La première partie de l'article sur les bases de la PNL peut être lue
ici . Aujourd'hui, nous allons parler de l'une des tâches NLP les plus populaires - la reconnaissance d'entités nommées (NER) - et analyser en détail l'architecture des solutions à ce problème.
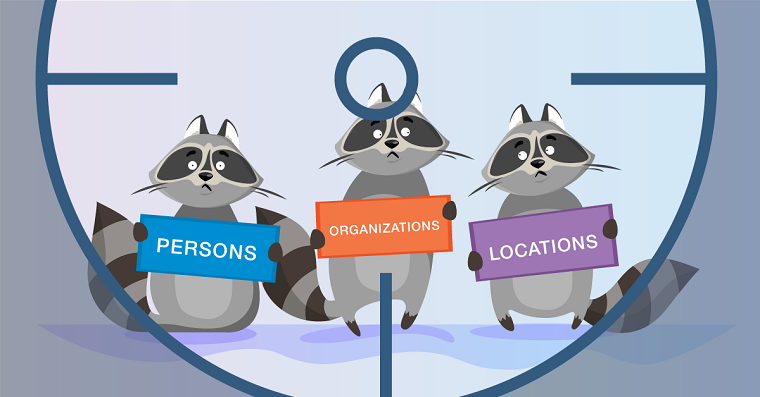
La tâche de NER est de mettre en évidence des étendues d'entités dans le texte (span est un fragment continu de texte). Supposons qu'il y ait un texte d'actualités et que nous voulons mettre en évidence les entités qu'il contient (un ensemble prédéfini - par exemple, des personnes, des lieux, des organisations, des dates, etc.). La tâche du NER est de comprendre que la partie du texte «
1er janvier 1997 » est la date, «
Kofi Annan » est la personne et «
ONU » est l’organisation.
Que sont les entités nommées? Dans le premier cadre classique, formulé lors de la conférence
MUC-6 en 1995, il s'agit de personnes, de lieux et d'organisations. Depuis lors, plusieurs packages disponibles sont apparus, chacun ayant son propre ensemble d'entités nommées. En règle générale, de nouveaux types d'entités sont ajoutés aux personnes, aux emplacements et aux organisations. Les plus courants d'entre eux sont numériques (dates, montants monétaires), ainsi que diverses entités (de divers - autres entités nommées; un exemple est l'iPhone 6).
Pourquoi avez-vous besoin de résoudre le problème NER
Il est facile de comprendre que, même si nous sommes bien en mesure d'identifier les personnes, les emplacements et les organisations dans le texte, il est peu probable que cela suscite un grand intérêt parmi les clients. Bien qu'une certaine application pratique, bien sûr, pose le problème dans le cadre classique.
Un des scénarios où une solution au problème dans la formulation classique peut encore être nécessaire est la structuration des données non structurées. Supposons que vous ayez une sorte de texte (ou un ensemble de textes) et que les données qu'il contient doivent être entrées dans une base de données (tableau). Les entités nommées classiques peuvent correspondre à des lignes d'un tel tableau ou servir de contenu à certaines cellules. En conséquence, afin de remplir correctement le tableau, vous devez d'abord sélectionner dans le texte les données que vous y entrerez (généralement après cela, il y a une autre étape - identifier les entités dans le texte, lorsque nous comprenons que l'
ONU et
les Nations Unies couvrent "Reportez-vous à la même organisation; cependant, la tâche d'identification ou de liaison d'entité est une autre tâche, et nous n'en parlerons pas en détail dans cet article).
Cependant, il existe plusieurs raisons pour lesquelles le NER est l'une des tâches de PNL les plus populaires.
Premièrement, l'extraction d'entités nommées est une étape vers la «compréhension» du texte. Cela peut à la fois avoir une valeur indépendante et aider à mieux résoudre d'autres tâches PNL.
Donc, si nous savons où les entités sont mises en surbrillance dans le texte, nous pouvons trouver des fragments du texte qui sont importants pour certaines tâches. Par exemple, nous pouvons sélectionner uniquement les paragraphes dans lesquels des entités d'un certain type sont rencontrées, puis travailler uniquement avec eux.
