Poursuivant le sujet des concours d'apprentissage automatique sur le Habré, nous voulons présenter aux lecteurs deux autres plates-formes. Ils ne sont certainement pas aussi énormes que kaggle, mais ils méritent certainement l'attention.

Personnellement, je n'aime pas trop kaggle pour plusieurs raisons:
- premièrement, les compétitions y durent souvent plusieurs mois et beaucoup d'efforts doivent être consacrés à une participation active;
- deuxièmement, les noyaux publics (solutions publiques). Les adeptes de Kaggle leur conseillent de rester calmes avec les moines tibétains, mais en réalité, c'est vraiment dommage quand ce que vous avez fait pendant un mois ou deux se révèle soudainement être présenté sur un plateau à tout le monde.
Heureusement, des compétitions d'apprentissage automatique sont organisées sur d'autres plateformes, et quelques-unes de ces compétitions seront discutées.
| IDAO | Hackathon SNA 2019 |
|---|
Langue officielle: anglais,
organisateurs: Yandex, Sberbank, HSE | Langue officielle: russe,
organisateurs: Mail.ru Group |
Ronde en ligne: 15 janvier - 11 février 2019;
Finale sur place: du 4 au 6 avril 2019 | en ligne - du 7 février au 15 mars;
hors ligne - du 30 mars au 1er avril. |
À partir d'un certain ensemble de données sur une particule dans un grand collisionneur de hadrons (sur la trajectoire, l'élan et d'autres paramètres physiques plutôt complexes), déterminer si le muon
De cette déclaration, 2 tâches ont été distinguées:
- dans celui que vous venez d'envoyer votre prédiction,
- et dans l'autre - le code complet et le modèle de prédiction, et des restrictions plutôt strictes ont été imposées sur le temps d'exécution et l'utilisation de la mémoire | Pour la compétition SNA Hackathon, des journaux pour afficher le contenu de groupes ouverts dans les flux de nouvelles des utilisateurs pour février-mars 2018 ont été collectés. L'ensemble de test a caché la dernière semaine et demie de mars. Chaque entrée du journal contient des informations sur ce qui a été montré à qui et aussi sur la façon dont l'utilisateur a réagi à ce contenu: mettre une «classe», commentée, ignorée ou masquée dans le flux.
L'essence des tâches de SNA Hackathon est d'organiser pour chaque utilisateur du réseau social Odnoklassniki sa bande, en élevant le plus haut possible les messages qui recevront la «classe».
Au stade en ligne, la tâche était divisée en 3 parties:
1. classer les postes selon divers motifs de collaboration
2. classer les messages en fonction des images qu'ils contiennent
3. classer les postes selon le texte qu'ils contiennent |
| Une métrique personnalisée complexe, quelque chose comme ROC-AUC | ROC-AUC moyen par utilisateur |
Prix de la première étape - T-shirts pour N places, passage à la deuxième étape, où l'hébergement et les repas ont été payés pendant la compétition
La deuxième étape - ??? (Pour une raison quelconque, je n'étais pas présent à la cérémonie de remise des prix et je n'ai pas pu comprendre avec quoi je me suis retrouvé pour les prix). Des ordinateurs portables promis à tous les membres de l'équipe gagnante | Prix de la première étape - T-shirts pour les 100 meilleurs participants, passage à la deuxième étape, où ils ont payé le voyage à Moscou, l'hébergement et les repas pendant la compétition. Aussi, vers la fin de la première étape, des prix ont été annoncés pour le meilleur des 3 tâches de l'étape 1: tout le monde a gagné sur la carte vidéo RTX 2080 TI!
