Nous avons déjà fait la connaissance du
moteur d'indexation PostgreSQL et de l'interface des méthodes d'accès et discuté
des index de hachage ,
des arbres B , ainsi que des
index GiST et
SP-GiST . Et cet article présentera l'index GIN.
Gin
"Gin? ... Le Gin est, semble-t-il, une telle liqueur américaine? .."
"Je ne suis pas un verre, oh, garçon curieux!" le vieil homme s'embrasa de nouveau, il se rendit compte de nouveau et se reprit en main. "Je ne suis pas un verre, mais un esprit puissant et intrépide, et il n'y a pas une telle magie dans le monde que je ne pourrais pas faire."- Lazar Lagin, «Old Khottabych».
Gin signifie Index généralisé inversé et doit être considéré comme un génie, pas comme une boisson.-
LISEZ -
MOIConcept général
GIN est l'index inversé généralisé abrégé. Il s'agit d'un soi-disant
index inversé . Il manipule des types de données dont les valeurs ne sont pas atomiques, mais constituées d'éléments. Nous appellerons ces types composés. Et ce ne sont pas les valeurs qui sont indexées, mais les éléments individuels; chaque élément fait référence aux valeurs dans lesquelles il se produit.
Une bonne analogie avec cette méthode est l'index à la fin d'un livre qui, pour chaque terme, fournit une liste de pages où ce terme apparaît. La méthode d'accès doit assurer une recherche rapide des éléments indexés, tout comme l'index dans un livre. Par conséquent, ces éléments sont stockés sous la forme d'un
arbre B familier (une implémentation différente et plus simple est utilisée pour cela, mais cela n'a pas d'importance dans ce cas). Un ensemble ordonné de références aux lignes de table qui contiennent des valeurs composées avec l'élément est lié à chaque élément. L'ordre n'est pas essentiel pour la récupération des données (l'ordre de tri des TID ne signifie pas grand-chose), mais il est important pour la structure interne de l'index.
Les éléments ne sont jamais supprimés de l'index GIN. On suppose que les valeurs contenant des éléments peuvent disparaître, apparaître ou varier, mais l'ensemble des éléments qui les composent est plus ou moins stable. Cette solution simplifie considérablement les algorithmes pour le travail simultané de plusieurs processus avec l'index.
Si la liste des TID est assez petite, elle peut tenir dans la même page que l'élément (et s'appelle "la liste de publication"). Mais si la liste est grande, une structure de données plus efficace est nécessaire, et nous en sommes déjà conscients - c'est à nouveau B-tree. Un tel arbre est situé sur des pages de données distinctes (et est appelé "l'arbre de publication").
Ainsi, l'index GIN se compose de l'arbre B des éléments, et les arbres B ou les listes plates de TID sont liés aux rangées de feuilles de cet arbre B.
Tout comme les index GiST et SP-GiST, discutés précédemment, GIN fournit à un développeur d'applications l'interface pour prendre en charge diverses opérations sur des types de données composés.