Supposons que vous receviez une lettre, et ce serait bien de faire un extrait uniquement de la partie où il y a quelque chose d'utile, et pas seulement «
Bonjour, Ivan Petrovich ». Si vous pouvez distinguer les entités nommées, vous pouvez rendre l'extrait intelligent en affichant la partie de la lettre où se trouvent les entités qui nous intéressent (et pas seulement afficher la première phrase de la lettre, comme cela se fait souvent). Ou vous pouvez simplement mettre en évidence dans le texte les parties nécessaires de la lettre (ou, directement, les entités qui sont importantes pour nous) pour la commodité des analystes.
De plus, les entités sont des collocations rigides et fiables; leur sélection peut être importante pour de nombreuses tâches. Supposons que vous ayez un nom pour une entité nommée et, quelle qu'elle soit, elle est très probablement continue, et toutes les actions avec celle-ci doivent être effectuées comme avec un seul bloc. Par exemple, traduisez le nom d'une entité en nom d'une entité. Vous voulez traduire
«Pyaterochka Shop» en français en un seul morceau, et non pas scindé en plusieurs fragments qui ne sont pas liés les uns aux autres. La capacité de détecter les colocations est également utile pour de nombreuses autres tâches - par exemple, pour l'analyse syntaxique.
Sans résoudre le problème NER, il est difficile d'imaginer la solution à de nombreux problèmes de PNL, par exemple, résoudre l'anaphore du pronom ou créer des systèmes de questions-réponses. L'anaphore du pronom nous permet de comprendre à quel élément du texte le pronom se réfère. Par exemple, souhaitons analyser le texte «
Charme galopé sur un cheval blanc. La princesse a couru à sa rencontre et l'a embrassé . " Si nous avons souligné l'essence de Persona sur le mot "Charming", alors la machine sera beaucoup plus facile à comprendre que la princesse a probablement embrassé non pas le cheval, mais le prince de Charming.
Nous donnons maintenant un exemple de la façon dont l'allocation d'entités nommées peut aider à la construction de systèmes de questions-réponses. Si vous posez la question "
Qui a joué le rôle de Dark Vador dans le film" L'Empire contre-attaque " " dans votre moteur de recherche préféré ", alors avec une forte probabilité vous obtiendrez la bonne réponse. Cela se fait simplement en isolant les entités nommées: nous sélectionnons les entités (film, rôle, etc.), comprenons ce qui nous est demandé, puis cherchons la réponse dans la base de données.
Probablement la considération la plus importante en raison de laquelle la tâche NER est si populaire: l'énoncé du problème est très flexible. En d'autres termes, personne ne nous oblige à distinguer les lieux, les personnes et les organisations. Nous pouvons sélectionner tous les morceaux de texte continus dont nous avons besoin qui sont quelque peu différents du reste du texte. En conséquence, vous pouvez choisir votre propre ensemble d'entités pour une tâche pratique spécifique venant du client, marquer le corps des textes avec cet ensemble et former le modèle. Un tel scénario est omniprésent, ce qui fait du NER l'une des tâches de PNL les plus fréquemment effectuées dans l'industrie.
Je vais donner quelques exemples de tels cas de clients spécifiques, à la solution desquels il m'est arrivé de participer.
Voici la première: vous permettre d'avoir un jeu de factures (virements). Chaque facture a une description textuelle, qui contient les informations nécessaires sur le transfert (qui, qui, quand, quoi et pour quelle raison envoyé). Par exemple, la société X a transféré 10 $ à la société Y à telle ou telle date pour telle ou telle chose. Le texte est assez formel, mais écrit dans une langue vivante. Les banques ont des personnes spécialement formées qui lisent ce texte puis saisissent les informations qu'il contient dans une base de données.