La deuxième étape est celle de l'équipe, les équipes comptaient de 2 à 5 personnes, prix:
1ère place - 300 000 roubles
2e place - 200 000 roubles
3e place - 100 000 roubles
prix du jury - 100 000 roubles |
| Le groupe officiel du télégramme, ~ 190 participants, communication en anglais, j'ai dû attendre plusieurs jours pour répondre aux questions | Le groupe officiel du télégramme, ~ 1500 participants, une discussion active des tâches entre les participants et les organisateurs |
| Les organisateurs ont proposé deux solutions de base, simples et avancées. Un simple nécessitait moins de 16 Go de RAM, tandis qu'un avancé de 16 ne convenait pas. Dans le même temps, avec un peu d'avance, les participants n'ont pas dépassé de manière significative la solution avancée. Le lancement de ces solutions n'a rencontré aucune difficulté. Il convient de noter que dans l'exemple avancé, il y avait un commentaire avec une indication par où commencer à améliorer la solution. | Des solutions primitives de base ont été fournies pour chacune des tâches, facilement dépassées par les participants. Au début du concours, les participants ont rencontré plusieurs difficultés: premièrement, les données ont été fournies au format Apache Parquet, et toutes les combinaisons de Python et du paquet de parquet n'ont pas fonctionné sans erreur. La deuxième difficulté était de pomper des photos depuis le nuage de messagerie, pour le moment il n'y a pas de moyen facile de télécharger une grande quantité de données à la fois. En conséquence, ces problèmes ont retardé les participants de quelques jours. |
IDAO. Première étape
La tâche consistait à classer les particules muons / non muons selon leurs caractéristiques. Une caractéristique clé de cette tâche était la présence d'une colonne de poids dans les données d'entraînement, que les organisateurs eux-mêmes ont interprétée comme une confiance dans la réponse pour cette ligne. Le problème était que plusieurs lignes contenaient des poids négatifs.
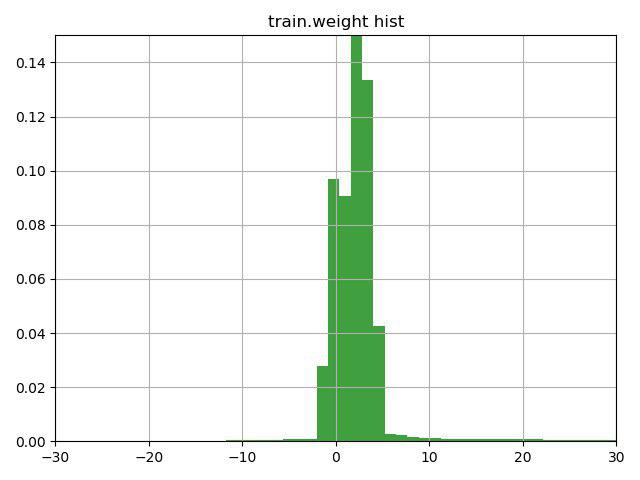
Après avoir réfléchi quelques minutes sur la ligne avec un indice (l'indice a simplement attiré l'attention sur cette caractéristique de la colonne de poids) et avoir construit ce graphique, nous avons décidé de vérifier 3 options:
1) inverser la cible des lignes avec un poids négatif (et un poids, respectivement)
2) déplacer les poids à la valeur minimale, de sorte qu'ils commencent à 0
3) n'utilisez pas de poids pour les lignes
La troisième option s'est avérée être la pire, mais les deux premières ont amélioré le résultat, la meilleure était l'option n ° 1, qui nous a immédiatement amenés à la deuxième place actuelle dans la première tâche et la première dans la seconde.

Notre prochaine étape consistait à examiner les données des valeurs manquantes. Les organisateurs nous ont donné des données déjà peignées, où il y avait pas mal de valeurs manquantes, et elles ont été remplacées par -9999.
Nous avons trouvé des valeurs manquantes dans les colonnes MatchedHit_ {X, Y, Z} [N] et MatchedHit_D {X, Y, Z} [N], et uniquement lorsque N = 2 ou 3. Comme nous l'avons compris, certaines particules ne sont pas passées par les 4 détecteurs et s'est arrêté à 3 ou 4 plaques. Les données contenaient également des colonnes Lextra_ {X, Y} [N], qui décrivent apparemment la même chose que MatchedHit_ {X, Y, Z} [N], mais en utilisant une sorte d'extrapolation. Ces maigres suppositions suggèrent qu'au lieu de valeurs manquantes dans MatchedHit_ {X, Y, Z} [N], vous pouvez remplacer Lextra_ {X, Y} [N] (uniquement pour les coordonnées X et Y). MatchedHit_Z [N] était bien rempli avec une médiane. Ces manipulations nous ont permis d'aller à 1 endroit intermédiaire pour les deux tâches.

Étant donné que pour la victoire dans la première étape, ils n'ont rien donné, nous avons pu nous arrêter, mais nous avons continué, dessiné de belles images et proposé de nouvelles fonctionnalités.

