 Variti développe une protection contre les robots et les attaques DDoS, et effectue également des tests de stress et de charge. Lors de la conférence HighLoad ++ 2018, nous avons expliqué comment sécuriser les ressources contre différents types d'attaques. En bref: isoler des parties du système, utiliser les services cloud et CDN et mettre à jour régulièrement. Mais sans entreprises spécialisées, une protection que vous ne pouvez toujours pas faire :)
Variti développe une protection contre les robots et les attaques DDoS, et effectue également des tests de stress et de charge. Lors de la conférence HighLoad ++ 2018, nous avons expliqué comment sécuriser les ressources contre différents types d'attaques. En bref: isoler des parties du système, utiliser les services cloud et CDN et mettre à jour régulièrement. Mais sans entreprises spécialisées, une protection que vous ne pouvez toujours pas faire :)Avant de lire le texte, vous pouvez vous familiariser avec de courts résumés
sur le site Web de la conférence .
Et si vous n'aimez pas lire ou souhaitez simplement regarder une vidéo, l'enregistrement de notre reportage est ci-dessous sous le spoiler.
De nombreuses entreprises savent déjà faire des tests de résistance, mais toutes ne le font pas. Certains de nos clients pensent que leur site est invulnérable car ils disposent d'un système à haute charge et il protège contre les attaques. Nous montrons que ce n'est pas entièrement vrai.
Bien sûr, avant d'effectuer les tests, nous obtenons l'autorisation du client, signée et tamponnée, et avec notre aide, nous ne pouvons pas attaquer DDoS contre qui que ce soit. Les tests sont effectués à l'heure choisie par le client, lorsque la fréquentation de sa ressource est minimale, et les problèmes d'accès n'affecteront pas les clients. De plus, étant donné que quelque chose peut toujours mal tourner pendant le processus de test, nous avons un contact constant avec le client. Cela permet non seulement de rendre compte des résultats obtenus, mais aussi de changer quelque chose pendant le test. A l'issue des tests, nous établissons toujours un rapport dans lequel nous signalons les failles découvertes et formulons des recommandations pour éliminer les faiblesses du site.
Comment travaillons-nous
Pendant les tests, nous émulons un botnet. Puisque nous travaillons avec des clients qui ne sont pas situés dans nos réseaux, afin d'empêcher le test de se terminer dans la première minute en raison du déclenchement de limites ou de protection, nous chargeons la charge non pas à partir d'une IP, mais à partir de notre propre sous-réseau. De plus, pour créer une charge importante, nous avons notre propre serveur de test plutôt puissant.
Postulats
Beaucoup n'est pas bon
Moins nous pouvons amener la ressource à l'échec, mieux c'est. Si vous parvenez à faire en sorte que le site cesse de fonctionner à partir d'une demande par seconde, voire d'une demande par minute, ça va. Parce que selon la loi de la méchanceté, les utilisateurs ou les attaquants tombent accidentellement dans cette vulnérabilité.
Une défaillance partielle vaut mieux qu'une défaillance complète
Nous conseillons toujours de rendre les systèmes hétérogènes. De plus, il vaut la peine de les séparer au niveau physique, et pas seulement de la conteneurisation. Dans le cas d'une séparation physique, même si quelque chose échoue sur le site, il est probable que cela ne s'arrêtera pas complètement, et les utilisateurs auront toujours accès à au moins une partie de la fonctionnalité.
Une architecture appropriée est le fondement de la durabilité
La tolérance aux pannes d'une ressource et sa capacité à résister aux attaques et aux charges doivent être définies au stade de la conception, en fait, au stade du dessin des premiers schémas fonctionnels dans un cahier. Parce que si des erreurs fatales se glissent, vous pouvez les corriger à l'avenir, mais c'est très difficile.
Non seulement le code devrait être bon, mais aussi une config
Beaucoup de gens pensent qu'une bonne équipe de développement est une garantie de résilience du service. Une bonne équipe de développement est vraiment nécessaire, mais il doit aussi y avoir un bon fonctionnement, de bons DevOps. Autrement dit, nous avons besoin de spécialistes qui configurent correctement Linux et le réseau, écrivent correctement les configurations dans nginx, configurent les limites et plus encore. Sinon, la ressource ne fonctionnera bien que sur le test, et en production à un moment donné, tout se cassera.
