
Salut Je veux parler en langage simple de la mécanique de l'émergence du vol à l'intérieur des machines virtuelles et de certains artefacts non évidents que nous avons pu découvrir lors de ses recherches, dans lesquels j'ai dû plonger en tant que conseiller technique de la plateforme cloud
Mail.ru Cloud Solutions . La plateforme fonctionne sur KVM.
Le temps de vol du processeur est le temps pendant lequel la machine virtuelle ne reçoit pas les ressources du processeur pour son exécution. Cette heure n'est prise en compte que dans les systèmes d'exploitation invités des environnements de virtualisation. Les raisons pour lesquelles ces ressources très allouées vont, comme dans la vie, sont très vagues. Mais nous avons décidé de le comprendre, même mis en place toute une série d'expériences. Non pas que nous sachions maintenant tout sur le vol, mais nous vous dirons quelque chose d'intéressant dès maintenant.
1. Qu'est-ce que voler
Ainsi, le vol est une métrique qui indique un manque de temps processeur pour les processus à l'intérieur d'une machine virtuelle. Comme décrit
dans le correctif du noyau KVM , le vol est le temps pendant lequel l'hyperviseur exécute d'autres processus sur le système d'exploitation hôte, bien qu'il ait mis en file d'attente le processus de la machine virtuelle pour exécution. C'est-à-dire que le vol est considéré comme la différence entre le moment où le processus est prêt à s'exécuter et le moment où le processeur se voit allouer le temps.
Le noyau du noyau reçoit le vol métrique de l'hyperviseur. Dans le même temps, l'hyperviseur ne spécifie pas exactement quels autres processus il exécute, simplement "pendant que je suis occupé, je ne peux pas vous donner de temps." Sur KVM, la prise en charge du comptage des vols a été ajoutée dans les
correctifs . Il y a deux points clés ici:
- La machine virtuelle apprend à voler de l'hyperviseur. Autrement dit, du point de vue des pertes, pour les processus sur la machine virtuelle elle-même, il s'agit d'une mesure indirecte qui peut être soumise à diverses distorsions.
- L'hyperviseur ne partage pas d'informations avec la machine virtuelle sur ce qu'il fait avec les autres - l'essentiel est qu'il n'y consacre pas de temps. Pour cette raison, la machine virtuelle elle-même ne peut pas détecter les distorsions dans l'indice de vol, qui pourraient être estimées par la nature des processus concurrents.
2. Ce qui affecte le vol
2.1. Vol de calcul
En fait, le vol est considéré à peu près comme le temps d'utilisation normal du processeur. Il n'y a pas beaucoup d'informations sur la façon dont l'élimination est envisagée. Probablement parce que la majorité considère cette question comme évidente. Mais il y a aussi des écueils ici. Pour
vous familiariser avec ce processus, vous pouvez lire l'
article de Brendann Gregg : vous en apprendrez sur un tas de nuances dans le calcul de l'utilisation et sur les situations où ce calcul sera erroné pour les raisons suivantes:
- Surchauffe du processeur, pendant laquelle les cycles d'horloge sont sautés.
- Activez / désactivez le turbo boost, à la suite de quoi la fréquence d'horloge du processeur change.
- Un changement dans la durée d'un quantum de temps qui se produit lors de l'utilisation de technologies d'économie d'énergie de processeur, telles que SpeedStep.
- Le problème du calcul de la moyenne: une estimation de l'utilisation en une minute à 80% peut masquer une rafale à court terme à 100%.
- Le verrouillage cyclique (spin lock) conduit au fait que le processeur est éliminé, mais le processus utilisateur ne voit pas de progrès dans son exécution. Par conséquent, l'utilisation estimée du processeur par le processus sera de cent pour cent, bien que le processus ne consommera pas physiquement de temps processeur.