Par exemple, nous avons constaté que si nous construisons les points d'intersection des particules de chacune des quatre plaques des détecteurs, nous pouvons voir que les points sur chacune des plaques sont regroupés en 5 rectangles avec un rapport d'aspect de 4 à 5 et le centre à (0,0), et le premier rectangle n'a pas de points.
| N ° de plaque / Dimensions du rectangle | 1 | 2 | 3 | 4 | 5 |
|---|
| Planche 1 | 500x625 | 1000x1250 | 2000x2500 | 4000x5000 | 8000x10000 |
| Planche 2 | 520x650 | 1040x1300 | 2080x2600 | 4160x5200 | 8320x10400 |
| Planche 3 | 560x700 | 1120x1400 | 2240x2800 | 4480x5600 | 8960x11200 |
| Planche 4 | 600x750 | 1200x1500 | 2400x3000 | 4800x6000 | 9600x12000 |
Après avoir déterminé ces tailles, nous avons ajouté pour chaque particule 4 nouvelles caractéristiques catégorielles - le numéro du rectangle dans lequel elle coupe chaque plaque.
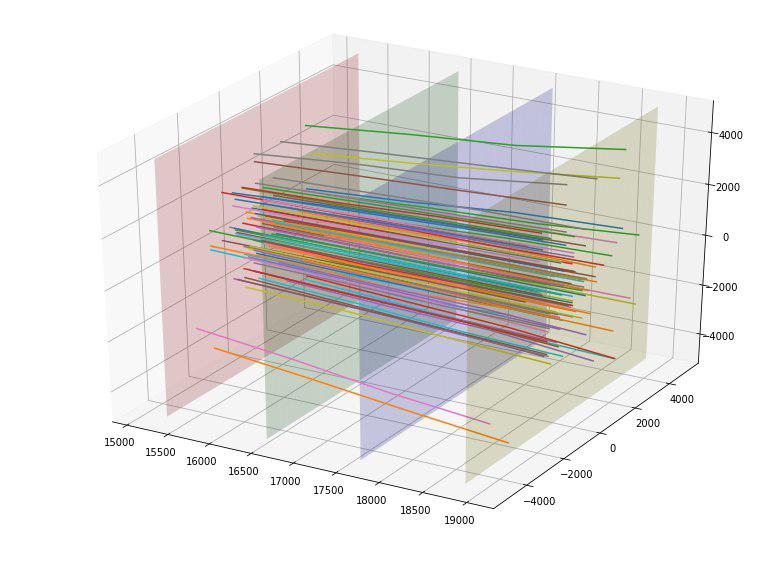
Nous avons également remarqué que les particules semblaient se disperser loin du centre et l'idée est venue d'une manière ou d'une autre d'évaluer la «qualité» de cette dispersion. Idéalement, probablement, on pourrait trouver une sorte de parabole «idéale» en fonction du point d'entrée et en estimer l'écart, mais nous nous sommes limités à la ligne «idéale». En construisant de telles lignes idéales pour chaque point d'entrée, nous avons pu calculer l'écart quadratique moyen de la trajectoire de chaque particule à partir de cette ligne. Étant donné que l'écart moyen pour l'objectif = 1 était de 152, et pour l'objectif = 0, il s'est avéré 390, nous avons provisoirement évalué cette fonctionnalité comme bonne. En effet, cette fonctionnalité a immédiatement atteint le sommet des plus utiles.
Nous avons été ravis et avons ajouté l'écart des 4 points d'intersection pour chaque particule de la ligne idéale en tant que 4 caractéristiques supplémentaires (et elles ont également bien fonctionné).
Les liens vers des articles scientifiques sur le sujet du concours, qui nous ont été donnés par les organisateurs, suggèrent que nous sommes loin d'être les premiers à résoudre ce problème et, peut-être, qu'il existe des logiciels spécialisés. Après avoir découvert le référentiel sur github où les méthodes IsMuonSimple, IsMuon, IsMuonLoose ont été implémentées, nous les avons transférées à nous-mêmes avec des modifications mineures. Les méthodes elles-mêmes étaient très simples: par exemple, si l'énergie est inférieure à un seuil, alors ce n'est pas un muon, sinon un muon. De tels signes simples ne pouvaient évidemment pas donner une augmentation dans le cas de l'utilisation de l'augmentation de gradient, nous avons donc ajouté un autre signe "distance" au seuil. Ces fonctionnalités se sont également un peu améliorées. Peut-être, après avoir analysé les méthodes existantes de manière plus approfondie, on pourrait trouver des méthodes plus solides et les ajouter aux attributs.
