
Des technologies et des modèles pour notre futur système de vision par ordinateur ont été créés et améliorés progressivement dans divers projets de notre entreprise - dans le courrier, le cloud et la recherche. Affiné comme du bon fromage ou du cognac. Une fois que nous avons réalisé que nos réseaux de neurones présentaient d'excellents résultats de reconnaissance, nous avons décidé de les regrouper en un seul produit b2b - Vision - que nous utilisons maintenant nous-mêmes et proposons de vous utiliser.
Aujourd'hui, notre technologie de vision par ordinateur sur la plateforme Mail.Ru Cloud Solutions fonctionne avec succès et résout des problèmes pratiques très complexes. Il est basé sur un certain nombre de réseaux de neurones formés sur nos ensembles de données et spécialisés dans la résolution de problèmes appliqués. Tous les services tournent sur les capacités de nos serveurs. Vous pouvez intégrer l'API Vision publique dans vos applications, grâce à laquelle toutes les fonctionnalités du service sont disponibles. L'API est rapide - grâce aux GPU du serveur, le temps de réponse moyen au sein de notre réseau est de 100 ms.
Sous la coupe, il y a une histoire détaillée et de nombreux exemples de Vision.
À titre d'exemple de service dans lequel nous utilisons nous-mêmes les technologies de reconnaissance faciale susmentionnées, nous pouvons citer les
événements . L'un de ses composants est le stand photo Vision, que nous installons lors de différentes conférences. Si vous vous rendez sur un tel support photo, prenez une photo avec l'appareil photo intégré et saisissez votre courrier, le système trouvera immédiatement parmi le tableau de photos celles dont les photographes de la conférence régulière vous ont capturé et, si vous le souhaitez, vous enverra les photos trouvées par courrier. Et il ne s'agit pas de portraits mis en scène - Vision vous reconnaît même en arrière-plan dans la foule de visiteurs. Bien sûr, ils ne sont pas reconnus par les supports de photos eux-mêmes, ce ne sont que des tablettes dans de magnifiques dessous de verre qui photographient simplement les invités sur leurs appareils photo intégrés et transmettent des informations aux serveurs, où toute la magie de la reconnaissance a lieu. Et nous avons observé à plusieurs reprises à quel point l'efficacité de la technologie est surprenante même chez les spécialistes de la reconnaissance d'image. Ci-dessous, nous parlerons de quelques exemples.
1. Notre modèle de reconnaissance faciale
1.1. Réseau de neurones et vitesse de traitement
Pour la reconnaissance, nous utilisons une modification du modèle de réseau de neurones ResNet 101. Le regroupement moyen à la fin est remplacé par une couche entièrement connectée, semblable à la façon dont cela a été fait dans ArcFace. Cependant, la taille des représentations vectorielles est de 128 et non de 512. Notre ensemble de formation contient environ 10 millions de photos de 273 593 personnes.
Le modèle fonctionne très rapidement grâce à une architecture de configuration de serveur soigneusement sélectionnée et à un calcul GPU. Il faut 100 ms pour obtenir une réponse de l'API dans nos réseaux internes - cela comprend la détection des visages (détection des visages sur la photo), la reconnaissance et le renvoi du PersonID dans la réponse de l'API. Avec de gros volumes de données entrantes - photos et vidéos - il faudra beaucoup plus de temps pour transférer des données vers le service et recevoir une réponse.
1.2. Évaluation de l'efficacité du modèle
Mais déterminer l'efficacité des réseaux de neurones est une tâche très mitigée. La qualité de leur travail dépend des ensembles de données sur lesquels les modèles ont été formés et s'ils ont été optimisés pour travailler avec des données spécifiques.
Nous avons commencé à évaluer la précision de notre modèle avec le test de vérification LFW populaire, mais il est trop petit et simple. Après avoir atteint une précision de 99,8%, il n'est plus utile. Il y a une bonne concurrence pour évaluer les modèles de reconnaissance - Megaface dessus, nous avons progressivement atteint 82% de rang 1. Le test Megaface se compose d'un million de photos - distracteurs - et le modèle devrait être capable de bien distinguer plusieurs milliers de photos de célébrités de l'ensemble de données Facescrub des distracteurs. Cependant, après avoir effacé le test d'erreurs Megaface, nous avons découvert que sur la version nettoyée, nous atteignons une précision de 98% de rang 1 (les photos de célébrités sont généralement assez spécifiques). Par conséquent, ils ont créé un test d'identification distinct, similaire à Megaface, mais avec des photos de personnes «ordinaires». Amélioré encore la précision de reconnaissance sur leurs ensembles de données et est allé de l'avant. De plus, nous utilisons le test de qualité de clustering, qui consiste en plusieurs milliers de photographies; Il simule le balisage des visages dans le cloud de l'utilisateur. Dans ce cas, les grappes sont des groupes d'individus similaires, un groupe pour chaque personne reconnaissable. Nous avons vérifié la qualité du travail sur de vrais groupes (vrai).
Bien sûr, tout modèle comporte des erreurs de reconnaissance. Mais de telles situations sont souvent résolues en affinant les seuils pour des conditions spécifiques (pour toutes les conférences, nous utilisons les mêmes seuils, et, par exemple, pour les ACS, nous devons augmenter considérablement les seuils afin qu'il y ait moins de faux positifs). La grande majorité des participants à la conférence ont été reconnus par nos supports photo Vision correctement. Parfois, quelqu'un regardait l'aperçu recadré et disait: "Votre système était faux, ce n'est pas moi." Ensuite, nous avons ouvert la photo entière, et il s'est avéré que ce visiteur était vraiment sur la photo, seulement ils ne l'ont pas prise, mais quelqu'un d'autre, juste un homme est apparu accidentellement en arrière-plan dans la zone floue. De plus, le réseau neuronal reconnaît souvent correctement même lorsqu'une partie du visage n'est pas visible, ou qu'une personne se tient de profil, ou même la moitié du visage. Le système peut reconnaître une personne, même si elle tombe dans le domaine de la distorsion optique, par exemple, lors de la prise de vue avec un objectif grand angle.
1.3. Tester des exemples dans des situations difficiles
Voici des exemples de fonctionnement de notre réseau de neurones. À l'entrée, des photos sont soumises, qu'elle doit marquer à l'aide de PersonID - un identifiant unique pour la personne. Si deux images ou plus ont le même identifiant, alors, selon les modèles, ces photos montrent une personne.
Immédiatement, nous notons que pendant les tests, nous avons accès à divers paramètres et seuils de modèles que nous pouvons configurer pour obtenir un résultat particulier. L'API publique est optimisée pour une précision maximale sur les cas courants.
Commençons par le plus simple, avec la reconnaissance faciale du visage.