Recherche plein texte
Le principal domaine d'application de la méthode GIN est l'accélération de la recherche en texte intégral, ce qui est donc raisonnable à utiliser comme exemple dans une discussion plus détaillée de cet index.
L'article relatif à GiST a déjà fourni une petite introduction à la recherche en texte intégral, alors allons droit au but sans répétitions. Il est clair que les valeurs composées dans ce cas sont des
documents , et les éléments de ces documents sont des
lexèmes .
Prenons l'exemple de l'article lié à GiST:
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc); postgres=# create index on ts using gin(doc_tsv);
Une structure possible de cet indice est illustrée dans la figure:
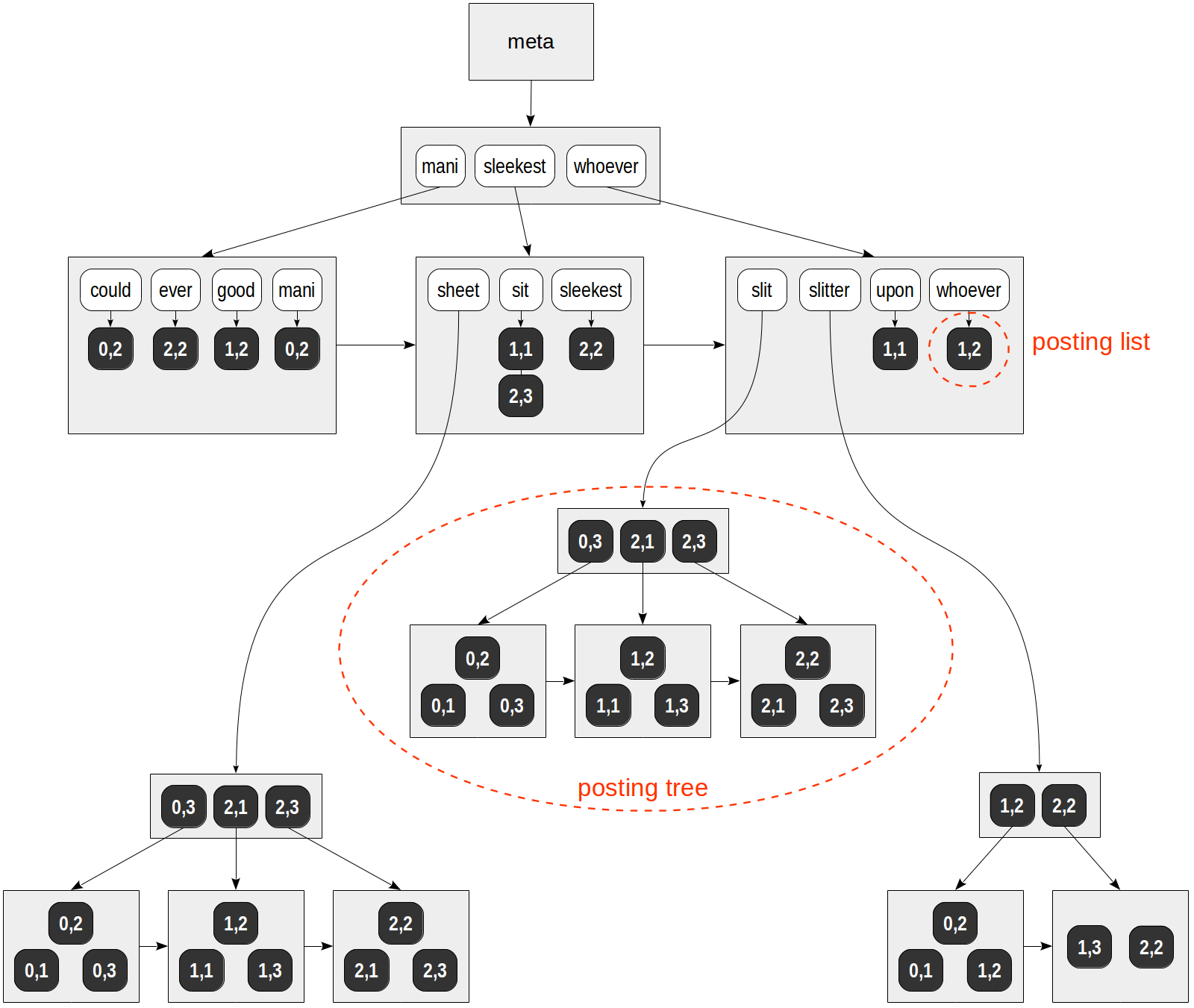
Contrairement à toutes les figures précédentes, les références aux lignes du tableau (TID) sont indiquées par des valeurs numériques sur fond sombre (le numéro de page et la position sur la page) plutôt que par des flèches.
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
Dans cet exemple spéculatif, la liste des TID tient dans des pages normales pour tous les lexèmes sauf "sheet", "slit" et "slitter". Ces lexèmes se sont produits dans de nombreux documents, et les listes de TID pour eux ont été placées dans des arbres B individuels.
Au fait, comment savoir combien de documents contiennent un lexème? Pour une petite table, une technique «directe», illustrée ci-dessous, fonctionnera, mais nous apprendrons plus loin quoi faire avec les plus grandes.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count ----------+------- sheet | 9 slit | 8 slitter | 5 sit | 2 upon | 1 mani | 1 whoever | 1 sleekest | 1 good | 1 could | 1 ever | 1 (11 rows)
Notez également que contrairement à un arbre B normal, les pages d'index GIN sont connectées par une liste unidirectionnelle plutôt que bidirectionnelle. Ceci est suffisant car une traversée d'arbre ne se fait que dans un sens.
Exemple de requête
Comment la requête suivante sera-t-elle exécutée pour notre exemple?
postgres=# explain(costs off) select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) (4 rows)
Les lexèmes individuels (clés de recherche) sont extraits de la requête en premier: "mani" et "slitter". Cela se fait par une fonction API spécialisée qui prend en compte le type de données et la stratégie déterminés par la classe d'opérateur:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'tsvector_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- @@(tsvector,tsquery) | 1 matching search query @@@(tsvector,tsquery) | 2 synonym for @@ (for backward compatibility) (2 rows)
Dans l'arborescence B des lexèmes, nous trouvons ensuite les deux clés et parcourons les listes prêtes de TID. Nous obtenons:
pour "mani" - (0,2).
pour «refendeuse» - (0,1), (0,2), (1,2), (1,3), (2,2).
