Si vous utilisez la base de données de séries chronologiques (timeseries db,
wiki ) comme référentiel principal pour un site avec des statistiques, au lieu de résoudre le problème, vous pouvez avoir beaucoup de maux de tête. Je travaille sur un projet où une telle base de données est utilisée, et parfois InfluxDB, qui sera discuté, a présenté des surprises inattendues en général.
Avis de non -
responsabilité : ces problèmes concernent InfluxDB 1.7.4.
Pourquoi des séries chronologiques?
Le projet consiste à suivre les transactions dans diverses chaînes de blocs et à afficher des statistiques. Plus précisément, nous examinons l'émission et la combustion de pièces stables (
wiki ). Sur la base de ces transactions, vous devez créer des graphiques et afficher des tableaux croisés dynamiques.
Lors de l'analyse des transactions, l'idée est venue: utiliser la base de données de séries chronologiques InfluxDB comme stockage principal. Les transactions sont des points dans le temps et elles s'intègrent bien dans le modèle des séries chronologiques.
De plus, les fonctions d'agrégation semblaient très pratiques - elles sont idéales pour le traitement de graphiques sur une longue période. L'utilisateur a besoin d'un graphique pour l'année et la base de données contient un ensemble de données avec un délai de cinq minutes. Il est inutile de lui envoyer cent mille points - à l'exception d'un long traitement, ils ne rentreront pas à l'écran. Vous pouvez écrire votre propre implémentation d'augmentation du délai ou utiliser les fonctions d'agrégation intégrées à Influx. Avec leur aide, vous pouvez regrouper les données par jour et envoyer les 365 points souhaités.
Il était un peu gênant que ces bases de données soient généralement utilisées pour collecter des mesures. Serveurs de surveillance, iot-devices, le tout à partir duquel des millions de points de la forme «pour»: [<time> - <metric value>]. Mais si la base de données fonctionne bien avec un grand flux de données, pourquoi une petite quantité devrait-elle causer des problèmes? Dans cet esprit, ils ont pris InfluxDB pour travailler.
Quoi d'autre est pratique dans InfluxDB
En plus des fonctions d'agrégation mentionnées, il y a une autre grande chose -
les requêtes continues (
doc ). Il s'agit d'un planificateur intégré à la base de données qui peut traiter les données selon un calendrier. Par exemple, vous pouvez regrouper tous les enregistrements d'un jour toutes les 24 heures, calculer la moyenne et écrire un nouveau point dans un autre tableau sans écrire vos propres vélos.
Il existe également des
politiques de conservation (
doc ) - mise en place de la suppression des données après une période. Il est utile lorsque, par exemple, vous devez stocker la charge sur le processeur pendant une semaine avec des mesures une fois par seconde, mais à une distance de quelques mois, cette précision n'est pas nécessaire. Dans cette situation, vous pouvez le faire:
- créer une requête continue pour agréger les données dans une autre table;
- Pour le premier tableau, définissez une stratégie de suppression des métriques antérieures à cette semaine.
Et Influx réduira indépendamment la taille des données et supprimera les inutiles.
À propos des données stockées
Peu de données sont stockées: environ 70 000 transactions et un autre million de points avec des informations sur le marché. Ajout de nouvelles entrées - pas plus de 3000 points par jour. Il y a aussi des mesures sur le site, mais il y a peu de données et selon la politique de rétention, elles ne sont pas stockées plus d'un mois.
Les problèmes
Au cours du développement et des tests ultérieurs du service, de plus en plus de problèmes critiques sont survenus lors du fonctionnement d'InfluxDB.
