
Le 8 avril, lors de la
conférence Saint HighLoad ++ 2019 , dans le cadre de la section DevOps et opérations, un rapport a été réalisé «Étendre et compléter Kubernetes», créé par trois employés de la société Flant. Nous y parlons de nombreuses situations dans lesquelles nous voulions étendre et compléter les capacités de Kubernetes, mais pour lesquelles nous n'avons pas trouvé de solution toute faite et simple. Les solutions nécessaires sont apparues sous forme de projets Open Source, et cette présentation leur est également dédiée.
Par tradition, nous sommes heureux de présenter une
vidéo avec un rapport (50 minutes, beaucoup plus informatif que l'article) et la principale compression sous forme de texte. C'est parti!
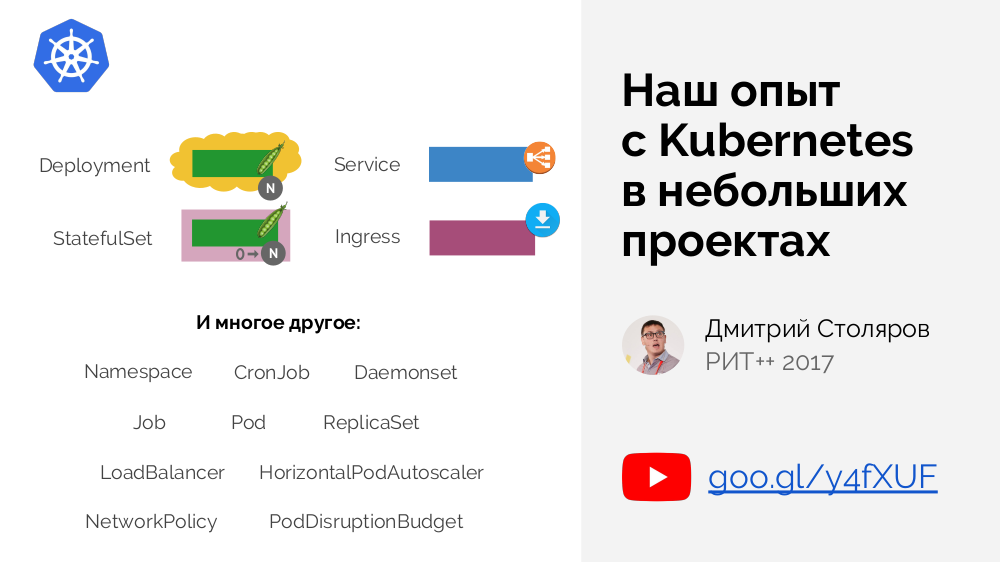
K8s Kernel and Add-ons
Kubernetes transforme une approche industrielle et administrative établie de longue date:
- Grâce à ses abstractions , nous ne fonctionnons plus avec des concepts tels que la configuration d'une config ou l'exécution d'une commande (Chef, Ansible ...), mais utilisons le regroupement de conteneurs, de services, etc.
- On peut préparer des candidatures sans penser aux nuances de la plateforme spécifique sur laquelle elle sera lancée: bare metal, le cloud de l'un des fournisseurs, etc.
- Avec les K8, les meilleures pratiques d'organisation des infrastructures sont devenues plus accessibles que jamais: évolutivité, auto-réparation, tolérance aux pannes, etc.
Cependant, bien sûr, tout n'est pas si simple: avec Kubernetes sont venus leurs propres - nouveaux - défis.
Kubernetes n'est
pas une moissonneuse-batteuse qui résout tous les problèmes de tous les utilisateurs.
Le noyau Kubernetes est uniquement responsable de l'ensemble des fonctions minimales nécessaires présentes dans
chaque cluster:
Au cœur de Kubernetes, un ensemble de base de primitives est défini - pour regrouper les conteneurs, gérer le trafic, etc. Nous en avons parlé plus en détail dans un
rapport il y a 2 ans .
D'un autre côté, les K8 offrent de grandes opportunités pour étendre les fonctions disponibles, ce qui aide à combler les besoins des autres utilisateurs spécifiques. Les administrateurs de cluster sont responsables des ajouts à Kubernetes, qui doivent installer et configurer tout ce qui est nécessaire pour que leur cluster "prenne la forme nécessaire" [pour résoudre leurs problèmes spécifiques]. De quel genre d'ajouts s'agit-il? Regardons quelques exemples.