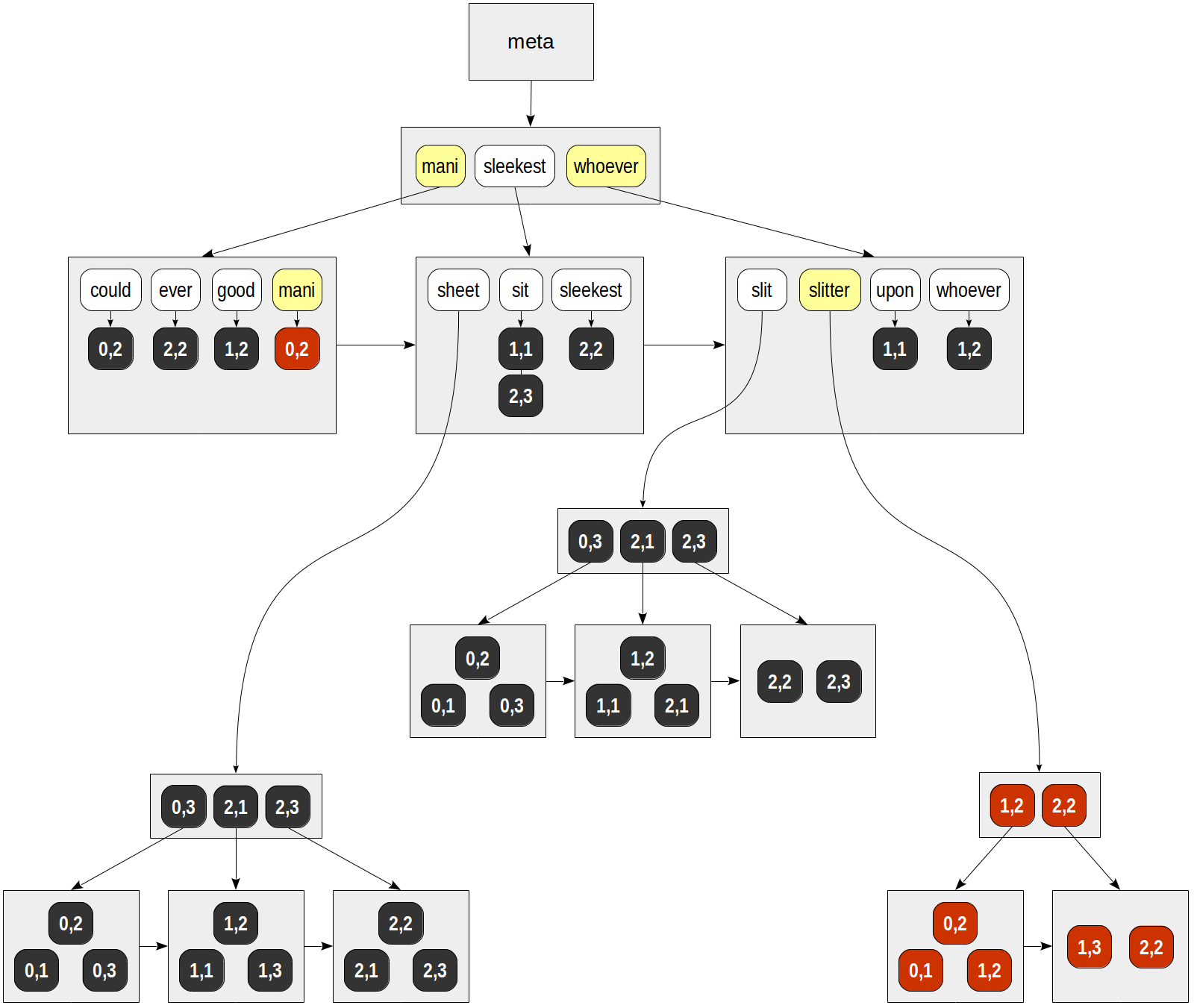
Enfin, pour chaque TID trouvé, une fonction de cohérence API est appelée, qui doit déterminer laquelle des lignes trouvées correspond à la requête de recherche. Puisque les lexèmes de notre requête sont joints par des booléens "et", la seule ligne renvoyée est (0,2):
| | | consistency | | | function TID | mani | slitter | slit & slitter -------+------+---------+---------------- (0,1) | f | T | f (0,2) | T | T | T (1,2) | f | T | f (1,3) | f | T | f (2,2) | f | T | f
Et le résultat est:
postgres=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc --------------------------------------------- How many sheets could a sheet slitter slit? (1 row)
Si nous comparons cette approche avec celle déjà discutée pour GiST, l'avantage de GIN pour la recherche en texte intégral apparaît évident. Mais il y a plus que cela à l'œil nu.
La question d'une mise à jour lente
Le fait est que l'insertion ou la mise à jour des données dans l'index GIN est assez lente. Chaque document contient généralement de nombreux lexèmes à indexer. Par conséquent, lorsqu'un seul document est ajouté ou mis à jour, nous devons mettre à jour massivement l'arborescence d'index.
D'un autre côté, si plusieurs documents sont mis à jour simultanément, certains de leurs lexèmes peuvent être les mêmes, et la quantité totale de travail sera plus petite que lors de la mise à jour des documents un par un.
L'index GIN a un paramètre de stockage "fastupdate", que nous pouvons spécifier lors de la création et de la mise à jour de l'index plus tard:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
Lorsque ce paramètre est activé, les mises à jour seront accumulées dans une liste distincte non triée (sur les pages individuelles connectées). Lorsque cette liste devient suffisamment grande ou lors de la mise à vide, toutes les mises à jour accumulées sont instantanément apportées à l'index. La liste à considérer comme "suffisamment grande" est déterminée par le paramètre de configuration "gin_pending_list_limit" ou par le paramètre de stockage du même nom de l'index.
