Bonjour mes amis! Le cours
"Sécurité des systèmes d'information" a été lancé, en lien avec cela nous partageons avec vous la dernière partie de l'article "Fondamentaux des moteurs JavaScript: optimisation des prototypes", dont la première partie peut être lue
ici .
Nous vous rappelons également que la publication actuelle est une continuation de ces deux articles:
«Fondamentaux des moteurs JavaScript: formulaires généraux et mise en cache en ligne. Partie 1 " ,
" Principes de base des moteurs JavaScript: formulaires généraux et mise en cache en ligne. Partie 2 " .
 Cours et programmation de prototypes
Cours et programmation de prototypesMaintenant que nous savons comment accéder rapidement aux propriétés des objets JavaScript, nous pouvons jeter un œil à la structure plus complexe des classes JavaScript. Voici à quoi ressemble la syntaxe des classes en JavaScript:
class Bar { constructor(x) { this.x = x; } getX() { return this.x; } }
Bien que cela semble être un concept relativement nouveau pour JavaScript, il ne s'agit que de «sucre syntaxique» pour le prototype de programmation qui a toujours été utilisé en JavaScript:
function Bar(x) { this.x = x; } Bar.prototype.getX = function getX() { return this.x; };
Ici, nous
getX propriété
getX à l'objet
getX . Cela fonctionnera comme avec tout autre objet, car les prototypes en JavaScript sont les mêmes objets. Dans les langages de programmation de prototypes tels que JavaScript, les méthodes sont accessibles via des prototypes, tandis que les champs sont stockés dans des instances spécifiques.
Examinons de plus près ce qui se passe lorsque nous créons une nouvelle instance de
Bar , que nous appellerons
foo .
const foo = new Bar(true);
Une instance créée à l'aide de ce code a un formulaire avec une seule propriété
'x' . Le prototype
foo est
Bar.prototype , qui appartient à la classe
Bar .
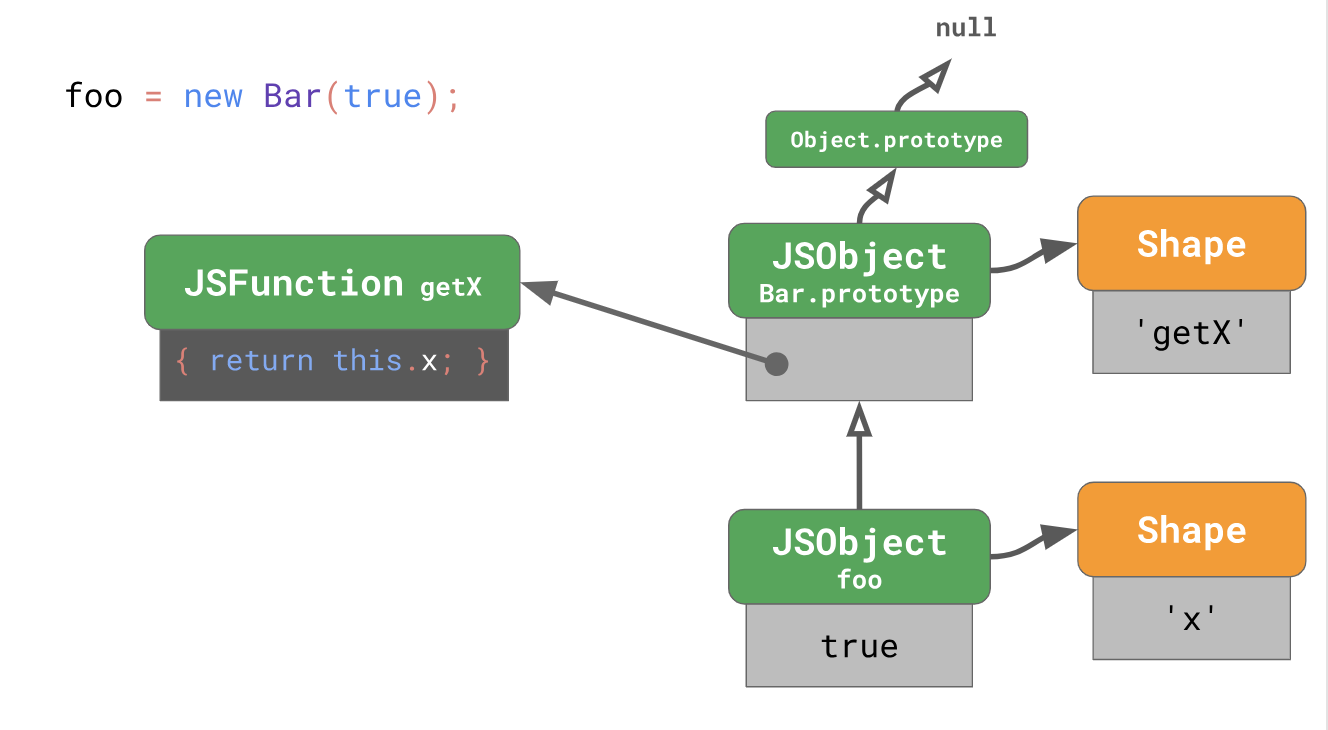
Ce
Bar.prototype a la forme de lui-même, contenant la seule propriété
'getX' , dont la valeur est déterminée par la fonction
'getX' qui, lorsqu'elle est appelée, renvoie
this.x Le prototype
Bar.prototype est
Object.prototype , qui fait partie du langage JavaScript.
Object.prototype est la racine de l'arbre du prototype, tandis que son prototype est
null .

Lorsque vous créez une nouvelle instance de la même classe, les deux instances ont la même forme, comme nous l'avons déjà compris. Les deux instances pointeront vers le même objet