Exemples d'ajouts
Après avoir installé Kubernetes, nous pouvons être surpris que le réseau, si nécessaire pour l'interaction des pods à la fois au sein du nœud et entre les nœuds, ne fonctionne pas seul. Le noyau Kubernetes ne garantit pas les connexions nécessaires - à la place, il définit une
interface réseau (
CNI ) pour les modules complémentaires tiers. Nous devons installer l'un de ces ajouts, qui sera responsable de la configuration du réseau.

Un exemple proche est les solutions de stockage de données (disque local, périphérique de bloc réseau, Ceph ...). Initialement, ils étaient dans le noyau, mais avec l'avènement de
CSI, la situation passe à une situation similaire déjà décrite: dans Kubernetes, l'interface et son implémentation, dans des modules tiers.
Entre autres exemples:
- Contrôleurs d' entrée (pour un examen, consultez notre récent article ) .
- cert-manager :

- Les opérateurs sont toute une classe d'add-ons (qui incluent le gestionnaire de certificats mentionné), ils définissent les primitives et les contrôleurs. La logique de leur travail n'est limitée que par notre imagination et nous permet de transformer des composants d'infrastructure prêts à l'emploi (par exemple, SGBD) en primitives, qui sont beaucoup plus faciles à travailler (qu'avec un ensemble de conteneurs et leurs paramètres). Un grand nombre d'opérateurs ont été écrits - même si beaucoup d'entre eux ne sont pas encore prêts pour la production, ce n'est qu'une question de temps:
- Les métriques sont une autre illustration de la façon dont Kubernetes a séparé l'interface (API de métriques) de son implémentation (modules complémentaires tiers tels que l'adaptateur Prometheus, l'agent de cluster Datadog ...).
- Pour la surveillance et les statistiques , où en pratique non seulement Prométhée et Grafana sont nécessaires , mais aussi les métriques d'état du kube, l'exportateur de nœuds, etc.
Et ce n'est pas une liste complète d'add-ons ... Par exemple, chez Flant, nous installons aujourd'hui
29 add-ons pour chaque cluster Kubernetes (tous créent au total 249 objets Kubernetes). Autrement dit, nous ne voyons pas la vie d'un cluster sans ajouts.
Automatisation
Les opérateurs sont conçus pour automatiser les opérations de routine auxquelles nous sommes confrontés quotidiennement. Voici des exemples de vie qui seraient parfaits pour écrire un opérateur:
- Il existe un registre privé (c'est-à-dire nécessitant une connexion) avec des images pour l'application. Il est supposé que chaque pod est lié à un secret spécial qui permet l'authentification dans le registre. Notre tâche est de nous assurer que ce secret se trouve dans l'espace de noms, afin que les pods puissent télécharger des images. Il peut y avoir beaucoup d'applications (dont chacune a besoin d'un secret), et il est utile de mettre à jour régulièrement les secrets eux-mêmes, de sorte que l'option de découvrir les secrets avec vos mains disparaisse. Ici, l'opérateur vient à la rescousse: nous créons un contrôleur qui attend que l'espace de noms apparaisse et ajoute un secret à l'espace de noms pour cet événement.
- Supposons que par défaut, l'accès des pods à Internet soit interdit. Mais parfois, cela peut être nécessaire: il est logique que le mécanisme d'autorisation d'accès fonctionne simplement sans nécessiter de compétences spécifiques, par exemple, par la présence d'une certaine étiquette dans l'espace de noms. Comment l'opérateur nous aidera-t-il ici? Un contrôleur est créé qui s'attend à ce que l'étiquette apparaisse dans l'espace de noms et ajoute la stratégie appropriée pour accéder à Internet.
- Une situation similaire: nous devons ajouter une certaine tache au nœud s'il a une étiquette similaire (avec une sorte de préfixe). Les actions avec l'opérateur sont évidentes ...
Dans tout cluster, il est nécessaire de résoudre les tâches de routine, et
correctement de le faire - en utilisant des opérateurs.