Différences entre le stress et les tests de résistance
Les tests de charge vous permettent d'identifier les limites du système. Les tests de résistance visent à détecter les faiblesses du système et sont utilisés pour casser ce système et voir comment il se comportera en cas de défaillance de certaines pièces. Dans le même temps, la nature de la charge reste généralement inconnue du client jusqu'au début des tests de résistance.
Caractéristiques distinctives des attaques L7
Nous divisons généralement les types de charges en charges au niveau de L7 et L3 & 4. L7 est une charge au niveau de l'application, le plus souvent, elle est uniquement comprise comme HTTP, mais nous entendons toute charge au niveau du protocole TCP.
Les attaques L7 ont certaines caractéristiques distinctives. Premièrement, ils arrivent directement à l'application, c'est-à-dire qu'il est peu probable qu'ils puissent être reflétés par des moyens réseau. De telles attaques utilisent la logique et, de ce fait, elles consomment le processeur, la mémoire, le disque, la base de données et d'autres ressources très efficacement et avec peu de trafic.
Déluge HTTP
Dans le cas d'une attaque, la charge est plus facile à créer qu'à gérer, et dans le cas de L7, cela est également vrai. Le trafic d'attaque n'est pas toujours facile à distinguer de légitime, et le plus souvent il peut être fait par fréquence, mais si tout est correctement planifié, alors il est impossible de comprendre où est l'attaque et où les demandes légitimes proviennent des journaux.
Comme premier exemple, considérons une attaque HTTP Flood. Le graphique montre que de telles attaques sont généralement très puissantes, dans l'exemple ci-dessous, le nombre maximal de demandes dépassait 600 000 par minute.

HTTP Flood est le moyen le plus simple de créer une charge. Habituellement, une sorte d'outil de test de charge est utilisée pour cela, par exemple, ApacheBench, et la demande et le but sont définis. Avec une approche aussi simple, il est susceptible de se heurter à la mise en cache du serveur, mais il est facile de se déplacer. Par exemple, l'ajout de lignes aléatoires à la requête, ce qui oblige le serveur à donner constamment une nouvelle page.
N'oubliez pas non plus l'agent utilisateur dans le processus de création d'une charge. De nombreux agents utilisateurs des outils de test populaires sont filtrés par les administrateurs système et, dans ce cas, la charge peut tout simplement ne pas atteindre le backend. Vous pouvez améliorer considérablement le résultat en insérant un en-tête plus ou moins valide du navigateur dans la demande.
Pour toute sa simplicité, les attaques HTTP Flood ont leurs inconvénients. Premièrement, de grandes capacités sont nécessaires pour créer une charge. Deuxièmement, de telles attaques sont très faciles à détecter, surtout si elles proviennent de la même adresse. En conséquence, les demandes commencent immédiatement à être filtrées soit par les administrateurs système, soit même au niveau du fournisseur.
Que chercher
Pour réduire le nombre de demandes par seconde et ne pas perdre en efficacité, il faut faire preuve d'un peu d'imagination et explorer le site. Ainsi, vous pouvez charger non seulement le canal ou le serveur, mais également des parties individuelles de l'application, par exemple, des bases de données ou des systèmes de fichiers. Vous pouvez également rechercher des emplacements sur le site qui font de grands calculs: calculatrices, pages de sélection de produits, etc. Enfin, il arrive souvent qu'il existe sur le site un script php qui génère une page de plusieurs centaines de milliers de lignes. Un tel script charge également fortement le serveur et peut devenir une cible d'attaque.
Où chercher
Lorsque nous analysons une ressource avant de tester, nous examinons tout d'abord, bien sûr, le site lui-même. Nous recherchons toutes sortes de champs de saisie, des fichiers lourds - en général, tout ce qui peut créer des problèmes pour une ressource et ralentir son fonctionnement. Ici, les outils de développement courants de Google Chrome et Firefox permettent d'afficher le temps de réponse de la page.
Nous analysons également les sous-domaines. Par exemple, il existe une certaine boutique en ligne, abc.com, et elle a un sous-domaine admin.abc.com. Il s'agit très probablement du panneau d'administration avec autorisation, mais si vous y mettez une charge, cela peut créer des problèmes pour la ressource principale.
Le site peut avoir un sous-domaine api.abc.com. Il s'agit très probablement d'une ressource pour les applications mobiles. L'application peut être trouvée dans l'App Store ou Google Play, mettre un point d'accès spécial, disséquer l'API et enregistrer des comptes de test. Le problème est que souvent les gens pensent que tout ce qui est protégé par une autorisation est à l'abri des attaques par déni de service. Apparemment, l'autorisation est le meilleur CAPTCHA, mais ce n'est pas le cas. Créer des comptes de test 10-20 est simple, et en les créant, nous avons accès à des fonctionnalités complexes et non déguisées.