1. Suppression de données
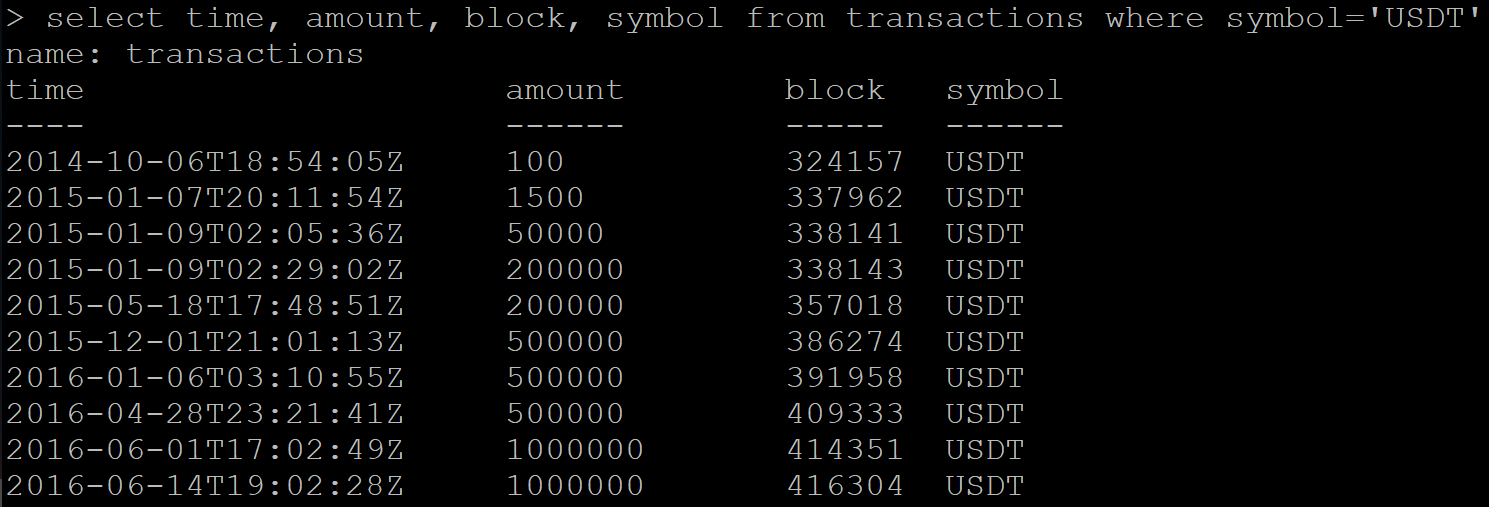
Il existe une série de données avec des transactions:
SELECT time, amount, block, symbol FROM transactions WHERE symbol='USDT'
Résultat:
J'envoie une commande pour supprimer les données:
DELETE FROM transactions WHERE symbol='USDT'
Ensuite, je fais une demande pour recevoir des données déjà supprimées. Et Influx, au lieu d'une réponse vide, renvoie une partie des données à supprimer.
J'essaie de supprimer tout le tableau:
DROP MEASUREMENT transactions
Je vérifie la suppression de la table:
SHOW MEASUREMENTS
Je ne regarde pas le tableau dans la liste, mais une nouvelle demande de données renvoie toujours le même ensemble de transactions.
Le problème ne m'est venu qu'une seule fois, car le cas de suppression est un cas isolé. Mais ce comportement de la base de données ne rentre manifestement pas dans le cadre d'un travail "correct". Plus tard sur github, j'ai trouvé un
ticket ouvert il y a presque un an sur ce sujet.
En conséquence, la suppression et la restauration ultérieure de la base de données entière ont aidé.
2. Nombres à virgule flottante
Les calculs mathématiques utilisant les fonctions intégrées dans InfluxDB donnent des erreurs de précision. Non pas que ce soit inhabituel, mais désagréable.
Dans mon cas, les données ont une composante financière et je voudrais les traiter avec une grande précision. Pour cette raison, les plans d'abandonner les requêtes continues.
3. Les requêtes continues ne peuvent pas être adaptées à différents fuseaux horaires
Le service dispose d'un tableau avec des statistiques quotidiennes sur les transactions. Pour chaque jour, vous devez regrouper toutes les transactions de cette journée. Mais la journée de chaque utilisateur commencera à une heure différente, donc l'ensemble des transactions est différent. UTC dispose de
37 options de décalage pour lesquelles vous devez agréger des données.
Lors du regroupement par heure dans InfluxDB, vous pouvez également spécifier un décalage, par exemple, pour l'heure de Moscou (UTC + 3):
SELECT MEAN("supply") FROM transactions GROUP BY symbol, time(1d, 3h) fill(previous)
Mais le résultat de la requête sera incorrect. Pour une raison quelconque, les données regroupées par jour commenceront dès 1677 (InfluxDB prend officiellement en charge la période de cette année):
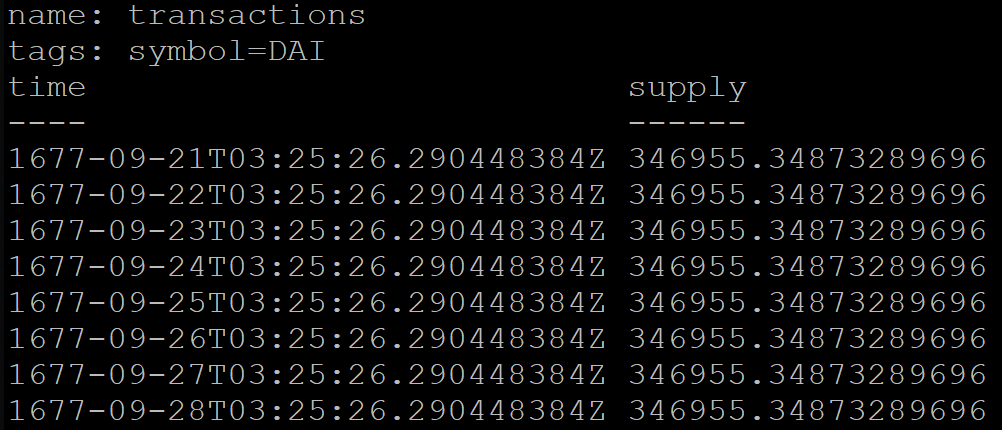
Pour contourner ce problème, le service a été temporairement transféré vers UTC + 0.
4. Performance
Il existe de nombreux points de référence sur Internet avec des comparaisons d'InfluxDB et d'autres bases de données. À la première connaissance, ils ressemblaient à du matériel de marketing, mais maintenant je pense qu'il y a du vrai en eux.