En résumant toutes les histoires décrites, nous sommes arrivés à la conclusion que
pour un travail confortable dans Kubernetes, il est nécessaire : a) d'
installer des modules complémentaires , b) de
développer des opérateurs (pour résoudre les tâches d'administration quotidiennes).
Comment écrire une déclaration pour Kubernetes?
En général, le schéma est simple:
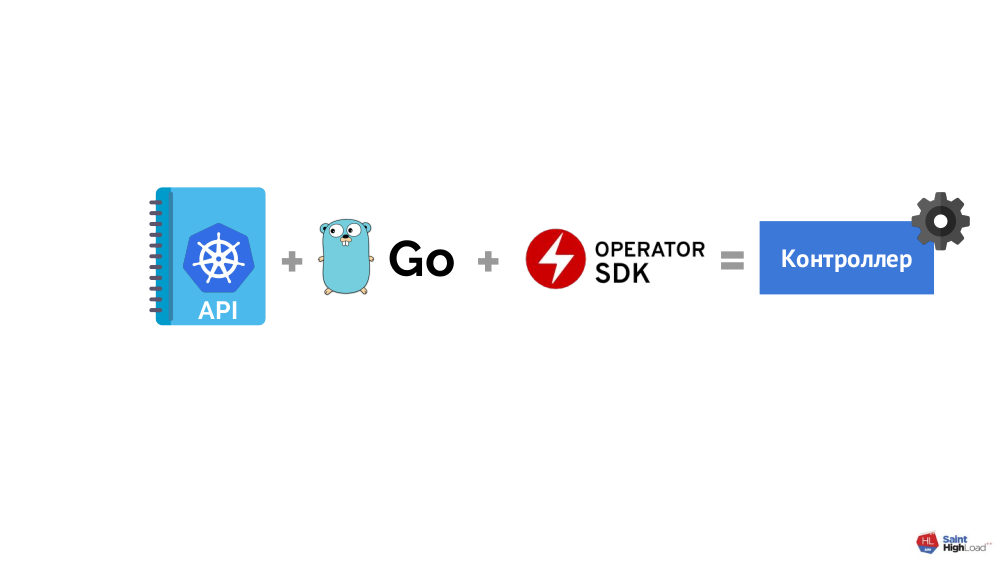
... mais il s'avère que:
- L'API Kubernetes est une chose plutôt simple qui nécessite beaucoup de temps à maîtriser;
- la programmation n'est pas non plus pour tout le monde (Go est choisi comme langue préférée car il existe un cadre spécial pour cela - Operator SDK );
- avec le cadre en tant que tel, une situation similaire.
Conclusion:
pour écrire un contrôleur (opérateur), vous devez
dépenser des ressources importantes pour étudier le matériel. Cela serait justifié pour les "gros" opérateurs - disons, pour le SGBD MySQL. Mais si nous rappelons les exemples décrits ci-dessus (révélation de secrets, accès des pods à Internet ...), que nous voulons également faire correctement, alors nous comprendrons que les efforts dépensés l'emporteront sur le résultat désormais recherché:

En général, un dilemme se pose: dépenser beaucoup de ressources et trouver le bon outil pour rédiger des déclarations ou agir "à l'ancienne" (mais rapidement). Pour le résoudre - pour trouver un compromis entre ces extrêmes - nous avons créé notre propre projet:
shell-operator (voir aussi sa récente annonce sur le hub) .
Opérateur Shell
Comment fonctionne-t-il? Dans le cluster, il y a un pod dans lequel se trouve le Go-binary avec shell-operator. Un ensemble de
crochets est stocké à côté
(pour plus de détails à leur sujet, voir ci-dessous) . L'opérateur shell lui-même souscrit à certains
événements dans l'API Kubernetes, sur lesquels il lance les hooks correspondants.
Comment l'opérateur shell comprend-il les hooks à déclencher sous quels événements? Ces informations sont transmises à l'opérateur shell par les hooks eux-mêmes et ils le rendent très simple.
Un hook est un script Bash ou tout autre fichier exécutable qui prend en charge un seul argument
--config et renvoie JSON en réponse. Ce dernier détermine quels objets l'intéressent et quels événements (pour ces objets) doivent être réagis:

J'illustrerai la mise en œuvre par un opérateur shell de l'un de nos exemples - révélant des secrets pour accéder à un registre privé avec des images d'application. Il se compose de deux étapes.