Eh bien, c'était trop facile. Nous compliquons la tâche, ajoutons une barbe et une poignée d'années.

Quelqu'un dira que cela n'a pas été trop difficile, car dans les deux cas, le visage est visible dans son intégralité, l'algorithme contient beaucoup d'informations sur le visage. D'accord, mettez Tom Hardy en profil. Cette tâche est beaucoup plus compliquée et nous avons consacré beaucoup d'efforts à sa solution réussie tout en maintenant un faible niveau d'erreurs: nous avons sélectionné un échantillon d'entraînement, réfléchi à l'architecture du réseau de neurones, affiné les fonctions de perte et amélioré le traitement préliminaire des photos.
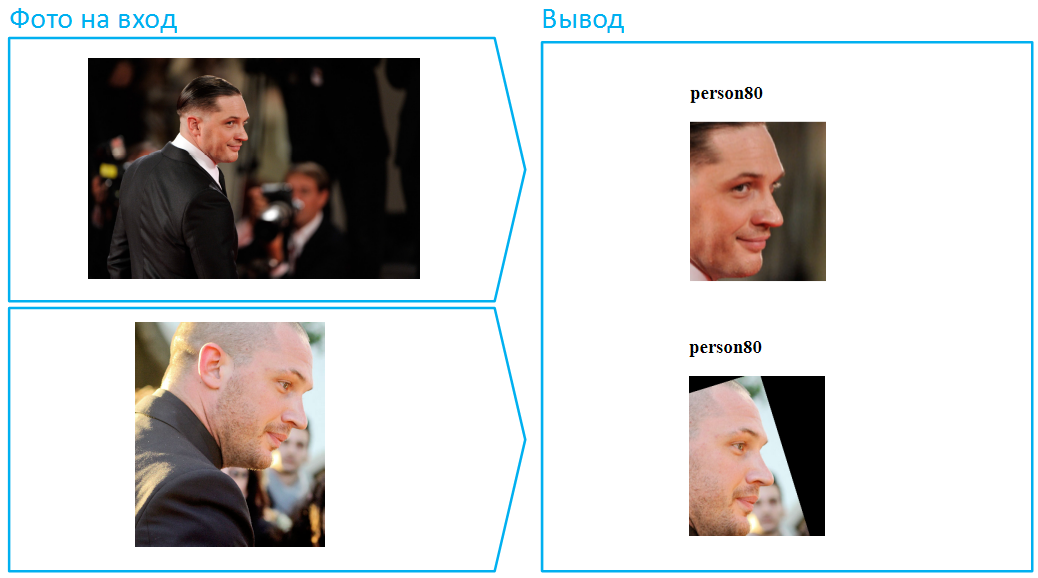
Mettons un chapeau sur lui:

Soit dit en passant, c'est un exemple d'une situation particulièrement difficile, car le visage est très couvert ici, et dans l'image inférieure il y a aussi une ombre profonde qui cache les yeux. Dans la vraie vie, les gens changent très souvent d'apparence à l'aide de lunettes noires. Faites de même avec Tom.

Eh bien, essayons de télécharger des photos d'âges différents, et cette fois, nous mettrons de l'expérience sur un autre acteur. Prenons un exemple beaucoup plus complexe lorsque les changements liés à l'âge sont particulièrement prononcés. La situation n'est pas farfelue, elle arrive tout le temps lorsque vous devez comparer une photo de votre passeport avec le visage du porteur. Après tout, la première photo est coincée dans le passeport lorsque le propriétaire a 20 ans et 45 personnes peuvent changer beaucoup:

Pensez-vous que la principale spéciale sur les missions impossibles n'a pas beaucoup changé avec l'âge? Je pense que même quelques personnes combineraient les photos du haut et du bas, le garçon a tellement changé au fil des ans.

Les réseaux de neurones sont confrontés beaucoup plus souvent à des changements d'apparence. Par exemple, parfois, les femmes peuvent changer considérablement leur image à l'aide de cosmétiques:

Maintenant, compliquons encore la tâche: laissez différentes parties du visage couvertes par différentes photos. Dans de tels cas, l'algorithme ne peut pas comparer les échantillons entiers. Cependant, Vision gère bien ces situations.
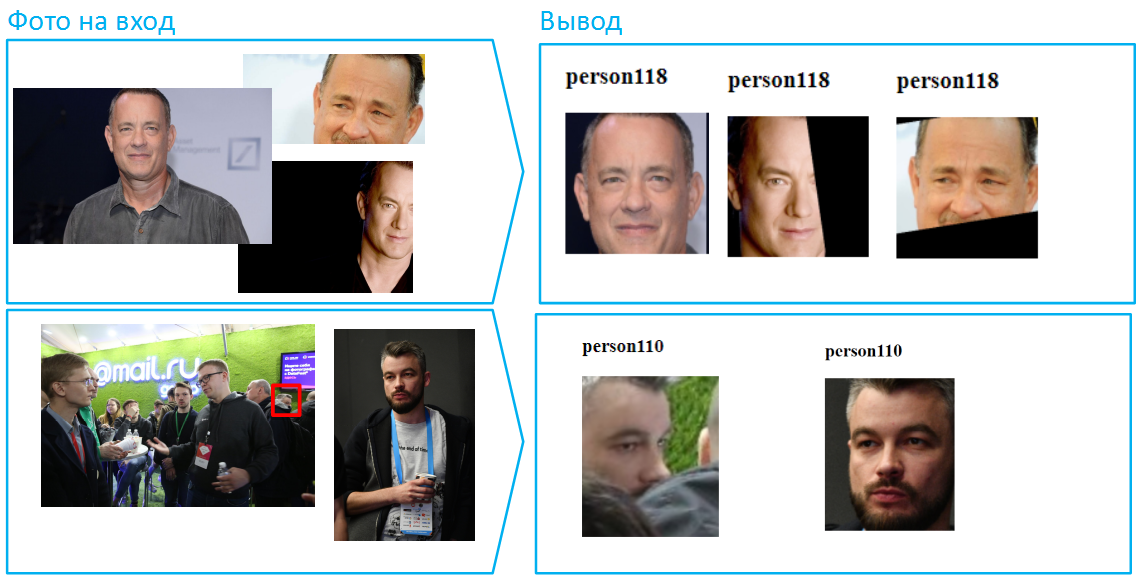
Soit dit en passant, il y a beaucoup de visages sur les photos, par exemple, plus de 100 personnes peuvent s'inscrire dans une image commune de la salle. C'est une situation difficile pour les réseaux de neurones, car de nombreux visages peuvent être éclairés différemment, quelqu'un en dehors de la zone de netteté. Cependant, si la photo a été prise avec une résolution et une qualité suffisantes (au moins 75 pixels par carré couvrant le visage), Vision pourra l'identifier et la reconnaître.