Vers la fin du concours, nous avons tiré une petite solution «rapide» pour la deuxième tâche, en conséquence, elle différait de la référence sur les points suivants:
- Dans les rangées avec un poids négatif, la cible a été inversée
- Rempli les valeurs manquantes dans MatchedHit_ {X, Y, Z} [N]
- Profondeur réduite à 7
- Taux d'apprentissage réduit à 0,1 (au lieu de 0,19)
En conséquence, nous avons essayé plus de fonctionnalités (pas particulièrement réussies), sélectionné les paramètres et formé catboost, lightgbm et xgboost, essayé différents mélanges de prédiction et remporté avec confiance la deuxième tâche avant d'ouvrir la privat, et figurions parmi les leaders de la première.
Après l'ouverture de la privat, nous étions en 10e place pour 1 tâche et 3 pour la seconde. Tous les dirigeants étaient confus et la vitesse à la privatisation était plus élevée qu'à la liberboard. Il semble que les données étaient mal stratifiées (ou par exemple, il n'y avait pas de lignes avec des poids négatifs dans le privé) et c'était un peu frustrant.
Hackathon SNA 2019 - Textes. Première étape
La tâche consistait à classer les messages de l'utilisateur sur le réseau social Odnoklassniki en fonction du texte qu'ils contenaient, en plus du texte, il y avait d'autres caractéristiques du message (langue, propriétaire, date et heure de création, date et heure de visualisation).
En tant qu'approches classiques du travail avec du texte, je soulignerais deux options:
- Le mappage de chaque mot dans un espace vectoriel à n dimensions, de sorte que des mots similaires ont des vecteurs similaires (plus de détails peuvent être trouvés dans notre article ), puis soit trouver le mot du milieu pour le texte ou utiliser des mécanismes qui prennent en compte la position relative des mots (CNN, LSTM / GRU) .
- Utiliser des modèles capables de travailler immédiatement avec des phrases entières. Par exemple, Bert. En théorie, cette approche devrait mieux fonctionner.
Comme c'était ma première expérience avec les textes, il serait faux d'enseigner à quelqu'un, donc je vais m'enseigner moi-même. Voici les conseils que je me donnerais au début du concours:
- Avant de courir pour apprendre quelque chose, regardez les données! En plus des textes eux-mêmes, il y avait plusieurs colonnes dans les données et on pouvait en tirer bien plus que moi. Le plus simple est de faire un encodage cible pour une partie des colonnes.
- N'apprends pas de toutes les données! Il y avait beaucoup de données (environ 17 millions de lignes) et il était tout à fait facultatif de les utiliser toutes pour tester des hypothèses. La formation et le prétraitement étaient très lents et j'aurais clairement le temps de tester des hypothèses plus intéressantes.
- < Conseils controversés > Pas besoin de chercher un modèle tueur. J'ai traité avec Elmo et Bert pendant longtemps, espérant qu'ils me mèneraient immédiatement à un haut lieu, et en conséquence j'ai utilisé des intégrations pré-entraînées FastText pour la langue russe. Avec Elmo, il n'était pas possible d'atteindre une meilleure vitesse, mais avec Bert je n'ai pas réussi à le comprendre.
- < Conseils controversés > Ne cherchez pas une caractéristique de tueur. En regardant les données, j'ai remarqué que près de 1% des textes ne contiennent pas, en fait, le texte! Mais il y avait ensuite des liens vers certaines ressources, et j'ai écrit un simple analyseur qui a ouvert le site et en a retiré le nom et la description. Cela semble être une bonne idée, mais ensuite je me suis emporté, j'ai décidé d'analyser tous les liens pour tous les textes et j'ai encore perdu beaucoup de temps. Tout cela n'a pas donné une amélioration significative du résultat final (même si j'ai compris avec le stemming, par exemple).
- Les fonctionnalités classiques fonctionnent. Google, par exemple, "text features kaggle", lit et ajoute tout. TF-IDF a également amélioré les caractéristiques statistiques, telles que la longueur du texte, le mot, la ponctuation.
