
Au fil des ans, Netcracker a été un fournisseur de produits pour les opérateurs de télécommunications, et en même temps agit en tant qu'intégrateur de toute la gamme de logiciels d'opérateur. Dans ce travail, la tâche se pose inévitablement de synchroniser et de coordonner un grand nombre de versions de produits et solutions, dans différentes combinaisons, de différents développeurs et avec différentes fonctionnalités. De nombreux opérateurs évitent délibérément la dépendance à l'égard d'un seul fournisseur en créant un zoo de produits de différents fournisseurs, de sorte que dans un scénario assez complexe, jusqu'à plusieurs dizaines de systèmes et processus disparates peuvent être impliqués.
Pour clarifier ce dont nous parlons, imaginez qu'une fois par semaine vous devez implémenter un processus en utilisant un ensemble d'outils et de technologies différents: procédures PL / SQL, scripts bash, scripts Perl, lancement d'applications individuelles et accès aux processus démon. Tout cela est dû à l'hétérogénéité du paysage informatique de l'opérateur. Dans le même temps, pour chaque procédure, il y aura ses propres paramètres de lancement, contrôle de sortie, ainsi qu'un ensemble d'erreurs possibles qui affectent l'exécution ultérieure du script. Chacun de ces lancements se transforme en une tâche sérieuse nécessitant plusieurs heures ou jours de travail d'ingénieurs informatiques hautement qualifiés - leur formation peut prendre jusqu'à trois ans avant de pouvoir être transmise à un opérateur de télécommunications productif avec des dizaines de millions d'utilisateurs.
Il est clair que ces tâches doivent être automatisées. Par conséquent, nous avons décidé de tirer le meilleur parti de l'Orchestre BPMN, du planificateur de processus, du système de surveillance et d'enrichir cet ensemble avec la possibilité d'analyser les journaux et les erreurs. Bien entendu, les meilleurs représentants de leur genre ont été pris en compte pour chaque type de système. Mais aucune essence correspondante n'a été trouvée pour les spécificités de l'industrie. Par conséquent, faites-le vous-même.
En bref sur ce que nous faisons: les procédures hétérogènes sont regroupées en «tâches» avec un ensemble typique d'interfaces et de propriétés; une certaine séquence de tâches forme un «processus» (par exemple, un processus de facturation des frais pour les services de communication). De plus, selon un calendrier ou manuellement, chaque processus démarre sa séquence de procédures avec les paramètres nécessaires, surveille l'exécution, évalue les résultats des tâches imbriquées et prend une décision sur le choix des scénarios. La relation entre les tâches au sein du processus est basée sur la logique BPMN standard, tandis que dans le serveur de gestion, nous avons défini la possibilité d'arrêter manuellement le processus, de le mettre en pause, de quitter le scénario actuel en enregistrant les données qui ont déjà été traitées. La gestion des processus est mise en œuvre via une interface Web avec une surveillance en temps réel, avec une évaluation des anomalies, une surveillance des SLA spécifiques pour chaque processus.
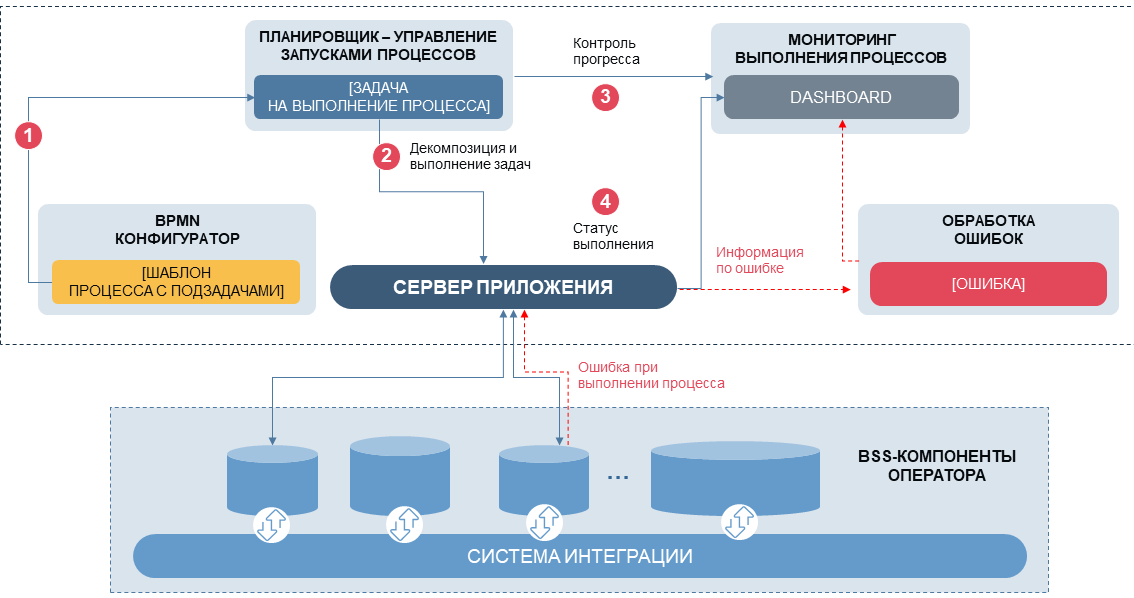