Naturellement, nous regardons l'historique, à robots.txt et WebArchive, ViewDNS, nous recherchons d'anciennes versions de la ressource. Parfois, il arrive que les développeurs déploient, disons, mail2.yandex.net, mais l'ancienne version, mail.yandex.net, est restée. Ce mail.yandex.net n'est plus pris en charge, les ressources de développement ne lui sont pas allouées, mais il continue de consommer la base de données. Par conséquent, en utilisant l'ancienne version, vous pouvez utiliser efficacement les ressources du backend et tout ce qui se trouve derrière la mise en page. Bien sûr, cela ne se produit pas toujours, mais nous rencontrons toujours quelque chose comme ça assez souvent.
Naturellement, nous disséquons tous les paramètres de demande, la structure des cookies. Vous pouvez, par exemple, pousser une valeur dans le tableau JSON à l'intérieur du cookie, créer plus d'imbrication et faire fonctionner la ressource de manière déraisonnablement longue.
Charge de recherche
La première chose qui vient à l'esprit lors de la recherche d'un site est de charger la base de données, car presque tout le monde a une recherche, et presque tout le monde, malheureusement, est mal protégé. Pour une raison quelconque, les développeurs ne prêtent pas assez d'attention à la recherche. Mais il y a une recommandation - ne faites pas le même type de demandes, car vous pouvez rencontrer la mise en cache, comme c'est le cas avec le déluge HTTP.
Les requêtes aléatoires dans la base de données ne sont pas non plus toujours efficaces. Il est préférable de créer une liste de mots clés pertinents pour la recherche. Si vous revenez à l'exemple d'une boutique en ligne: disons qu'un site vend des pneus de voiture et vous permet de définir le rayon des pneus, le type de voiture et d'autres paramètres. En conséquence, des combinaisons de mots pertinents feront fonctionner la base de données dans des conditions beaucoup plus complexes.
De plus, cela vaut la peine d'utiliser la pagination: il est beaucoup plus difficile pour une recherche de renvoyer l'avant-dernière page d'un problème que la première. Autrement dit, avec l'aide de la pagination, vous pouvez diversifier un peu la charge.
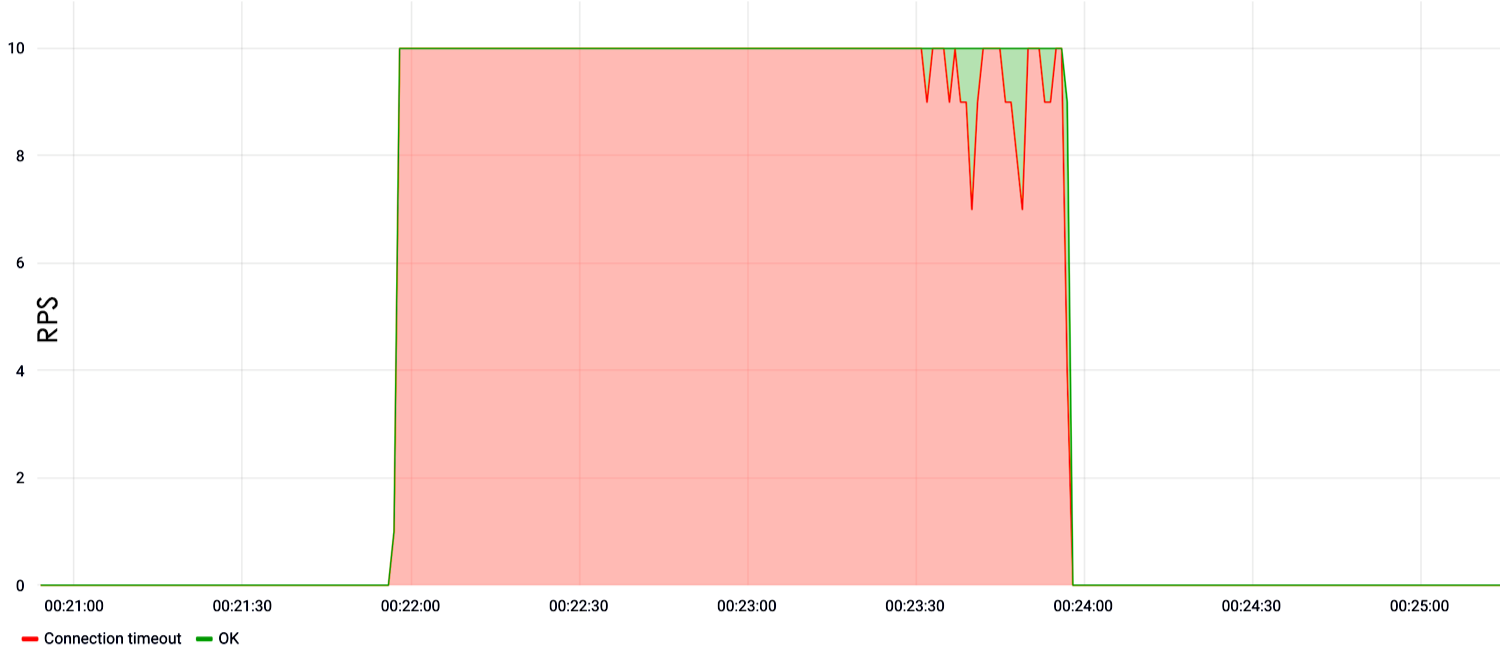
Dans l'exemple ci-dessous, nous montrons la charge dans la recherche. On voit que dès la première seconde du test à une vitesse de dix requêtes par seconde, le site est tombé en panne et n'a pas répondu.
S'il n'y a pas de recherche?
S'il n'y a pas de recherche, cela ne signifie pas que le site ne contient pas d'autres champs de saisie vulnérables. Ce champ peut être une autorisation. Désormais, les développeurs aiment créer des hachages complexes afin de protéger la base de données de connexion contre les attaques sur les tables arc-en-ciel. C'est bien, mais de tels hachages consomment de grandes ressources CPU. Un flux important de fausses autorisations entraîne une défaillance du processeur et, par conséquent, le site cesse de fonctionner sur la sortie.
