Introduction aux systèmes d'exploitation
Bonjour, Habr! Je veux attirer votre attention sur une série d'articles-traductions d'une littérature intéressante à mon avis - OSTEP. Cet article décrit assez en profondeur le travail des systèmes d'exploitation de type Unix, à savoir le travail avec les processus, les différents planificateurs, la mémoire et d'autres composants similaires qui composent le système d'exploitation moderne. L'original de tous les matériaux que vous pouvez voir
ici . Veuillez noter que la traduction a été effectuée de manière non professionnelle (assez librement), mais j'espère avoir conservé le sens général.
Les travaux de laboratoire sur ce sujet peuvent être trouvés ici:
Autres parties:
Et vous pouvez regarder ma chaîne en
télégramme =)
Présentation du planificateur
L'essence du problème: comment élaborer une politique de planification
Comment développer les cadres de politique de base du planificateur? Quelles devraient être les hypothèses clés? Quels paramètres sont importants? Quelles techniques de base ont été utilisées dans les premiers calculs?Hypothèses de charge de travail
Avant de discuter des politiques possibles, pour commencer, nous allons faire quelques digressions simplificatrices sur les processus en cours d'exécution dans le système, appelés collectivement la
charge de travail . En définissant une charge de travail en tant que partie critique de l'élaboration de politiques et plus vous en savez sur la charge de travail, meilleure est la politique que vous pouvez écrire.
Nous faisons les hypothèses suivantes sur les processus en cours d'exécution dans le système, parfois également appelés
travaux (tâches). Presque toutes ces hypothèses ne sont pas réalistes, mais nécessaires au développement de la pensée.
- Chaque tâche s'exécute le même temps,
- Toutes les tâches sont définies en même temps,
- La tâche à accomplir jusqu'à son achèvement,
- Toutes les tâches utilisent uniquement le CPU,
- Le temps d'exécution de chaque tâche est connu.
Mesures du planificateur
En plus de certaines hypothèses sur la charge, il existe toujours un besoin d'un outil pour comparer diverses politiques de planification: les mesures du planificateur. Une métrique n'est qu'une mesure de quelque chose. Il existe un certain nombre de métriques qui peuvent être utilisées pour comparer les planificateurs.
Par exemple, nous utiliserons une métrique appelée délai d'exécution. Le délai d'exécution d'une tâche est défini comme la différence entre le temps qu'il faut pour terminer la tâche et le moment où la tâche entre dans le système.
Tturnaround = Tcompletion - TarrivalPuisque nous avons supposé que toutes les tâches arrivaient en même temps, alors Ta = 0 et donc Tt = Tc. Cette valeur changera naturellement lorsque nous changerons les hypothèses ci-dessus.
Une autre mesure est l'
équité (équité, honnêteté). La productivité et l'honnêteté sont souvent des caractéristiques opposées dans la planification. Par exemple, un planificateur peut optimiser les performances, mais au prix d'attendre que d'autres tâches s'exécutent, réduisant ainsi l'intégrité.
PREMIER EN PREMIER SORTI (FIFO)
L'algorithme le plus élémentaire que nous pouvons implémenter est appelé FIFO ou
premier arrivé (premier entré, premier servi) . Cet algorithme présente plusieurs avantages: il est très simple à mettre en œuvre et il correspond à toutes nos hypothèses, faisant assez bien le travail.
Prenons un exemple simple. Supposons que 3 tâches ont été définies en même temps. Mais supposons que la tâche A soit arrivée un peu plus tôt que tout le monde, elle sera donc sur la liste d'exécution avant les autres, tout comme B par rapport à C. Supposons que chacune d'entre elles prenne 10 secondes. Quel sera le temps moyen pour terminer ces tâches?
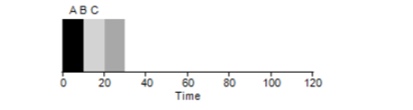
En comptant les valeurs - 10 + 20 + 30 et en divisant par 3, nous obtenons le temps d'exécution moyen du programme égal à 20 secondes.