Nous pouvons sélectionner un ensemble d'entités qui correspondent aux colonnes du tableau dans la base de données (noms d'entreprises, montant du transfert, sa date, type de transfert, etc.) et apprendre à les sélectionner automatiquement. Après cela, il ne reste plus qu'à entrer les entités sélectionnées dans le tableau, et les personnes qui ont déjà lu les textes et entré des informations dans la base de données pourront effectuer des tâches plus importantes et utiles.
Le deuxième cas d'utilisation est le suivant: vous devez analyser les lettres avec les commandes des magasins en ligne. Pour ce faire, vous devez connaître le numéro de commande (afin que toutes les lettres liées à cette commande puissent être marquées ou placées dans un dossier séparé), ainsi que d'autres informations utiles - le nom du magasin, la liste des marchandises commandées, le montant du chèque, etc. - les numéros de commande, les noms de magasins, etc. - peuvent être considérés comme des entités nommées, et il est également facile d'apprendre à les distinguer à l'aide des méthodes que nous allons maintenant analyser.
Si le NER est si utile, pourquoi n'est-il pas utilisé partout?
Pourquoi la tâche NER n'est-elle pas toujours résolue et les clients commerciaux sont toujours disposés à payer le moins d'argent pour sa solution? Il semblerait que tout soit simple: comprendre quel morceau de texte mettre en évidence, et le mettre en valeur.
Mais dans la vie, tout n'est pas si facile, diverses difficultés surgissent.
La complexité classique qui nous empêche de vivre en résolvant une variété de problèmes de PNL est toutes sortes d'ambiguïtés dans la langue. Par exemple, des mots polysémantiques et des homonymes (voir exemples dans la
partie 1 ). Il existe un type d'homonymie distinct qui est directement lié à la tâche NER - des entités complètement différentes peuvent être appelées le même mot. Par exemple, prenons le mot «
Washington ». Qu'est ce que c'est Personne, ville, état, nom du magasin, nom du chien, objet, autre chose? Pour mettre en évidence cette section du texte en tant qu'entité spécifique, il faut prendre en compte beaucoup de choses - le contexte local (sur quoi portait le texte précédent), le contexte global (connaissance du monde). Une personne prend tout cela en compte, mais ce n'est pas facile d'apprendre à une machine à le faire.
La deuxième difficulté est technique, mais ne la sous-estimez pas. Quelle que soit la façon dont vous définissez l'essence, il y aura très probablement des cas limites et difficiles - lorsque vous devrez mettre en évidence l'essence, quand vous n'aurez pas besoin de quoi inclure dans la portée de l'entité, et ce qui ne l'est pas, etc. (bien sûr, si notre essence est pas quelque chose de légèrement variable, comme un e-mail; cependant, vous pouvez généralement distinguer ces entités triviales par des méthodes triviales - écrivez une expression régulière et ne pensez à aucun type d'apprentissage automatique).
Supposons, par exemple, que nous voulons mettre en évidence les noms des magasins.
Dans le texte «La
boutique de détecteurs de métaux professionnels vous souhaite la bienvenue », nous voulons presque certainement inclure le mot «boutique» dans notre essence - cela fait clairement partie du nom.
Un autre exemple est "
Vous êtes accueilli par Volkhonka Prestige, votre magasin de marque préféré à des prix abordables ." Probablement, le mot "store" ne devrait pas être inclus dans l'annotation - ce n'est clairement pas une partie du nom, mais simplement sa description. De plus, si vous incluez ce mot dans le nom, vous devez également inclure les mots «- votre préféré», et cela, peut-être, je ne veux pas du tout le faire.
Troisième exemple:
"L'animalerie de Nemo vous écrit. " Il n'est pas clair si la «animalerie» fait partie du nom ou non. Dans cet exemple, il semble que tout choix sera adéquat. Cependant, il est important que nous devions faire ce choix et le corriger dans les instructions pour les marqueurs, de sorte que dans tous les textes, ces exemples soient marqués également (si cela n'est pas fait, l'apprentissage automatique commencera inévitablement à faire des erreurs en raison de contradictions dans le balisage).