La présence sur le site de toutes sortes de formulaires de commentaires et de retours d'expérience est l'occasion d'y envoyer de très gros textes ou simplement de créer un déluge massif. Parfois, les sites acceptent les pièces jointes, y compris au format gzip. Dans ce cas, nous prenons un fichier de 1 To, en utilisant gzip nous le compressons à quelques octets ou kilo-octets et l'envoyons sur le site. Ensuite, il est décompressé et un effet très intéressant est obtenu.
API Rest
Je voudrais faire un peu attention à des services aussi populaires que l'API Rest. La protection de l'API Rest est beaucoup plus difficile qu'un site classique. Pour l'API Rest, même des méthodes triviales de protection contre le craquage de mot de passe et d'autres activités illégitimes ne fonctionnent pas.
L'API Rest est très facile à casser car elle accède directement à la base de données. Dans le même temps, la défaillance d'un tel service entraîne des conséquences assez graves pour l'entreprise. Le fait est que l'API Rest implique généralement non seulement le site principal, mais également l'application mobile, certaines ressources commerciales internes. Et si tout cela tombe, alors l'effet est beaucoup plus fort que dans le cas de la défaillance d'un site simple.
Charge de contenu élevée
Si on nous propose de tester une application ordinaire d'une page, une page de destination, un site Web de carte de visite, qui ne possède pas de fonctionnalités complexes, nous recherchons du contenu lourd. Par exemple, de grandes images que le serveur donne, des fichiers binaires, de la documentation pdf - nous essayons de tout pomper. De tels tests chargent bien le système de fichiers et obstruent les canaux, et sont donc efficaces. Autrement dit, même si vous ne mettez pas le serveur hors tension, en téléchargeant un fichier volumineux à faible vitesse, vous obstruerez simplement le canal du serveur cible et un déni de service se produira.
Un exemple d'un tel test montre qu'à une vitesse de 30 RPS, le site a cessé de répondre ou a généré 500 erreurs de serveur.

N'oubliez pas de configurer des serveurs. Vous pouvez souvent constater qu'une personne a acheté une machine virtuelle, y a installé Apache, tout configuré par défaut, localisé une application php, et ci-dessous vous pouvez voir le résultat.

Ici, la charge est allée à la racine et ne représentait que 10 RPS. Nous avons attendu 5 minutes et le serveur s'est écrasé. À la fin, cependant, on ne sait pas pourquoi il est tombé, mais on suppose qu'il était simplement plein de mémoire et a donc cessé de répondre.
