L'histoire de VKontakte est sur Wikipédia, raconte Pavel lui-même. Il semble que tout le monde la connaisse déjà. Pavel a
parlé de l'intérieur, de l'architecture et de la conception du site sur HighLoad ++
en 2010 . Beaucoup de serveurs ont fui depuis lors, nous allons donc mettre à jour les informations: nous disséquons, retirons l'intérieur, pesons - nous considérons le dispositif VK d'un point de vue technique.
 Alexey Akulovich
Alexey Akulovich (
AterCattus ) est un développeur backend de l'équipe VKontakte. La transcription de ce rapport est une réponse collective aux questions fréquemment posées sur le fonctionnement de la plateforme, l'infrastructure, les serveurs et l'interaction entre eux, mais pas sur le développement, notamment
sur le matériel . Séparément - sur les bases de données et ce que VK a à leur place, sur la collecte des journaux et la surveillance de l'ensemble du projet dans son ensemble. Détails sous la coupe.
Depuis plus de quatre ans, je fais toutes sortes de tâches liées au backend.
- Téléchargement, stockage, traitement, distribution de médias: vidéo, streaming en direct, audio, photos, documents.
- Infrastructure, plate-forme, surveillance des développeurs, journaux, caches régionaux, CDN, protocole propriétaire RPC.
- Intégration avec des services externes: push mailing, analyse de liens externes, flux RSS.
- Aidez vos collègues sur diverses questions, pour les réponses auxquelles vous devez plonger dans un code inconnu.
Pendant ce temps, j'ai participé à de nombreuses composantes du site. Je veux partager cette expérience.
Architecture générale
Tout, comme d'habitude, commence par un serveur ou un groupe de serveurs qui acceptent les requêtes.
Serveur frontal
Le serveur frontal accepte les demandes via HTTPS, RTMP et WSS.
Les HTTPS sont des demandes pour les versions Web principale et mobile du site: vk.com et m.vk.com, et d'autres clients officiels et non officiels de notre API: clients mobiles, messageries instantanées. Nous avons du trafic
RTMP pour les diffusions en direct avec des serveurs frontaux séparés et des connexions
WSS pour l'API Streaming.
Pour HTTPS et WSS,
nginx est installé sur les serveurs. Pour les émissions RTMP, nous avons récemment opté pour notre propre solution
Kive , mais cela dépasse le cadre du rapport. Pour la tolérance aux pannes, ces serveurs annoncent des adresses IP communes et agissent comme des groupes afin qu'en cas de problème sur l'un des serveurs, les requêtes des utilisateurs ne soient pas perdues. Pour HTTPS et WSS, ces mêmes serveurs chiffrent le trafic pour prendre une partie de la charge CPU sur eux-mêmes.
De plus, nous ne parlerons pas de WSS et RTMP, mais seulement des requêtes HTTPS standard, qui sont généralement associées à un projet Web.
Backend
Derrière le front se trouvent généralement les serveurs principaux. Ils gèrent les demandes que le serveur frontal reçoit des clients.
Ce sont des
serveurs kPHP exécutant le démon HTTP car HTTPS est déjà décrypté. kPHP est un serveur qui fonctionne selon le
modèle prefork : il démarre le processus maître, un tas de processus enfants, leur transmet des sockets d'écoute et ils traitent leurs requêtes. Dans le même temps, les processus ne sont pas redémarrés entre chaque demande de l'utilisateur, mais réinitialisent simplement leur état à l'état initial à valeur zéro - demande par demande, au lieu de redémarrer.
Partage de charge
Tous nos backends ne sont pas un énorme pool de machines capables de traiter n'importe quelle demande. Nous les
divisons en groupes distincts : général, mobile, api, vidéo, mise en scène ... Le problème sur un groupe de machines distinct n'affectera pas tout le monde. En cas de problèmes avec la vidéo, l'utilisateur qui écoute de la musique ne connaît même pas les problèmes. Le backend auquel envoyer la requête est résolu par nginx sur le devant de la configuration.
Collecte et rééquilibrage des métriques
Pour comprendre le nombre de voitures dont vous avez besoin dans chaque groupe, nous
ne comptons pas sur QPS . Les backends sont différents, ils ont des demandes différentes, chaque demande a une complexité de calcul QPS différente. Par conséquent, nous utilisons le
concept de charge sur le serveur dans son ensemble - sur le CPU et la perf .
Nous avons des milliers de tels serveurs. Le groupe kPHP s'exécute sur chaque serveur physique pour utiliser tous les noyaux (car kPHP est monothread).
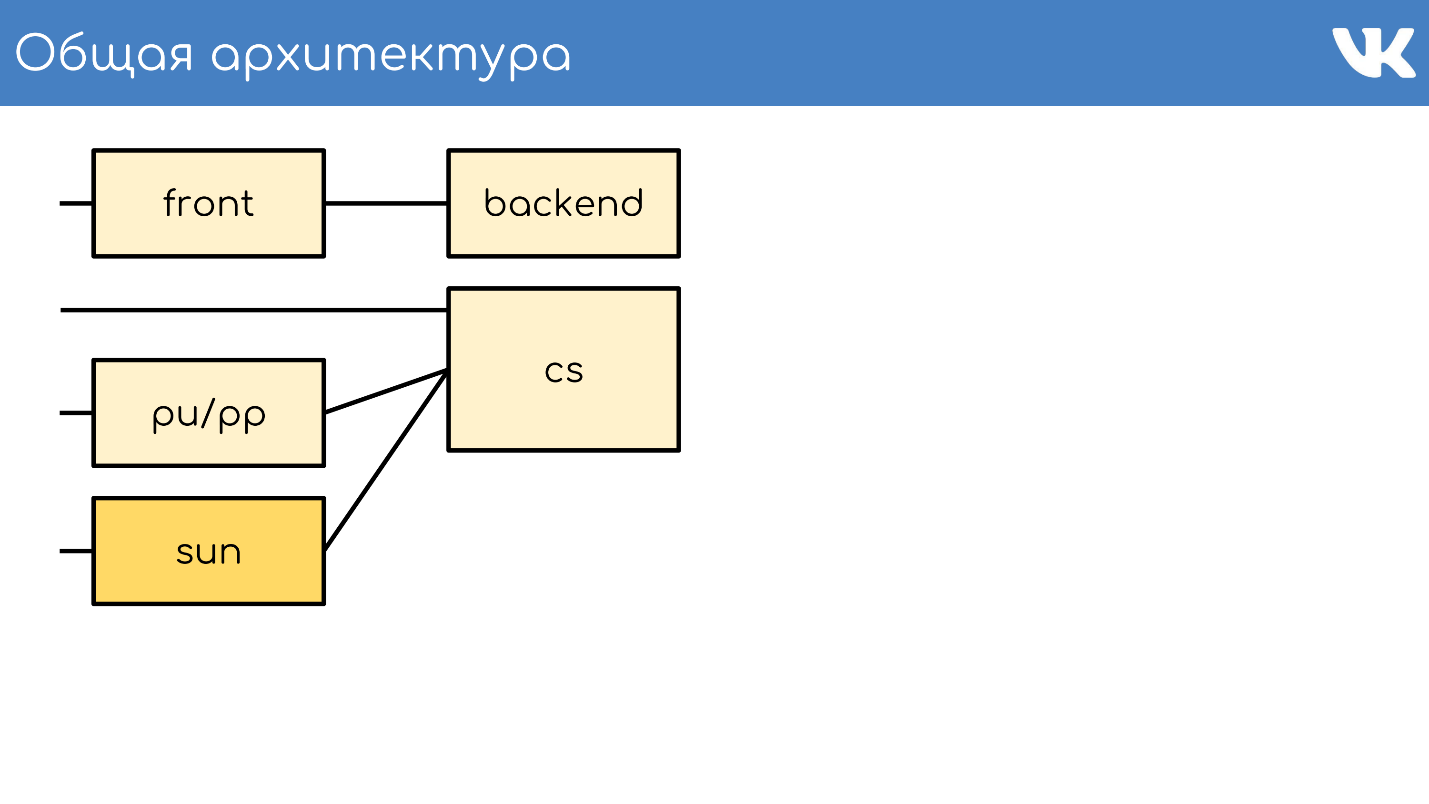
Serveur de contenu
CS ou Content Server est un stockage . CS est un serveur qui stocke les fichiers, et traite également les fichiers téléchargés, toutes sortes de tâches d'arrière-plan synchrones que le frontend Web principal lui pose.
Nous avons des dizaines de milliers de serveurs physiques qui stockent des fichiers. Les utilisateurs aiment télécharger des fichiers, et nous aimons les stocker et les partager. Certains de ces serveurs sont fermés par des serveurs spéciaux pu / pp.
pu / pp
Si vous avez ouvert l'onglet réseau dans VK, vous avez vu pu / pp.