Mais cette approche présente des inconvénients: premièrement, la recherche est ralentie (car la liste non ordonnée doit être consultée en plus de l'arborescence), et deuxièmement, une prochaine mise à jour peut prendre de manière inattendue beaucoup de temps si la liste non ordonnée a été débordée.
Recherche d'une correspondance partielle
Nous pouvons utiliser une correspondance partielle dans la recherche en texte intégral. Par exemple, considérez la requête suivante:
gin=# select doc from ts where doc_tsv @@ to_tsquery('slit:*');
doc -------------------------------------------------------- Can a sheet slitter slit sheets? How many sheets could a sheet slitter slit? I slit a sheet, a sheet I slit. Upon a slitted sheet I sit. Whoever slit the sheets is a good sheet slitter. I am a sheet slitter. I slit sheets. I am the sleekest sheet slitter that ever slit sheets. She slits the sheet she sits on. (9 rows)
Cette requête trouvera des documents contenant des lexèmes commençant par "fente". Dans cet exemple, ces lexèmes sont "fente" et "refendeur".
Une requête fonctionnera certainement de toute façon, même sans index, mais GIN permet également d'accélérer la recherche suivante:
postgres=# explain (costs off) select doc from ts where doc_tsv @@ to_tsquery('slit:*');
QUERY PLAN ------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) (4 rows)
Ici, tous les lexèmes ayant le préfixe spécifié dans la requête de recherche sont recherchés dans l'arborescence et joints par des booléens "ou".
Lexèmes fréquents et peu fréquents
Pour voir comment l'indexation fonctionne sur les données en direct, prenons l'archive des e-mails "pgsql-hackers", que nous avons déjà utilisés lors de la discussion sur GiST.
Cette version de l'archive contient 356125 messages avec la date d'envoi, le sujet, l'auteur et le texte.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
Prenons un lexème qui apparaît dans de nombreux documents. La requête utilisant "unnest" ne fonctionnera pas sur une si grande taille de données, et la bonne technique consiste à utiliser la fonction "ts_stat", qui fournit les informations sur les lexèmes, le nombre de documents où ils se sont produits et le nombre total d'occurrences.
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') order by ndoc desc limit 3;
word | ndoc -------+-------- re | 322141 wrote | 231174 use | 176917 (3 rows)
Choisissons "écrit".
Et nous prendrons un mot qui est peu fréquent pour le courrier électronique des développeurs, par exemple, "tatouage":
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc --------+------ tattoo | 2 (1 row)
Y a-t-il des documents où ces deux lexèmes se produisent? Il semble qu'il y ait:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row)
Une question se pose comment effectuer cette requête. Si nous obtenons des listes de TID pour les deux lexèmes, comme décrit ci-dessus, la recherche sera évidemment inefficace: nous devrons parcourir plus de 200 000 valeurs, dont une seule restera. Heureusement, en utilisant les statistiques du planificateur, l'algorithme comprend que le lexème "écrit" se produit fréquemment, tandis que "tatoo" se produit rarement. Par conséquent, la recherche du lexème peu fréquent est effectuée, et les deux documents récupérés sont ensuite vérifiés pour l'occurrence du lexème "écrit". Et cela ressort clairement de la requête, qui est effectuée rapidement:
fts=# \timing on fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row) Time: 0,959 ms
La recherche de "écrit" à lui seul prend beaucoup plus de temps:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count -------- 231174 (1 row) Time: 2875,543 ms (00:02,876)
Cette optimisation fonctionne certainement non seulement pour deux lexèmes, mais aussi dans des cas plus complexes.
Limiter le résultat de la requête
Une caractéristique de la méthode d'accès GIN est que le résultat est toujours renvoyé sous forme de bitmap: cette méthode ne peut pas renvoyer le résultat TID par TID. C'est pour cette raison que tous les plans de requête de cet article utilisent l'analyse bitmap.
Par conséquent, la limitation du résultat de l'analyse d'index à l'aide de la clause LIMIT n'est pas tout à fait efficace. Faites attention au coût prévu de l'opération (champ "coût" du nœud "Limite"):
fts=# explain (costs off) select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN ----------------------------------------------------------------------------------------- Limit (cost=1283.61..1285.13 rows=1) -> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207) Recheck Cond: (tsv @@ to_tsquery('wrote'::text)) -> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207) Index Cond: (tsv @@ to_tsquery('wrote'::text)) (5 rows)
Le coût est estimé à 1285.13, ce qui est un peu plus élevé que le coût de construction de la totalité du bitmap 1249.30 (champ "coût" du nœud Bitmap Index Scan).