Essayons maintenant de changer nos hypothèses. En particulier, l'hypothèse 1, et donc nous ne supposerons plus que chaque tâche prend le même temps. Comment le FIFO se montrera-t-il cette fois?
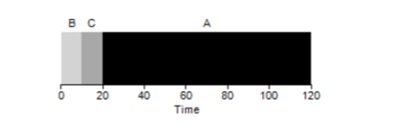
Il s'avère que différents temps d'exécution des tâches ont un impact extrêmement négatif sur la productivité de l'algorithme FIFO. Supposons que la tâche A sera exécutée pendant 100 secondes, tandis que B et C seront toujours de 10 chacun.

Comme le montre la figure, le temps moyen pour le système est (100 + 110 + 120) / 3 = 110. Cet effet est appelé
effet de convoi , lorsque certains consommateurs à court terme d'une ressource seront en ligne après un gros consommateur. Cela ressemble à une ligne d'épicerie lorsqu'un client avec un chariot plein est devant vous. La meilleure solution au problème est d'essayer de changer de caissière ou de vous détendre et de respirer profondément.
L'emploi le plus court en premier
Est-il possible de résoudre d'une manière ou d'une autre une situation similaire avec des processus lourds? Bien sûr. Un autre type de planification est appelé
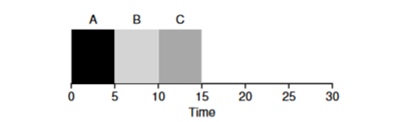
Shortest Job First (SJF). Son algorithme est également assez primitif - comme son nom l'indique, les tâches les plus courtes seront lancées les unes après les autres.
Dans cet exemple, le résultat du démarrage des mêmes processus sera une amélioration du délai d'exécution moyen des programmes et il sera de
50 au lieu de 110 , ce qui est presque 2 fois meilleur.
Ainsi, pour l'hypothèse donnée que toutes les tâches arrivent en même temps, l'algorithme SJF semble être l'algorithme le plus optimal. Cependant, nos hypothèses ne semblent toujours pas réalistes. Cette fois, nous changeons l'hypothèse 2 et cette fois, imaginons que les tâches peuvent rester à tout moment, et pas toutes en même temps. À quels problèmes cela peut-il conduire?

Imaginez que la tâche A (100s) arrive en premier et commence à être exécutée. Au temps t = 10, les tâches B, C arrivent, chacune prenant 10 secondes. Ainsi, le temps d'exécution moyen est (100+ (110-10) + (120-10)) \ 3 = 103. Que pourrait faire le planificateur pour améliorer la situation?
Délai le plus court en premier (STCF)
Afin d'améliorer la situation, nous omettons l'hypothèse 3 que le programme est opérationnel jusqu'à la fin. De plus, nous aurons besoin d'un support matériel, et comme vous l'avez peut-être deviné, nous utiliserons une
minuterie pour interrompre une tâche de travail et
changer de contexte . Ainsi, le planificateur peut faire quelque chose au moment où les tâches B et C arrivent - arrêter l'exécution de la tâche A et mettre les tâches B et C en traitement et, une fois qu'elles ont terminé, continuer le processus A. Ce planificateur est appelé
STCF ou
Preemptive Job First .
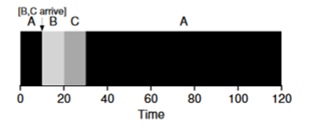
Le résultat de ce planificateur sera le résultat suivant: ((120-0) + (20-10) + (30-10)) / 3 = 50. Ainsi, un tel ordonnanceur devient encore plus optimal pour nos tâches.