Qu'est-ce que pu / pp? Si nous fermons un serveur après l'autre, il y a deux options pour télécharger et télécharger un fichier sur un serveur qui a été fermé:
directement via
http://cs100500.userapi.com/path ou
via un serveur intermédiaire -
http://pu.vk.com/c100500/path .
Pu est le nom historique du téléchargement de photos et pp est un proxy de photos . Autrement dit, un serveur pour télécharger des photos, et un autre - pour donner. Désormais, non seulement les photos sont chargées, mais le nom a été conservé.
Ces serveurs
mettent fin aux
sessions HTTPS pour supprimer la charge du processeur du stockage. De plus, comme les fichiers utilisateur sont traités sur ces serveurs, moins les informations sensibles sont stockées sur ces machines, mieux c'est. Par exemple, les clés de chiffrement HTTPS.
Étant donné que les machines sont fermées par nos autres machines, nous pouvons nous permettre de ne pas leur donner des adresses IP externes «blanches» et de
donner des adresses IP
«grises» . Nous avons donc économisé sur le pool IP et garanti de protéger les machines contre l'accès de l'extérieur - il n'y a tout simplement pas d'adresse IP pour y accéder.
Tolérance aux pannes via IP partagée . En termes de tolérance aux pannes, le schéma fonctionne de la même manière - plusieurs serveurs physiques ont une adresse IP physique commune, et le morceau de fer devant eux choisit où envoyer la demande. Plus tard, je parlerai d'autres options.
Le point controversé est que dans ce cas, le
client détient moins de connexions . S'il y a la même IP sur plusieurs machines - avec le même hôte: pu.vk.com ou pp.vk.com, le navigateur client a une limite sur le nombre de demandes simultanées à un hôte. Mais pendant l'omniprésent HTTP / 2, je pense que ce n'est plus le cas.
L'inconvénient évident du schéma est que vous devez
pomper tout le trafic qui va vers le stockage via un autre serveur. Étant donné que nous pompons le trafic dans les voitures, nous ne pouvons pas encore pomper le trafic lourd de la même manière, par exemple, la vidéo. Nous le transférons directement - une connexion directe distincte pour les référentiels individuels spécifiquement pour la vidéo. Nous transmettons un contenu plus léger via un proxy.
Il n'y a pas si longtemps, nous avons une version améliorée du proxy. Je vais maintenant vous expliquer en quoi ils diffèrent des modèles ordinaires et pourquoi cela est nécessaire.
Soleil
En septembre 2017, Oracle, qui avait précédemment acheté Sun, a
licencié un grand nombre d'employés de Sun. On peut dire qu'à ce moment la société a cessé d'exister. En choisissant un nom pour le nouveau système, nos administrateurs ont décidé de rendre hommage et de respect à cette société et ont nommé le nouveau système Sun. Entre nous, nous l'appelons simplement «soleil».
Pp a eu quelques problèmes.
Une adresse IP par groupe est un cache inefficace . Plusieurs serveurs physiques ont une adresse IP commune, et il n'y a aucun moyen de contrôler le serveur auquel la demande sera adressée. Par conséquent, si différents utilisateurs viennent pour le même fichier, alors s'il existe un cache sur ces serveurs, le fichier s'installe dans le cache de chaque serveur. Il s'agit d'un schéma très inefficace, mais rien ne pourrait être fait.
Par conséquent,
nous ne pouvons pas partager le contenu , car nous ne pouvons pas sélectionner un serveur spécifique pour ce groupe - ils ont une IP commune. De plus, pour certaines raisons internes, nous
n'avons pas eu la possibilité de mettre de tels serveurs dans les régions . Ils ne se tenaient qu'à Saint-Pétersbourg.
Avec les soleils, nous avons changé le système de sélection. Nous avons maintenant le
routage anycast :
routage dynamique, anycast, démon d'auto-vérification. Chaque serveur a sa propre IP individuelle, mais en même temps un sous-réseau commun. Tout est configuré de manière à ce qu'en cas de perte d'un serveur, le trafic soit automatiquement réparti sur les autres serveurs du même groupe. Il est maintenant possible de sélectionner un serveur spécifique,
il n'y a pas de mise en cache excessive et la fiabilité n'est pas affectée.
Support de poids . Maintenant, nous pouvons nous permettre de mettre des voitures de capacités différentes selon les besoins, et également en cas de problèmes temporaires, de changer les poids des «soleils» de travail pour réduire la charge sur eux afin qu'ils se «reposent» et fonctionnent à nouveau.
Partage par identifiant de contenu . Ce qui est amusant avec le sharding, c'est que nous partitionnons généralement le contenu afin que différents utilisateurs suivent le même fichier à travers le même «soleil» afin qu'ils aient un cache commun.
Nous avons récemment lancé l'application Clover. Il s'agit d'un quiz de diffusion en direct en ligne où le présentateur pose des questions et les utilisateurs répondent en temps réel en choisissant des options. L'application dispose d'un chat où les utilisateurs peuvent inonder.
Plus de 100 000 personnes peuvent se connecter simultanément à la diffusion. Ils écrivent tous des messages qui sont envoyés à tous les participants, avec le message vient un autre avatar. Si 100 000 personnes viennent pour un avatar dans un «soleil», il peut parfois rouler sur un nuage.
Pour résister à des rafales de demandes provenant du même fichier, c'est pour une sorte de contenu que nous incluons un schéma stupide qui répartit les fichiers sur tous les "soleils" disponibles dans la région.
Soleil à l'intérieur
Proxy inverse vers nginx, cache en RAM ou disques rapides Optane / NVMe. Exemple:
http://sun4-2.userapi.com/c100500/path - lien vers le "soleil", qui se trouve dans la quatrième région, le deuxième groupe de serveurs. Il ferme le fichier de chemin, qui se trouve physiquement sur le serveur 100500.
Cache
Nous ajoutons un nœud supplémentaire à notre schéma architectural - l'environnement de mise en cache.