Bar.prototype .
Accéder aux propriétés du prototypeEh bien, maintenant nous savons ce qui se passe lorsque nous définissons une classe et créons une nouvelle instance. Mais que se passe-t-il si nous appelons la méthode sur l'instance, comme nous l'avons fait dans l'exemple suivant?
class Bar { constructor(x) { this.x = x; } getX() { return this.x; } } const foo = new Bar(true); const x = foo.getX();
Vous pouvez considérer tout appel de méthode comme deux étapes distinctes:
const x = foo.getX();
La première étape consiste à charger la méthode, qui est en fait une propriété du prototype (dont la valeur est une fonction). La deuxième étape consiste à appeler une fonction avec une instance, par exemple, la valeur de
this . Examinons de plus près la première étape où la méthode
getX est
getX partir de l'instance
foo .

Le moteur démarre une instance de
foo et se rend compte que le formulaire
foo n'a pas
'getX' , il doit donc passer par la chaîne de prototype pour le trouver. Nous
Bar.prototype à
Bar.prototype , regardons la forme du prototype, voyons qu'elle a la propriété
'getX' à zéro décalage. Nous recherchons la valeur de ce décalage dans
Bar.prototype et trouvons la
JSFunction getX que nous recherchions.
La flexibilité de JavaScript permet aux prototypes de maillons de chaîne de changer, par exemple:
const foo = new Bar(true); foo.getX();
Dans cet exemple, nous appelons
foo.getX()
deux fois, mais à chaque fois il a des significations et des résultats complètement différents. C'est pourquoi, malgré le fait que les prototypes ne sont que des objets en JavaScript, accélérer l'accès aux propriétés d'un prototype est une tâche encore plus importante pour les moteurs JavaScript que d'accélérer leur propre accès aux propriétés des objets normaux.
Dans la pratique quotidienne, le chargement des propriétés d'un prototype est une opération assez courante: cela se produit chaque fois que vous appelez une méthode!
class Bar { constructor(x) { this.x = x; } getX() { return this.x; } } const foo = new Bar(true); const x = foo.getX();
Plus tôt, nous avons expliqué comment les moteurs optimisent le chargement des propriétés régulières à l'aide de formulaires et de caches en ligne. Comment puis-je optimiser le chargement des propriétés du prototype pour des objets de même forme? D'en haut, nous avons vu comment les propriétés sont chargées.

Pour ce faire rapidement avec des téléchargements répétés dans ce cas particulier, vous devez connaître les trois choses suivantes:
- Le formulaire
foo ne contient pas 'getX' et il n'a pas changé. Cela signifie que personne n'a modifié l'objet foo en ajoutant ou en supprimant une propriété ou en modifiant l'un des attributs de propriété. - Le prototype foo est toujours le
Bar.prototype original. Donc, personne n'a changé le prototype foo utilisant Object.setPrototypeOf() ou en l'affectant à la propriété spéciale _proto_ . - Le formulaire
Bar.prototype contient 'getX' et n'a pas changé. Cela signifie que personne n'a modifié Bar.prototype en ajoutant ou en supprimant une propriété ou en modifiant l'un des attributs de propriété.
Dans le cas général, cela signifie que vous devez effectuer une vérification de l'instance elle-même et deux vérifications supplémentaires pour chaque prototype jusqu'au prototype qui contient la propriété souhaitée. Les vérifications 1 + 2N, où N est le nombre de prototypes utilisés, ne sonnent pas si mal dans ce cas, car la chaîne de prototypes est relativement peu profonde. Cependant, les moteurs doivent souvent gérer des chaînes de prototypes beaucoup plus longues, comme c'est le cas avec les classes DOM régulières. Par exemple:
const anchor = document.createElement('a');
Nous avons un
HTMLAnchorElement et nous appelons la méthode
getAttribute() . La chaîne de cet élément simple comprend déjà 6 prototypes! La plupart des méthodes DOM qui nous intéressent ne se trouvent pas dans le prototype
HTMLAnchorElement -
HTMLAnchorElement , mais quelque part dans la chaîne.

La méthode
getAttribute() trouve dans
Element.prototype . Cela signifie que chaque fois que nous appelons
anchor.getAttribute() , le moteur JavaScript a besoin:
- Vérifiez que
'getAttribute' pas un objet d' anchor soi; - Vérifiez que le prototype final est
HTMLAnchorElement.prototype ; - Confirmez l'absence de
'getAttribute' là-bas; - Vérifiez que le prochain prototype est
HTMLElement.prototype ; - Confirmez à nouveau l'absence de
'getAttribute' ; - Vérifiez que le prochain prototype est
Element.prototype ; - Vérifiez que
'getAttribute' présent.
Un total de 7 chèques. Étant donné que ce type de code est assez courant sur le Web, les moteurs utilisent diverses astuces pour réduire le nombre de contrôles requis pour charger les propriétés du prototype.
Revenons à un exemple précédent dans lequel nous n'avions effectué que trois vérifications lors de la demande de
'getX' pour
foo :
class Bar { constructor(x) { this.x = x; } getX() { return this.x; } } const foo = new Bar(true); const $getX = foo.getX;
Pour chaque objet apparaissant avant le prototype contenant la propriété souhaitée, il est nécessaire de vérifier les formes pour l'absence de cette propriété. Ce serait bien si nous pouvions réduire le nombre de contrôles en présentant le prototype de chèque comme un contrôle de l'absence de propriété. En substance, c'est exactement ce que font les moteurs avec une astuce simple: au lieu de stocker le lien prototype vers l'instance elle-même, les moteurs le stockent sous forme.
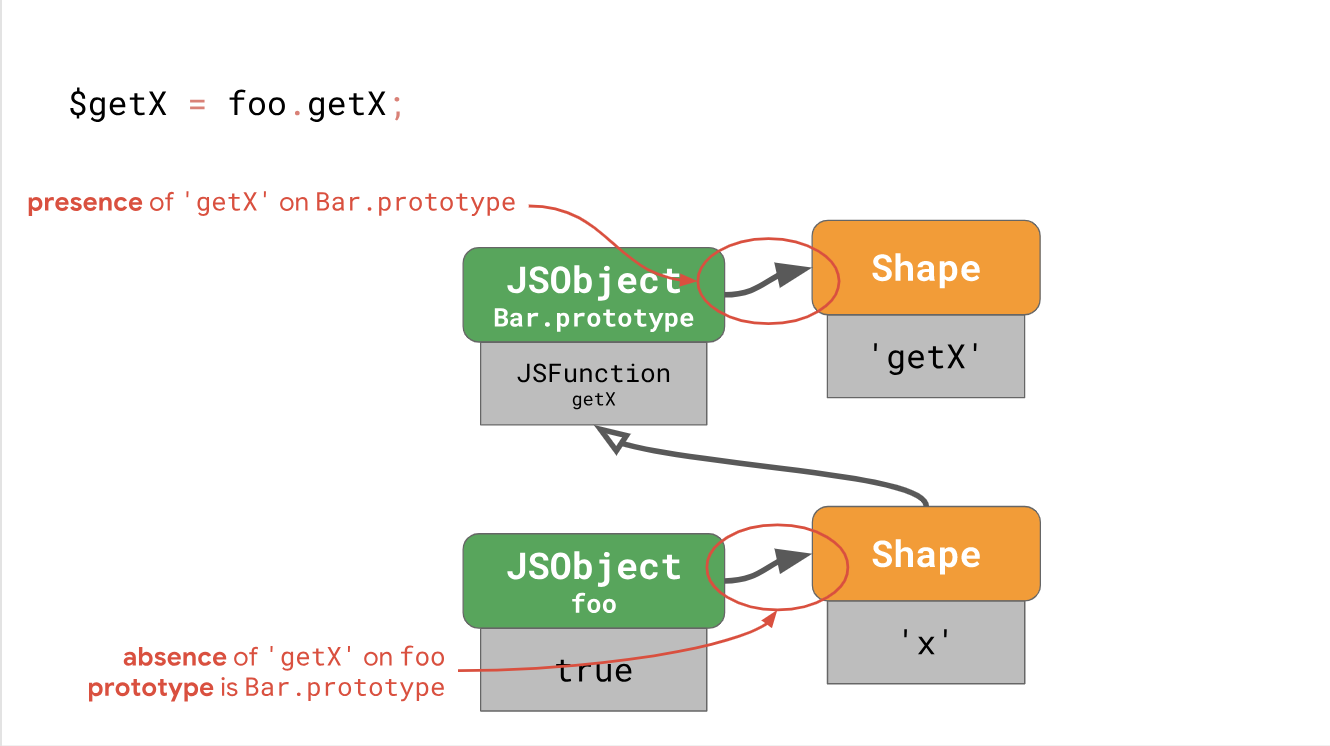
Chaque formulaire indique un prototype. Cela signifie que chaque fois que le prototype change, le moteur passe à une nouvelle forme. Nous devons maintenant vérifier uniquement la forme de l'objet pour confirmer l'absence de certaines propriétés, ainsi que protéger le lien prototype (protéger le lien prototype).
Avec cette approche, nous pouvons réduire le nombre de contrôles requis de 2N + 1 à 1 + N pour accélérer l'accès. C'est toujours une opération assez coûteuse, car c'est toujours une fonction linéaire du nombre de prototypes dans la chaîne. Les moteurs utilisent diverses astuces pour réduire davantage le nombre de contrôles à une certaine valeur constante, en particulier dans le cas d'un chargement séquentiel des mêmes propriétés.
Cellules de validitéLe V8 traite des formulaires prototypes spécialement à cet effet. Chaque prototype a une forme unique qui n'est pas partagée avec d'autres objets (en particulier, avec d'autres prototypes), et chacune de ces formes de prototype a une
ValidityCell spéciale qui lui est associée.
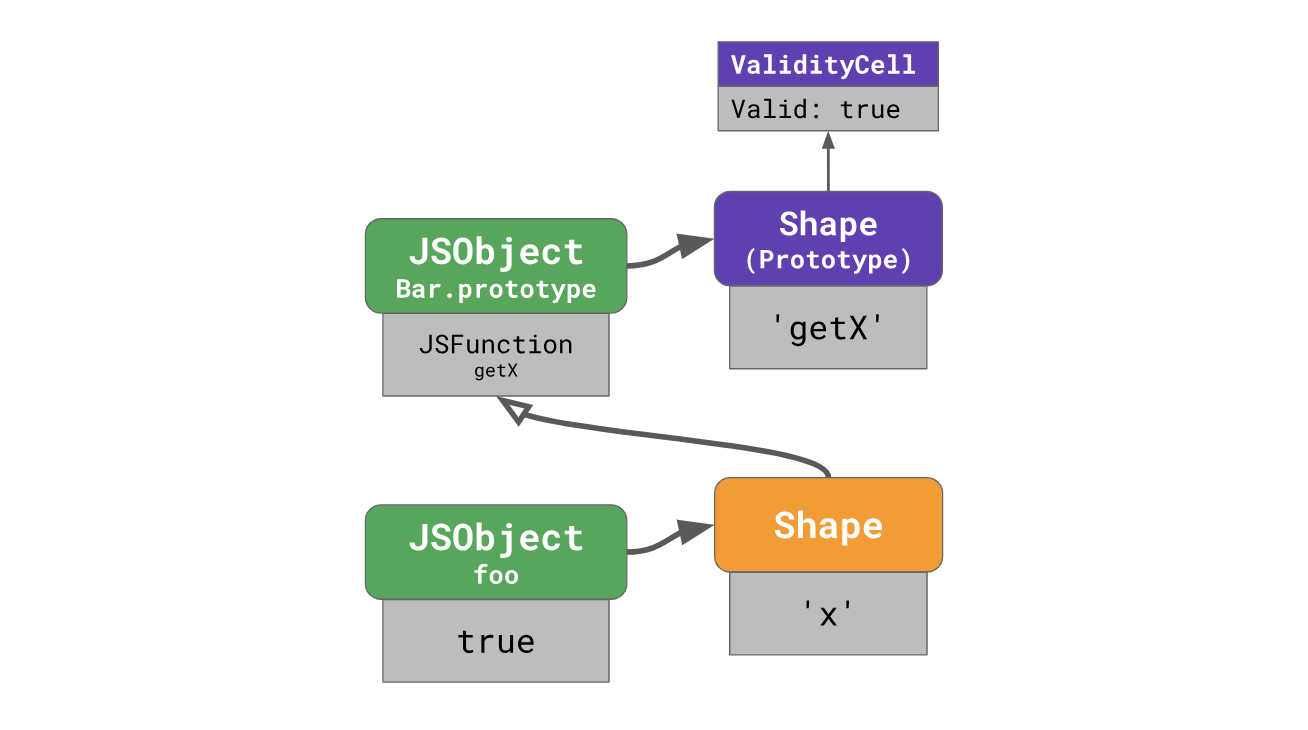
Cette
ValidityCell désactivée à chaque fois que quelqu'un change le prototype qui lui est associé ou tout autre prototype au-dessus. Voyons comment cela fonctionne.
Pour accélérer les téléchargements de prototypes ultérieurs, V8 place le cache en ligne dans un emplacement à quatre champs:
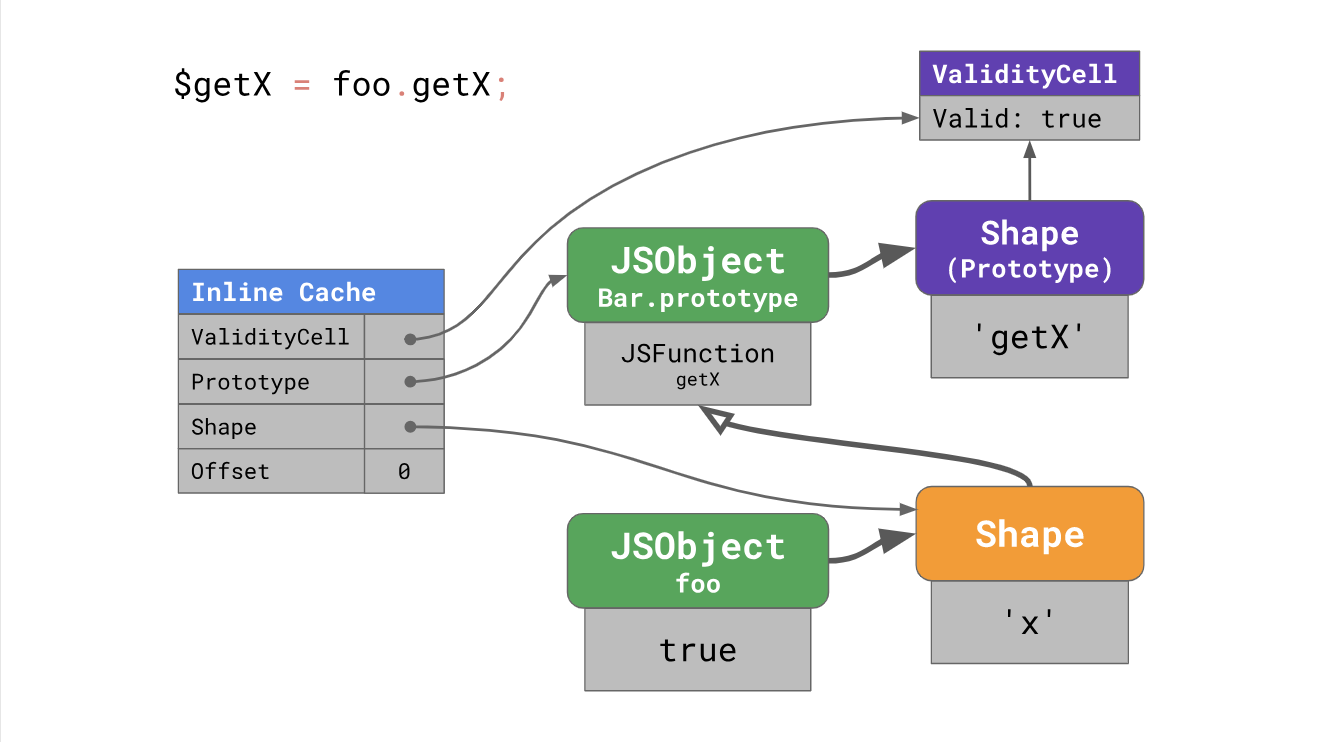
Lorsque le cache en ligne est chauffé la première fois que le code est exécuté, V8 se souvient de l'offset auquel la propriété a été trouvée dans le prototype, ce prototype (par exemple,
Bar.prototype ), le formulaire d'instance (dans notre cas, le formulaire
foo ), et lie également la
ValidityCell actuelle au prototype reçu à partir de l'instance du formulaire (dans notre cas,
Bar.prototype est pris).
La prochaine fois que vous utiliserez le cache en ligne, le moteur devra vérifier le formulaire d'instance et
ValidityCell . S'il est toujours valide, le moteur utilise directement l'offset sur le prototype, ignorant les étapes de recherche supplémentaires.
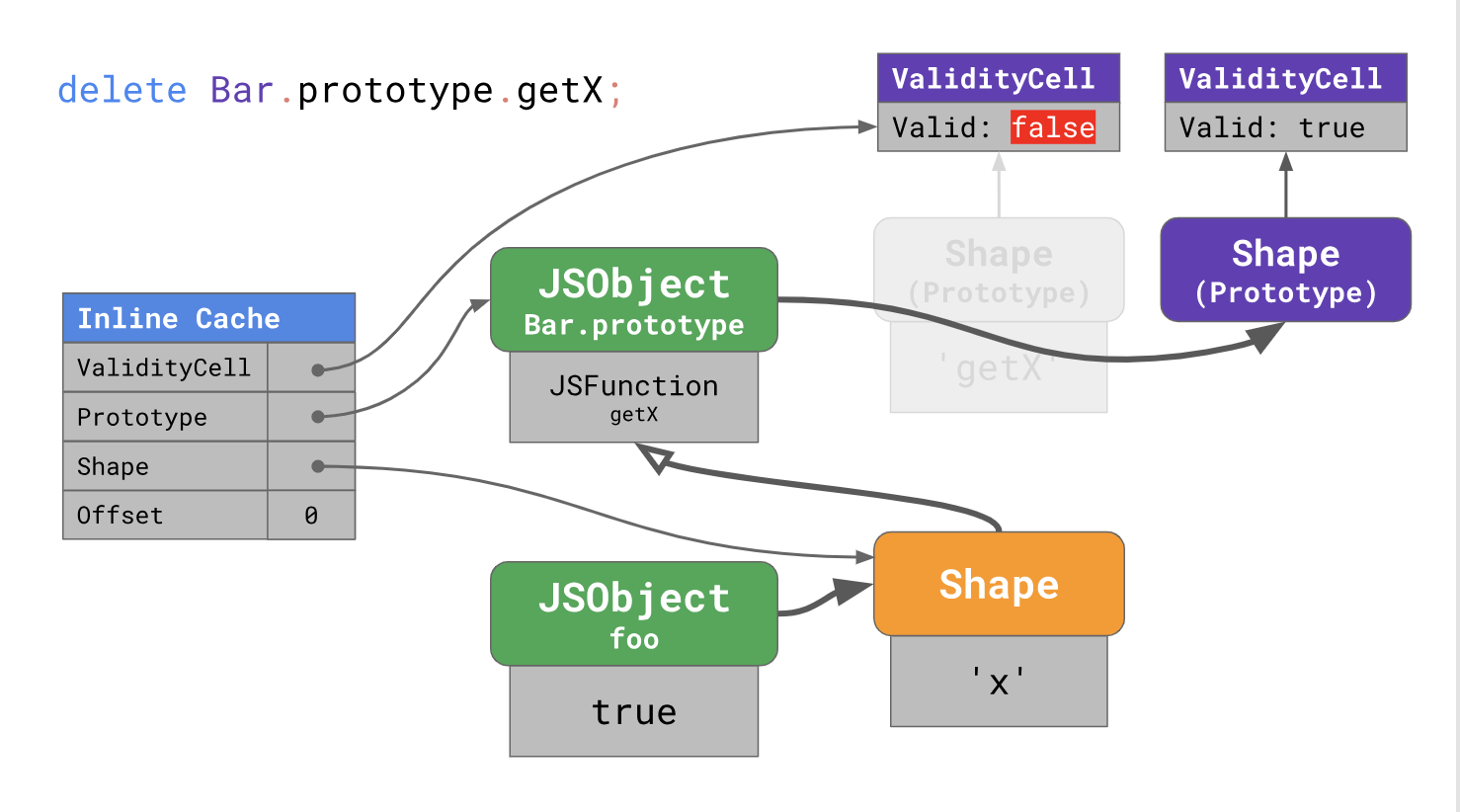
Lorsque vous modifiez le prototype, un nouveau formulaire est mis en surbrillance et la cellule
ValidityCell précédente est désactivée. Pour cette raison, le cache en ligne est ignoré au prochain démarrage, ce qui entraîne des performances médiocres.
Revenons à l'exemple avec l'élément DOM. Chaque modification dans
Object.prototype invalide non seulement les caches en ligne pour
Object.prototype , mais aussi pour tout prototype dans la chaîne en dessous, y compris
EventTarget.prototype ,
Node.prototype ,
Element.prototype , etc., jusqu'à
HTMLAnchorElement.prototype lui-même.
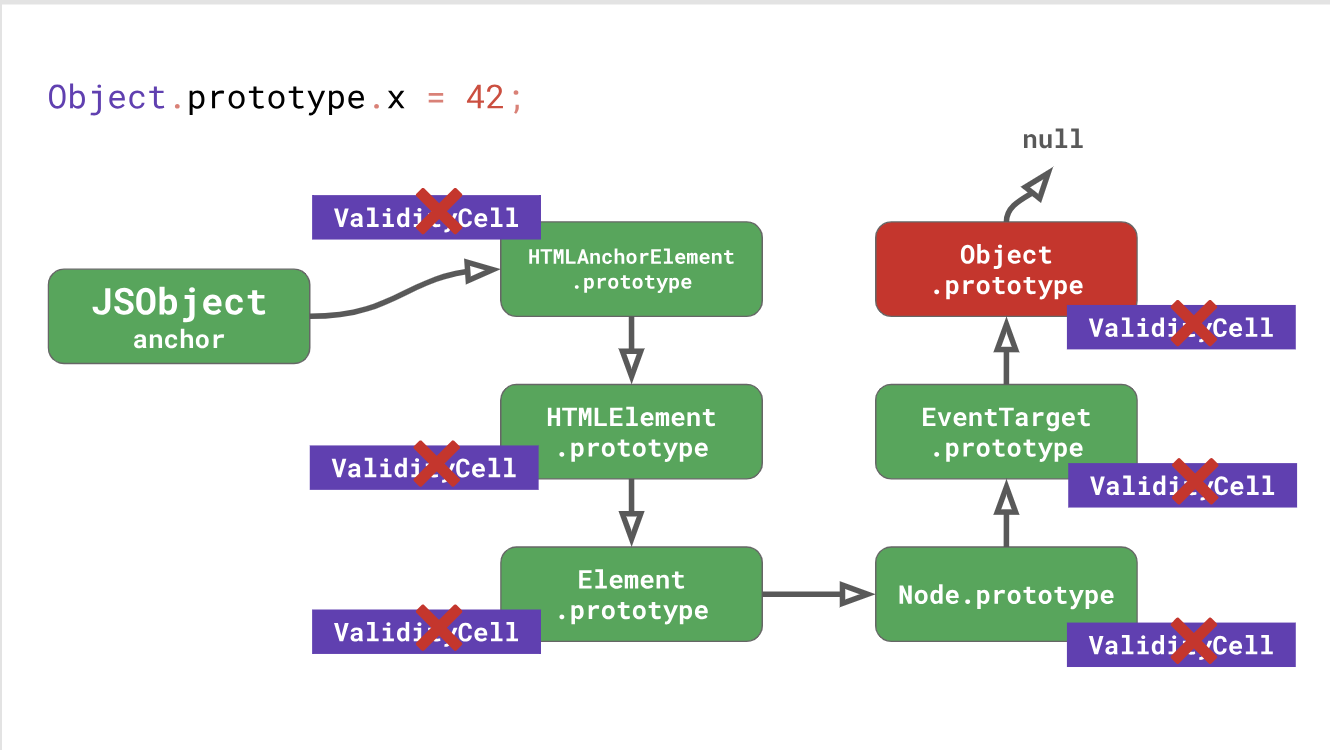
En fait, la modification de
Object.prototype pendant que le code s'exécute est une perte de performance terrible. Ne fais pas ça!
Regardons un exemple spécifique pour mieux comprendre comment cela fonctionne. Disons que nous avons une classe
Bar et une fonction
loadX qui appelle une méthode sur des objets de type
Bar . Nous appelons la fonction
loadX plusieurs fois avec des instances de la même classe.
class Bar { } function loadX(bar) { return bar.getX();
Le cache en ligne dans
loadX pointe désormais vers
ValidityCell pour
Bar.prototype . Si vous modifiez ensuite le (Object)
Object.prototype , qui est la racine de tous les prototypes en JavaScript,
ValidityCell devient invalide et les caches Inline existants ne seront pas utilisés la prochaine fois, ce qui entraînera de mauvaises performances.
Changer
Object.prototype est toujours une mauvaise idée, car il invalide tous les caches Inline pour les prototypes chargés au moment du changement. Voici un exemple de comment NE PAS faire:
Object.prototype.foo = function() { };
Nous développons
Object.prototype , qui invalide tous les caches de prototypes Inline chargés par le moteur à ce stade. Ensuite, nous exécuterons du code qui utilise la méthode décrite par nous. Le moteur devra démarrer dès le début et configurer les caches Inline pour tout accès à la propriété prototype. Et puis, enfin, «nettoyer» et supprimer la méthode prototype que nous avons ajoutée précédemment.
Vous pensez que le nettoyage est une bonne idée, non? Eh bien, dans ce cas, cela aggravera encore la situation! La suppression des propriétés modifie
Object.prototype , de sorte que tous les caches Inline sont à nouveau désactivés et que le moteur doit recommencer à travailler depuis le début.
Pour résumer . Bien que les prototypes ne soient que des objets, ils sont spécialement traités par des moteurs JavaScript afin d'optimiser les performances des recherches de méthodes par prototypes.
Laissez les prototypes tranquilles! Ou si vous avez vraiment besoin de les gérer, faites-le avant d'exécuter le code, vous n'invaliderez donc pas toutes les tentatives d'optimisation de votre code lors de son exécution!
Résumer
Nous avons appris comment JavaScript stocke les objets et les classes, et comment les formulaires, les caches en ligne et les cellules de validité aident à optimiser les opérations du prototype. Sur la base de ces connaissances, nous avons compris comment améliorer les performances d'un point de vue pratique: ne touchez pas aux prototypes! (ou si vous en avez vraiment besoin, faites-le avant d'exécuter le code).
←
La première partieCette série de publications vous a-t-elle été utile? Écrivez dans les commentaires.