- S'il existe des colonnes DateTime, vous devez les analyser en plusieurs fonctionnalités distinctes (heures, jours de la semaine, etc.). Les fonctionnalités à mettre en évidence doivent être analysées avec des graphiques / certaines mesures. Ici, j'ai tout fait correctement et j'ai sélectionné les fonctionnalités nécessaires, mais une analyse normale ne ferait pas de mal (par exemple, comme nous l'avons fait lors de la finale).
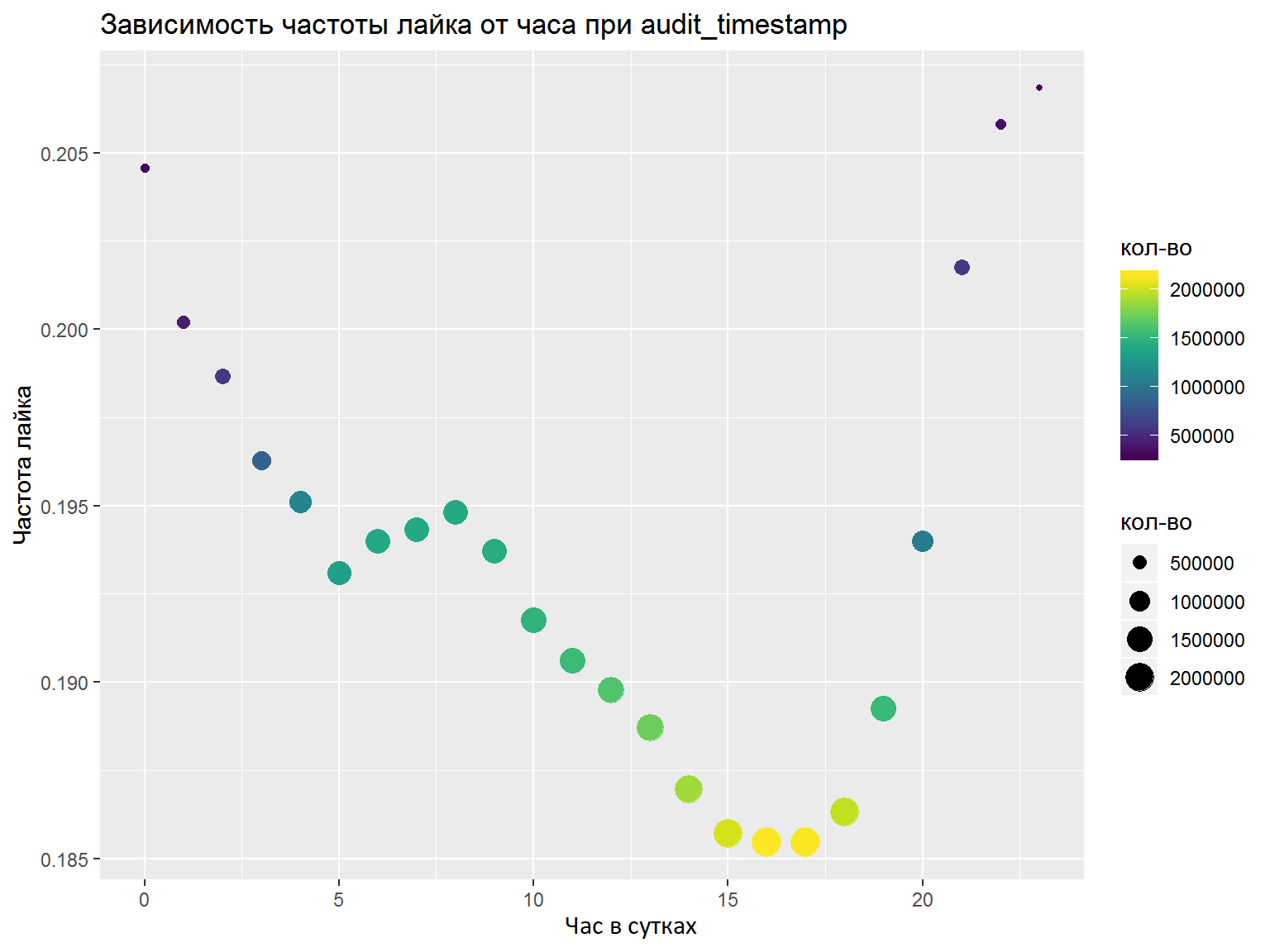
À la suite de la compétition, j'ai formé un modèle de kéros avec convolution selon les mots, et un autre basé sur LSTM et GRU. Là et là, des intégrations FastText pré-formées ont été utilisées pour la langue russe (j'ai essayé un certain nombre d'autres intégrations, mais celles-ci fonctionnaient mieux). Après avoir fait la moyenne des prévisions, j'ai pris la 7e place finale sur 76 participants.