Vous trouverez ci-dessous la disposition des
caches régionaux , il y en a environ 20. Ce sont les endroits où se trouvent exactement les caches et les "soleils", qui peuvent mettre en cache le trafic à travers eux-mêmes.

Il s'agit de la mise en cache du contenu multimédia, les données utilisateur ne sont pas stockées ici - juste de la musique, des vidéos, des photos.
Pour déterminer la région de l'utilisateur, nous
collectons les préfixes de réseau BGP annoncés dans les régions . Dans le cas de repli, nous avons toujours l'analyse de la base geoip, si nous ne pouvions pas trouver IP par préfixes.
Par IP utilisateur, nous déterminons la région . Dans le code, nous pouvons regarder une ou plusieurs régions de l'utilisateur - les points dont il est géographiquement le plus proche.
Comment ça marche?
Nous considérons la popularité des fichiers par région . Il y a un numéro de cache régional où se trouve l'utilisateur et un identifiant de fichier - nous prenons cette paire et incrémentons la note pour chaque téléchargement.
Dans le même temps, les démons - services dans les régions - viennent de temps en temps à l'API et disent: "J'ai tel ou tel cache, donnez-moi une liste des fichiers les plus populaires de ma région que je n'ai pas encore." L'API donne un tas de fichiers triés par note, le démon les pompe, les transporte dans les régions et leur donne des fichiers à partir de là. C'est une différence fondamentale entre pu / pp et Sun des caches: ils transmettent le fichier par eux-mêmes immédiatement, même si le fichier n'existe pas dans le cache, et le cache pompe d'abord le fichier pour lui-même, puis il commence à le révéler.
Dans le même temps, nous
rapprochons le contenu des utilisateurs et réduisons la charge du réseau. Par exemple, uniquement à partir du cache de Moscou, nous distribuons plus de 1 Tbit / s pendant les heures de pointe.
Mais il y a des problèmes -
les serveurs de cache ne sont pas en caoutchouc . Pour le contenu super populaire, il n'y a parfois pas assez de réseau sur un serveur séparé. Nous avons des serveurs de cache de 40 à 50 Gbit / s, mais il y a du contenu qui obstrue complètement un tel canal. Nous nous efforçons de réaliser le stockage de plus d'une copie de fichiers populaires dans la région. J'espère que nous le réaliserons d'ici la fin de l'année.
Nous avons examiné l'architecture générale.
- Serveurs frontaux qui acceptent les demandes.
- Backends qui traitent les demandes.
- Des coffres fermés par deux types de procurations.
- Caches régionaux.
Qu'est-ce qui manque à ce schéma? Bien sûr, les bases de données dans lesquelles nous stockons les données.
Bases de données ou moteurs
Nous ne les appelons pas des bases de données, mais des moteurs moteurs, car dans le sens généralement admis, nous n'avons pratiquement pas de bases de données.
 C'est une mesure nécessaire
C'est une mesure nécessaire . Cela est arrivé parce qu'en 2008-2009, lorsque VK a connu une croissance explosive de la popularité, le projet a pleinement fonctionné sur MySQL et Memcache, et il y avait des problèmes. MySQL aimait tomber et ruiner des fichiers, après quoi il ne montait pas, et Memcache dégradait progressivement ses performances et devait être redémarré.
Il s'avère que dans le projet qui gagnait en popularité, il y avait un stockage persistant qui corrompait les données et un cache qui ralentissait. Dans ces conditions, il est difficile de développer un projet en pleine croissance. Il a été décidé d'essayer de réécrire les éléments essentiels sur lesquels le projet reposait sur leurs propres vélos.
La solution a réussi . La possibilité de le faire était, tout comme un besoin urgent, car il n'existait pas à l'époque d'autres méthodes de mise à l'échelle. Il n'y avait pas de tas de bases, NoSQL n'existait pas encore, il n'y avait que MySQL, Memcache, PostrgreSQL - et c'est tout.
Fonctionnement universel . Le développement a été mené par notre équipe de développeurs C, et tout a été fait de la même manière. Quel que soit le moteur, partout il y avait à peu près le même format des fichiers écrits sur le disque, les mêmes paramètres de démarrage, les signaux étaient traités de la même manière et se comportaient de la même manière en cas de situations de bord et de problèmes. Avec la croissance des moteurs, il est pratique pour les administrateurs de faire fonctionner le système - il n'y a pas de zoo à entretenir et d'apprendre à exploiter chaque nouvelle base tierce, ce qui a permis d'augmenter rapidement et facilement leur nombre.
Types de moteurs
L'équipe a écrit pas mal de moteurs. Voici quelques-uns d'entre eux: ami, conseils, image, ipdb, lettres, listes, journaux, memcached, meowdb, actualités, nostradamus, photo, listes de lecture, pmemcached, sandbox, recherche, stockage, likes, tâches, ...
Pour chaque tâche nécessitant une structure de données spécifique ou traitant des requêtes atypiques, l'équipe C écrit un nouveau moteur. Pourquoi pas.
Nous avons un moteur
memcached séparé, qui est similaire à celui habituel, mais avec un tas de petits pains, et qui ne ralentit pas. Pas ClickHouse, mais fonctionne aussi. Il y a
pmemcached séparément - c'est un
memcached persistant qui peut stocker des données également sur le disque, et plus que ce qu'il entre dans la RAM afin de ne pas perdre de données lors du redémarrage. Il existe différents moteurs pour des tâches individuelles: files d'attente, listes, ensembles - tout ce qui est requis par notre projet.
Clusters
Du point de vue du code, il n'est pas nécessaire d'imaginer des moteurs ou des bases de données comme certains processus, entités ou instances. Le code fonctionne spécifiquement avec les clusters, avec des groupes de moteurs -
un type par cluster . Disons qu'il y a un cluster memcached - c'est juste un groupe de machines.
Le code n'a pas besoin de connaître l'emplacement physique, la taille et le nombre de serveurs. Il va au cluster par un identifiant.
Pour que cela fonctionne, vous devez ajouter une autre entité, située entre le code et les moteurs -
proxy .
Proxy RPC
Proxy - un
bus de connexion , qui exécute presque tout le site. Dans le même temps, nous
n'avons pas de découverte de service - au lieu de cela, il y a une configuration de ce proxy, qui connaît l'emplacement de tous les clusters et de tous les fragments de ce cluster. Cela est fait par les administrateurs.
Les programmeurs ne se soucient généralement pas de combien, où et ce que cela coûte - ils vont simplement au cluster. Cela nous permet beaucoup. Dès réception de la demande, le proxy redirige la demande, sachant où - il le détermine.

