Nous continuons à parler des projets du hackathon de printemps DevDays, auxquels ont participé les étudiants du programme de master
"Software Engineering / Software Engineering" .

Soit dit en passant, nous voulons inviter les lecteurs à rejoindre le
groupe VK de la magistrature . Nous y publierons les dernières nouvelles sur le recrutement et les études. La vidéo de la journée portes ouvertes peut également être trouvée dans le groupe. Nous vous rappelons: l'événement aura lieu le 29 avril, détails
sur le site .
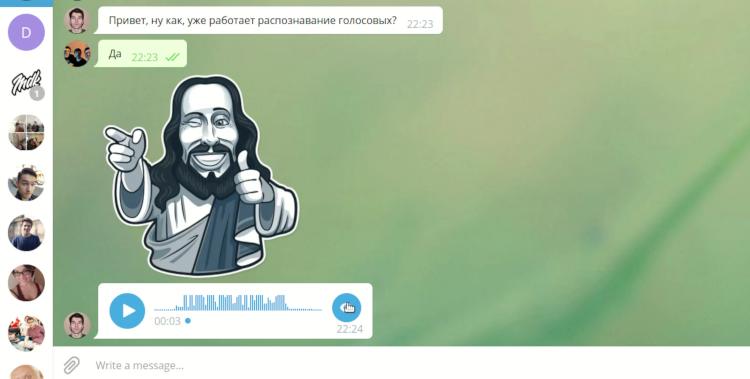
Analyseur de messages vocaux de bureau Telegram
 L'auteur de l'idée
L'auteur de l'idéeKhoroshev Artyom
Composition de l'équipeKhoroshev Artem - chef de projet / développeur / QA
Eliseev Anton - Analyste d'affaires / spécialiste en marketing
Kuklina Maria - Concepteur / développeur d'interface utilisateur
Bakhvalov Pavel - Concepteur / développeur UI / QA
De notre point de vue, Telegram est un messager moderne et pratique, et sa version PC est populaire et open source, il est donc possible de le modifier. Le client offre une fonctionnalité assez riche. En plus des messages texte standard, il contient des appels vocaux, des messages vidéo et des messages vocaux. Et c'est ce dernier qui dérange parfois leur destinataire. Souvent, il n'y a aucun moyen d'écouter un message vocal sur un ordinateur ou un ordinateur portable. Le bruit ambiant, le manque d'écouteurs peuvent interférer ou vous ne voulez pas que le contenu du message soit entendu par quiconque. De tels problèmes ne se produisent presque jamais si vous utilisez des télégrammes sur votre smartphone, car vous pouvez simplement les porter à votre oreille, contrairement à un ordinateur portable ou un PC. Nous avons essayé de résoudre ce problème.
L'objectif de notre projet chez DevDays était d'ajouter la possibilité de traduire les messages vocaux reçus en texte dans le client de bureau Telegram (ci-après Telegram Desktop).
À l'heure actuelle, tous les analogues sont des robots auxquels vous pouvez envoyer un message audio et en retour recevoir un texte. Ce n'est pas très pratique pour nous: transmettre un message à un bot n'est pas très pratique, j'aimerais avoir des fonctionnalités natives. De plus, tout bot est un tiers qui agit en tant qu'intermédiaire entre l'API de reconnaissance vocale et l'utilisateur, ce qui est au moins dangereux.
Comme indiqué précédemment, le télégramme de bureau présente deux avantages de poids: légèreté et vitesse. Et ce n'est pas un hasard, car il est entièrement écrit en C ++. Et comme nous avons décidé d'ajouter de nouvelles fonctionnalités directement au client, nous avons dû les développer en C ++.

Il y avait 4 personnes dans notre équipe. Au départ, deux cherchaient une bibliothèque appropriée pour la reconnaissance vocale, une personne a étudié le code source de Telegram-desktop, une autre déployait la construction du projet
Telegram Desktop . Plus tard, tout le monde était occupé par les corrections d'interface utilisateur et le débogage.
Il semblait que la mise en œuvre de la fonctionnalité prévue ne serait pas difficile, mais, comme toujours, des difficultés surgissaient.
La solution au problème consistait en deux sous-tâches indépendantes: sélectionner les moyens appropriés pour la reconnaissance vocale et implémenter l'interface utilisateur pour de nouvelles fonctionnalités.