Par conséquent, l'index a une capacité spéciale pour limiter le nombre de résultats. La valeur de seuil est spécifiée dans le paramètre de configuration "gin_fuzzy_search_limit" et est égale à zéro par défaut (aucune limitation n'a lieu). Mais nous pouvons définir la valeur seuil:
fts=# set gin_fuzzy_search_limit = 1000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 5746 (1 row)
fts=# set gin_fuzzy_search_limit = 10000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 14726 (1 row)
Comme nous pouvons le voir, le nombre de lignes renvoyées par la requête diffère pour différentes valeurs de paramètre (si l'accès à l'index est utilisé). La limitation n'est pas stricte: plus de lignes que spécifiées peuvent être retournées, ce qui justifie une partie "floue" du nom du paramètre.
Représentation compacte
Parmi les autres, les indices GIN sont bons grâce à leur compacité. Premièrement, si un même lexème apparaît dans plusieurs documents (et c'est généralement le cas), il n'est stocké dans l'index qu'une seule fois. Deuxièmement, les TID sont stockés dans l'index de manière ordonnée, ce qui nous permet d'utiliser une compression simple: chaque TID suivant dans la liste est réellement stocké comme sa différence par rapport au précédent; il s'agit généralement d'un petit nombre, ce qui nécessite beaucoup moins de bits qu'un TID complet à six octets.
Pour avoir une idée de la taille, construisons B-tree à partir du texte des messages. Mais une comparaison équitable ne va certainement pas se produire:
- GIN est construit sur un type de données différent ("tsvector" plutôt que "text"), qui est plus petit,
- en même temps, la taille des messages pour B-tree doit être réduite à environ deux kilo-octets.
Néanmoins, nous continuons:
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
Nous allons également construire l'index GiST:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
La taille des index sur "vide plein":
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin, pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist, pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree --------+--------+-------- 179 MB | 125 MB | 546 MB (1 row)
En raison de la compacité de la représentation, nous pouvons essayer d'utiliser l'index GIN lors de la migration depuis Oracle en remplacement des index bitmap (sans entrer dans les détails, je fournis
une référence à la publication de Lewis pour les esprits curieux). En règle générale, les index bitmap sont utilisés pour les champs qui ont peu de valeurs uniques, ce qui est également excellent pour GIN. Et, comme indiqué
dans le premier article , PostgreSQL peut créer un bitmap basé sur n'importe quel index, y compris GIN, à la volée.
GiST ou GIN?
Pour de nombreux types de données, les classes d'opérateurs sont disponibles pour GiST et GIN, ce qui pose la question de l'index à utiliser. Peut-être pouvons-nous déjà tirer quelques conclusions.
En règle générale, GIN bat GiST en termes de précision et de vitesse de recherche. Si les données ne sont pas mises à jour fréquemment et qu'une recherche rapide est nécessaire, le GIN sera très probablement une option.
D'un autre côté, si les données sont intensivement mises à jour, les frais généraux de mise à jour du GIN peuvent sembler trop élevés. Dans ce cas, il faudra comparer les deux options et choisir celle dont les caractéristiques sont mieux équilibrées.
Tableaux
L'indexation des tableaux est un autre exemple d'utilisation de GIN. Dans ce cas, les éléments du tableau entrent dans l'index, ce qui permet d'accélérer un certain nombre d'opérations sur les tableaux:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- &&(anyarray,anyarray) | 1 intersection @>(anyarray,anyarray) | 2 contains array <@(anyarray,anyarray) | 3 contained in array =(anyarray,anyarray) | 4 equality (4 rows)
Notre
base de données de démonstration a une vue "routes" avec des informations sur les vols. Parmi les autres, cette vue contient la colonne «days_of_week» - un tableau de jours de la semaine lorsque les vols ont lieu. Par exemple, un vol de Vnoukovo à Guelendjik part les mardis, jeudis et dimanches:
demo=# select departure_airport_name, arrival_airport_name, days_of_week from routes where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week ------------------------+----------------------+-------------- Vnukovo | Gelendzhik | {2,4,7} (1 row)
Pour construire l'index, "matérialisons" la vue dans une table:
demo=# create table routes_t as select * from routes; demo=# create index on routes_t using gin(days_of_week);
Maintenant, nous pouvons utiliser l'index pour connaître tous les vols qui partent les mardis, jeudis et dimanches:
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (4 rows)
Il semble qu'il y en ait six:
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week -----------+------------------------+----------------------+-------------- PG0005 | Domodedovo | Pskov | {2,4,7} PG0049 | Vnukovo | Gelendzhik | {2,4,7} PG0113 | Naryan-Mar | Domodedovo | {2,4,7} PG0249 | Domodedovo | Gelendzhik | {2,4,7} PG0449 | Stavropol | Vnukovo | {2,4,7} PG0540 | Barnaul | Vnukovo | {2,4,7} (6 rows)
Comment cette requête est-elle exécutée? Exactement de la même manière que celle décrite ci-dessus:
- À partir du tableau {2,4,7}, qui joue ici le rôle de la requête de recherche, des éléments (mots-clés de recherche) sont extraits. Évidemment, ce sont les valeurs de "2", "4" et "7".
- Dans l'arborescence des éléments, les clés extraites sont trouvées et pour chacune d'elles, la liste des TID est sélectionnée.
- De tous les TID trouvés, la fonction de cohérence sélectionne ceux qui correspondent à l'opérateur dans la requête. Pour l'opérateur
= , seuls les TID correspondent à ceux qui se sont produits dans les trois listes (en d'autres termes, le tableau initial doit contenir tous les éléments). Mais cela n'est pas suffisant: il est également nécessaire que le tableau ne contienne aucune autre valeur, et nous ne pouvons pas vérifier cette condition avec l'index. Par conséquent, dans ce cas, la méthode d'accès demande au moteur d'indexation de revérifier tous les TID retournés avec la table.
Il est intéressant de noter qu'il existe des stratégies (par exemple, "contenues dans un tableau") qui ne peuvent rien vérifier et doivent revérifier tous les TID trouvés avec la table.
Mais que faire si nous avons besoin de connaître les vols qui partent de Moscou les mardis, jeudis et dimanches? L'index ne prendra pas en charge la condition supplémentaire, qui entrera dans la colonne "Filtre".
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) Filter: (departure_city = 'Moscow'::text) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (5 rows)
Ici, c'est OK (l'index ne sélectionne que six lignes de toute façon), mais dans les cas où la condition supplémentaire augmente la capacité de sélection, il est souhaitable d'avoir un tel support. Cependant, nous ne pouvons pas simplement créer l'index:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin" HINT: You must specify an operator class for the index or define a default operator class for the data type.
Mais l'extension "
btree_gin " aidera, ce qui ajoute des classes d'opérateurs GIN qui simulent le travail d'un arbre B régulier.
demo=# create extension btree_gin; demo=# create index on routes_t using gin(days_of_week,departure_city); demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) -> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) (4 rows)
Jsonb
JSON est un autre exemple d'un type de données composé qui prend en charge GIN intégré. Pour travailler avec les valeurs JSON, un certain nombre d'opérateurs et de fonctions sont actuellement définis, dont certains peuvent être accélérés à l'aide d'index:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname in ('jsonb_ops','jsonb_path_ops') and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str ----------------+------------------+----- jsonb_ops | ?(jsonb,text) | 9 top-level key exists jsonb_ops | ?|(jsonb,text[]) | 10 some top-level key exists jsonb_ops | ?&(jsonb,text[]) | 11 all top-level keys exist jsonb_ops | @>(jsonb,jsonb) | 7 JSON value is at top level jsonb_path_ops | @>(jsonb,jsonb) | 7 (5 rows)
Comme nous pouvons le voir, deux classes d'opérateurs sont disponibles: "jsonb_ops" et "jsonb_path_ops".
La première classe d'opérateur "jsonb_ops" est utilisée par défaut. Toutes les clés, valeurs et éléments de tableau accèdent à l'index en tant qu'éléments du document JSON initial. Un attribut est ajouté à chacun de ces éléments, qui indique si cet élément est une clé (cela est nécessaire pour les stratégies "existe", qui distinguent les clés et les valeurs).
Par exemple, représentons quelques lignes de "routes" en JSON comme suit:
demo=# create table routes_jsonb as select to_jsonb(t) route from ( select departure_airport_name, arrival_airport_name, days_of_week from routes order by flight_no limit 4 ) t; demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty -------+------------------------------------------------- (0,1) | { + | "days_of_week": [ + | 1 + | ], + | "arrival_airport_name": "Surgut", + | "departure_airport_name": "Ust-Ilimsk" + | } (0,2) | { + | "days_of_week": [ + | 2 + | ], + | "arrival_airport_name": "Ust-Ilimsk", + | "departure_airport_name": "Surgut" + | } (0,3) | { + | "days_of_week": [ + | 1, + | 4 + | ], + | "arrival_airport_name": "Sochi", + | "departure_airport_name": "Ivanovo-Yuzhnyi"+ | } (0,4) | { + | "days_of_week": [ + | 2, + | 5 + | ], + | "arrival_airport_name": "Ivanovo-Yuzhnyi", + | "departure_airport_name": "Sochi" + | } (4 rows)
demo=# create index on routes_jsonb using gin(route);
L'index peut se présenter comme suit:
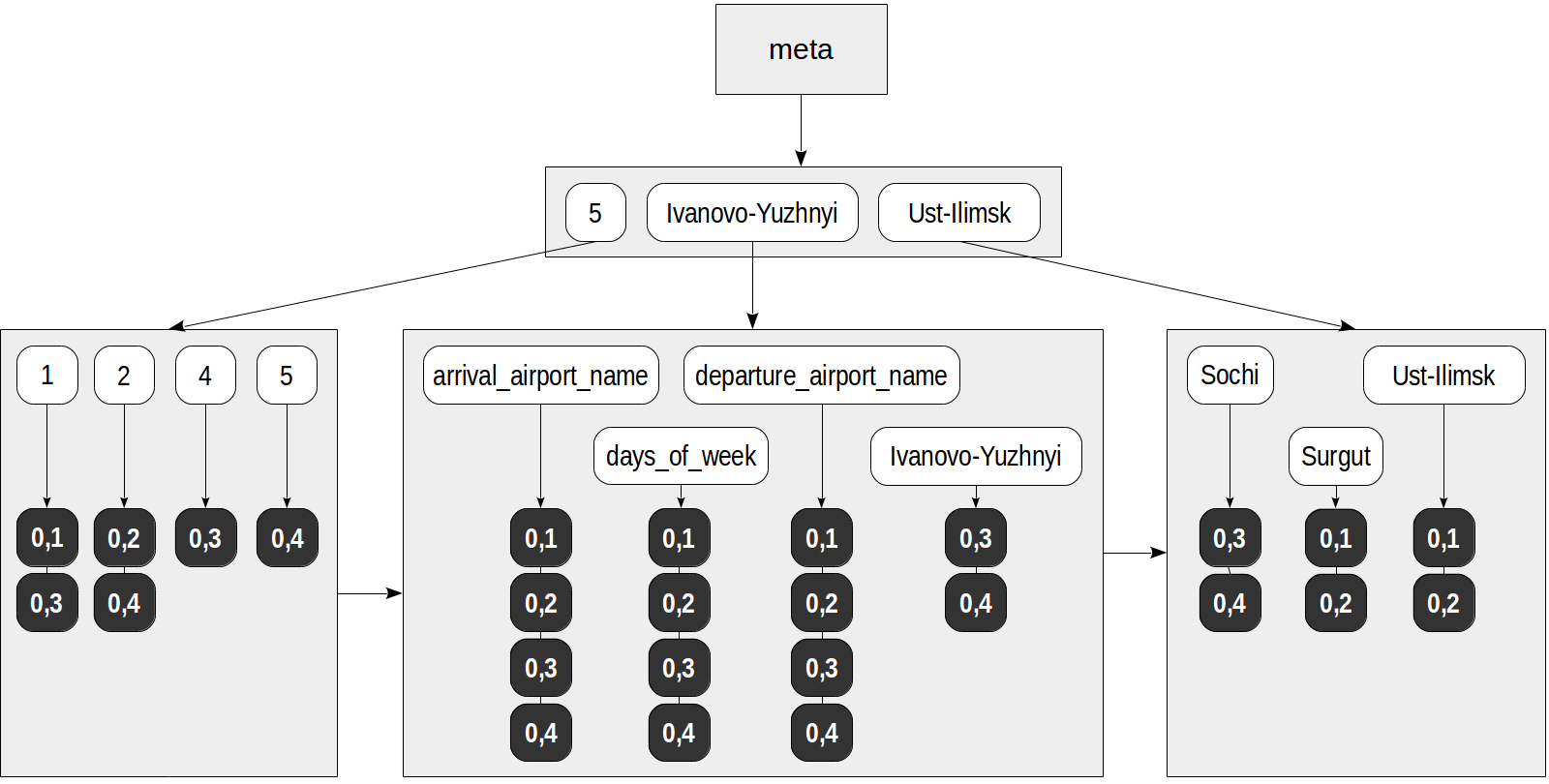
Maintenant, une requête comme celle-ci, par exemple, peut être effectuée à l'aide de l'index:
demo=# explain (costs off) select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
QUERY PLAN --------------------------------------------------------------- Bitmap Heap Scan on routes_jsonb Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb) -> Bitmap Index Scan on routes_jsonb_route_idx Index Cond: (route @> '{"days_of_week": [5]}'::jsonb) (4 rows)
En commençant par la racine du document JSON, l'opérateur
@> vérifie si l'itinéraire spécifié (
"days_of_week": [5] ) se produit. Ici, la requête renvoie une ligne:
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty ------------------------------------------------ { + "days_of_week": [ + 2, + 5 + ], + "arrival_airport_name": "Ivanovo-Yuzhnyi",+ "departure_airport_name": "Sochi" + } (1 row)
La requête est exécutée comme suit:
- Dans la requête de recherche (
"days_of_week": [5] ), des éléments (clés de recherche) sont extraits: "days_of_week" et "5".
- Dans l'arborescence des éléments, les clés extraites sont trouvées, et pour chacune d'elles la liste des TID est sélectionnée: pour "5" - (0.4), et pour "days_of_week" - (0,1), (0,2 ), (0,3), (0,4).
- De tous les TID trouvés, la fonction de cohérence sélectionne ceux qui correspondent à l'opérateur dans la requête. Pour l'opérateur
@> , les documents qui ne contiennent pas tous les éléments de la requête de recherche ne seront pas sûrs, donc il ne reste que (0,4). Mais nous devons encore revérifier le TID laissé avec la table car il n'est pas clair de l'index dans quel ordre les éléments trouvés se produisent dans le document JSON.
Pour découvrir plus de détails sur d'autres opérateurs, vous pouvez lire
la documentation .