La particularité de rapporter des photographies et des images provenant de caméras de surveillance est que les gens sont souvent flous parce qu'ils étaient hors du champ de netteté ou se déplaçaient à ce moment:

De plus, l'intensité de l'éclairage peut varier considérablement d'une image à l'autre. Cela se transforme également souvent en une pierre d'achoppement, de nombreux algorithmes ont beaucoup de mal à traiter correctement des images trop sombres et trop claires, sans parler de la comparaison exacte. Permettez-moi de vous rappeler que pour atteindre un tel résultat, vous devez définir des seuils d'une certaine manière, cette possibilité n'est pas encore accessible au public. Pour tous les clients, nous utilisons le même réseau de neurones, il a des seuils adaptés à la plupart des tâches pratiques.

Récemment, nous avons déployé une nouvelle version du modèle qui reconnaît les visages asiatiques avec une grande précision. Auparavant, c'était un gros problème, qui était même appelé "racisme d'apprentissage machine" (ou "réseaux de neurones"). Les réseaux de neurones européens et américains ont bien reconnu les visages européens, et les choses étaient bien pires avec ceux mongoloïdes et négroïdes. Probablement dans la même Chine, la situation était exactement le contraire. Il s'agit de jeux de données de formation qui reflètent les types de personnes dominantes dans un pays particulier. Cependant, la situation évolue, aujourd'hui ce problème est loin d'être aussi aigu. La vision n'a pas de difficultés avec les représentants des différentes races.

La reconnaissance faciale n'est qu'une des nombreuses applications de notre technologie, la vision peut apprendre à reconnaître n'importe quoi. Par exemple, les numéros de voiture, y compris dans des conditions difficiles pour les algorithmes: à des angles aigus, des numéros sales et difficiles à lire.