Il existe de nombreux exemples de ce type, et si nous voulons que le marquage soit cohérent, tous doivent être inclus dans les instructions pour les marqueurs. Même si les exemples eux-mêmes sont simples, ils doivent être pris en compte et calculés, ce qui rendra l'instruction plus grande et plus compliquée.
Eh bien, plus les instructions sont compliquées, plus vous avez besoin de marqueurs qualifiés. C'est une chose lorsque le scribe doit déterminer si la lettre est le texte de l'ordre ou non (bien qu'il y ait des subtilités et des cas limites ici), et c'est une autre chose lorsque le scribe doit lire les instructions de 50 pages, trouver des entités spécifiques, comprendre ce qu'il faut inclure dans annotation et quoi non.
Les marqueurs qualifiés sont chers et ne fonctionnent généralement pas très rapidement. Vous dépenserez l'argent à coup sûr, mais ce n'est pas du tout un fait que vous obtenez le balisage parfait, car si les instructions sont complexes, même une personne qualifiée peut faire une erreur et mal comprendre quelque chose. Pour lutter contre cela, un balisage multiple du même texte par différentes personnes est utilisé, ce qui augmente encore le prix du balisage et le temps pour lequel il est préparé. Éviter ce processus ou même le réduire sérieusement ne fonctionnera pas: pour apprendre, vous devez avoir un ensemble de formation de haute qualité de tailles raisonnables.
Ce sont les deux principales raisons pour lesquelles NER n'a pas encore conquis le monde et pourquoi les pommiers ne poussent toujours pas sur Mars.
Comment comprendre si le problème NER a été résolu de manière qualitative
Je vais vous parler un peu des mesures que les gens utilisent pour évaluer la qualité de leur solution au problème NER, et des cas standard.
La métrique principale pour notre tâche est une f-mesure stricte. Expliquez ce que c'est.
Ayons un balisage de test (le résultat du travail de notre système) et un standard (balisage correct des mêmes textes). Ensuite, nous pouvons compter deux métriques - l'exactitude et l'exhaustivité. La précision est la fraction des véritables entités positives (c'est-à-dire les entités sélectionnées par nous dans le texte, qui sont également présentes dans la norme), par rapport à toutes les entités sélectionnées par notre système. Et l'exhaustivité est la fraction des véritables entités positives par rapport à toutes les entités présentes dans la norme. Un exemple de classificateur très précis mais incomplet est un classificateur qui sélectionne un objet correct dans le texte et rien d'autre. Un exemple de classificateur très complet mais généralement inexact est un classificateur qui sélectionne une entité sur n'importe quel segment du texte (ainsi, en plus de toutes les entités standard, notre classificateur alloue une énorme quantité de déchets).
La mesure F est la moyenne harmonique de précision et d'exhaustivité, une métrique standard.
Comme nous l'avons décrit dans la section précédente, la création d'un balisage coûte cher. Par conséquent, il n'y a pas beaucoup de bâtiments accessibles avec un balisage.
Il y a une certaine variété pour la langue anglaise - il y a des conférences populaires où les gens rivalisent pour résoudre le problème NER (et un balisage est créé pour les compétitions). MUC, TAC, CoNLL sont des exemples de telles conférences au cours desquelles leurs organes avec des entités nommées ont été créés. Tous ces cas se composent presque exclusivement de textes d'actualité.
Le principal organe sur lequel la qualité de la résolution du problème NER est évaluée est le cas CoNLL 2003 (voici un
lien vers le cas lui -
même , voici
un article à ce sujet ). Il y a environ 300 000 jetons et jusqu'à 10 000 entités. Désormais, les systèmes SOTA (état de l'art - c'est-à-dire les meilleurs résultats pour le moment) montrent dans ce cas une f-mesure de l'ordre de 0,93.
Pour la langue russe, tout est bien pire. Il existe un organisme public (
FactRuEval 2016 , voici
un article à ce sujet , voici
un article sur Habré ), et il est très petit - il n'y a que 50 mille jetons. Dans ce cas, le cas est assez spécifique. En particulier, l'essence plutôt controversée de LocOrg (emplacement dans un contexte organisationnel) se détache dans le cas, qui est confondu avec les organisations et les emplacements, ce qui fait que la qualité de la sélection de ces derniers est inférieure à ce qu'elle pourrait être.