Dans le même temps, le proxy est un point de protection contre les pannes de service. Si un moteur ralentit ou tombe en panne, le proxy le comprend et répond en conséquence du côté client. Cela vous permet de supprimer le délai d'expiration - le code n'attend pas que le moteur réponde, mais comprend qu'il ne fonctionne pas et que vous devez vous comporter différemment. Le code doit être préparé pour le fait que les bases de données ne fonctionnent pas toujours.
Implémentations spécifiques
Parfois, nous voulons toujours vraiment avoir une sorte de solution personnalisée comme moteur. En même temps, il a été décidé de ne pas utiliser notre proxy rpc prêt à l'emploi, créé spécifiquement pour nos moteurs, mais de créer un proxy séparé pour la tâche.
Pour MySQL, que nous avons encore à certains endroits, nous utilisons db-proxy et pour ClickHouse -
Kittenhouse .
Cela fonctionne globalement comme ça. Il y a un serveur, kPHP, Go, Python fonctionnent dessus - en général, tout code pouvant suivre notre protocole RPC. Le code va localement à RPC-proxy - sur chaque serveur où il y a du code, son propre proxy local est lancé. Sur demande, le mandataire sait où aller.
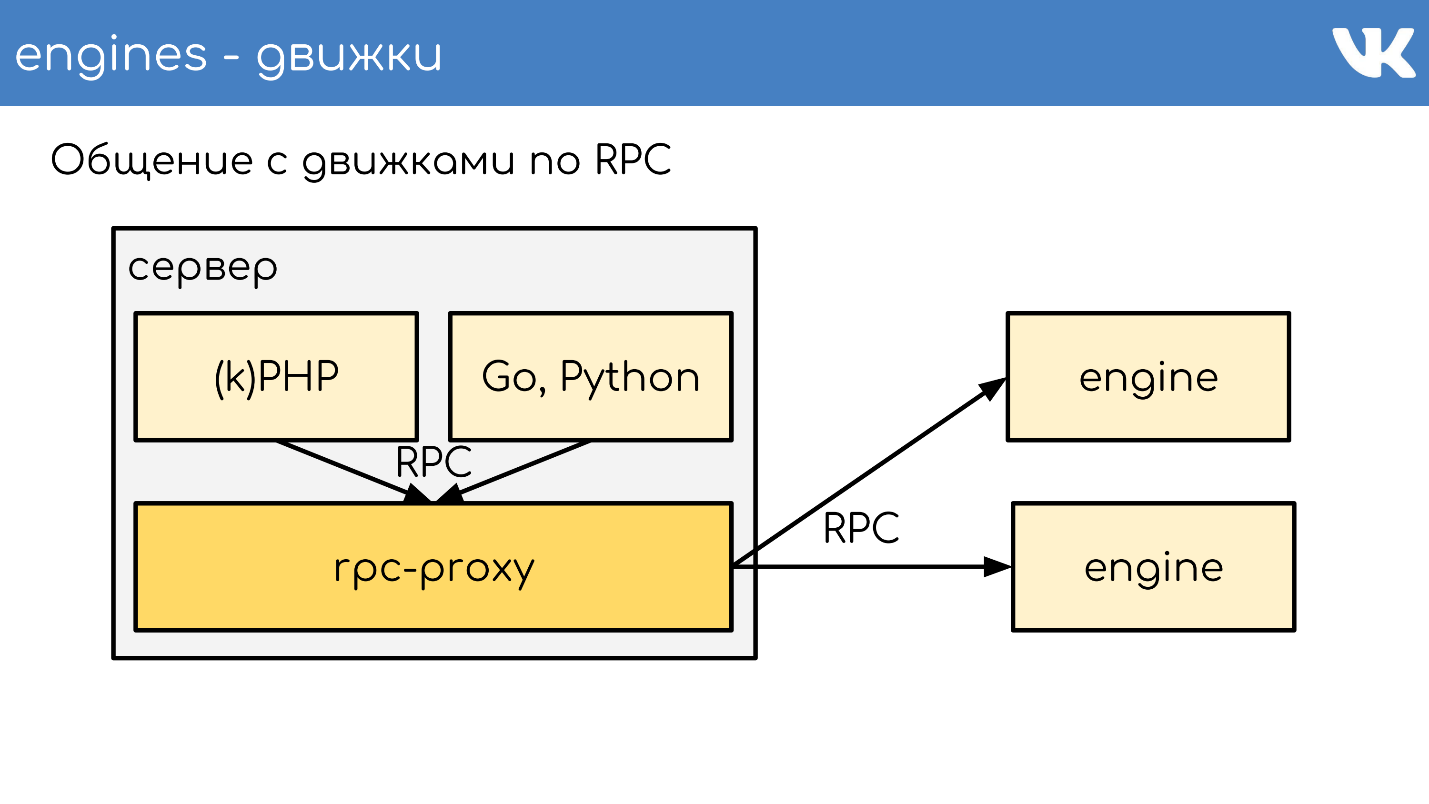
Si un moteur veut passer à un autre, même s'il s'agit d'un voisin, il passe par un proxy, car le voisin peut se trouver dans un centre de données différent. Le moteur ne doit pas être lié à la connaissance de l'emplacement d'autre chose que lui-même - nous avons cette solution standard. Mais bien sûr, il y a des exceptions :)
Un exemple de schéma TL selon lequel tous les moteurs fonctionnent.
memcache.not_found = memcache.Value; memcache.strvalue value:string flags:int = memcache.Value; memcache.addOrIncr key:string flags:int delay:int value:long = memcache.Value; tasks.task fields_mask:# flags:int tag:%(Vector int) data:string id:fields_mask.0?long retries:fields_mask.1?int scheduled_time:fields_mask.2?int deadline:fields_mask.3?int = tasks.Task; tasks.addTask type_name:string queue_id:%(Vector int) task:%tasks.Task = Long;
Il s'agit d'un protocole binaire, dont l'analogue le plus proche est
protobuf. Le schéma décrit à l'avance les champs facultatifs, les types complexes - les extensions de scalaires intégrés et les requêtes. Tout fonctionne selon ce protocole.
RPC sur TL sur TCP / UDP ... UDP?
Nous avons un protocole RPC pour interroger le moteur, qui s'exécute au-dessus du schéma TL. Tout cela fonctionne en plus de la connexion TCP / UDP. TCP - il est clair pourquoi nous sommes souvent interrogés sur UDP.
UDP permet d'