2. Cas d'utilisation pratiques
2.1. Contrôle d'accès physique: lorsque deux vont sur le même col
Avec l'aide de Vision, il est possible de mettre en place des systèmes comptables pour l'arrivée et le départ des employés. Un système traditionnel basé sur des laissez-passer électroniques présente des inconvénients évidents, par exemple, vous pouvez passer deux badges ensemble. Si le système de contrôle d'accès (ACS) est complété par Vision, il enregistrera honnêtement qui va et vient quand.
2.2. Suivi du temps
Ce cas d'utilisation de Vision est étroitement lié au précédent. Si nous complétons le système de contrôle d'accès avec notre service de reconnaissance faciale, il pourra non seulement constater les violations du contrôle d'accès, mais également enregistrer le séjour réel des employés dans le bâtiment ou dans l'établissement. En d'autres termes, Vision aidera à considérer honnêtement qui et combien sont venus travailler et sont partis avec elle, et qui ont même sauté, même si ses collègues l'ont couvert devant ses supérieurs.
2.3. Analyse vidéo: suivi et sécurité des personnes
En suivant les personnes à l'aide de Vision, vous pouvez évaluer avec précision la perméabilité réelle des zones commerçantes, des gares, des passages à niveau, des rues et de nombreux autres lieux publics. Notre suivi peut également être très utile pour contrôler l'accès, par exemple, à un entrepôt ou à d'autres locaux de bureaux importants. Et bien sûr, le suivi des personnes et des visages permet de résoudre les problèmes de sécurité. Vous avez surpris quelqu'un en train de voler dans votre magasin? Ajoutez-le au PersonID, qui a renvoyé Vision, dans la liste noire de votre logiciel d'analyse vidéo, et la prochaine fois que le système alertera immédiatement la sécurité si ce type réapparaît.
2.4. Dans le commerce
Les commerces de détail et divers services sont intéressés par la reconnaissance des files d'attente. En utilisant Vision, vous pouvez reconnaître qu'il ne s'agit pas d'une foule aléatoire de personnes, mais plutôt d'une file d'attente, et déterminer sa longueur. Et puis le système informe les personnes responsables de la file d'attente afin de comprendre la situation: soit c'est un afflux de visiteurs et des employés supplémentaires doivent être appelés, soit quelqu'un pirate ses responsabilités professionnelles.
Une autre tâche intéressante est la séparation des employés de l'entreprise dans le hall des visiteurs. En règle générale, le système apprend à séparer les objets dans certains vêtements (code vestimentaire) ou avec une caractéristique distinctive (écharpe signature, badge sur la poitrine, etc.). Cela permet d'évaluer plus précisément la fréquentation (afin que les employés ne «remontent» pas à eux seuls les statistiques des personnes présentes dans la salle).
Grâce à la reconnaissance faciale, vous pouvez évaluer votre public: quelle est la fidélité des visiteurs, c'est-à-dire combien de personnes reviennent dans votre établissement et à quelle fréquence. Calculez le nombre de visiteurs uniques qui viennent vous voir en un mois. Pour optimiser les coûts d'attraction et de rétention, vous pouvez connaître et changer la fréquentation en fonction du jour de la semaine et même de l'heure.
Les franchiseurs et les sociétés de réseau peuvent demander une évaluation de la qualité de l'image de marque de divers points de vente à partir de photographies: la présence de logos, d'enseignes, d'affiches, de bannières, etc.
2.5. Sur le transport
Un autre exemple de sécurité grâce à l'analyse vidéo est l'identification des objets laissés dans les halls des aéroports ou des gares. La vision peut être formée pour reconnaître des objets de centaines de classes: meubles, sacs, valises, parapluies, différents types de vêtements, bouteilles, etc. Si votre système d'analyse vidéo détecte un objet sans propriétaire et le reconnaît à l'aide de Vision, il envoie un signal au service de sécurité. Une tâche similaire est liée à la détection automatique des situations non standard dans les lieux publics: quelqu'un est tombé malade, ou quelqu'un a fumé au mauvais endroit, ou la personne est tombée sur les rails, etc. - tous ces modèles du système d'analyse vidéo peuvent reconnaître grâce à l'API Vision.
2.6. Workflow
Une autre future application intéressante de Vision que nous développons actuellement est la reconnaissance de documents et leur analyse automatique dans des bases de données. Au lieu de conduire manuellement (ou pire encore, d'entrer) des séries, des numéros, des dates d'émission, des numéros de compte, des coordonnées bancaires, des dates et des lieux de naissance sans fin et de nombreuses autres données formalisées, vous pouvez numériser des documents et les envoyer automatiquement via un canal sécurisé via l'API dans le cloud, où le système sera à la volée, ces documents seront reconnus, analysés et renverront une réponse avec des données au format souhaité pour une entrée automatique dans la base de données. Aujourd'hui, Vision sait déjà comment classer les documents (y compris en PDF) - il distingue les passeports, les SNILS, les TIN, les certificats de naissance, les certificats de mariage et autres.
Bien sûr, toutes ces situations que le réseau neuronal n'est pas en mesure de gérer hors de la boîte. Dans chaque cas, un nouveau modèle est construit pour un client particulier, de nombreux facteurs, nuances et exigences sont pris en compte, les ensembles de données sont sélectionnés, les paramètres de test de formation sont itérés.
3. Schéma de fonctionnement de l'API
La «porte d'entrée» de Vision pour les utilisateurs est l'API REST. À l'entrée, il peut prendre des photos, des fichiers vidéo et des émissions à partir de caméras réseau (flux RTSP).
Pour utiliser Vision, vous devez vous
inscrire dans Mail.ru Cloud Solutions et obtenir des jetons d'accès (client_id + client_secret). L'authentification des utilisateurs est effectuée à l'aide du protocole OAuth. Les données source dans les corps des requêtes POST sont envoyées à l'API. Et en réponse, le client reçoit le résultat de la reconnaissance de l'API au format JSON, et la réponse est structurée: elle contient des informations sur les objets trouvés et leurs coordonnées.