Je n'ai pas trouvé d'article décrivant un calcul similaire pour le vol (si vous le savez, partagez les commentaires). Mais, à en juger par la source, le mécanisme de calcul est le même que pour l'élimination. C'est juste qu'un autre compteur est ajouté au noyau, directement pour le processus KVM (processus de machine virtuelle), qui compte la durée pendant laquelle le processus KVM est en veille du temps processeur. Le compteur prend des informations sur le processeur à partir de ses spécifications et cherche à voir si tous ses ticks ont été utilisés par le processus virtuel. Si c'est tout, alors nous pensons que le processeur n'était engagé que dans le processus de la machine virtuelle. Sinon, nous informons que le processeur faisait autre chose, le vol est apparu.
Le processus de comptage des vols est soumis aux mêmes problèmes que le comptage de recyclage régulier. Cela ne veut pas dire que de tels problèmes apparaissent fréquemment, mais ils semblent décourageants.
2.2. Types de virtualisation sur KVM
D'une manière générale, il existe trois types de virtualisation, et tous sont pris en charge par KVM. Le type de virtualisation peut déterminer le mécanisme par lequel le vol se produit.
Diffusion Dans ce cas, le fonctionnement du système d'exploitation de la machine virtuelle avec les périphériques physiques de l'hyperviseur se produit approximativement comme ceci:
- Le système d'exploitation invité envoie une commande à son appareil invité.
- Le pilote de périphérique invité accepte la commande, génère une demande pour le BIOS du périphérique et l'envoie à l'hyperviseur.
- Le processus de l'hyperviseur traduit une commande en une commande pour un périphérique physique, ce qui le rend, entre autres, plus sûr.
- Le pilote de périphérique physique accepte la commande modifiée et l'envoie au périphérique physique lui-même.
- Les résultats de l'exécution des commandes remontent le même chemin.
L'avantage de la traduction est qu'elle vous permet d'émuler n'importe quel périphérique et ne nécessite pas de préparation spéciale du noyau du système d'exploitation. Mais il faut d'abord le payer avec rapidité.
Virtualisation matérielle . Dans ce cas, l'appareil au niveau matériel comprend les commandes du système d'exploitation. C'est le moyen le plus rapide et le meilleur. Mais, malheureusement, il n'est pas pris en charge par tous les périphériques physiques, hyperviseurs et systèmes d'exploitation invités. Actuellement, les principaux périphériques prenant en charge la virtualisation matérielle sont les processeurs.
Paravirtualisation (paravirtualisation) . La version la plus courante de la virtualisation de périphériques sur KVM et généralement le mode de virtualisation le plus courant pour les systèmes d'exploitation invités. Sa particularité est que le travail avec certains sous-systèmes de l'hyperviseur (par exemple, avec un réseau ou une pile de disques) ou l'allocation de pages mémoire se fait à l'aide de l'API hyperviseur, sans traduire les commandes de bas niveau. L'inconvénient de cette méthode de virtualisation est la nécessité de modifier le noyau du système d'exploitation invité afin qu'il puisse interagir avec l'hyperviseur à l'aide de cette API. Mais généralement, cela est résolu en installant des pilotes spéciaux sur le système d'exploitation invité. Dans KVM, cette API est appelée
API virtio .
Avec la paravirtualisation, par rapport à la traduction, le chemin vers le périphérique physique est considérablement réduit en envoyant des commandes directement de la machine virtuelle au processus d'hyperviseur hôte. Cela vous permet d'accélérer l'exécution de toutes les instructions à l'intérieur de la machine virtuelle. Dans KVM, l'API virtio en est responsable, ce qui ne fonctionne que pour certains périphériques, comme un réseau ou un adaptateur de disque. C'est pourquoi les pilotes virtio sont placés à l'intérieur des machines virtuelles.
Le revers de cette accélération est que tous les processus qui s'exécutent à l'intérieur d'une machine virtuelle ne le restent pas. Cela crée des effets spéciaux qui peuvent entraîner l'apparition de vols. Je recommande de commencer une étude détaillée de ce problème avec
une API pour les E / S virtuelles: virtio .
2.3. Délibération équitable
La virtualisation sur un hyperviseur est, en fait, un processus ordinaire qui obéit aux lois de délestage (allocation des ressources entre les processus) dans le noyau Linux, nous allons donc l'examiner plus en détail.
Linux utilise le soi-disant CFS, Completely Fair Scheduler, qui est devenu le répartiteur par défaut depuis le noyau 2.6.23. Pour comprendre cet algorithme, vous pouvez lire l'architecture ou les sources du noyau Linux. L'essence de CFS est la répartition du temps processeur entre les processus en fonction de la durée de leur exécution. Plus le processus nécessite de temps processeur, moins il reçoit de temps. Cela garantit l'exécution «honnête» de tous les processus - de sorte qu'un processus n'occupe pas constamment tous les processeurs et que d'autres processus puissent également être exécutés.
Parfois, ce paradigme conduit à des artefacts intéressants. Les utilisateurs de longue date de Linux se souviendront probablement de la décoloration d'un éditeur de texte de bureau normal lors de l'exécution d'applications exigeantes de type compilateur. Cela s'est produit parce que les tâches non gourmandes en ressources des applications de bureau étaient en concurrence avec des tâches qui consomment activement des ressources, comme un compilateur. CFS considère que cela est malhonnête, il arrête donc périodiquement l'éditeur de texte et permet au processeur de traiter les tâches du compilateur. Cela a été corrigé en utilisant le mécanisme
sched_autogroup , mais de nombreuses autres fonctionnalités de la distribution du temps CPU entre les tâches sont restées. En fait, cette histoire ne concerne pas la gravité des problèmes dans CFS, mais une tentative pour attirer l'attention sur le fait qu'une distribution «honnête» du temps processeur n'est pas la tâche la plus triviale.
Un autre point important dans le sheduler est la préemption. Cela est nécessaire pour piloter le processus de ricanement à partir du processeur et laisser les autres travailler. Le processus d'exil est appelé commutation de contexte, commutation de contexte de processeur. Dans ce cas, tout le contexte de la tâche est sauvegardé: l'état de la pile, des registres, etc., après quoi le processus va attendre, et un autre prend sa place. C'est une opération coûteuse pour le système d'exploitation, et elle est rarement utilisée, mais en fait il n'y a rien de mal à cela. Un changement de contexte fréquent peut indiquer un problème dans le système d'exploitation, mais il se poursuit généralement en continu et n'indique rien de particulier.
Une si longue histoire est nécessaire pour expliquer un fait: plus un honnête sheduler Linux essaie de consommer de ressources processeur, plus il sera arrêté rapidement pour que d'autres processus puissent également fonctionner. Que ce soit correct ou non est un problème complexe, qui est résolu différemment sous différentes charges. Sous Windows, jusqu'à récemment, le sheduler se concentrait sur le traitement prioritaire des applications de bureau, en raison des processus d'arrière-plan qui pouvaient se bloquer. Sun Solaris avait cinq classes différentes de shedulers. Lorsqu'ils ont commencé la virtualisation, ils ont ajouté le sixième
planificateur de partage équitable , car les cinq précédents ne fonctionnaient pas correctement avec la virtualisation des zones Solaris. Je recommande de commencer une étude détaillée de ce problème avec des livres comme
Solaris Internals: Solaris 10 et OpenSolaris Kernel Architecture ou
Understanding the Linux Kernel .
2.4. Comment surveiller voler?
La surveillance du vol dans une machine virtuelle, comme toute autre mesure de processeur, est simple: vous pouvez utiliser n'importe quel moyen pour supprimer les mesures de processeur. L'essentiel est que la machine virtuelle soit sous Linux. Pour une raison quelconque, Windows ne fournit pas ces informations à ses utilisateurs. :(
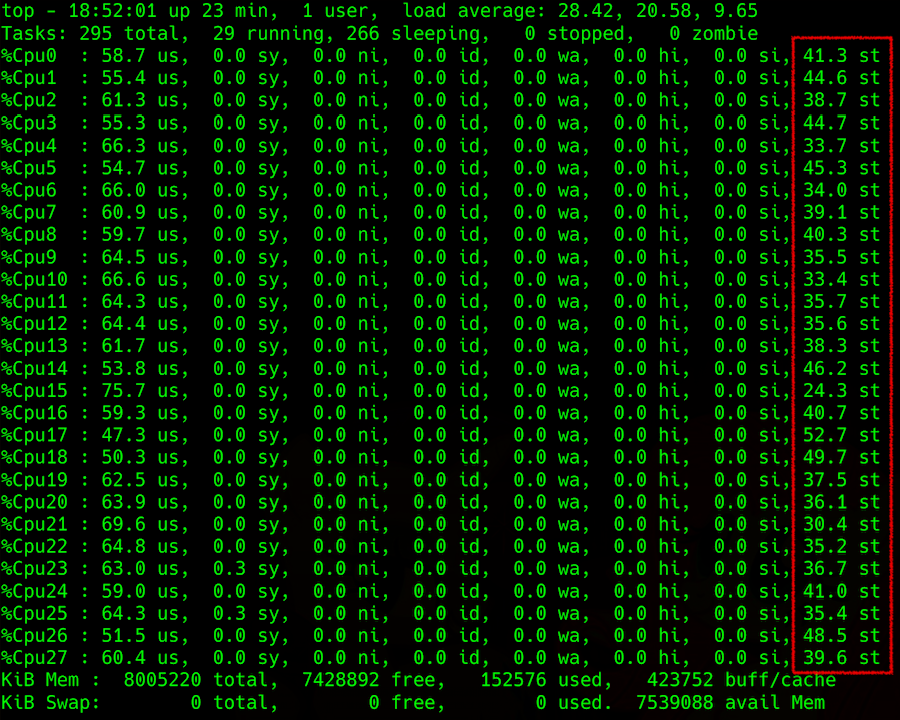 La sortie de la commande supérieure: détails de la charge du processeur, dans la colonne la plus à droite - voler
La sortie de la commande supérieure: détails de la charge du processeur, dans la colonne la plus à droite - volerLa difficulté survient lorsque vous essayez d'obtenir ces informations de l'hyperviseur. Vous pouvez essayer de prédire le vol sur la machine hôte, par exemple, par le paramètre Load Average (LA) - la valeur moyenne du nombre de processus en attente d'exécution dans la file d'attente. La méthodologie de calcul de ce paramètre n'est pas simple, mais en général, si LA, normalisé par le nombre de threads de processeur, est supérieur à 1, cela indique que le serveur Linux est quelque peu surchargé.
Qu'attendent tous ces processus? La réponse évidente est le processeur. Mais la réponse n'est pas entièrement correcte, car parfois le processeur est gratuit et LA se retourne. Rappelez-vous
comment NFS tombe et comment LA grandit . Il peut être à peu près la même chose avec un disque et avec d'autres périphériques d'entrée / sortie. Mais en fait, les processus peuvent s'attendre à la fin de tout verrou, à la fois physique, associé à un périphérique d'E / S, et logique, comme un mutex. Cela inclut également les verrous au niveau matériel (la même réponse du disque) ou la logique (les soi-disant primitives de verrouillage, qui incluent un tas d'entités, mutex adaptative et spin, sémaphores, variables de condition, verrous rw, verrous ipc ...).
Une autre caractéristique de LA est qu'elle est considérée comme la valeur moyenne du système d'exploitation. Par exemple, 100 processus sont en concurrence pour un fichier, puis LA = 50. Une telle valeur, semble-t-il, suggère que le système d'exploitation est mauvais. Mais pour d'autres codes écrits de manière tordue, cela peut être un état normal, malgré le fait qu'il ne soit mauvais que pour lui, et que les autres processus du système d'exploitation n'en souffrent pas.
En raison de cette moyenne (et pas moins d'une minute), déterminer quelque chose par l'indicateur LA n'est pas la tâche la plus reconnaissante, avec des résultats très incertains dans des cas spécifiques. Si vous essayez de le comprendre, vous constaterez que seuls les cas les plus simples sont décrits dans les articles Wikipedia et autres ressources disponibles, sans explication approfondie du processus. J'envoie tous les intéressés, encore une fois,
ici à Brendann Gregg - plus loin sur les liens. Pour qui la paresse en anglais est une
traduction de son article populaire sur LA .
3. Effets spéciaux
Passons maintenant aux principaux cas de vol que nous avons rencontrés. Je vais vous dire comment ils découlent de ce qui précède et comment ils se rapportent aux indicateurs de l'hyperviseur.
Le recyclage . Le plus simple et le plus fréquent: l'hyperviseur est réutilisé. En effet, il y a beaucoup de machines virtuelles en cours d'exécution, une grande consommation de processeur à l'intérieur, beaucoup de concurrence, l'utilisation de LA est supérieure à 1 (normalisée par les threads de processeur). Dans tous les virtualoks, tout ralentit. Le vol transmis par l'hyperviseur augmente également, il est nécessaire de redistribuer la charge ou d'éteindre quelqu'un. En général, tout est logique et compréhensible.
Paravirtualisation versus instances uniques . Il y a une seule machine virtuelle sur l'hyperviseur, elle en consomme une petite partie, mais elle donne une grande charge en entrée / sortie, par exemple, sur un disque. Et de quelque part, un petit vol apparaît, jusqu'à 10% (comme le montrent plusieurs expériences).
L'affaire est intéressante. Le vol apparaît ici juste à cause des verrous au niveau des pilotes paravirtualisés. Une interruption est créée à l'intérieur de la machine virtuelle, traitée par le pilote, et va à l'hyperviseur. En raison du traitement d'interruption sur l'hyperviseur de la machine virtuelle, cela ressemble à une demande envoyée, il est prêt à être exécuté et en attente du processeur, mais ils ne donnent pas de temps au processeur. Virtualka pense que ce temps est volé.
Cela se produit lorsque le tampon est envoyé, il va dans l'espace noyau de l'hyperviseur et nous commençons à l'attendre. Bien que, du point de vue de virtualka, il devrait immédiatement revenir. Par conséquent, selon l'algorithme de calcul de vol, ce temps est considéré comme volé. Très probablement, dans cette situation, il peut y avoir d'autres mécanismes (par exemple, le traitement de certains autres appels sys), mais ils ne devraient pas être très différents.
Sheduler contre les virtualoks lourdement chargés . Lorsqu'une machine virtuelle souffre de voler plus que d'autres, elle est connectée précisément avec le sheduler. Plus le processus charge le processeur, plus tôt le sheduler l'expulsera, afin que les autres puissent également fonctionner. Si la machine virtuelle consomme un peu, elle ne voit presque pas voler: son processus s'est honnêtement assis et attendu, il faut lui donner plus de temps. Si la machine virtuelle produit la charge maximale sur tous ses cœurs, elle est souvent expulsée du processeur et essaie de ne pas laisser trop de temps.
Pire encore, lorsque les processus à l'intérieur de la machine virtuelle essaient d'obtenir plus de processeur, car ils ne peuvent pas faire face au traitement des données. Ensuite, le système d'exploitation sur l'hyperviseur, en raison d'une optimisation honnête, donnera de moins en moins de temps processeur. Ce processus se déroule comme une avalanche, et le vol saute au ciel, bien que d'autres machines virtuelles ne le remarquent presque pas. Et plus il y a de cœurs, plus la machine tombe sous la distribution. En bref, les machines virtuelles fortement chargées avec de nombreux cœurs souffrent le plus.
Faible LA, mais il y a un vol . Si LA est d'environ 0,7 (c'est-à-dire que l'hyperviseur semble être sous-chargé), mais le vol est observé à l'intérieur des machines virtuelles individuelles:
- L'option décrite ci-dessus avec paravirtualisation. Une machine virtuelle peut recevoir des métriques qui pointent vers le vol, bien que tout va bien avec l'hyperviseur. Selon les résultats de nos expériences, une telle option de vol ne dépasse pas 10% et ne devrait pas avoir un impact significatif sur les performances des applications à l'intérieur de la machine virtuelle.
- Le paramètre LA est incorrectement considéré. Plus précisément, à chaque instant, elle est considérée comme vraie, mais lorsqu'elle est calculée en moyenne pendant une minute, elle se révèle sous-estimée. Par exemple, si une machine virtuelle consomme tous ses processeurs pendant exactement une demi-minute par tiers de l'hyperviseur, alors LA par minute sera de 0,15 sur l'hyperviseur; quatre de ces machines virtuelles fonctionnant simultanément donneront 0,6. Et le fait que pendant une demi-minute sur chacun d'eux il y ait eu un vol sauvage à 25% à LA, ne peut plus être retiré.
- Encore une fois, à cause du sheduler qui a décidé que quelqu'un mangeait trop et a laissé celui-ci attendre. En attendant, je change de contexte, je traite les interruptions et je fais d'autres choses importantes sur le système. Par conséquent, certaines machines virtuelles ne voient aucun problème, tandis que d'autres connaissent une grave dégradation des performances.
4. Autres distorsions
Il existe un autre million de raisons pour fausser le retour honnête du temps processeur sur la machine virtuelle. Par exemple, l'hypertreading et NUMA ajoutent de la complexité aux calculs. Ils confondent complètement le choix du noyau pour exécuter le processus, parce que le sheduler utilise des coefficients - poids, qui lors des changements de contextes rendent le calcul encore plus difficile.
Il existe des distorsions dues à des technologies telles que le turbo boost ou, inversement, le mode d'économie d'énergie, qui lors du calcul de l'utilisation peut augmenter ou diminuer artificiellement la fréquence ou même la tranche de temps sur le serveur. L'activation du turbo boost réduit les performances d'un thread de processeur en raison des performances accrues d'un autre. À ce moment, les informations sur la fréquence actuelle du processeur ne sont pas transmises à la machine virtuelle, et elle pense que quelqu'un fixe son temps (par exemple, elle a demandé 2 GHz, mais elle en a reçu la moitié).
En général, il peut y avoir de nombreuses causes de distorsion. Dans un système particulier, vous pouvez trouver autre chose. Il vaut mieux commencer par les livres auxquels j'ai donné les liens ci-dessus, et prendre les statistiques de l'hyperviseur avec des utilitaires comme perf, sysdig, systemtap, dont il existe des
dizaines .
5. Conclusions
- Une certaine quantité de vol peut survenir en raison de la paravirtualisation, et elle peut être considérée comme normale. Sur Internet, ils écrivent que cette valeur peut être de 5 à 10%. Cela dépend des applications à l'intérieur de la machine virtuelle et du type de charge qu'elle met sur ses périphériques physiques. Il est important de faire attention à la façon dont les applications au sein des machines virtuelles se sentent.
- Le rapport de la charge sur l'hyperviseur et le vol à l'intérieur de la machine virtuelle n'est pas toujours interconnecté sans ambiguïté, les deux estimations de vol peuvent être erronées dans des situations spécifiques à différentes charges.
- Le planificateur n'aime pas les processus qui demandent beaucoup. Il essaie de donner moins à ceux qui en demandent plus. Les grosses machines virtuelles sont mauvaises.
- Un petit vol peut être la norme sans paravirtualisation (en tenant compte de la charge à l'intérieur de la machine virtuelle, des caractéristiques de la charge des voisins, de la répartition de la charge entre les threads et d'autres facteurs).
- Si vous voulez découvrir voler dans un système spécifique, vous devez rechercher diverses options, collecter des métriques, les analyser soigneusement et réfléchir à la façon de répartir uniformément la charge. Des écarts sont possibles dans tous les cas, qui doivent être confirmés expérimentalement ou affichés dans le débogueur du noyau.