éviter le problème d'un grand nombre de connexions entre les serveurs . S'il y a un proxy RPC sur chaque serveur et en général, il peut aller à n'importe quel moteur, vous obtenez des dizaines de milliers de connexions TCP au serveur. Il y a une charge, mais elle est inutile. Dans le cas d'UDP, ce n'est pas un problème.
Aucune poignée de main TCP redondante . Il s'agit d'un problème typique: lorsqu'un nouveau moteur ou un nouveau serveur arrive, de nombreuses connexions TCP sont établies en même temps. Pour les petites demandes légères, par exemple, la charge utile UDP, toutes les communications entre le code et le moteur sont
deux paquets UDP: l' un vole dans un sens, l'autre vole dans l'autre. Un aller-retour - et le code a reçu une réponse du moteur sans poignée de main.
Oui, tout cela ne fonctionne
qu'avec un très faible pourcentage de perte de paquets . Le protocole prend en charge les retransmissions, les délais d'attente, mais si nous perdons beaucoup, nous obtenons pratiquement TCP, ce qui n'est pas rentable. À travers les océans, ne conduisez pas UDP.
Nous avons des milliers de ces serveurs, et le même schéma existe: un pack de moteurs est placé sur chaque serveur physique. Fondamentalement, ils sont à filetage unique pour fonctionner aussi rapidement que possible sans blocage, et sont déchiquetés en tant que solutions à filetage unique. Dans le même temps, nous n'avons rien de plus fiable que ces moteurs, et une grande attention est accordée au stockage persistant des données.
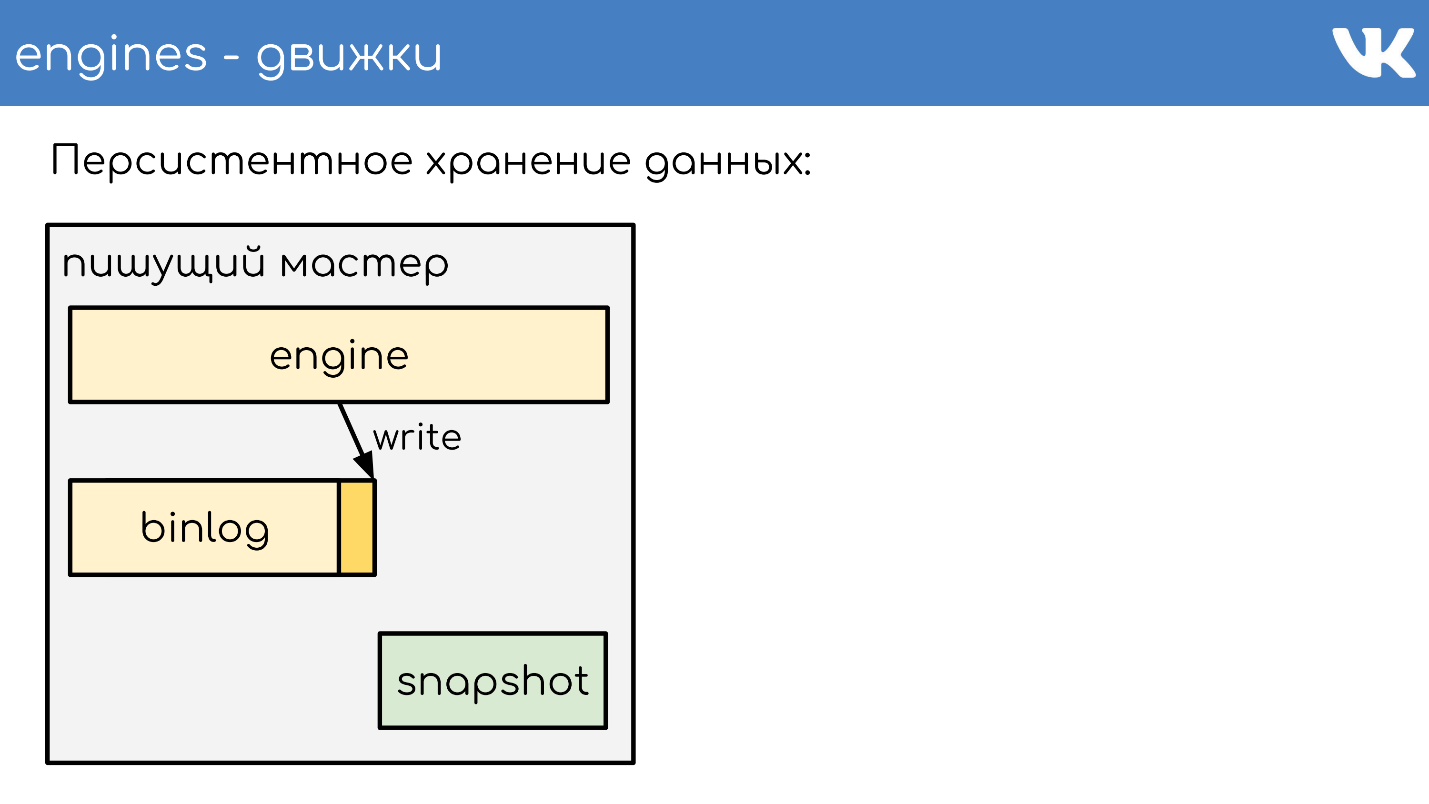
Stockage de données persistant
Les moteurs écrivent des binlogs . Un binlog est un fichier à la fin duquel un événement est ajouté pour changer un état ou des données. Dans différentes solutions, il est appelé différemment: log binaire,
WAL ,
AOF , mais le principe est un.
Afin que le moteur ne relise pas l'intégralité du binlog lors d'un redémarrage pendant plusieurs années, les moteurs écrivent des
instantanés - l'état actuel . Si nécessaire, ils lisent d'abord celui-ci, puis lisent à partir du binlog. Tous les binlogs sont écrits dans le même format binaire - selon le schéma TL, afin que les administrateurs puissent les administrer également avec leurs outils. Il n'y a pas un tel besoin de clichés. Il y a un titre général qui indique dont l'instantané est l'int, la magie du moteur, et quel corps n'est important pour personne. C'est le problème du moteur qui a enregistré l'instantané.
Je décrirai brièvement le principe du travail. Il existe un serveur sur lequel le moteur fonctionne. Il ouvre un nouveau binlog vide pour l'enregistrement, y écrit un événement de modification.