Notre "gestionnaire de processus" peut désormais fonctionner en mode semi-automatique, mais il ne réduit pratiquement pas la charge des ingénieurs informatiques - lorsque deux systèmes complexes ou plus interagissent, la variabilité des anomalies dans les processus augmente de nombreuses fois et les principaux efforts sont consacrés à la gestion des erreurs. Par conséquent, à l'étape suivante, nous avons dû prendre une décision:
- Comment voulons-nous automatiser la gestion des erreurs?
- Comment corriger des scénarios basés sur l'analyse d'anomalies?
- En général, dans quelle mesure une personne doit-elle intervenir dans le fonctionnement d'un tel système, dans quels volumes et à quels endroits?
Je note encore une fois que tout cela doit être fait en temps réel sur la productivité du système critique servant des dizaines et des centaines de milliers de transactions par seconde. Et ici, nous avons dû résoudre le problème de la recherche et du dépannage (le soi-disant dépannage) dans les conditions:
- mises à jour périodiques des processus
- développement d'une base de porteurs
- changements dans l'ensemble des services de télécommunications
Oui, et une autre condition importante à laquelle nous devons nous conformer est de ne pas nuire. Ou parler la langue des documents officiels - pour réduire les coûts de temps et de main-d'œuvre dans le fonctionnement des systèmes informatiques d'un fournisseur de télécommunications.
La question s'est posée - dans quelle proportion la gestion automatique des erreurs et la participation d'experts à un tel dépannage devraient-elles être mélangées? Parlons maintenant des options.
AI
Puisque nous vivons à l'ère du battage éternel, nous avons décidé de faire du développement une base d'intelligence artificielle - afin que cet intellect reconnaisse les erreurs et les anomalies, prédit les échecs et les corrige immédiatement. Les grandes entreprises et les petites startups créent déjà de telles solutions et mettent même en œuvre des solutions similaires. Le champ d'application principal de leur application: les opérations de construction, de maintenance et de support des infrastructures informatiques. C'est ce qu'on appelle AIOps - Opérations d'intelligence artificielle (pour les TI), et le mot à la mode le plus populaire est NoOps, c'est-à-dire les opérations informatiques entièrement automatisées.
L'apprentissage du système ne sera pas facile, car l'ensemble des données historiques est limité, il est coûteux de créer une copie exacte du produit et les exemples d'enseignement (apprentissage actif) sont trop longs et, dans notre cas, inexacts. Vous pouvez essayer la méthode d'agrégation bootstrap - pour simuler un ensemble fini de scénarios pour les cas connus et suspects et créer un arbre de décision basé sur celui-ci, par exemple, l'arbre de classification et de régression, mais c'est également une méthode assez coûteuse. Mais si nous faisons tout cela, nous ferons réfléchir le programme pour nous et économiserons un tas de ressources utiles (ce qui, traduit de gestionnaire à humain, signifie "licencier les administrateurs système les plus ennuyeux").
Inconvénients:
- En raison de la complexité des systèmes et de leur interaction, il est pratiquement impossible de créer et de former une certaine version «en boîte» d'une telle solution pour toutes les situations possibles. Pour chaque nouveau projet, ce sera sa propre «formation» distincte, avec la reconnaissance des erreurs spécifiques, des anomalies et des moyens appropriés pour les résoudre.
- Nous ne concevons pas une solution de masse, mais une solution interne, pour un nombre limité d'implémentations (car il y a très peu d'opérateurs de cette envergure dans le monde). Il peut facilement s'avérer de sorte qu'il sera plus économique d'offrir à nos clients l'externalisation «humaine» appropriée pour résoudre de tels problèmes.
- Peut-être que nos clients sont plus susceptibles de supporter les coûts de nouveaux ingénieurs hautement qualifiés que d'accepter les risques de transfert du support produit à l'intelligence artificielle. Pour le dire légèrement, cela peut soulever certaines préoccupations.
Je ne me fais pas de cerveaux
Étant donné que l'intervention humaine ne peut être dispensée, nous sommes passés à l'ancienne. Rappelez-vous, une fois que nous pensions que «une machine devrait fonctionner et qu'une personne devrait penser»? Nous avons reformulé ceci: "le programme devrait résoudre les problèmes connus, et l'ingénieur devrait résoudre les inconnues."
Nous avons créé un système algorithmique organisé selon le concept d'apprentissage renforcé, mais avec une logique claire. La formation système se déroule dans un volume étroit et contrôlé, les règles sont stockées de manière transparente, elles peuvent être éditées, développées, spécifiées, désactivées, etc. Un tel développement n'est pas beaucoup plus compliqué qu'une simple "semi-automatisation". Un ingénieur qualifié est toujours nécessaire pour le fonctionnement, mais ses ressources sont utilisées uniquement pour identifier et résoudre de nouveaux problèmes. Si nous adhérons fermement au principe «une personne ne doit pas résoudre les problèmes connus», nous pouvons supposer qu'après un certain temps, la fourniture de problèmes inconnus commencera à se dessécher, et la fonctionnalité du système développé approchera l'IA pour ce domaine d'application particulier.
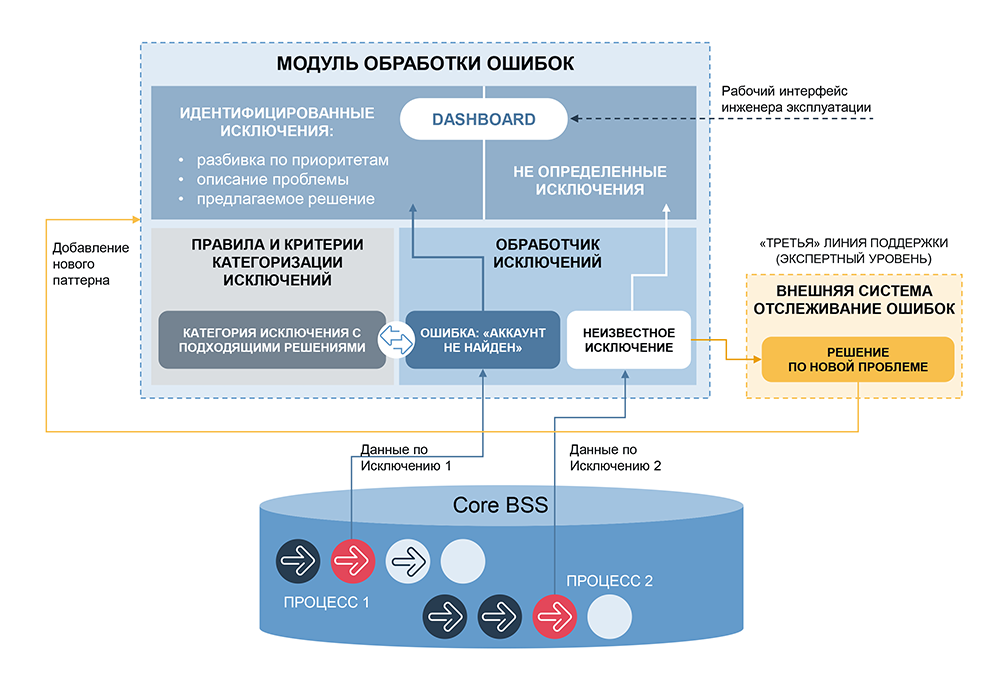
La partie la plus importante d'un tel système est la catégorisation, la ré-identification des anomalies. Notre entreprise dispose déjà d'un système similaire - Order Tracker, qui est utilisé pour surveiller les processus commerciaux d'un opérateur mobile gérant les commandes. Order Tracker analyse des centaines d'événements par seconde, identifie les anomalies sur des lignes distinctes et dans des combinaisons d'événements, permet à l'utilisateur de les regrouper, de définir des valeurs maximales et minimales, de déterminer les erreurs de différents niveaux de gravité et de proposer des actions pour résoudre les problèmes. Le système fonctionne depuis longtemps, de nombreux râteaux ont déjà été complétés avec succès, nous l'avons donc pris comme outil de catégorisation.
Il fallait maintenant automatiser la résolution des problèmes. Contrairement à la gestion des commandes, où l'intervention de l'opérateur est souvent requise (par exemple, lorsque vous devez impliquer le service financier, le service client, etc.), nous avons la capacité de résoudre automatiquement une partie importante des incidents et il existe un outil prêt à l'emploi pour concevoir ces solutions - des scripts à partir de blocs prêts à l'emploi, qui peut être complétée, la logique étendue, inclure des vérifications supplémentaires et associer à chaque catégorie d'erreurs reconnue.
Qu'est-ce qui pourrait mal tourner?
C’est tout!
Le système de suivi des commandes ne nécessite généralement pas de prise de décision et de correction en temps réel, et toute anomalie affecte un nombre limité de clients, de un à plusieurs centaines. Nous essayons d'introduire la gestion automatique des erreurs sur les processus qui affectent des centaines de milliers et des millions d'abonnés et nécessitent une solution en temps réel ou en quelques heures. C'est un risque énorme pour tout opérateur avec lequel nous travaillons, et donc pour nous, pour notre réputation.
Nous avons dû augmenter considérablement la flexibilité des scripts, implémenter un système de contrôle de version, ajouter l'entité «instance de script», c'est-à-dire que pour chaque script, vous pouvez maintenant créer de nombreuses sous-classes avec certaines combinaisons de paramètres, seuils, vérifications supplémentaires, etc. J'ai dû augmenter la flexibilité de nombreuses tâches en introduisant des vérifications supplémentaires des paramètres d'entrée et de sortie.
Une autre direction de développement consiste à augmenter la granularité des catégories d'événements analysés et à créer des méta-catégories, c'est-à-dire combinaisons de différents événements définis par le catégoriseur. Nous avons ajouté une estimation de la séquence des anomalies et de la coïncidence des différentes anomalies dans le temps. Le système est devenu de plus en plus compliqué, mais il a gardé une logique claire - pour toute paire «catégorie d'anomalies - scénario sélectionné», les relations causales sont toujours préservées.
Pour de nombreuses combinaisons, nous avons déjà obtenu des résultats fiables et fiables et les avons publiés de manière productive. Les erreurs, dont la recherche et la correction prenaient auparavant des heures, sont désormais résolues en mode automatique. Pour les autres types d'anomalies, nous continuons de tester: quelque part sur les données de test, quelque part dans le mode de vérification manuelle et de confirmation du scénario sélectionné.
Et puis il s'est avéré ...
Nous avons récemment réalisé que nous avions obtenu un résultat de ces travaux auquel nous ne nous attendions pas au début - un outil très efficace pour l'ingénierie inverse des solutions d'autres personnes, y compris celles pour lesquelles nous n'avons ni le soutien des développeurs, ni même une documentation claire. Par inadvertance, la soi-disant «découverte de processus métier» a été effectuée. Nous avons appris en pratique à analyser la logique des applications, à identifier les erreurs internes et les problèmes d'intégration avec d'autres systèmes. Maintenant, nous ne pouvons pas simplement orchestrer les applications d'autres personnes - nous pouvons développer des correctifs pour elles, améliorer l'intégration et la chose la plus précieuse est d'offrir nos produits pour remplacer l'héritage existant.
À l'étape suivante, nous voulons essayer de mettre en œuvre notre solution sous la forme d'un produit complet pour les tests d'intégration, qui détectera automatiquement les erreurs et les anomalies, apprendra à la volée, fournira des outils pour la correction des symptômes et pour rechercher et analyser les problèmes dans la logique d'application. Cette solution n'aura pas moins d'efficacité que les AIOps et NoOps à la mode, et nous conserverons la logique de décision transparente et gérable. Donc, si dans quelques années vous rencontrez une telle solution de Netcracker sur le marché, gardez à l'esprit - tout a commencé avec les scripts bash ...