Lors du choix d'une bibliothèque pour la reconnaissance vocale, nous avons immédiatement dû abandonner toutes les API hors ligne, car les modèles de langage occupent beaucoup d'espace. Mais ce n'est qu'une langue. Il est devenu clair que vous deviez utiliser l'API en ligne. Plus tard, il s'est avéré que les services de reconnaissance vocale de géants tels que Google, Yandex et Microsoft ne sont pas gratuits du tout, et nous devrons nous contenter d'une période d'essai. En conséquence, Google Speech-To-Text a été choisi, car il vous permet d'obtenir un jeton pour utiliser le service, qui durera toute une année.
Le deuxième problème que nous avons rencontré est associé à certains des inconvénients du C ++ - le zoo de diverses bibliothèques en l'absence d'un référentiel centralisé. Il se trouve que Telegram Desktop dépend de nombreuses autres bibliothèques de versions spécifiques. Le référentiel officiel contient des
instructions pour la construction du projet. Et aussi un grand nombre de problèmes ouverts concernant les problèmes de génération, par exemple,
une et
deux fois . Tous les problèmes se sont avérés être liés au fait que le script de construction a été écrit pour Ubuntu 14.04, et pour réussir à construire le télégramme sous Ubuntu 18.04, j'ai dû apporter des modifications.
Telegram Desktop lui-même va prendre un certain temps: sur un ordinateur portable avec un Intel Core i5-7200U, l'assemblage complet (indicateur -j 4) avec toutes les dépendances prend environ trois heures. Parmi ceux-ci, il faut environ 30 minutes pour lier le client lui-même (plus tard, il s'est avéré que dans la configuration de débogage, la liaison prend environ 10 minutes), mais l'étape de liaison doit être répétée à chaque fois après avoir apporté des modifications.
Malgré les problèmes, nous avons réussi à mettre en œuvre notre idée, ainsi qu'à mettre à jour le
script de construction pour Ubuntu 18.04. La démonstration du travail peut être vue
ici . Nous appliquons également plusieurs animations. Un bouton est apparu près de tous les messages vocaux, vous permettant de traduire le message en texte. Lorsque vous cliquez avec le bouton droit, vous pouvez éventuellement spécifier la langue qui sera utilisée pour la traduction. Le client est disponible en téléchargement
via le lien .
Dépôt.À notre avis, nous avons obtenu une bonne fonctionnalité de preuve de concept qui serait pratique pour de nombreux utilisateurs. Nous espérons le voir dans les futures versions de Telegram Desktop.
Prise en charge étendue du langage naturel dans IntelliJ IDEA
 L'auteur de l'idée
L'auteur de l'idéeRéservoirs Vladislav
Composition de l'équipeTanks Vladislav (chef d'équipe, travaillant avec LanguageTool et IntelliJ IDEA)
Sokolov Nikita (travailler avec LanguageTool et créer l'interface utilisateur)
Hvorov Alexander (travailler avec LanguageTool et optimiser les performances)
Sadovnikov Alexander (prise en charge de l'analyse des langages et du code de balisage)
Nous avons développé un plugin pour IntelliJ IDEA qui vérifie divers textes (commentaires et documentation, lignes littérales dans le code, texte formaté dans Markdown ou XML markup) pour la fidélité grammaticale, orthographique et stylistique (en anglais, cela s'appelle la relecture).
L'idée du projet était d'étendre le correcteur orthographique standard IntelliJ IDEA à l'échelle de Grammaire, pour créer une sorte de grammaire à l'intérieur de l'IDE.
Vous pouvez voir ce qui s'est passé
en cliquant sur le lien .
Eh bien, ci-dessous, nous parlerons davantage des capacités du plugin, ainsi que des difficultés qui se sont posées lors de sa création.
La motivationIl existe de nombreux produits conçus pour écrire des textes en langues naturelles, mais la documentation et les commentaires sur le code sont écrits le plus souvent dans des environnements de développement. Dans le même temps, les IDE font un excellent travail pour trouver des erreurs dans l'écriture de code, mais sont mal adaptés aux textes en langues naturelles. Pour cette raison, il est très facile de faire des erreurs de grammaire, de ponctuation ou de style, et l'environnement de développement ne les indiquera pas. Il est très important de faire une erreur en écrivant l'interface utilisateur, car cela affectera non seulement la compréhensibilité du code, mais aussi les utilisateurs de l'application développée eux-mêmes.
IntelliJ IDEA est l'un des environnements de développement les plus populaires et développés, ainsi que les IDE basés sur IntelliJ Platform. IntelliJ Platform dispose déjà d'un correcteur orthographique intégré, mais il n'enregistre pas même les erreurs de grammaire les plus simples. Nous avons décidé d'intégrer l'un des systèmes d'analyse de langage naturel les plus populaires dans IntelliJ IDEA.
