Bonjour Je m'appelle Ibadov Ilkin, je suis étudiant à l'Université fédérale de l'Oural.
Dans cet article, je veux parler de mon expérience avec la solution automatisée pour captcha de Google - "reCAPTCHA". Je tiens à avertir le lecteur à l'avance qu'au moment de la rédaction de l'article, le prototype ne fonctionne pas aussi efficacement qu'il pourrait sembler d'après le titre, cependant, le résultat démontre que l'approche mise en œuvre est capable de résoudre le problème.
Probablement tout le monde dans sa vie est tombé sur un captcha: saisir du texte à partir d'une image, résoudre une expression simple ou une équation complexe, choisir des voitures, des bornes d'incendie, des passages pour piétons ... La protection des ressources contre les systèmes automatisés est nécessaire et joue un rôle important dans la sécurité: le captcha protège contre les attaques DDoS , les enregistrements et les publications automatiques, l'analyse, empêche la sélection du spam et du mot de passe pour les comptes.
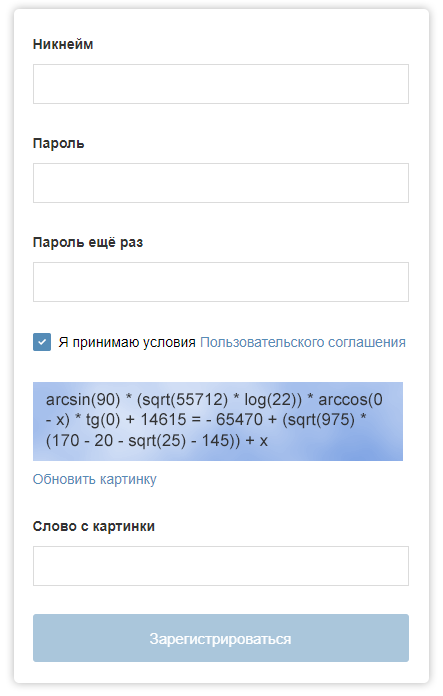 Le formulaire d'inscription sur "Habré" pourrait être avec un tel captcha.
Le formulaire d'inscription sur "Habré" pourrait être avec un tel captcha.Avec le développement des technologies d'apprentissage automatique, les performances du captcha peuvent être menacées. Dans cet article, je décris les points clés d'un programme qui peut résoudre le problème de la sélection manuelle d'images dans Google reCAPTCHA (heureusement, pas toujours jusqu'à présent).
Pour traverser le captcha, il est nécessaire de résoudre des problèmes tels que: déterminer la classe de captcha requise, détecter et classer les objets, détecter les cellules de captcha, imiter les activités humaines pour résoudre le captcha (mouvement du curseur, cliquez).
Pour rechercher des objets dans une image, des réseaux de neurones entraînés peuvent être téléchargés sur un ordinateur et reconnaître des objets dans des images ou des vidéos. Mais pour résoudre le captcha, il ne suffit pas de détecter des objets: vous devez déterminer la position des cellules et savoir quelles cellules vous souhaitez sélectionner (ou ne pas sélectionner de cellules du tout). Pour cela, des outils de vision par ordinateur sont utilisés: dans ce travail, il s'agit de la célèbre
bibliothèque OpenCV .
Pour trouver des objets dans l'image, premièrement, l'image elle-même est requise.
J'obtiens une capture d'écran d'une partie de l'écran en utilisant le module
PyAutoGUI avec des dimensions suffisantes pour détecter des objets. Dans le reste de l'écran, j'affiche des fenêtres de débogage et de surveillance des processus du programme.
Détection d'objets
La détection et la classification des objets est ce que fait le réseau neuronal. La bibliothèque qui nous permet de travailler avec des réseaux de neurones s'appelle "
Tensorflow " (développée par Google). Aujourd'hui,
il existe de nombreux modèles formés différents pour votre choix
sur différentes données , ce qui signifie que tous peuvent renvoyer un résultat de détection différent: certains modèles détecteront mieux les objets et d'autres moins.
Dans cet article, j'utilise le modèle ssd_mobilenet_v1_coco. Le modèle sélectionné a été formé sur l'ensemble de données
COCO , qui met en évidence 90 classes différentes (des personnes et des voitures aux brosses à dents et peignes). Maintenant, il existe d'autres modèles qui sont formés sur les mêmes données, mais avec des paramètres différents. De plus, ce modèle a des paramètres de performance et de précision optimaux, ce qui est important pour un ordinateur de bureau. La source indique que le temps de traitement d'une image de 300 x 300 pixels est de 30 millisecondes. Sur le "Nvidia GeForce GTX TITAN X".
Le résultat du réseau neuronal est un ensemble de tableaux:
- avec une liste des classes d'objets détectés (leurs identifiants);
- avec une liste des évaluations des objets détectés (en pourcentage);
- avec une liste de coordonnées des objets détectés ("cases").
Les indices des éléments dans ces tableaux correspondent les uns aux autres, c'est-à-dire que le troisième élément du tableau des classes d'objets correspond au troisième élément du tableau des "boîtes" des objets détectés et le troisième élément du tableau des évaluations d'objets.
 Le modèle sélectionné vous permet de détecter des objets de 90 classes en temps réel.
Le modèle sélectionné vous permet de détecter des objets de 90 classes en temps réel.Détection cellulaire
«OpenCV» nous permet de fonctionner avec des entités appelées «
circuits »: elles ne peuvent être détectées que par la fonction «findContours ()» de la bibliothèque «OpenCV». Il est nécessaire de soumettre une image binaire à l'entrée d'une telle fonction, qui peut être obtenue
par la fonction de transformation de seuil :
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY) contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
Après avoir défini les valeurs extrêmes des paramètres de la fonction de transformation de seuil, nous nous débarrassons également de divers types de bruit. De plus, pour minimiser la quantité de petits éléments inutiles et le bruit,
des transformations morphologiques peuvent être appliquées: fonctions d'érosion (compression) et d'accumulation (expansion). Ces fonctions font également partie d'OpenCV. Après les transformations, les contours sont sélectionnés dont le nombre de sommets est de quatre (ayant précédemment effectué la fonction d'
approximation sur les contours).
 Dans la première fenêtre, le résultat de la transformation de seuil. Le second est un exemple de transformation morphologique. Dans la troisième fenêtre, les cellules et le capuchon captcha sont déjà sélectionnés: mis en surbrillance en couleur par programmation.
Dans la première fenêtre, le résultat de la transformation de seuil. Le second est un exemple de transformation morphologique. Dans la troisième fenêtre, les cellules et le capuchon captcha sont déjà sélectionnés: mis en surbrillance en couleur par programmation.Après toutes les transformations, les contours qui ne sont pas des cellules tombent toujours dans le tableau final avec des cellules. Afin de filtrer les bruits inutiles, je sélectionne en fonction des valeurs de la longueur (périmètre) et de l'aire des contours.
Il a été révélé expérimentalement que les valeurs des circuits d'intérêt se situent dans la plage de 360 à 900 unités. Cette valeur est sélectionnée à l'écran avec une diagonale de 15,6 pouces et une résolution de 1366 x 768 pixels. En outre, les valeurs indiquées des contours peuvent être calculées en fonction de la taille de l'écran de l'utilisateur, mais il n'existe aucun lien de ce type dans le prototype en cours de création.
Le principal avantage de l'approche choisie pour détecter les cellules est que nous ne nous soucions pas à quoi ressemblera la grille et combien de cellules seront affichées sur la page captcha: 8, 9 ou 16.
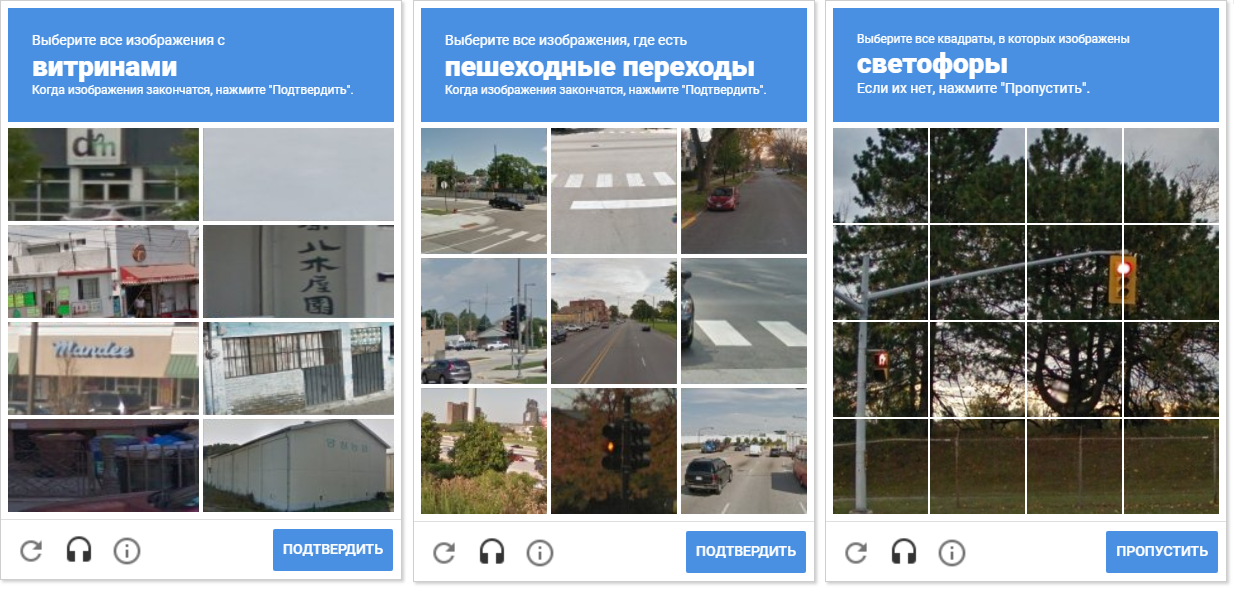 L'image montre une variété de filets captcha. Veuillez noter que la distance entre les cellules est différente. Séparer les cellules les unes des autres permet une compression morphologique.
L'image montre une variété de filets captcha. Veuillez noter que la distance entre les cellules est différente. Séparer les cellules les unes des autres permet une compression morphologique.Un avantage supplémentaire de la détection des contours est qu'OpenCV nous permet de détecter leurs centres (nous en avons besoin pour déterminer les coordonnées de mouvement et de clic de souris).
Sélection des cellules à sélectionner
Ayant une matrice avec des contours propres de cellules CAPTCHA sans circuits de bruit inutiles, nous pouvons parcourir chaque cellule CAPTCHA («circuit» dans la terminologie «OpenCV») et vérifier si elle croise la «boîte» détectée de l'objet reçu du réseau neuronal.
Pour établir ce fait, le transfert de la «boîte» détectée vers un circuit similaire aux cellules a été utilisé. Mais cette approche s'est avérée erronée, car le cas où l'objet se trouve à l'intérieur de la cellule n'est pas considéré comme une intersection. Naturellement, ces cellules ne se démarquent pas dans le captcha.
Le problème a été résolu en redessinant le contour de chaque cellule (avec remplissage blanc) sur une feuille noire. De façon similaire, une image binaire d'un cadre avec un objet a été obtenue. La question se pose - comment établir maintenant le fait de l'intersection de la cellule avec le cadre ombré de l'objet? A chaque itération d'un tableau avec des cellules, une opération de disjonction (logique ou) est effectuée sur deux images binaires. En conséquence, nous obtenons une nouvelle image binaire dans laquelle les zones intersectées seront mises en évidence. Autrement dit, s'il existe de telles zones, la cellule et le cadre de l'objet se croisent. Par programmation, une telle vérification peut être effectuée en utilisant la méthode «
.any () »: elle retournera «True» si le tableau a au moins un élément égal à un ou «False» s'il n'y a pas d'unités.
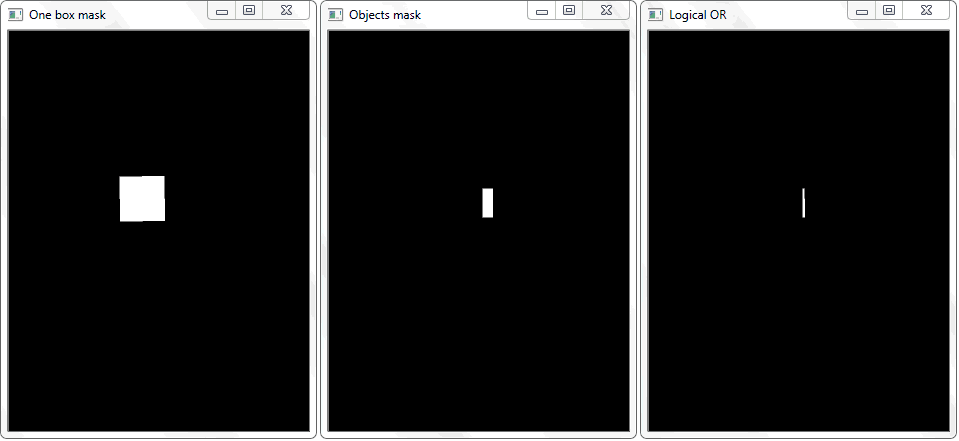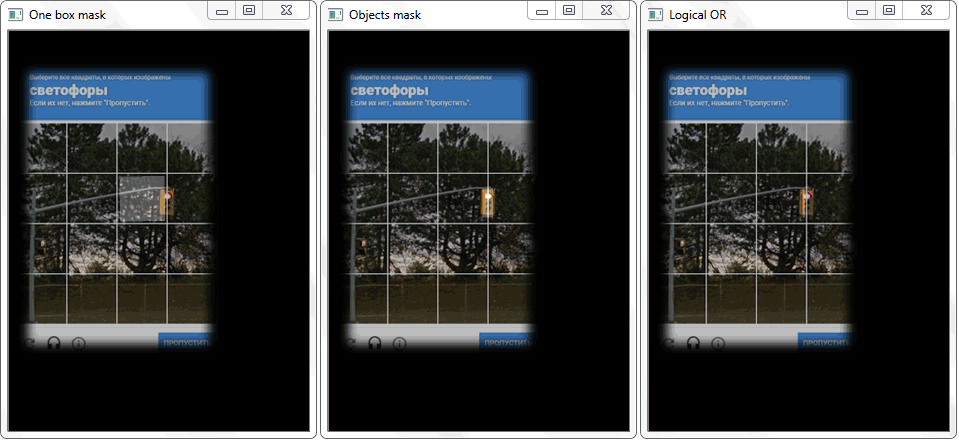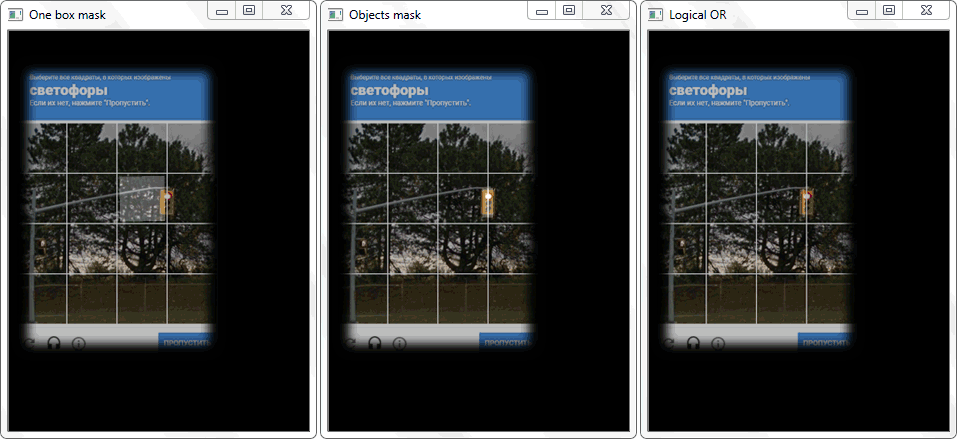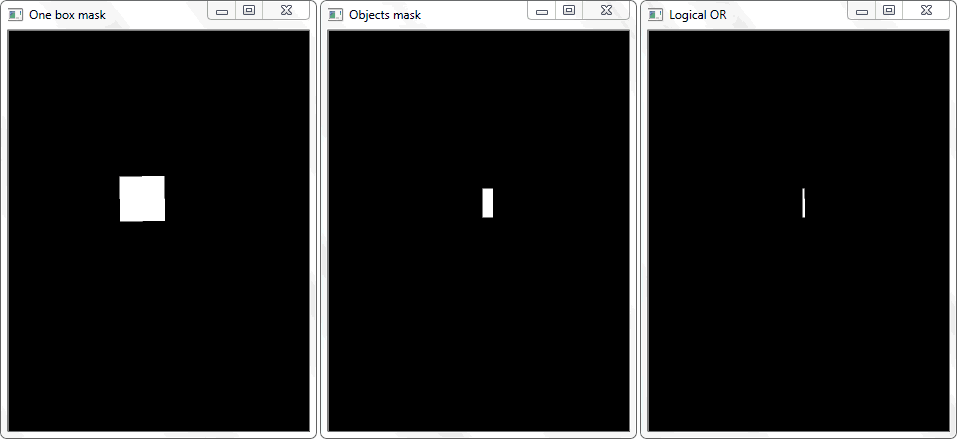 La fonction «any ()» pour l'image «OU logique» dans ce cas retournera vrai et établira ainsi le fait de l'intersection de la cellule avec la zone de trame de l'objet détecté.
La fonction «any ()» pour l'image «OU logique» dans ce cas retournera vrai et établira ainsi le fait de l'intersection de la cellule avec la zone de trame de l'objet détecté.La gestion
Le contrôle du curseur dans «Python» devient disponible grâce au module «win32api» (cependant, il s'est avéré plus tard que le «PyAutoGUI» déjà importé dans le projet sait aussi comment faire). Appuyer et relâcher le bouton gauche de la souris, ainsi que déplacer le curseur sur les coordonnées souhaitées, est effectué par les fonctions correspondantes du module win32api. Mais dans le prototype, ils étaient enveloppés dans des fonctions définies par l'utilisateur afin de fournir une observation visuelle du mouvement du curseur. Cela affecte négativement les performances et a été implémenté uniquement à des fins de démonstration.
Au cours du processus de développement, l'idée est venue de choisir les cellules dans un ordre aléatoire. Il est possible que cela ne soit pas logique (pour des raisons évidentes, Google ne nous donne pas de commentaires et de descriptions des mécanismes de fonctionnement du captcha), mais déplacer le curseur à travers les cellules de manière chaotique semble plus amusant.
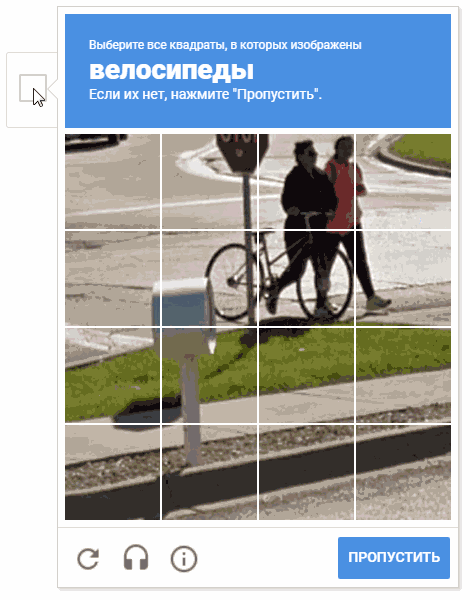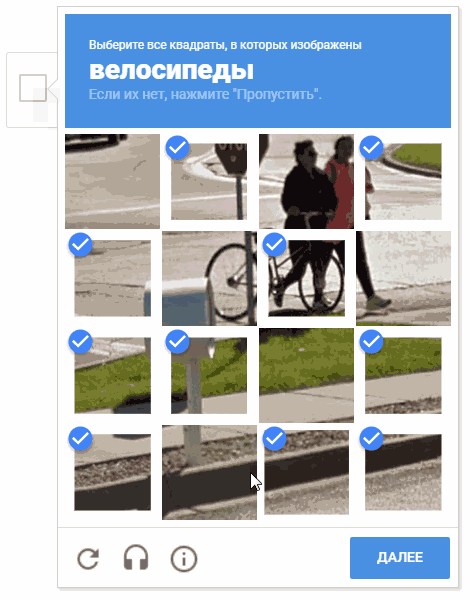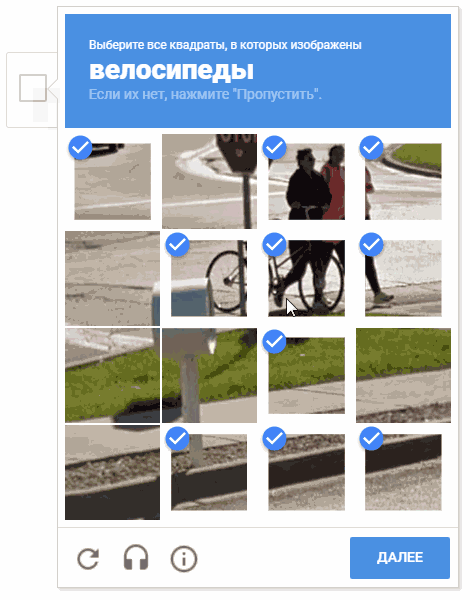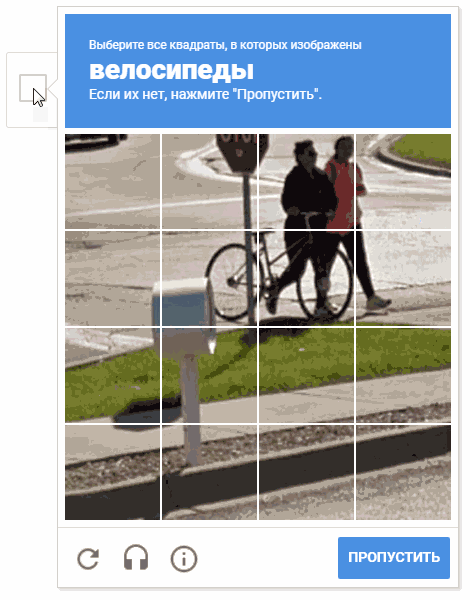 Sur l'animation, le résultat est "random.shuffle (boxesForSelect)".
Sur l'animation, le résultat est "random.shuffle (boxesForSelect)".Reconnaissance de texte
Afin de combiner tous les développements disponibles en un seul ensemble, un lien supplémentaire est nécessaire: une unité de reconnaissance pour la classe requise du captcha. Nous savons déjà reconnaître et distinguer différents objets dans l'image, nous pouvons cliquer sur des cellules captcha arbitraires, mais nous ne savons pas sur quelles cellules cliquer. L'une des façons de résoudre ce problème consiste à reconnaître le texte de l'en-tête captcha. Tout d'abord, j'ai essayé d'implémenter la reconnaissance de texte à l'aide de l'outil de reconnaissance optique de caractères "
Tesseract-OCR ".
Dans les dernières versions, il est possible d'installer des modules linguistiques directement dans la fenêtre du programme d'installation (auparavant cela se faisait manuellement). Après avoir installé et importé Tesseract-OCR dans mon projet, j'ai essayé de reconnaître le texte de l'en-tête captcha.
Le résultat, malheureusement, ne m'a pas du tout impressionné. J'ai décidé que le texte dans l'en-tête était mis en surbrillance en gras et fusionné pour une raison, j'ai donc essayé d'appliquer diverses transformations à l'image: binarisation, rétrécissement, expansion, flou, distorsion et redimensionnement. Malheureusement, cela n'a pas donné un bon résultat: dans le meilleur des cas, seule une partie des lettres de classe a été déterminée, et lorsque le résultat a été satisfaisant, j'ai appliqué les mêmes transformations, mais pour d'autres majuscules (avec un texte différent), et le résultat s'est révélé à nouveau mauvais.
 La reconnaissance des bouchons Tesseract-OCR a généralement conduit à des résultats insatisfaisants.
La reconnaissance des bouchons Tesseract-OCR a généralement conduit à des résultats insatisfaisants.Il est impossible de dire sans équivoque que «Tesseract-OCR» ne reconnaît pas bien le texte, ce n’est pas le cas: l’outil s’adapte bien mieux aux autres images (pas aux majuscules captcha).
J'ai décidé d'utiliser un service tiers qui offrait une API pour travailler avec elle gratuitement (l'enregistrement et la réception d'une clé pour une adresse e-mail sont requis). Le service a une limite de 500 reconnaissances par jour, mais pour toute la période de développement, je n'ai rencontré aucun problème de limitations. Au contraire: j'ai soumis l'image originale de l'en-tête au service (sans appliquer absolument aucune transformation) et le résultat m'a impressionné agréablement.
Les mots du service ont été retournés pratiquement sans erreur (généralement même ceux écrits en petits caractères). De plus, ils sont revenus dans un format très pratique - coupé par ligne avec des caractères de saut de ligne. Dans toutes les images, je ne m'intéressais qu'à la deuxième ligne, donc j'y ai directement accédé. Cela ne pouvait que se réjouir, car un tel format me libérait de la nécessité de préparer une ligne: je n'avais pas à couper le début ou la fin de tout le texte, faire des "trims", des remplacements, travailler avec des expressions régulières et effectuer d'autres opérations sur la ligne, visant à mettre en évidence un mot (et parfois deux!) - un joli bonus!
text = serviceResponse['ParsedResults'][0]['ParsedText']
Le service qui a reconnu le texte n'a presque jamais fait d'erreur avec le nom de la classe, mais j'ai quand même décidé de laisser une partie du nom de la classe pour une éventuelle erreur. C'est facultatif, mais j'ai remarqué que «Tesseract-OCR» dans certains cas reconnaissait incorrectement la fin d'un mot commençant par le milieu. De plus, cette approche élimine l'erreur d'application dans le cas d'un nom de classe long ou d'un nom à deux mots (dans ce cas, le service renverra non pas 3, mais 4 lignes, et je ne trouve pas le nom complet de la classe dans la deuxième ligne).
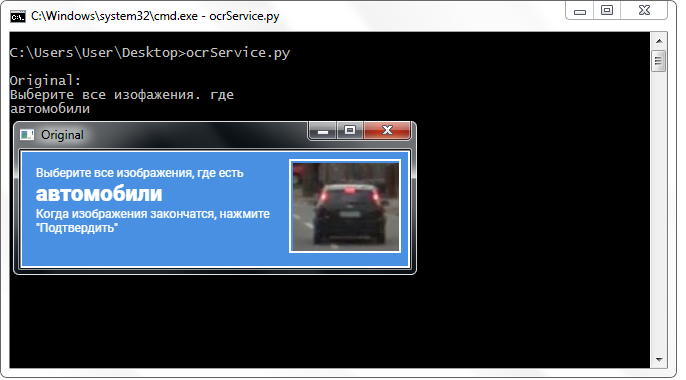 Un service tiers reconnaît bien le nom de la classe sans aucune transformation sur l'image.
Un service tiers reconnaît bien le nom de la classe sans aucune transformation sur l'image.Fusion
Obtenir du texte depuis l'en-tête ne suffit pas. Il doit être comparé aux identificateurs des classes de modèle disponibles, car dans le tableau de classes, le réseau neuronal renvoie exactement l'identifiant de classe, et non son nom, comme cela peut sembler. Lors de la formation du modèle, en règle générale, un fichier est créé dans lequel les noms de classe et leurs identificateurs sont comparés (alias «carte d'étiquettes»). J'ai décidé de le faire plus facilement et de spécifier les identificateurs de classe manuellement, car captcha nécessite toujours des classes en russe (à propos, cela peut être modifié):
if "" in query:
Tout ce qui est décrit ci-dessus est reproduit dans le cycle de programme principal: les cadres de l'objet, la cellule, leurs intersections sont déterminés, le curseur se déplace et clique. Lorsqu'un en-tête est détecté, la reconnaissance de texte est effectuée. Si le réseau neuronal ne peut pas détecter la classe requise, un décalage arbitraire de l'image est effectué jusqu'à 5 fois (c'est-à-dire que l'entrée sur le réseau neuronal est modifiée), et si la détection ne se produit toujours pas, le bouton «Ignorer / Confirmer» est cliqué (sa position est détectée de la même manière détecter les cellules et les bouchons).
Si vous résolvez souvent le captcha, vous pouvez observer l'image lorsque la cellule sélectionnée disparaît, et une nouvelle apparaît lentement et lentement à sa place. Étant donné que le prototype est programmé pour passer instantanément à la page suivante après avoir sélectionné toutes les cellules, j'ai décidé de faire des pauses de 3 secondes pour exclure de cliquer sur le bouton "Suivant" sans détecter d'objets sur la cellule apparaissant lentement.
L'article ne serait pas complet s'il ne contenait pas une description de la chose la plus importante - une coche pour réussir le captcha. J'ai décidé qu'une simple
comparaison de modèles pourrait le faire. Il convient de noter que la correspondance de motifs est loin d'être la meilleure façon de détecter des objets. Par exemple, j'ai dû régler la sensibilité de détection sur «0,01» pour que la fonction arrête de voir les tiques dans tout, mais la voit quand il y a vraiment une tique. De même, j'ai agi avec une case à cocher vide qui rencontre l'utilisateur et à partir de laquelle le captcha démarre (il n'y a eu aucun problème de sensibilité).
Résultat
Le résultat de toutes les actions décrites est une application dont j'ai testé les performances sur le "
Toaster ":
Il convient de reconnaître que la vidéo n'a pas été tournée du premier coup, car j'ai souvent été confronté à la nécessité de choisir des classes qui ne sont pas dans le modèle (par exemple, les passages pour piétons, les escaliers ou les vitrines).
"Google reCAPTCHA" renvoie une certaine valeur au site, montrant comment "Vous êtes un robot", et les administrateurs du site, à leur tour, peuvent définir un seuil pour passer cette valeur. Il est possible qu'un seuil de captcha relativement bas ait été défini sur le grille-pain. Cela explique le passage assez facile du captcha par le programme, malgré le fait qu'il se soit trompé deux fois, ne voyant pas le feu de circulation de la première page et la bouche d'incendie de la quatrième page du captcha.
En plus du grille-pain, des expériences ont été menées sur la
page de démonstration officielle de
reCAPTCHA . En conséquence, il a été remarqué qu'après plusieurs détections erronées (et non-découvertes), la capture d'un captcha devient extrêmement difficile même pour une personne: de nouvelles classes sont nécessaires (comme les tracteurs et les palmiers), des cellules sans objets apparaissent dans les échantillons (couleurs presque monotones) et le nombre de pages augmente considérablement, passer.
Cela a été particulièrement visible lorsque j'ai décidé d'essayer de cliquer sur des cellules aléatoires en cas de non-détection d'objets (en raison de leur absence dans le modèle). Par conséquent, nous pouvons affirmer avec certitude que les clics aléatoires ne permettront pas de résoudre le problème. Pour se débarrasser d'un tel «blocage» par l'examinateur, nous avons reconnecté la connexion Internet et effacé les données du navigateur, car il est devenu impossible de passer un tel test - c'était presque sans fin!
 Si vous doutez de votre humanité, un tel résultat est possible.
Si vous doutez de votre humanité, un tel résultat est possible.Développement
Si l'article et l'application suscitent l'intérêt du lecteur, je continuerai volontiers sa mise en œuvre, ses tests et la suite de la description sous une forme plus détaillée.
Il s'agit de trouver des classes qui ne font pas partie du réseau actuel, cela améliorera considérablement l'efficacité de l'application. À l'heure actuelle, il est urgent de reconnaître au moins des classes telles que: passages pour piétons, vitrines et cheminées - je vais vous dire comment recycler le modèle. Pendant le développement, j'ai fait une courte liste des classes les plus courantes:
- passages pour piétons;
- bornes d'incendie;
- vitrines
- cheminées;
- les voitures;
- Autobus
- feux de circulation;
- vélos
- moyens de transport;
- escaliers
- signes.
Il est possible d'améliorer la qualité de la détection d'objets en utilisant plusieurs modèles en même temps: cela peut dégrader les performances mais augmenter la précision.
Une autre façon d'améliorer la qualité de détection des objets est de changer l'entrée d'image sur le réseau neuronal: dans la vidéo, vous pouvez voir que lorsque des objets ne sont pas détectés, je fais un décalage d'image arbitraire plusieurs fois (à moins de 10 pixels horizontalement et verticalement), et souvent cette opération vous permet de voir des objets qui étaient auparavant n'ont pas été détectés.
Une augmentation de l'image d'un petit carré à un grand (jusqu'à 300 x 300 pixels) conduit également à la détection d'objets non détectés.
 Aucun objet n'a été trouvé sur la gauche: carré d'origine avec 100 pixels de côté. A droite, un bus est détecté: un carré agrandi jusqu'à 300 x 300 pixels.
Aucun objet n'a été trouvé sur la gauche: carré d'origine avec 100 pixels de côté. A droite, un bus est détecté: un carré agrandi jusqu'à 300 x 300 pixels.Une autre transformation intéressante est la suppression de la grille blanche sur l'image à l'aide des outils OpenCV: il est possible que la bouche d'incendie n'ait pas été détectée dans la vidéo pour cette raison (cette classe est présente dans le réseau neuronal).
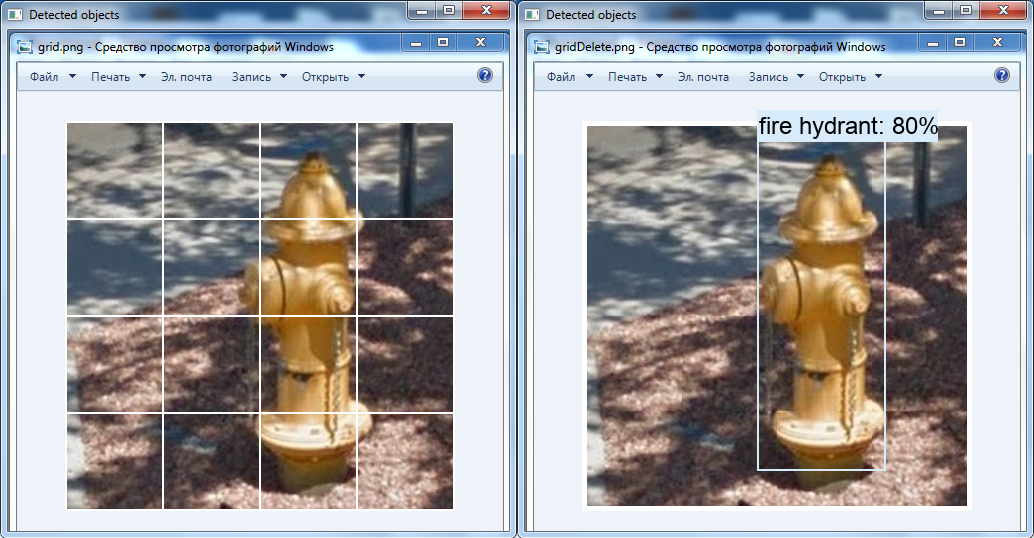 A gauche se trouve l'image d'origine et à droite celle modifiée dans l'éditeur graphique: la grille est supprimée, les cellules sont déplacées les unes vers les autres.
A gauche se trouve l'image d'origine et à droite celle modifiée dans l'éditeur graphique: la grille est supprimée, les cellules sont déplacées les unes vers les autres.Résumé
Avec cet article, je voulais vous dire que le captcha n'est probablement pas la meilleure protection contre les bots, et il est fort possible que dans un proche avenir, il y aura un besoin de nouveaux moyens de protection contre les systèmes automatisés.
Le prototype développé, même dans un état inachevé, démontre qu'avec les classes requises dans le modèle de réseau neuronal et en appliquant des transformations sur les images, il est possible de réaliser l'automatisation d'un processus qui ne devrait pas être automatisé.
Je voudrais également attirer l'attention de Google sur le fait qu'en plus de la méthode de contournement du captcha décrite dans cet article, il existe également
une autre manière de
transcrire un échantillon audio. À mon avis, il est maintenant nécessaire de prendre des mesures liées à l'amélioration de la qualité des logiciels et des algorithmes contre les robots.
D'après le contenu et l'essence du matériel, il peut sembler que je n'aime pas Google et, en particulier, reCAPTCHA, mais c'est loin d'être le cas, et s'il y a une prochaine mise en œuvre, je vous dirai pourquoi.
Développé et démontré afin d'améliorer l'éducation et d'améliorer les méthodes visant à assurer la sécurité de l'information.
Merci de votre attention.