Je vais vous raconter mon cas.
Le service fournit une méthode API qui renvoie des statistiques pour le dernier jour. Pendant les calculs, la méthode interroge la base de données trois fois avec les requêtes suivantes:
SELECT * FROM coins_info WHERE time <= NOW() GROUP BY symbol ORDER BY time DESC LIMIT 1
SELECT * FROM dominance_info ORDER BY time DESC LIMIT 1
SELECT * FROM transactions WHERE time >= NOW() - 24h ORDER BY time DESC
Explication
- Dans la première requête, nous obtenons les derniers points pour chaque pièce avec les données du marché. Huit points pour huit pièces dans mon cas.
- La deuxième demande reçoit l'un du point le plus récent.
- Le troisième demande une liste de transactions pour le dernier jour, il peut y en avoir plusieurs centaines.
Je précise que dans InfluxDB, un index est automatiquement créé par balises et par heure, ce qui accélère les requêtes. Dans la première requête, le
symbole est la balise.
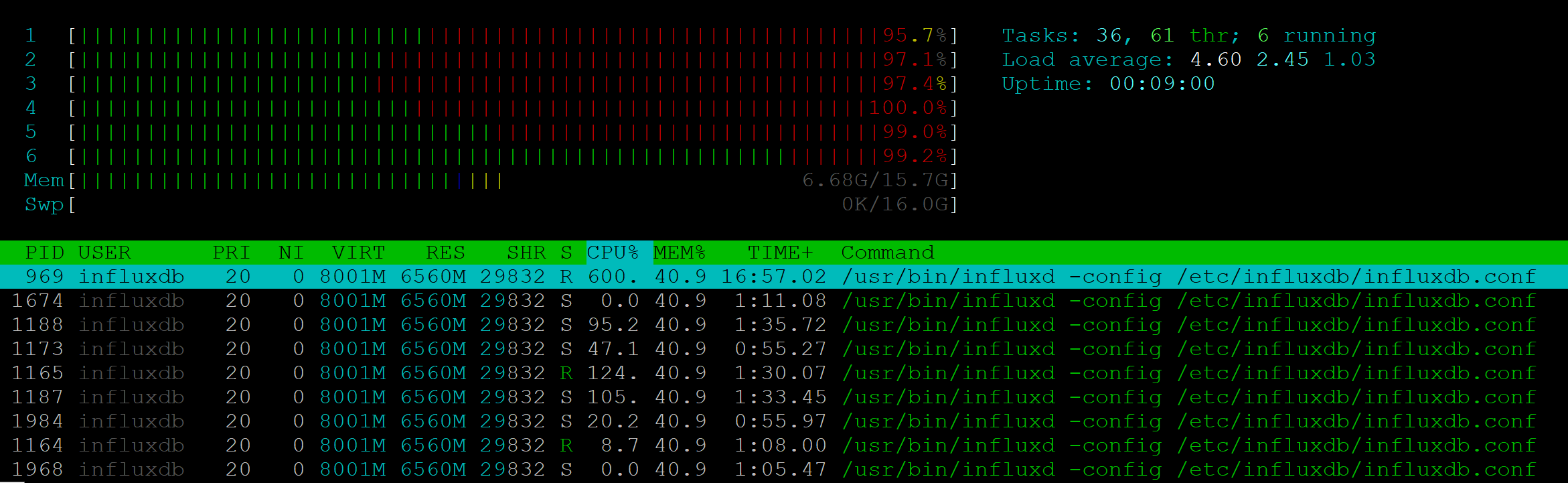
J'ai fait un test de résistance pour cette méthode API. Pour 25 RPS, le serveur a montré une charge complète de six CPU:
Dans le même temps, le processus NodeJs n'a donné aucune charge.
La vitesse d'exécution s'est déjà dégradée de 7 à 10 RPS: si un client pouvait recevoir une réponse en 200 ms, alors 10 clients devraient attendre une seconde. 25 RPS - la frontière avec laquelle la stabilité a souffert, 500 erreurs ont été retournées aux clients.
Avec de telles performances, il est impossible d'utiliser Influx dans notre projet. De plus: dans un projet où vous devez démontrer la surveillance à de nombreux clients, des problèmes similaires peuvent apparaître et le serveur métrique sera surchargé.
Conclusion
La conclusion la plus importante de l'expérience acquise est que vous ne pouvez pas intégrer une technologie inconnue dans le projet sans une analyse suffisante. Un simple filtrage des tickets ouverts sur github pourrait fournir des informations afin de ne pas prendre InfluxDB comme entrepôt de données principal.
InfluxDB aurait dû être bien adapté aux tâches de mon projet, mais comme la pratique l'a montré, cette base de données ne répond pas aux besoins et gâche beaucoup.
Vous pouvez déjà trouver la version 2.0.0-beta dans le référentiel du projet, on espère que dans la deuxième version il y aura des améliorations significatives. En attendant, je vais étudier la documentation de TimescaleDB.