À un moment donné, il décide soit de prendre un instantané, soit il reçoit un signal. Le serveur crée un nouveau fichier, y écrit complètement son état, ajoute la taille actuelle du binlog - décalé à la fin du fichier et continue d'écrire davantage. Un nouveau binlog n'est pas créé.
À un certain moment, lorsque le moteur redémarre, il y aura un binlog et un instantané sur le disque. Le moteur lit en instantané complet, élève son état à un certain point.

Soustrait la position qui était au moment de la création de l'instantané et la taille du binlog.
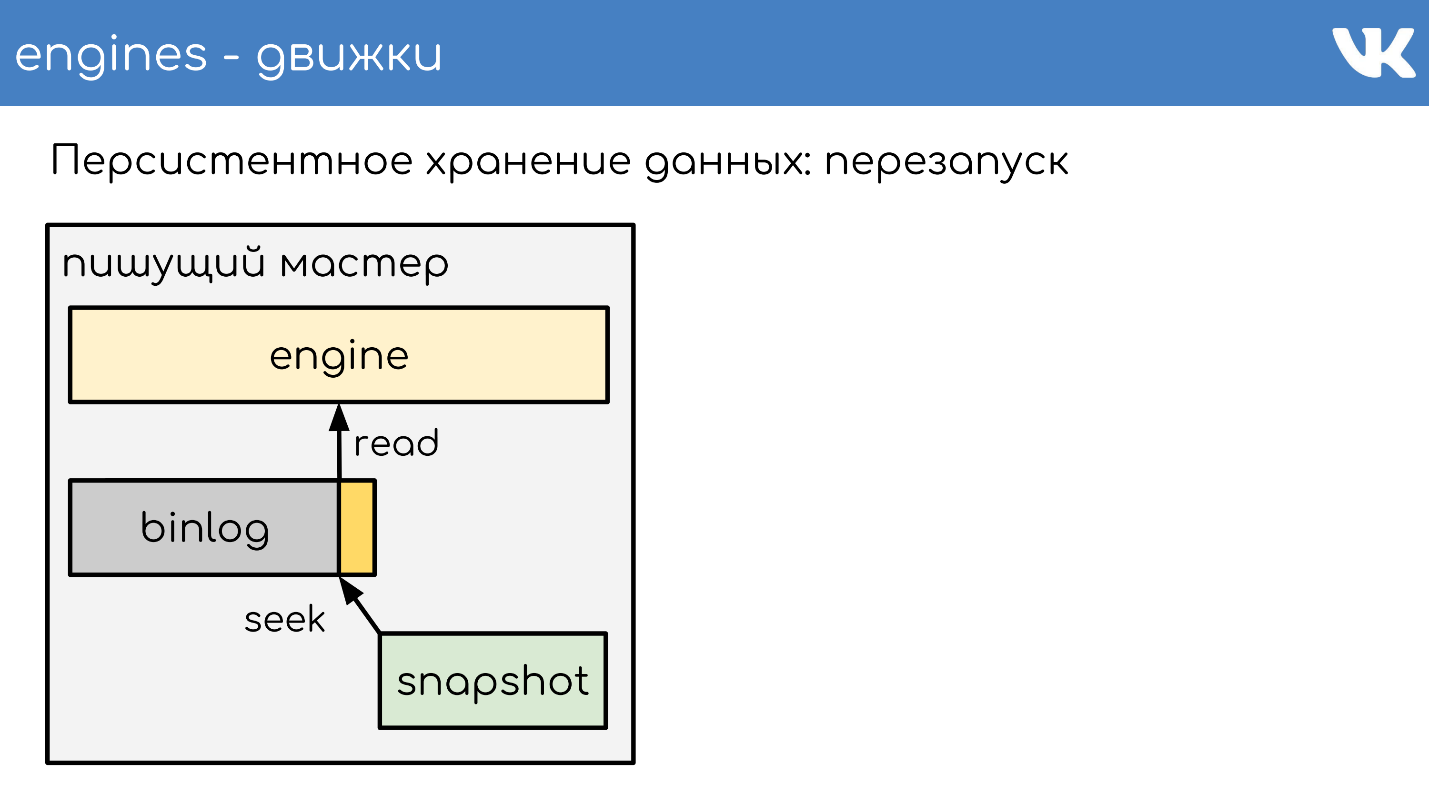
Lit la fin du binlog pour obtenir l'état actuel et continue d'écrire d'autres événements. C'est un schéma simple, tous nos moteurs y travaillent.
Réplication de données
Par conséquent, la réplication des données est
basée sur des instructions - nous n'écrivons aucune modification de page dans le binlog, mais plutôt des
demandes de modifications . Très similaire à ce qui vient sur le réseau, seulement un peu changé.
Le même schéma est utilisé non seulement pour la réplication, mais également
pour la création de sauvegardes . Nous avons un moteur - un maître d'écriture qui écrit dans un binlog. Dans tout autre endroit où les administrateurs s'installent, la copie de ce binlog augmente, et c'est tout - nous avons une sauvegarde.

Si vous avez besoin d'une
réplique de lecture afin de réduire la charge de lecture sur le CPU, le moteur de lecture monte simplement, qui lit la fin du binlog et exécute ces commandes localement.
Le décalage ici est très faible et il est possible de découvrir à quel point la réplique se trouve derrière le maître.
Partage de données dans le proxy RPC
Comment fonctionne le sharding? Comment le proxy comprend-il le fragment de cluster auquel envoyer? Le code ne dit pas: "Envoyer à 15 fragments!" - non, il fait un proxy.
Le schéma le plus simple est firstint , le premier numéro de la demande.
get(photo100_500) => 100 % N.Ceci est un exemple pour un protocole de texte memcached simple, mais, bien sûr, les demandes sont complexes, structurées. L'exemple prend le premier nombre de la requête et le reste de la division par la taille du cluster.
Ceci est utile lorsque nous voulons avoir la localité des données d'une entité. Disons que 100 est un ID d'utilisateur ou de groupe, et nous voulons que toutes les données d'une entité soient sur le même fragment pour les requêtes complexes.
Si nous ne nous soucions pas de la façon dont les demandes sont réparties dans le cluster, il existe une autre option:
hacher l'intégralité du fragment .
hash(photo100_500) => 3539886280 % NNous obtenons également le hachage, le reste de la division et le numéro du fragment.
Ces deux options ne fonctionnent que si nous sommes préparés au fait que lorsque nous augmentons la taille du cluster, nous le divisons ou l'augmentons plusieurs fois. Par exemple, nous avions 16 fragments, nous manquons, nous en voulons plus - vous pouvez en obtenir 32 en toute sécurité sans interruption. Si nous voulons construire plusieurs fois, il y aura un temps d'arrêt, car il ne sera pas possible de tout écraser soigneusement sans perte. Ces options sont utiles, mais pas toujours.
Si nous devons ajouter ou supprimer un nombre arbitraire de serveurs,
un hachage cohérent sur l'anneau à la Ketama est utilisé . Mais en même temps, nous perdons complètement la localité des données, nous devons faire une demande de fusion au cluster afin que chaque pièce renvoie sa petite réponse, et déjà combiner les réponses au proxy.
- . : RPC-proxy , , . , , , . proxy.

. —
memcache .
ring-buffer: prefix.idx = line— , , — . 0 1. memcache — . .
,
Multi Get , , . , - , , , .
logs-engine . , . 600 .
, , 6–7 . , , , ClickHouse .
ClickHouse
, .

, RPC RPC-proxy, , . ClickHouse, :
- - ClickHouse;
- RPC-proxy, ClickHouse, - , , RPC.
— ClickHouse.
ClickHouse,
KittenHouse . KittenHouse ClickHouse — . , HTTP- . , ClickHouse
reverse proxy , , . .

RPC- , , nginx. KittenHouse UDP.

, UDP- . RPC , UDP. .
Suivi
: , , . :
.
Netdata ,
Graphite Carbon . ClickHouse, Whisper, . ClickHouse,
Grafana , . , Netdata Grafana .
. , , Counts, UniqueCounts , - .
statlogsCountEvent ( 'stat_name', $key1, $key2, …) statlogsUniqueCount ( 'stat_name', $uid, $key1, $key2, …) statlogsValuetEvent ( 'stat_name', $value, $key1, $key2, …) $stats = statlogsStatData($params)
, , — , Wathdogs.
, 600 1 .
, . — , . , .
,
memcache , .
stats-daemon .
logs-collectors , , .

logs-collectors.
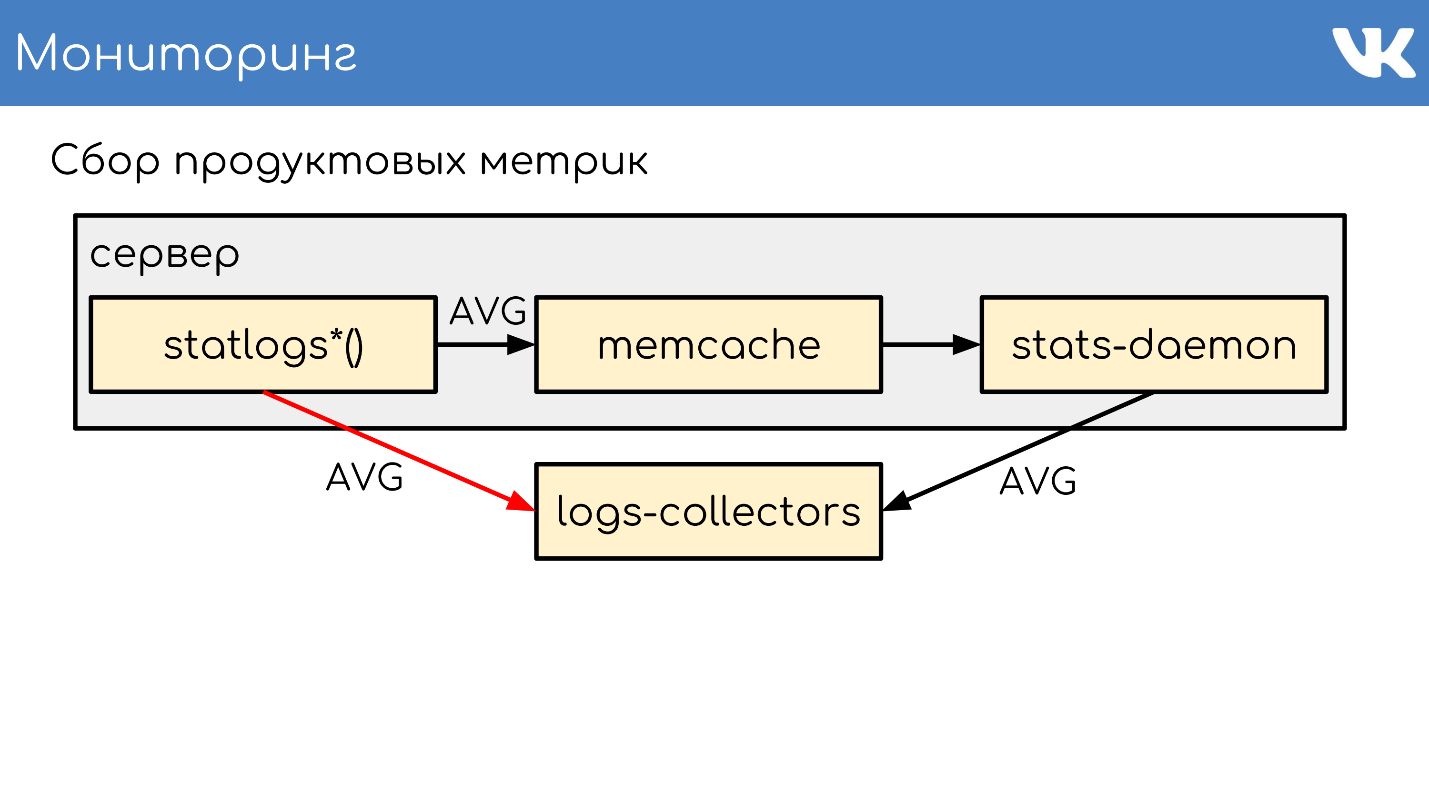
stas-daemom — , collector. , - memcache stats-daemon, , .
logs-collectors
meowDB — , .
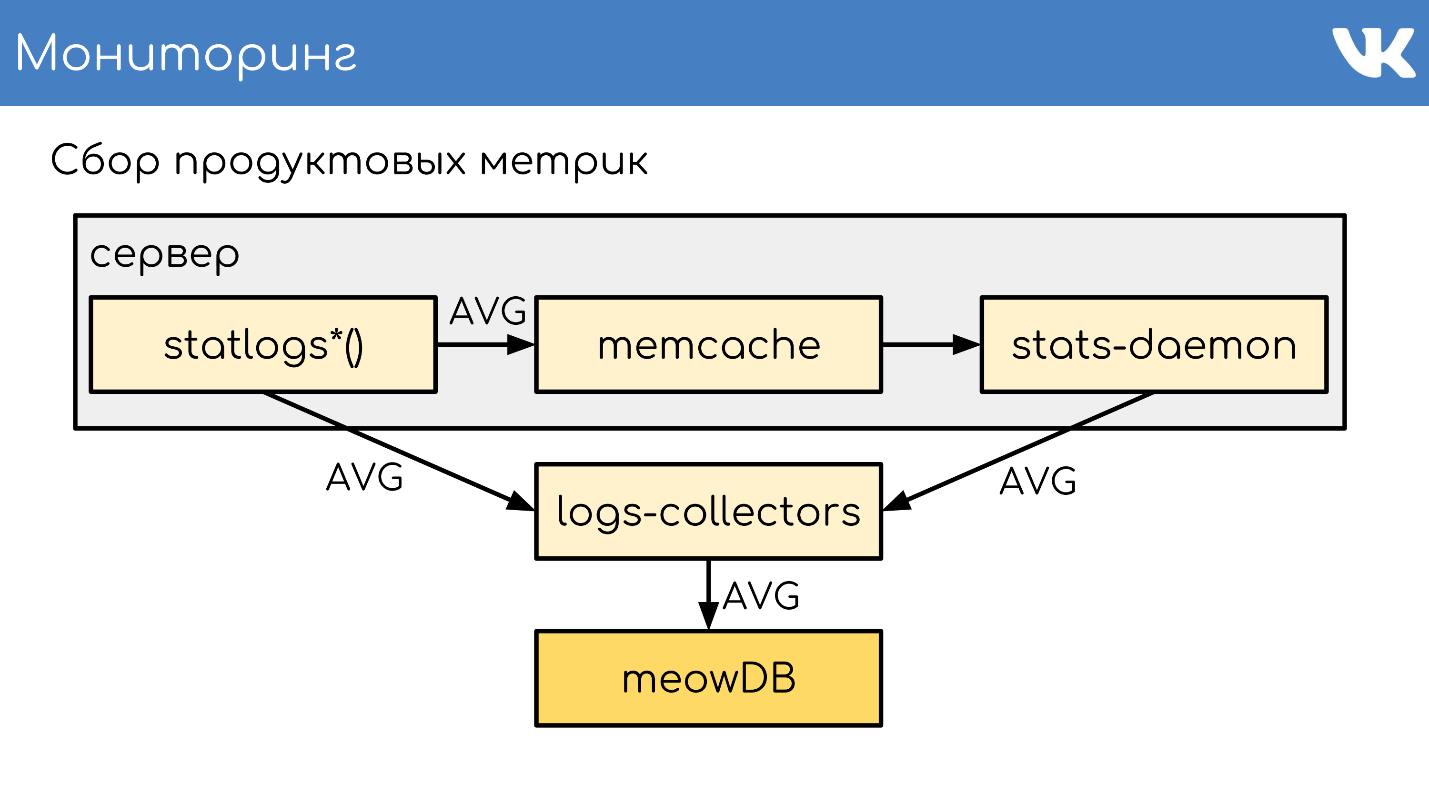
«-SQL» .

2018 , -, ClickHouse. ClickHouse — ?

, KittenHouse.
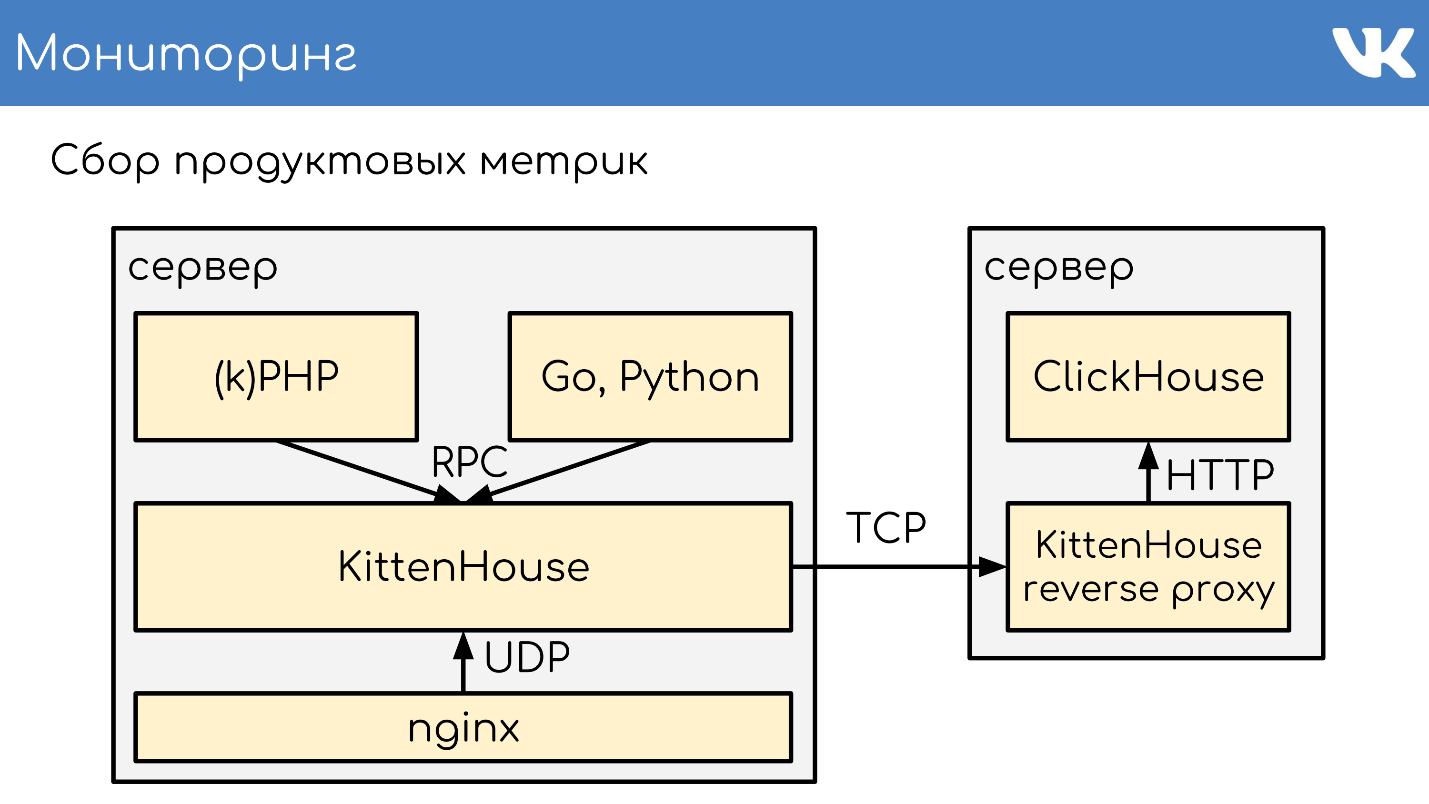 «*House»
«*House» , , UDP. *House inserts, , KittenHouse. ClickHouse, .
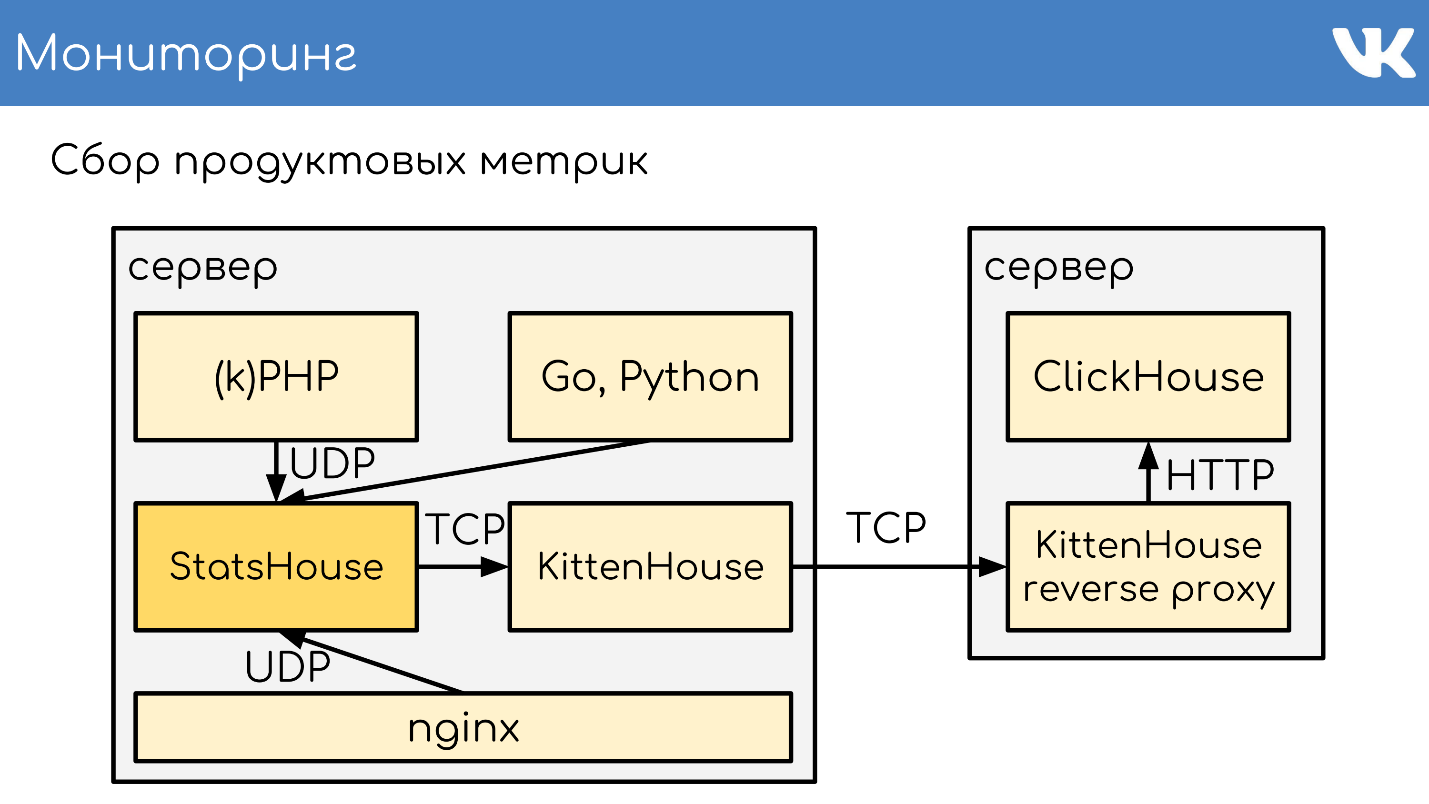
memcache, stats-daemon logs-collectors .

memcache, stats-daemon logs-collectors .
- , StatsHouse.
- StatsHouse KittenHouse UDP-, SQL-inserts, .
- KittenHouse ClickHouse.
- , StatsHouse — ClickHouse SQL.
, , . , , , . .
. , stats-daemons logs-collectors, ClickHouse , , .
, .
PHP.
git :
GitLab TeamCity . -, , — .
, diff — : , , . binlog copyfast, . ,
gossip replication , , — , . . ,
. .
kPHP
git .
HTTP- , diff — . —
binlog copyfast . , .
. copyfast' , binlog , gossip replication , -, .
graceful .
, , :
- git master branch;
- .deb ;
- binlog copyfast;
- ;
- .dep;
- dpkg -i ;
- graceful .
,
.deb ,
dpkg -i . kPHP , — dpkg? . — .
:, PHP Russia 17 PHP-. , , ( PHP!) — , PHP, .