Exemple de réponse{ "status":200, "body":{ "objects":[ { "status":0, "name":"file_0" }, { "status":0, "name":"file_2", "persons":[ { "tag":"person9" "coord":[149,60,234,181], "confidence":0.9999, "awesomeness":0.45 }, { "tag":"person10" "coord":[159,70,224,171], "confidence":0.9998, "awesomeness":0.32 } ] } { "status":0, "name":"file_3", "persons":[ { "tag":"person11", "coord":[157,60,232,111], "aliases":["person12", "person13"] "confidence":0.9998, "awesomeness":0.32 } ] }, { "status":0, "name":"file_4", "persons":[ { "tag":"undefined" "coord":[147,50,222,121], "confidence":0.9997, "awesomeness":0.26 } ] } ], "aliases_changed":false }, "htmlencoded":false, "last_modified":0 }
La réponse a un paramètre génial intéressant - c'est la «fraîcheur» conditionnelle du visage sur la photo, avec elle nous sélectionnons le meilleur visage tiré de la séquence. Nous avons formé le réseau neuronal pour prédire la probabilité que l'image ressemble à celle des réseaux sociaux. Plus la photo est bonne et plus le visage est lisse, plus la génialité est grande.
L'API Vision utilise un concept tel que l'espace. Il s'agit d'un outil pour créer différents ensembles de faces. Des exemples d'espaces sont des listes noires et blanches, des listes de visiteurs, d'employés, de clients, etc. Pour chaque jeton dans Vision, vous pouvez créer jusqu'à 10 espaces, dans chaque espace, il peut y avoir jusqu'à 50 000 PersonID, c'est-à-dire jusqu'à 500 000 pour un jeton. . De plus, le nombre de jetons par compte n'est pas limité.
Aujourd'hui, l'API prend en charge les méthodes de détection et de reconnaissance suivantes:
- Reconnaître / Définir - définition et reconnaissance des visages. Attribue automatiquement un PersonID à chaque visage unique, renvoie le PersonID et les coordonnées des visages trouvés.
- Supprimer - supprime un PersonID spécifique de la base de données des personnes.
- Tronquer - effacer tout l'espace de PersonID, utile s'il a été utilisé comme test et que vous devez réinitialiser la base de production.
- Détecter - définition des objets, scènes, plaques d'immatriculation, attractions, files d'attente, etc. Renvoie la classe des objets trouvés et leurs coordonnées
- Détecter pour les documents - détecte des types spécifiques de documents de la Fédération de Russie (distingue passeport, snls, auberge, etc.).
En outre, nous terminerons bientôt les travaux sur les méthodes d'OCR, déterminant le sexe, l'âge et les émotions, ainsi que la résolution des tâches de marchandisage, c'est-à-dire de contrôler automatiquement l'affichage des marchandises dans les magasins. Vous pouvez trouver la documentation complète de l'API ici:
https://mcs.mail.ru/help/vision-api4. Conclusion
Maintenant, via l'API publique, vous pouvez accéder à la reconnaissance faciale dans les photos et les vidéos, elle prend en charge la définition de divers objets, numéros de voiture, attractions, documents et scènes entières. Scénarios d'application - Mer. Venez tester notre service, définissez-lui les tâches les plus délicates. Les 5000 premières transactions sont gratuites. Ce peut être «l'ingrédient manquant» pour vos projets.
L'accès à l'API peut être obtenu instantanément lors de l'inscription et de la connexion à
Vision . Tous les utilisateurs Habra - un code promotionnel pour des transactions supplémentaires. Écrivez une adresse e-mail personnelle à laquelle le compte a été enregistré!