Comment résoudre le problème NER
Réduction du problème NER au problème de classification
Malgré le fait que les entités sont souvent verbeuses, la tâche NER se résume généralement au problème de classification au niveau du jeton, c'est-à-dire que chaque jeton appartient à l'une des nombreuses classes possibles. Il existe plusieurs méthodes standard pour ce faire, mais la plus courante est appelée schéma BIOES. Le schéma consiste à ajouter un préfixe à l'étiquette d'entité (par exemple, PER pour les personnes ou ORG pour les organisations), qui indique la position du jeton dans la plage de l'entité. Plus de détails:
B - depuis le début du mot - le premier jeton de la plage de l'entité, qui se compose de plus d'un mot.
Je - des mots à l'intérieur - c'est ce qui est au milieu.
E - à partir du mot se terminant, c'est le dernier jeton de l'entité, qui se compose de plus d'un élément.
S est célibataire. Nous ajoutons ce préfixe si l'entité se compose d'un mot.
Ainsi, nous ajoutons l'un des 4 préfixes possibles à chaque type d'entité. Si le jeton n'appartient à aucune entité, il est marqué d'une étiquette spéciale, généralement étiquetée OUT ou O.
Nous donnons un exemple. Ayons le texte "
Karl Friedrich Jerome von Munchausen est né à Bodenwerder ." Ici, il y a une entité verbeuse - la personne "Karl Friedrich Jerome von Münhausen" et une en un mot - l'emplacement "Bodenwerder".
Ainsi, BIOES est un moyen de mapper des projections de plages ou d'annotations au niveau du jeton.
Il est clair que, grâce à ce balisage, nous pouvons établir sans ambiguïté les limites de toutes les annotations d'entité. En effet, à propos de chaque jeton, nous savons s'il est vrai qu'une entité commence par ce jeton ou s'y termine, ce qui signifie s'il faut mettre fin à l'annotation de l'entité sur un jeton donné, ou l'étendre aux jetons suivants.
La grande majorité des chercheurs utilisent cette méthode (ou ses variantes avec moins d'étiquettes - BIOE ou BIO), mais elle présente plusieurs inconvénients importants. Le principal est que le schéma ne permet pas de travailler avec des entités imbriquées ou entrecroisées. Par exemple, l'essence de «
l'Université d'État de Moscou du nom de M.V. Lomonosov »est une organisation. Mais Lomonosov lui-même est une personne, et ce serait aussi bien de demander dans le balisage. En utilisant la méthode de balisage décrite ci-dessus, nous ne pouvons jamais transmettre ces deux faits en même temps (car nous ne pouvons faire qu'une seule marque sur un seul jeton). Par conséquent, le jeton «Lomonosov» peut faire partie de l'annotation de l'organisation ou de l'annotation de la personne, mais jamais les deux en même temps.
Autre exemple d'entités intégrées: «
Département de logique mathématique et théorie des algorithmes de la Faculté de mécanique et de mathématiques de l'Université d'État de Moscou ». Ici, idéalement, je voudrais distinguer 3 organisations imbriquées, mais la méthode de balisage ci-dessus vous permet de sélectionner soit 3 entités disjointes, soit une entité qui annote le fragment entier.
En plus de la manière standard de réduire la tâche à la classification au niveau du jeton, il existe également un format de données standard dans lequel il est pratique de stocker le balisage pour la tâche NER (ainsi que pour de nombreuses autres tâches NLP). Ce format est appelé
CoNLL-U .