Implémentation
Nous ne nous sommes pas donné pour tâche de créer notre propre système de vérification des textes, nous avons donc profité de la solution existante. L'option la plus appropriée était
LanguageTool . La licence nous a permis de l'utiliser librement à nos fins: elle est gratuite, écrite en Java et présentée en open-source. De plus, il prend en charge 25 langues et se développe depuis plus de quinze ans. Malgré son ouverture, LanguageTool est un concurrent sérieux des solutions de vérification de texte payantes, et le fait qu'il soit capable de travailler localement est littéralement sa caractéristique la plus meurtrière.
Le code du plugin est dans le
référentiel sur GitHub . L'ensemble du projet a été écrit en Kotlin avec un petit ajout de Java pour l'interface utilisateur. Pendant le hackathon, a réussi à implémenter la prise en charge de Markdown, JavaDoc, HTML et Plain Text. Après le hackathon, une grande mise à jour a ajouté la prise en charge de XML, des littéraux de chaîne en Java, Kotlin et Python, ainsi que de la vérification orthographique.
Des difficultésAssez rapidement, nous avons réalisé que si nous alimentions tout le texte à chaque fois pour la vérification de LanguageTool, l'interface IDEA se bloquerait sur des textes plus ou moins sérieux, car l'inspection elle-même bloque le flux d'interface utilisateur. Le problème a été résolu par la vérification de `ProgressManager.checkCancelled` - cette fonction lève une exception si IDEA considère que l'inspection doit être interrompue.
Cela a complètement éliminé les blocages, mais il est impossible de l'utiliser: le texte est traité depuis très longtemps. De plus, dans notre cas, le plus souvent une très petite partie du texte change et je veux en quelque sorte mettre en cache les résultats. C'est ce que nous avons fait. Afin de ne pas tout vérifier à chaque fois, nous avons divisé le texte en morceaux de manière déterministe et n'avons vérifié que ceux qui avaient changé. Comme les textes peuvent être volumineux et ne veulent pas charger le cache, nous avons stocké non pas les textes eux-mêmes, mais leurs hachages. Cela a permis au plug-in de fonctionner sans problème, même sur des fichiers volumineux.
LanguageTool prend en charge plus de 25 langues, mais à peine un utilisateur en a besoin. Je voulais donner la possibilité de télécharger des bibliothèques pour une langue spécifique sur demande (si cochée par une coche dans l'interface utilisateur). Nous l'avons même implémenté, mais cela s'est avéré trop compliqué et peu fiable. En particulier, nous avons dû charger LanguageTool avec un nouvel ensemble de langues en tant que chargeur de classe séparé, puis l'initialiser soigneusement. En même temps, toutes les bibliothèques se trouvaient dans le référentiel utilisateur .m2, et à chaque démarrage, nous devions vérifier leur intégrité. En fin de compte, nous avons décidé que si les utilisateurs avaient des problèmes avec la taille du plugin, nous fournirions un plugin séparé pour plusieurs des langues les plus populaires.
Après le hackathonLe hackathon s'est terminé, mais le travail sur le plug-in s'est poursuivi avec une composition plus étroite. Je voulais prendre en charge les lignes, les commentaires et même les constructions de langage, telles que les noms de variable et de classe. Ceci n'est actuellement pris en charge que pour Java, Kotlin et Python, mais nous espérons que cette liste s'allongera. Nous avons corrigé de nombreux petits bugs et sommes devenus plus compatibles avec le correcteur orthographique intégré Idea. De plus, le support XML et la vérification orthographique sont apparus. Tout cela se trouve dans la deuxième version que nous avons publiée récemment.
Et ensuite?Un tel plugin peut être utile non seulement pour les développeurs, mais aussi pour les rédacteurs techniques (travaillant souvent, par exemple, avec XML dans l'EDI). Chaque jour, ils doivent travailler avec le langage naturel, sans avoir un assistant sous la forme de conseils d'éditeur sur les erreurs possibles. Notre plugin fournit de tels conseils et le fait avec un haut degré de précision.
Nous prévoyons de développer le plugin à la fois en ajoutant de nouvelles langues et en explorant l'approche générale de l'organisation de la validation de texte. Dans un avenir proche, la mise en œuvre de profils de style (ensembles de règles qui définissent le guide de style pour le texte, par exemple, «n'écrivez pas par exemple, mais écrivez le formulaire complet»), développez le dictionnaire et améliorez l'interface utilisateur (en particulier, nous voulons donner à l'utilisateur la possibilité non seulement d'ignorer le mot, mais d'ajouter lui dans le dictionnaire, indiquant une partie du discours).