Basé sur les vagues
Au cours des deux dernières années, les attaques par vagues sont devenues très populaires. Cela est dû au fait que de nombreuses organisations achètent certains éléments matériels pour se protéger contre les DDoS, qui nécessitent une certaine quantité de statistiques pour commencer à filtrer les attaques. Autrement dit, ils ne filtrent pas l'attaque dans les 30 à 40 premières secondes, car ils accumulent des données et apprennent. Par conséquent, dans ces 30 à 40 secondes, vous pouvez lancer autant de ressources que la ressource restera longtemps longtemps jusqu'à ce que toutes les demandes soient ratissées.
Dans le cas de l'attaque, il y a eu un intervalle de 10 minutes plus bas, après quoi une nouvelle partie modifiée de l'attaque est arrivée.

Autrement dit, la défense s'est entraînée, a commencé à filtrer, mais une nouvelle portion complètement différente de l'attaque est arrivée, et la défense a recommencé à s'entraîner. En effet, le filtrage cesse de fonctionner, la protection devient inefficace et le site est inaccessible.
Les attaques par vagues se caractérisent par des valeurs très élevées au pic, elle peut atteindre cent mille ou un million de requêtes par seconde, dans le cas de L7. Si nous parlons de L3 et 4, il peut y avoir des centaines de gigabits de trafic, ou, en conséquence, des centaines de mpps, si vous comptez en paquets.
Le problème avec de telles attaques est la synchronisation. Les attaques proviennent d'un botnet et afin de créer un pic unique très important, un degré élevé de synchronisation est requis. Et cette coordination ne fonctionne pas toujours: parfois, la sortie est une sorte de pic parabolique, qui semble plutôt pathétique.
Non HTTP Unified
En plus de HTTP au niveau L7, nous adorons exploiter d'autres protocoles. En règle générale, un site Web régulier, en particulier un hébergement régulier, a des protocoles de messagerie et MySQL qui sort. Les protocoles de messagerie sont moins affectés que les bases de données, mais ils peuvent également être chargés assez efficacement et obtenir un processeur surchargé sur le serveur en sortie.
Avec l'aide de la vulnérabilité SSH 2016, nous avons réussi. Maintenant, cette vulnérabilité a été corrigée pour presque tout le monde, mais cela ne signifie pas que SSH ne peut pas être chargé. Tu peux. Juste une énorme charge d'autorisations est servie, SSH consomme presque tout le processeur sur le serveur, puis le site Web est déjà composé d'une ou deux demandes par seconde.
Par conséquent, ces une ou deux requêtes de journal ne peuvent pas être distinguées d'une charge légitime.
Les nombreuses connexions que nous ouvrons dans les serveurs restent pertinentes. Auparavant, Apache a péché, maintenant nginx a réellement péché, car il est souvent configuré par défaut. Le nombre de connexions que nginx peut garder ouvert est limité, nous ouvrons donc ce nombre de connexions, la nouvelle connexion nginx n'accepte plus et le site ne fonctionne pas en sortie.
Notre cluster de test possède suffisamment de CPU pour attaquer la négociation SSL. En principe, comme le montre la pratique, les botnets aiment aussi parfois le faire. D'une part, il est clair que vous ne pouvez pas vous passer de SSL, car l'émission, le classement et la sécurité de Google. SSL, d'autre part, a malheureusement un problème de processeur.
L3 & 4
Lorsque nous parlons d'une attaque au niveau L3 & 4, nous parlons généralement d'une attaque au niveau du canal. Une telle charge se distingue presque toujours de la légitime s'il ne s'agit pas d'une attaque par inondation SYN. Le problème des attaques par inondation SYN pour les fonctions de sécurité est important. La valeur maximale de L3 et 4 était de 1,5 à 2 To / s. Un tel trafic est très difficile à gérer même pour les grandes entreprises, notamment Oracle et Google.
SYN et SYN-ACK sont les packages utilisés pour établir la connexion. Par conséquent, il est difficile de distinguer SYN-flood d'une charge légitime: il n'est pas clair qu'il s'agit de SYN, qui est venu établir la connexion, ou une partie du déluge.
Inondation UDP
En général, les attaquants n'ont pas les capacités que nous avons, donc l'amplification peut être utilisée pour organiser des attaques. Autrement dit, un attaquant scanne Internet et trouve des serveurs vulnérables ou mal configurés qui, par exemple, en réponse à un paquet SYN, répondent avec trois SYN-ACK. En simulant l'adresse source à partir de l'adresse du serveur cible, vous pouvez utiliser un package pour augmenter la capacité, disons, trois fois, et rediriger le trafic vers la victime.

Le problème des amplifications est leur détection complexe. À partir des derniers exemples, nous pouvons citer le cas sensationnel avec le memcached vulnérable. De plus, il existe maintenant de nombreux appareils IoT, des caméras IP, qui sont également principalement configurés par défaut, et par défaut, ils sont configurés de manière incorrecte.Par conséquent, grâce à de tels appareils, les attaquants font le plus souvent des attaques.

SYN-flood difficile
SYN-flood est probablement la vue la plus intéressante de toutes les attaques du point de vue du développeur. Le problème est que les administrateurs système utilisent souvent le blocage IP pour la protection. De plus, le blocage IP affecte non seulement les administrateurs système qui fonctionnent selon des scripts, mais, malheureusement, certains systèmes de sécurité achetés pour beaucoup d'argent.
Cette méthode peut se transformer en catastrophe, car si les attaquants modifient leurs adresses IP, l'entreprise bloquera son propre sous-réseau. Lorsque le pare-feu bloque son propre cluster, les interactions externes se bloquent à la sortie et la ressource s'arrête.
Et il est facile de bloquer votre propre réseau. Si le bureau du client dispose d'un réseau Wi-Fi, ou si la santé des ressources est mesurée à l'aide de diverses surveillances, nous prenons l'adresse IP de ce système de surveillance ou client Wi-Fi de bureau, et nous l'utilisons comme source. En sortie, la ressource semble être disponible, mais les adresses IP cibles sont bloquées. Ainsi, le réseau Wi-Fi de la conférence HighLoad, où un nouveau produit de l'entreprise est présenté, peut être bloqué, ce qui entraîne certains coûts commerciaux et économiques.
Pendant les tests, nous ne pouvons pas utiliser l'amplification via memcached par certaines ressources externes, car il existe des accords pour fournir du trafic uniquement aux adresses IP autorisées. En conséquence, nous utilisons l'amplification via SYN et SYN-ACK, lorsque le système répond avec deux ou trois SYN-ACK pour envoyer un SYN et que la sortie est multipliée par deux à trois fois.
Les outils
L'un des principaux outils que nous utilisons pour la charge au niveau L7 est le réservoir Yandex. En particulier, un fantôme est utilisé comme pistolet, et il existe plusieurs scripts pour générer des cartouches et analyser les résultats.
Tcpdump est utilisé pour analyser le trafic réseau et Nmap est utilisé pour analyser le trafic du serveur. Pour créer une charge au niveau L3 & 4, OpenSSL est utilisé et un peu de sa propre magie avec la bibliothèque DPDK. DPDK est une bibliothèque d'Intel qui vous permet de travailler avec une interface réseau, en contournant la pile Linux, et ainsi d'augmenter l'efficacité. Naturellement, nous utilisons DPDK non seulement au niveau L3 & 4, mais aussi au niveau L7, car il vous permet de créer un flux de charge très élevé, en quelques millions de requêtes par seconde à partir d'une machine.
Nous utilisons également certains générateurs de trafic et des outils spéciaux que nous écrivons pour des tests spécifiques. Si nous rappelons la vulnérabilité sous SSH, alors avec l'ensemble ci-dessus, elle ne peut pas être échappée. Si nous attaquons le protocole de messagerie, nous prenons des utilitaires de messagerie ou écrivons simplement des scripts dessus.
Conclusions
En conséquence, je voudrais dire:
- En plus des tests de charge classiques, des tests de contrainte doivent également être effectués. Nous avons un exemple concret où un sous-traitant partenaire n'a effectué que des tests de charge. Il a montré que la ressource résiste à la charge standard. Mais alors une charge anormale est apparue, les visiteurs du site ont commencé à utiliser la ressource un peu différemment, et en fin de compte le sous-traitant s'est fixé. Ainsi, il vaut la peine de rechercher des vulnérabilités même si vous êtes déjà protégé contre les attaques DDoS.
- Il est nécessaire d'isoler certaines parties du système des autres. , , . , - . - , , , , OAuth2.
- .
- CDN , .
- . L3&4 , , , . L7 , . , - , .
- . , SSH daemon, . , , .