L'idée principale du format est la suivante: nous stockons les données sous la forme d'un tableau, où une ligne correspond à un jeton et les colonnes correspondent à un type spécifique d'attributs de jeton (y compris le mot lui-même, la forme du mot). Dans un sens étroit, le format CoNLL-U définit quels types d'entités (c'est-à-dire les colonnes) sont incluses dans le tableau - un total de 10 types d'entités pour chaque jeton. Mais les chercheurs considèrent généralement le format plus largement et incluent les types de fonctionnalités nécessaires pour une tâche particulière et une méthode pour le résoudre.
Vous trouverez ci-dessous un exemple de données au format CoNLL-U, où 6 types d'attributs sont pris en compte: le numéro de la phrase actuelle dans le texte, la forme du mot (c'est-à-dire le mot lui-même), le lemme (forme initiale du mot), l'étiquette POS (partie du discours), la morphologie caractéristiques du mot et, enfin, l'étiquette de l'entité allouée sur ce jeton.

Comment avez-vous résolu le problème NER auparavant?
À strictement parler, le problème peut être résolu sans apprentissage automatique - à l'aide de systèmes basés sur des règles (dans la version la plus simple - à l'aide d'expressions régulières). Cela semble obsolète et inefficace, cependant, vous devez comprendre si votre domaine est limité et clairement défini et si l'entité, en soi, n'a pas beaucoup de variabilité, le problème NER est résolu en utilisant des méthodes basées sur des règles assez rapidement et efficacement.
, (, ), , .
, ( ), . .
, 2000- SOTA . , .
, — . . . , ( ), 1, 0.
, (POS-), ( — , , ), (. . ), (, ), .
, , :
- “ , ”,
- “ ”,
- “ ”,
- “ ” ( , , “iPhone”).
, , - , — .
, – . , , , – , , , – , , , – . , (“” , “” — ), . , , , — ( , NER 2 — ).
, NER, ,
Nadeau and Sekine (2007), A survey of Named Entity Recognition and Classification . , , , ( - , , , HMM, , , , ), .
(summarized pattern ). NLP. , 2018
(word shape) .
NER ?
NLP almost from scratch
NER
2011 .
SOTA- CoNLL 2003. , . ML , .
NER , , NLP . , , , , . , NER ( , NLP).
, .
, :
- «» (window based approach),
- (sentence based approach).
– , – , .. , .
: , “
The cat sat on the mat ”.
K (, , , , . .). (, , 1 ). Soit

— , i- j- .
, sentence based approach , , — , . i i-core, core — , ( , , ).
—
, Lookup Table ( “” ). ,
— , 1, – 0.
sur
, . .
( i 1 K) – , .
word2vec ( , word2vec, ) , , word2vec ( ).
, ,
sur
.
, sentence based approach (window based ). , (. . “The cat sat on the mat” 6 ). , , , — core.
: 3-5. , , ( ). m f, m — , (. . ), f — .
, — max pooling (. . ), f. , , , core, (max pooling , , ). “ ” , , core.
- ( — HardTanh), softmax d, d — .
, , — ( ), softmax — , core.
CharCNN-BLSTM-CRF
CharCNN-BLSTM-CRF, , SOTA 2016-2018 ( 2018 , NLP ; ). NER
Lample et al (2016) Ma & Hovy (2016) .
, NLP,
.
- . . – , – , — : , . . - .
. , , . — . Lookup- , , .
, .
, . — , , ( , ).
CharCNN ( , CharRNN). , - . - (, 20) — . , — , .
, , , , — ( ). - , .
2 .
– ( CharCNN). , sentence based approach .
, (, 3), . max pooling, 1 . .
– (BLSTM BiGRU; ,
). RNN.
, - . - .
BLSTM BiGRU. i- , RNN. ( RNN), ( RNN). - .
NLP, NLP.
, , NER. - , . .
– softmax d, d — . ( ).
, — . BiRNN, , . , I-PER B-PER I-PER.
— CRF (conditional random fields). , (
), , CRF , .
, CharCNN-BLSTM-CRF, SOTA NER 2018 .
. CharCNN f- 1%, CRF — 1-1.5%, ( multi-task learning,
Wu et al (2018) ). BiRNN — , , ,
.
, NER. , , .
,
NLP Advanced Research Group