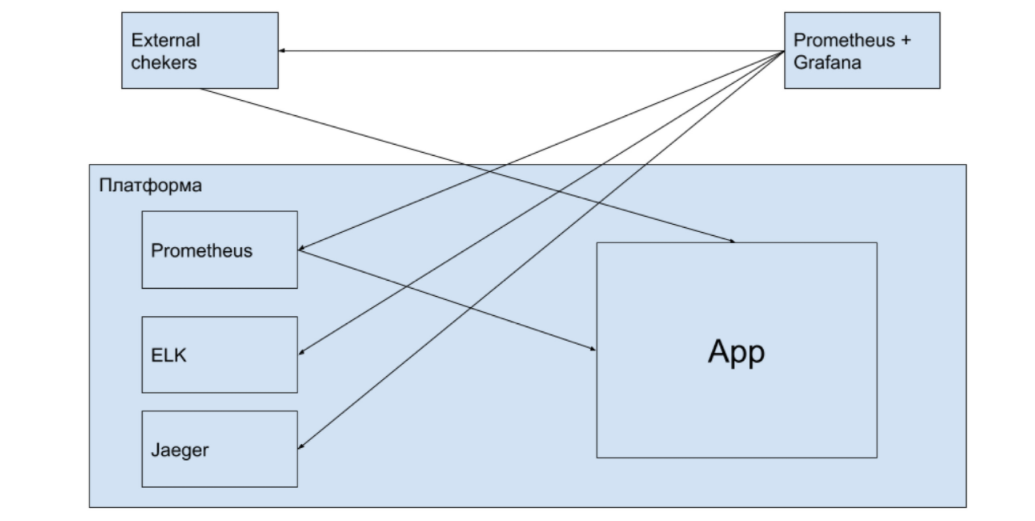
. , , , . , . , , , — .
, :
Prometheus Kubernetes — ?! , ? , , — , .
. . , Promtheus, , , . ? , , .
Conclusions
- — , . 98% — . , , , --.
- : 30% , .
- , , - , — . , — .
- ( ) — .
- , , « » — , .
Saint Highload++.UPD ( ):
1. , , , «, , , ». , : DevOps , — , , , .
2. Je n'essaie pas d'indiquer, disent-ils, "tout est mauvais partout, mais nous pouvons vous surveiller - venez à ITSumma." Non, si le projet est lancé, le suivi ne peut pas être effectué par une société tierce. Bien sûr, nous avons également des objectifs commerciaux, et ce que nous pensons vraiment faire est d'introduire la consultation pour soutenir le projet dans le processus de son développement afin de transmettre comment mener correctement la partie de suivi du développement.Si vous êtes intéressé par mes idées et réflexions à ce sujet et ainsi de suite, alors vous pouvez
lire la chaîne :-)