Pratique: 1. Écrire un crochet
La première étape du hook consiste à traiter
--config , indiquant que nous nous intéressons aux espaces de noms, et plus précisément au moment de leur création:
[[ $1 == "--config" ]] ; then cat << EOF { "onKubernetesEvent": [ { "kind": "namespace", "event": ["add"] } ] } EOF …
À quoi ressemblera la logique? Assez simple aussi:
… else createdNamespace=$(jq -r '.[0].resourceName' $BINDING_CONTEXT_PATH) kubectl create -n ${createdNamespace} -f - << EOF Kind: Secret ... EOF fi
La première étape consiste à découvrir quel espace de noms a été créé et la deuxième étape consiste à créer un secret pour cet espace de noms via
kubectl .
Pratique: 2. Assembler une image
Il reste à transférer le crochet créé à l'opérateur shell - comment faire? L'opérateur shell lui-même est fourni en tant qu'image Docker, notre tâche consiste donc à ajouter un hook à un répertoire spécial dans cette image:
FROM flant/shell-operator:v1.0.0-beta.1 ADD my-handler.sh /hooks
Il reste à le ramasser et à le push'nut:
$ docker build -t registry.example.com/my-operator:v1 . $ docker push registry.example.com/my-operator:v1
La touche finale consiste à intégrer l'image dans un cluster. Pour ce faire, écrivez
Déploiement :
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: my-operator spec: template: spec: containers: - name: my-operator image: registry.example.com/my-operator:v1 # 1 serviceAccountName: my-operator # 2
Dans ce document, vous devez faire attention à deux points:
- Indication de l'image nouvellement créée;
- il s'agit d'un composant système qui (au minimum) a besoin de droits pour s'abonner aux événements dans Kubernetes et pour révéler des secrets par espace de noms, nous créons donc un ServiceAccount (et un ensemble de règles) pour le hook.
Le résultat - nous avons résolu notre problème d'une manière
native de Kubernetes, créant un opérateur pour révéler des secrets.
Autres fonctionnalités de shell-operator
Pour limiter les objets du type de votre choix avec lesquels le crochet fonctionnera,
vous pouvez les filtrer en les filtrant par des étiquettes spécifiques (ou en utilisant
matchExpressions ):
"onKubernetesEvent": [ { "selector": { "matchLabels": { "foo": "bar", }, "matchExpressions": [ { "key": "allow", "operation": "In", "values": ["wan", "warehouse"], }, ], } … } ]
Un
mécanisme de déduplication est fourni, qui - à l'aide d'un filtre jq - vous permet de convertir de gros JSON d'objets en petits, où seuls les paramètres que nous voulons surveiller sont modifiés.
Lorsque le hook est appelé, l'opérateur shell lui transmet des
données sur l'objet , qui peuvent être utilisées pour tous les besoins.
Les événements sur lesquels des hooks sont déclenchés ne sont pas limités aux événements Kubernetes: l'opérateur shell fournit un support pour
appeler des hooks à temps (similaire à crontab dans le planificateur traditionnel), ainsi qu'un événement
onStartup spécial. Tous ces événements peuvent être combinés et affectés au même hook.
Et deux autres fonctionnalités de shell-operator:
- Cela fonctionne de manière asynchrone . Depuis l'événement Kubernetes (par exemple, la création d'un objet), d'autres événements (par exemple, la suppression du même objet) peuvent se produire dans le cluster, et cela doit être pris en compte dans les hooks. Si le hook a échoué, par défaut, il sera rappelé jusqu'à la fin (ce comportement peut être modifié).
- Il exporte des métriques pour Prometheus, avec lesquelles vous pouvez comprendre si l'opérateur shell fonctionne, connaître le nombre d'erreurs pour chaque hook et la taille de la file d'attente actuelle.
Pour résumer cette partie du rapport:

Installation de modules complémentaires
Pour un travail confortable avec Kubernetes, la nécessité d'installer des modules complémentaires a également été mentionnée. Je vais en parler sur l'exemple de la façon dont notre entreprise est de savoir comment nous le faisons maintenant.