En plus des opérations conventionnelles pour traiter avec JSON, l'extension "jsquery" est depuis longtemps disponible, qui définit un langage de requête avec des capacités plus riches (et certainement, avec le support des index GIN). En outre, en 2016, une nouvelle norme SQL a été publiée, qui définit son propre ensemble d'opérations et le langage de requête "Chemin SQL / JSON". Une implémentation de cette norme a déjà été réalisée et nous pensons qu'elle apparaîtra dans PostgreSQL 11.
Le correctif de chemin SQL / JSON a finalement été validé pour PostgreSQL 12, tandis que d'autres éléments sont toujours en cours. J'espère que nous verrons la fonctionnalité entièrement implémentée dans PostgreSQL 13.
Internes
Nous pouvons regarder à l'intérieur de l'index GIN en utilisant l'extension "
pageinspect ".
fts=# create extension pageinspect;
Les informations de la méta-page présentent des statistiques générales:
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+----------- pending_head | 4294967295 pending_tail | 4294967295 tail_free_size | 0 n_pending_pages | 0 n_pending_tuples | 0 n_total_pages | 22968 n_entry_pages | 13751 n_data_pages | 9216 n_entries | 1423598 version | 2
La structure de page fournit une zone spéciale où les méthodes d'accès stockent leurs informations; cette zone est "opaque" pour les programmes ordinaires tels que le vide. La fonction "Gin_page_opaque_info" affiche ces données pour GIN. Par exemple, nous pouvons apprendre à connaître l'ensemble des pages d'index:
fts=# select flags, count(*) from generate_series(1,22967) as g(id),
flags | count ------------------------+------- {meta} | 1 meta page {} | 133 internal page of element B-tree {leaf} | 13618 leaf page of element B-tree {data} | 1497 internal page of TID B-tree {data,leaf,compressed} | 7719 leaf page of TID B-tree (5 rows)
La fonction "Gin_leafpage_items" fournit des informations sur les TID stockés sur les pages {données, feuille, compressées}:
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]--------------------------------------------------------------------- first_tid | (239,44) nbytes | 248 tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",... -[ RECORD 2 ]--------------------------------------------------------------------- first_tid | (247,40) nbytes | 248 tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",... ...
Notez ici que les pages de gauche de l'arborescence des TID contiennent en fait de petites listes compressées de pointeurs vers les lignes de table plutôt que des pointeurs individuels.
Propriétés
Examinons les propriétés de la méthode d'accès GIN (des requêtes
ont déjà été fournies ).
amname | name | pg_indexam_has_property --------+---------------+------------------------- gin | can_order | f gin | can_unique | f gin | can_multi_col | t gin | can_exclude | f
Fait intéressant, GIN prend en charge la création d'index multicolonnes. Cependant, contrairement à un arbre B normal, au lieu de clés composées, un index multicolonne stockera toujours les éléments individuels et le numéro de colonne sera indiqué pour chaque élément.
Les propriétés de couche d'index suivantes sont disponibles:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Notez que le retour des résultats TID par TID (balayage d'index) n'est pas pris en charge; seul le scan bitmap est possible.
Le scan vers l'arrière n'est pas pris en charge non plus: cette fonctionnalité est essentielle pour le scan d'index uniquement, mais pas pour le scan bitmap.
Et ce qui suit sont des propriétés de couche de colonne:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Rien n'est disponible ici: pas de tri (ce qui est clair), pas d'utilisation de l'index comme couverture (puisque le document lui-même n'est pas stocké dans l'index), pas de manipulation de NULLs (car cela n'a pas de sens pour les éléments de type composé) .
Autres types de données
Quelques extensions supplémentaires sont disponibles qui ajoutent la prise en charge de GIN pour certains types de données.
- " pg_trgm " nous permet de déterminer la "ressemblance" des mots en comparant le nombre de séquences égales à trois lettres (trigrammes) disponibles. Deux classes d'opérateurs sont ajoutées, "gist_trgm_ops" et "gin_trgm_ops", qui prennent en charge divers opérateurs, y compris la comparaison au moyen de LIKE et d'expressions régulières. Nous pouvons utiliser cette extension avec la recherche en texte intégral afin de suggérer des options de mots pour corriger les fautes de frappe.
- " hstore " implémente le stockage "clé-valeur". Pour ce type de données, des classes d'opérateur pour différentes méthodes d'accès sont disponibles, y compris GIN. Cependant, avec l'introduction du type de données "jsonb", il n'y a aucune raison particulière d'utiliser "hstore".
- " intarray " étend la fonctionnalité des tableaux entiers. La prise en charge des index comprend GiST, ainsi que GIN (classe d'opérateur "gin__int_ops").
Et ces deux extensions ont déjà été mentionnées ci-dessus:
- " btree_gin " ajoute la prise en charge GIN pour les types de données réguliers afin qu'ils puissent être utilisés dans un index multicolonne avec des types composés.
- " jsquery " définit un langage pour les requêtes JSON et une classe d'opérateur pour la prise en charge des index de ce langage. Cette extension n'est pas incluse dans une livraison PostgreSQL standard.
Continuez à lire .