Temps de réponse métrique
Ainsi, si nous connaissons le temps d'exécution des tâches et que ces tâches n'utilisent que le CPU, STCF sera la meilleure solution. Et une fois au début, ces algorithmes fonctionnaient et fonctionnaient assez bien. Cependant, l'utilisateur passe maintenant la plupart du temps au terminal et attend de lui une interaction interactive productive. Ainsi, une nouvelle métrique est née - le
temps de réponse (réponse).
Le temps de réponse est calculé comme suit:
Tresponse = Tfirstrun - TarrivalAinsi, pour l'exemple précédent, le temps de réponse sera le suivant: A = 0, B = 0, B = 10 (abg = 3,33).
Et il s'avère que l'algorithme STCF n'est pas si bon dans une situation où 3 tâches arrivent en même temps - il faudra attendre que les petites tâches soient complètement terminées. Ainsi, l'algorithme est bon pour la métrique de délai d'exécution, mais mauvais pour la métrique d'interactivité. Imaginez-vous assis au terminal pour tenter de taper des caractères dans l'éditeur, vous devrez attendre plus de 10 secondes, car une autre tâche est occupée par le processeur. Ce n'est pas très agréable.
Nous sommes donc confrontés à un autre problème - comment pouvons-nous construire un planificateur sensible au temps de réponse?
Tournoi à la ronde
Pour résoudre ce problème, l'algorithme
Round Robin (RR) a été développé. L'idée de base est assez simple: au lieu de commencer les tâches jusqu'à leur achèvement, nous allons commencer la tâche pendant une certaine période de temps (appelée quantum de temps), puis passer à une autre tâche de la file d'attente. L'algorithme répète son travail jusqu'à ce que toutes les tâches soient terminées. Dans ce cas, le temps d'exécution du programme doit être un multiple du temps après lequel le temporisateur interrompt le processus. Par exemple, si le temporisateur interrompt le processus toutes les x = 10 ms, la taille de la fenêtre d'exécution du processus doit être un multiple de 10 et être 10,20 ou x * 10.
Regardons un exemple: les tâches d'ABV arrivent simultanément dans le système et chacune veut travailler pendant 5 secondes. L'algorithme SJF terminera chaque tâche jusqu'à la fin avant d'en démarrer une autre. En revanche, l'algorithme RR avec la fenêtre de lancement = 1 passera par les tâches comme suit (Fig. 4.3):
(SJF à nouveau (mauvais pour le temps de réponse)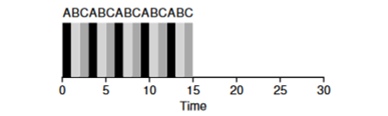 (Round Robin (bon pour le temps de réponse)
(Round Robin (bon pour le temps de réponse)Le temps de réponse moyen pour l'algorithme est RR (0 + 1 + 2) / 3 = 1, tandis que pour SJF (0 + 5 + 10) / 3 = 5.
Il est logique de supposer que la fenêtre temporelle est un paramètre très important pour RR, plus elle est petite, plus le temps de réponse est élevé. Cependant, vous ne pouvez pas le rendre trop petit, car le temps de changement de contexte jouera également un rôle dans les performances globales. Ainsi, le timing de la fenêtre d'exécution est défini par l'architecte du système d'exploitation et dépend des tâches qui doivent y être exécutées. Changer de contexte n'est pas la seule opération de service qui passe du temps - le programme en cours d'exécution fonctionne avec beaucoup plus, par exemple, divers caches, et chaque fois qu'il est nécessaire de sauvegarder et de restaurer cet environnement, ce qui peut également prendre beaucoup de temps.
RR est un excellent planificateur s'il ne s'agissait que d'une métrique de temps de réponse. Mais comment la métrique du délai d'exécution de la tâche se comportera-t-elle avec cet algorithme? Considérons l'exemple ci-dessus, lorsque le temps de fonctionnement A, B, C = 5s et arrivent en même temps. La tâche A se terminera à 13, B à 14, C à 15 s et le délai d'exécution moyen sera de 14 s. Ainsi, RR est le pire algorithme pour les métriques de chiffre d'affaires.
Plus généralement, tout algorithme tel que RR est honnête, il répartit le temps passé sur le CPU également entre tous les processus. Et donc, ces mesures sont constamment en conflit les unes avec les autres.
Ainsi, nous avons plusieurs algorithmes opposés et en même temps plusieurs hypothèses demeurent - que l'heure de la tâche est connue et que la tâche utilise uniquement le CPU.
Mixage avec E / S
Tout d'abord, nous supprimons l'hypothèse 4 selon laquelle le processus utilise uniquement le CPU, bien sûr que ce n'est pas le cas, et les processus peuvent se tourner vers d'autres équipements.
Au moment où un processus demande une opération d'E / S, le processus passe dans un état bloqué, en attendant la fin des E / S. Si des E / S sont envoyées au disque dur, une telle opération peut prendre plusieurs ms ou plus et le processeur sera inactif à ce moment. À ce moment, le planificateur peut prendre le contrôle du processeur par tout autre processus. La prochaine décision que l'ordonnanceur devra prendre est lorsque le processus termine ses E / S. Lorsque cela se produit, une interruption se produit et le système d'exploitation met le processus d'appel d'E / S à l'état prêt.
Prenons un exemple de plusieurs tâches. Chacun d'eux a besoin de 50 ms de temps processeur. Cependant, le premier accédera aux E / S toutes les 10 ms (qui seront également exécutées pendant 10 ms). Et le processus B utilise simplement un processeur de 50 ms sans E / S.
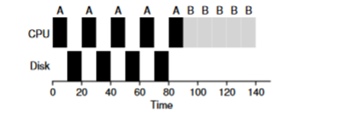
Dans cet exemple, nous utiliserons le planificateur STCF. Comment se comporte l'ordonnanceur si vous exécutez un processus comme A dessus? Il procédera comme suit - d'abord traiter entièrement A, puis traiter B.

L'approche traditionnelle pour résoudre ce problème consiste à interpréter chaque sous-tâche de 10 ms du processus A comme une tâche distincte. Ainsi, lors du démarrage avec l'algorithme STJF, le choix entre une tâche de 50 ms et une tâche de 10 ms est évident. Ensuite, une fois la sous-tâche A terminée, le processus B et les E / S seront démarrés. Une fois les E / S terminées, il sera habituel de redémarrer le processus A de 10 ms au lieu du processus B. Ainsi, il est possible de réaliser un chevauchement lorsque le CPU est utilisé par un autre processus tandis que le premier attend les E / S. Et en conséquence, le système est mieux utilisé - au moment où les processus interactifs attendent des E / S, d'autres processus peuvent être exécutés sur le processeur.
Oracle n'est plus
Essayons maintenant de nous débarrasser de l'hypothèse que l'heure de la tâche est connue. C'est généralement l'hypothèse la plus mauvaise et la plus irréaliste de toute la liste. En fait, dans les systèmes d'exploitation standard moyens, le système d'exploitation lui-même connaît généralement très peu de temps pour terminer les tâches, alors comment pouvez-vous créer un planificateur sans savoir combien de temps la tâche prendra? Peut-être pourrions-nous utiliser certains des principes de RR pour résoudre ce problème?
Résumé
Nous avons examiné les idées de base de la planification des tâches et examiné 2 familles de planificateurs. La première commence la tâche la plus courte au début et augmente ainsi le temps d'exécution, la seconde est partagée entre toutes les tâches de manière égale, augmentant le temps de réponse. Les deux algorithmes sont mauvais là où les autres algorithmes de la famille sont bons. Nous avons également examiné comment l'utilisation parallèle du processeur et des E / S peut améliorer les performances, mais nous n'avons pas résolu le problème de voyance du système d'exploitation. Et dans la prochaine leçon, nous considérerons un planificateur qui se penche sur le passé proche et essaie de prédire l'avenir. Et cela s'appelle une file d'attente de rétroaction à plusieurs niveaux.