Nous avons commencé à travailler avec Kubernetes avec plusieurs clusters, dont le seul ajout était Ingress. Il fallait le placer différemment dans chaque cluster, et nous avons réalisé plusieurs configurations YAML pour différents environnements: bare metal, AWS ...
Il y avait plus de clusters - plus de configurations. De plus, nous avons amélioré ces configurations elles-mêmes, ce qui les a rendues assez hétérogènes:
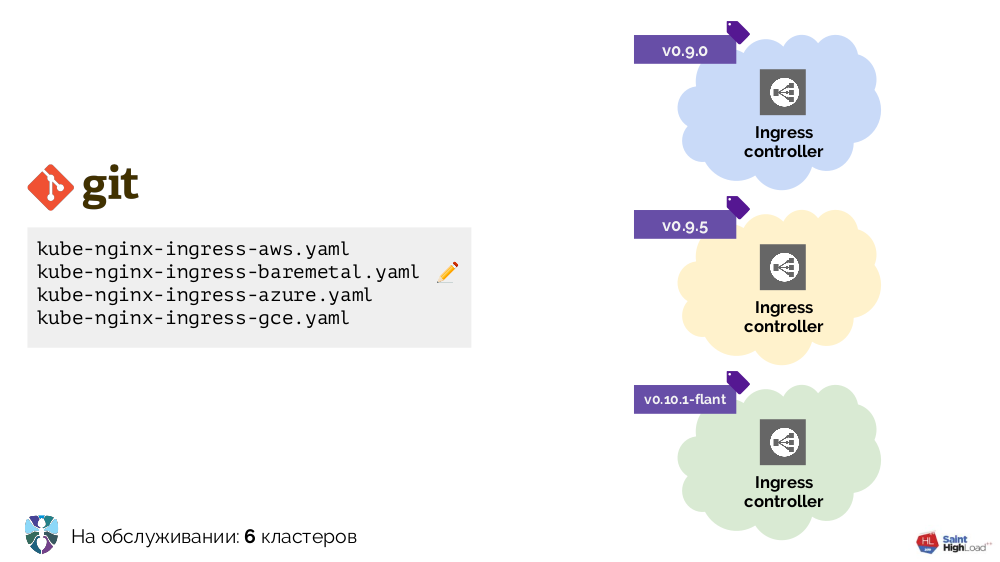
Pour mettre tout en ordre, nous avons commencé avec un script (
install-ingress.sh ), qui a pris comme argument le type de cluster à déployer, a généré la configuration YAML souhaitée et l'a déployée sur Kubernetes.
En bref, notre nouvelle voie et les arguments qui y sont liés étaient les suivants:
- pour travailler avec des configurations YAML, un moteur de template est requis (dans les premiers temps c'est un sed simple);
- avec l'augmentation du nombre de clusters, le besoin est venu de mises à jour automatiques (la première solution est de mettre un script dans Git, de le mettre à jour par cron et de l'exécuter);
- un script similaire était requis pour Prometheus (
install-prometheus.sh ), mais il est remarquable en ce qu'il nécessite beaucoup plus de données d'entrée, ainsi que leur stockage (dans le bon sens, centralisé et dans le cluster), et certaines données (mots de passe) pourraient être générées automatiquement :

- le risque de rouler quelque chose de mal dans un nombre croissant de clusters augmentait constamment, nous avons donc réalisé que les installateurs (c'est-à-dire deux scripts: pour Ingress et Prometheus) avaient besoin d'une configuration de scène (plusieurs branches dans Git, plusieurs cron pour les mettre à jour dans les correspondantes: clusters stables ou de test);
- il est devenu difficile de travailler avec
kubectl apply , car il n'est pas déclaratif et ne peut que créer des objets, mais pas prendre des décisions sur leur statut / les supprimer; - manquait de fonctions que nous ne réalisions pas à l'époque:
- un contrôle total sur le résultat des mises à jour du cluster,
- détermination automatique de certains paramètres (saisie pour les scripts d'installation) à partir des données pouvant être obtenues à partir du cluster (découverte),
- son développement logique sous forme de découverte continue.
Nous avons réalisé toute cette expérience accumulée dans le cadre de notre autre projet -
addon-operator .