Déjà après la première étape, un article a été publié par Nikolai Anokhin , qui a pris la deuxième place (il a participé hors du concours), et sa décision a été répétée la mienne jusqu'à un certain stade, mais il est allé plus loin en raison du mécanisme d'attention requête-clé-valeur.
Deuxième étape OK & IDAO
Les deuxièmes étapes des compétitions se sont déroulées presque d'affilée, j'ai donc décidé de les considérer ensemble.
Tout d'abord, avec l'équipe nouvellement acquise, je me suis retrouvé dans l'impressionnant bureau de Mail.ru, où notre tâche consistait à combiner les modèles des trois pistes de la première étape - texte, images et collabs. Un peu plus de 2 jours ont été alloués pour cela, qui s'est avéré être très petit. En fait, nous n'avons pu que répéter nos résultats de la première étape, sans recevoir aucun gain de l'association. En conséquence, nous avons pris la 5e place, mais le modèle de texte n'a pas pu être utilisé. En regardant les décisions des autres participants, il semble qu'il valait la peine d'essayer de regrouper les textes et de les ajouter au modèle de collaboration. Un effet secondaire de cette étape a été de nouvelles impressions, connaissances et communication avec des participants et des organisateurs sympas, ainsi qu'un grave manque de sommeil, ce qui peut avoir affecté le résultat de l'étape finale de l'OIDA.
Au stade de la finale IDAO 2019, la tâche consistait à prévoir le temps d'attente pour une commande de chauffeurs de taxi Yandex à l'aéroport. À l'étape 2, 3 tâches = 3 aéroports ont été attribués. Pour chaque aéroport, des données par minute sur le nombre de commandes de taxi pour six mois sont fournies. Et le mois prochain et les données de commande par minute pour les 2 dernières semaines ont été données comme données de test. Il n'y avait pas assez de temps (1,5 jour), la tâche était assez spécifique, une seule personne était venue de l'équipe pour le concours - et par conséquent, le triste endroit était plus proche de la fin. Parmi les idées intéressantes, il y a eu des tentatives d'utilisation de données externes: météo, embouteillages et statistiques sur les commandes de taxis Yandex. Bien que les organisateurs n'aient pas précisé en quoi consistaient les aéroports, de nombreux participants ont suggéré qu'il s'agissait de Sheremetyevo, Domodedovo et Vnukovo. Bien que cette hypothèse ait été réfutée après la compétition, des caractéristiques, par exemple, des données météorologiques de Moscou ont amélioré le résultat à la fois sur la validation et sur le classement.
Conclusion
- Les concours ML sont cool et intéressants! Il existe une application pour les compétences en analyse de données et en modèles et techniques astucieux, et le bon sens est le bienvenu.
- Le ML est déjà une énorme couche de connaissances qui semble croître de façon exponentielle. Je me suis fixé comme objectif de connaître différents domaines (signaux, images, tableaux, texte) et j'ai déjà réalisé combien apprendre. Par exemple, après ces compétitions, j'ai décidé d'étudier: les algorithmes de clustering, les techniques avancées pour travailler avec les bibliothèques de boosting de gradient (en particulier, travailler avec CatBoost sur le GPU), les réseaux de capsules et le mécanisme d'attention requête-clé-valeur.
- Pas un seul kaggle! Il existe de nombreux autres concours où au moins il est plus facile d'obtenir un T-shirt, et il y a plus de chances pour d'autres prix.
- Chattez! Dans le domaine de l'apprentissage automatique et de l'analyse des données, il y a déjà une grande communauté, il y a des groupes thématiques dans le télégramme, le mou et les gens sérieux de Mail.ru, Yandex et d'autres entreprises répondent aux questions et aident les débutants et poursuivent leur voyage dans ce domaine de la connaissance.
- Je conseille à tous ceux qui sont imprégnés du paragraphe précédent de visiter datafest - une grande conférence gratuite à Moscou, qui se tiendra du 10 au 11 mai.