Addon-operator
Il est basé sur l'opérateur shell déjà mentionné. L'ensemble du système est le suivant:
Aux crochets de l'opérateur shell sont ajoutés:
- stockage des valeurs
- Tableau de barre
- le composant qui surveille le référentiel de valeurs et - en cas de changement - demande à Helm de relancer le graphique.

Ainsi, nous pouvons répondre à un événement dans Kubernetes, lancer un hook et, à partir de ce hook, apporter des modifications au référentiel, après quoi le graphique sera re-pompé. Dans le schéma résultant, nous sélectionnons un ensemble de crochets et un graphique en un seul composant, que nous appelons un
module :
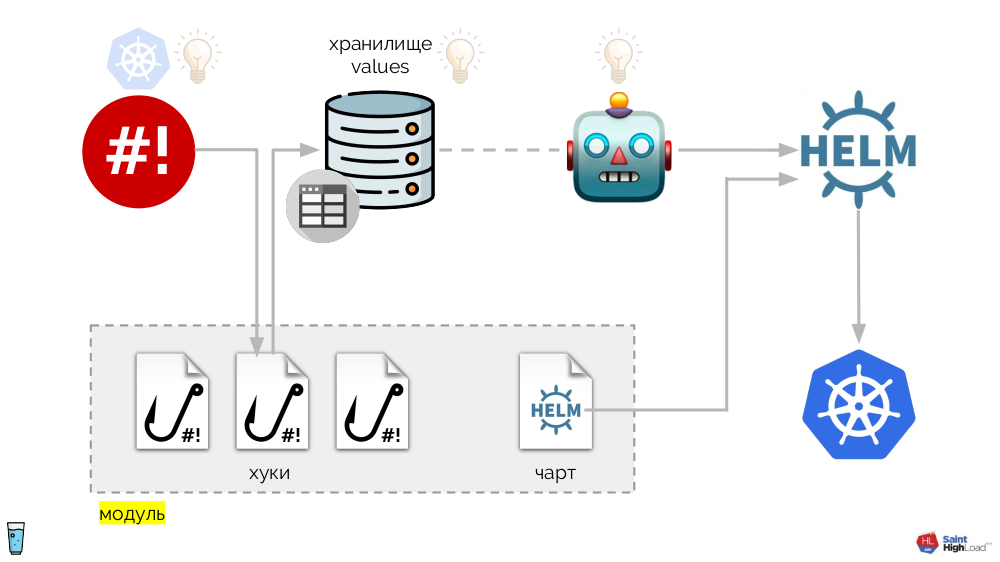
Il peut y avoir de nombreux modules et nous y ajoutons des hooks globaux, un stockage de valeurs globales et un composant qui surveille ce stockage global.
Maintenant que quelque chose se passe dans Kubernetes, nous pouvons y répondre avec un hook global et changer quelque chose dans le référentiel global. Cette modification sera remarquée et entraînera la restauration de tous les modules du cluster:
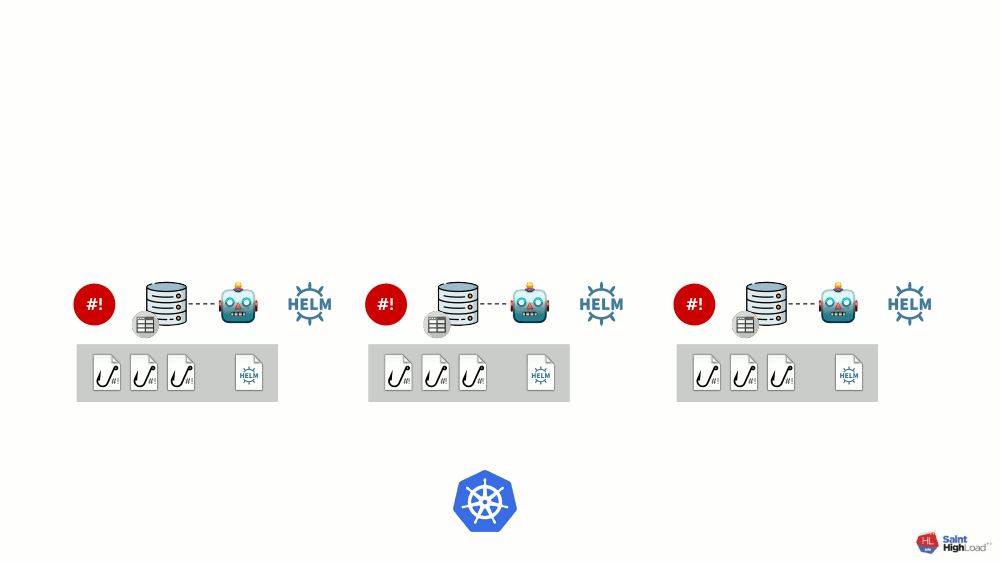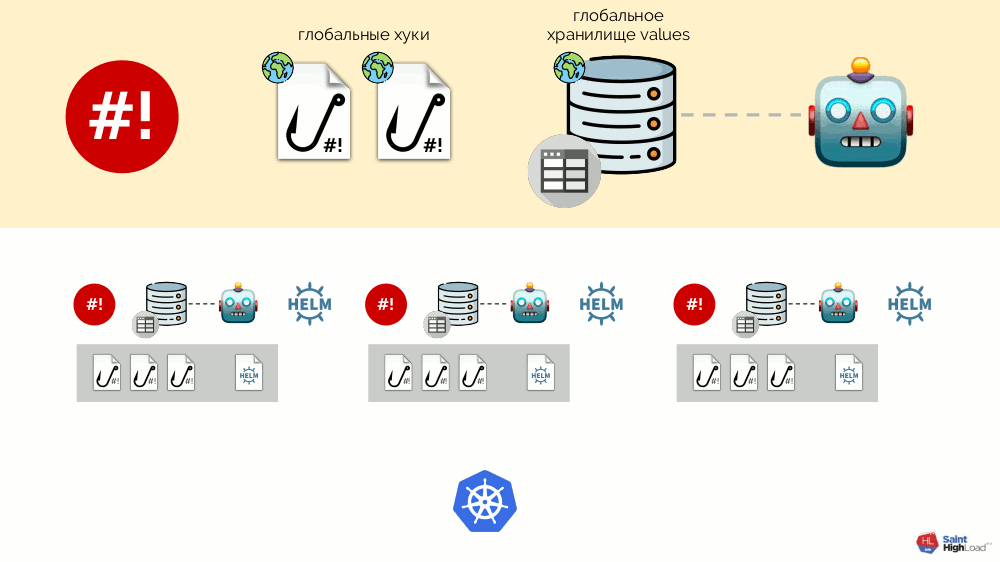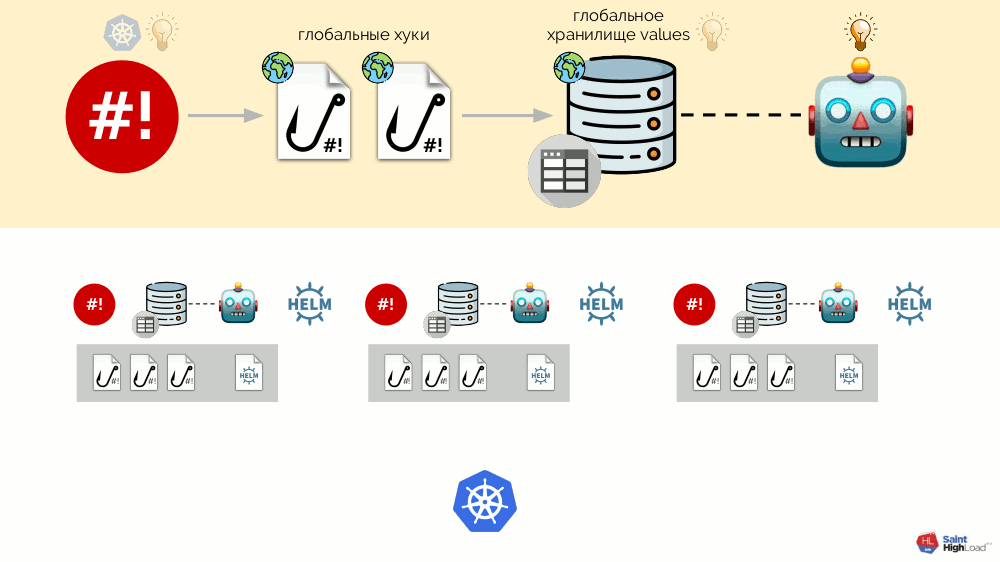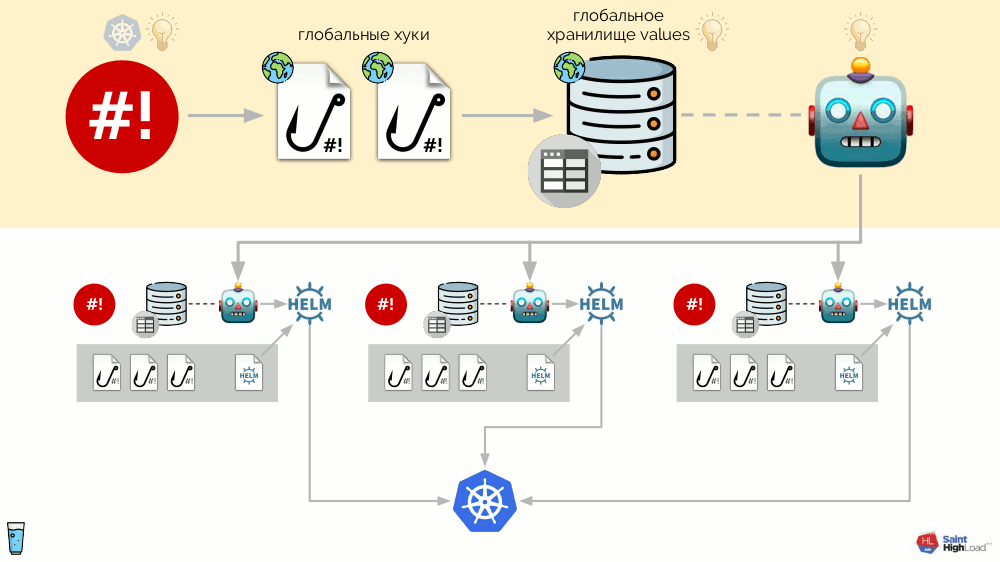
Ce schéma répond à toutes les exigences d'installation des modules complémentaires annoncées ci-dessus:
- Helm est responsable de la normalisation et de la déclarativité.
- Le problème de mise à jour automatique a été résolu à l'aide d'un hook global, qui va au registre selon un calendrier et, s'il y voit une nouvelle image du système, le relance (c'est-à-dire «lui-même»).
- Le stockage des paramètres dans le cluster est implémenté à l'aide de ConfigMap , dans lequel les données primaires des stockages sont enregistrées (au démarrage, elles sont chargées dans les stockages).
- Les problèmes de génération de mot de passe, de découverte et de découverte continue sont résolus à l'aide de crochets.
- La mise en scène est réalisée grâce aux balises prises en charge par Docker.
- Le résultat est contrôlé à l'aide de mesures permettant de comprendre l'état.
L'ensemble de ce système est implémenté comme un seul binaire on Go, qui a été appelé addon-operator. Grâce à cela, le schéma semble plus simple:

Le composant principal de ce diagramme est un ensemble de modules
(grisé ci-dessous) . Maintenant, nous pouvons écrire un module avec un petit effort pour le module complémentaire souhaité et être sûr qu'il sera installé dans chaque cluster, sera mis à jour et répondra aux événements dont il a besoin dans le cluster.
Flant utilise l'
opérateur d'addon sur plus de 70 clusters Kubernetes. Le statut actuel est
la version alpha . Nous préparons maintenant la documentation pour la sortie de la bêta, mais pour l'instant
, des exemples sont disponibles dans le référentiel, sur la base desquels vous pouvez créer votre addon.
Où obtenir les modules d'opérateur d'addon eux-mêmes? La publication de notre bibliothèque est la prochaine étape pour nous, nous prévoyons de le faire en été.
Vidéos et diapositives
Vidéo de la performance (~ 50 minutes):
Présentation du rapport:
PS
Autres reportages sur notre blog:
Vous pourriez également être intéressé par les publications suivantes: