Récemment, dans le groupe de reconnaissance ABBYY, nous utilisons de plus en plus les réseaux de neurones dans diverses tâches. Très bien, ils ont fait leurs preuves principalement pour les types d'écriture complexes. Dans des articles précédents, nous avons expliqué comment nous utilisons les réseaux de neurones pour reconnaître les scripts japonais, chinois et coréen.
 Publication sur la reconnaissance des caractères japonais et chinois Poste de reconnaissance de caractères coréens
Publication sur la reconnaissance des caractères japonais et chinois Poste de reconnaissance de caractères coréensDans les deux cas, nous avons utilisé des réseaux de neurones pour remplacer complètement la méthode de classification d'un seul symbole. Toutes les approches comprenaient de nombreux réseaux différents, et certaines des tâches comprenaient la nécessité de travailler correctement sur des images qui ne sont pas des symboles. Le modèle dans ces situations devrait en quelque sorte signaler que nous ne sommes pas un symbole. Aujourd'hui, nous allons simplement expliquer pourquoi cela peut être nécessaire en principe et les approches qui peuvent être utilisées pour obtenir l'effet souhaité.
La motivation
Quel est le problème? Pourquoi travailler sur des images qui ne sont pas des caractères séparés? Il semblerait que vous pouvez diviser un fragment d'une chaîne en caractères, les classer tous et en collecter le résultat, comme, par exemple, dans l'image ci-dessous.
Oui, spécifiquement dans ce cas, cela peut vraiment être fait. Mais, hélas, le monde réel est beaucoup plus compliqué, et dans la pratique, lors de la reconnaissance, vous devez faire face aux distorsions géométriques, au flou, aux taches de café et à d'autres difficultés.
En conséquence, vous devez souvent travailler avec de tels fragments:
Je pense qu'il est évident pour tout le monde quel est le problème. Selon une telle image d'un fragment, il n'est pas si simple de le diviser sans ambiguïté en symboles séparés afin de les reconnaître individuellement. Nous devons proposer un ensemble d'hypothèses sur la position des frontières entre les personnages et sur la position des personnages eux-mêmes. Pour cela, nous utilisons le soi-disant graphe de division linéaire (GLD). Dans l'image ci-dessus, ce graphique est affiché en bas: les segments verts sont les arcs du GLD construit, c'est-à-dire les hypothèses sur l'emplacement des symboles individuels.
Ainsi, certaines des images pour lesquelles le module de reconnaissance de caractères individuels est lancé ne sont en fait pas des caractères individuels, mais des erreurs de segmentation. Et ce même module devrait signaler que devant lui, très probablement, n'est pas un symbole, retournant une faible confiance pour toutes les options de reconnaissance. Et si cela ne se produit pas, à la fin, la mauvaise option pour segmenter ce fragment par symboles peut être choisie, ce qui augmentera considérablement le nombre d'erreurs de division linéaire.
En plus des erreurs de segmentation, le modèle doit également être résistant aux ordures a priori de la page. Par exemple, ici, de telles images peuvent également être envoyées pour reconnaître un seul caractère:
Si vous classez simplement ces images en caractères séparés, les résultats de la classification tomberont dans les résultats de la reconnaissance. De plus, en fait, ces images ne sont que des artefacts de l'algorithme de binarisation, rien ne devrait leur correspondre dans le résultat final. Donc, pour eux aussi, vous devez être en mesure de retourner une faible confiance dans le classement.
Toutes les images similaires: erreurs de segmentation, ordures a priori, etc. nous serons ci-après appelés exemples négatifs. Les images de symboles réels seront appelées exemples positifs.
Le problème de l'approche des réseaux de neurones
Rappelons maintenant comment un réseau neuronal normal fonctionne pour reconnaître des caractères individuels. Habituellement, il s'agit d'une sorte de couches convolutives et entièrement connectées, à l'aide desquelles le vecteur de probabilités d'appartenance à chaque classe particulière est formé à partir de l'image d'entrée.
De plus, le nombre de classes coïncide avec la taille de l'alphabet. Pendant la formation du réseau neuronal, des images de symboles réels sont servies et apprennent à renvoyer une forte probabilité pour la classe de symboles correcte.
Et que se passera-t-il si un réseau de neurones est alimenté par des erreurs de segmentation et des ordures a priori? En fait, purement théoriquement, tout peut arriver, car le réseau n'a pas du tout vu de telles images dans le processus d'apprentissage. Pour certaines images, cela peut être chanceux et le réseau renverra une faible probabilité pour toutes les classes. Mais dans certains cas, le réseau peut commencer à chercher parmi les ordures à l'entrée les contours familiers d'un certain symbole, par exemple le symbole «A» et le reconnaître avec une probabilité de 0,99.
Dans la pratique, lorsque nous avons travaillé, par exemple, sur un modèle de réseau neuronal pour l'écriture japonaise et chinoise, l'utilisation de la probabilité brute de la sortie du réseau a conduit à l'apparition d'un grand nombre d'erreurs de segmentation. Et, malgré le fait que le modèle symbolique fonctionnait très bien sur la base d'images, il n'a pas été possible de l'intégrer dans l'algorithme de reconnaissance complet.
Quelqu'un peut se demander: pourquoi exactement avec les réseaux de neurones un tel problème se pose-t-il? Pourquoi les classificateurs d'attributs n'ont-ils pas fonctionné de la même manière, car ils ont également étudié sur la base d'images, ce qui signifie qu'il n'y avait pas d'exemples négatifs dans le processus d'apprentissage?
La différence fondamentale, à mon avis, réside dans la façon dont les signes se distinguent exactement des images de symboles. Dans le cas du classificateur habituel, une personne elle-même prescrit comment les extraire, guidée par une certaine connaissance de leur appareil. Dans le cas d'un réseau de neurones, l'extraction de caractéristiques fait également partie intégrante du modèle: elles sont configurées de sorte qu'il est possible de distinguer au mieux les caractères de différentes classes. Et en pratique, il s'avère que les caractéristiques décrites par une personne sont plus résistantes aux images qui ne sont pas des symboles: elles sont moins susceptibles d'être les mêmes que des images de symboles réels, ce qui signifie qu'une valeur de confiance inférieure peut leur être retournée.
Amélioration de la stabilité du modèle avec perte centrale
Parce que le problème, selon nos soupçons, était de savoir comment le réseau neuronal sélectionne les signes, nous avons décidé d'essayer d'améliorer cette partie particulière, c'est-à-dire d'apprendre à mettre en évidence certains «bons» signes. Dans l'apprentissage en profondeur, il existe une section distincte consacrée à ce sujet, et elle est appelée «apprentissage par la représentation». Nous avons décidé d'essayer différentes approches réussies dans ce domaine. La plupart des solutions ont été proposées pour la formation des représentations aux problèmes de reconnaissance faciale.
L'approche décrite dans l'article «
Une approche d'apprentissage des fonctions discriminantes pour la reconnaissance des visages profonds » semblait assez bonne. L'idée principale des auteurs: ajouter un terme supplémentaire à la fonction de perte, ce qui réduira la distance euclidienne dans l'espace caractéristique entre les éléments de la même classe.
Pour différentes valeurs du poids de ce terme dans la fonction de perte générale, on peut obtenir différentes images dans les espaces attributaires:
Cette figure montre la distribution des éléments d'un échantillon de test dans un espace d'attributs à deux dimensions. Le problème de la classification des nombres manuscrits est considéré (exemple MNIST).
L'une des propriétés importantes qui a été déclarée par les auteurs: une augmentation de la capacité de généralisation des caractéristiques obtenues pour les personnes qui n'étaient pas dans l'ensemble de formation. Les visages de certaines personnes étaient toujours situés à proximité et les visages de différentes personnes étaient éloignés.
Nous avons décidé de vérifier si une propriété similaire pour la sélection des caractères était préservée. Dans ce cas, ils étaient guidés par la logique suivante: si dans l'espace d'entité tous les éléments d'une même classe sont regroupés de manière compacte près d'un point, alors les signes d'exemples négatifs seront moins susceptibles d'être situés près du même point. Par conséquent, comme critère principal de filtrage, nous avons utilisé la distance euclidienne au centre statistique d'une classe particulière.
Pour tester l'hypothèse, nous avons effectué l'expérience suivante: nous avons formé des modèles pour reconnaître un petit sous-ensemble de caractères japonais d'alphabets syllabiques (le soi-disant kana). En plus de l'échantillon de formation, nous avons également examiné 3 bases artificielles d'exemples négatifs:
- Paires - un ensemble de paires de caractères européens
- Coupes - des fragments de lignes japonaises coupées dans des espaces, pas des caractères
- Pas kana - autres caractères de l'alphabet japonais qui ne sont pas liés au sous-ensemble considéré
Nous voulions comparer l'approche classique avec la fonction de perte d'entropie croisée et l'approche avec la perte centrale dans leur capacité à filtrer les exemples négatifs. Les critères de filtrage des exemples négatifs étaient différents. Dans le cas de la perte entropique croisée, nous avons utilisé la réponse du réseau de la dernière couche, et dans le cas de la perte centrale, nous avons utilisé la distance euclidienne au centre statistique de la classe dans l'espace attributaire. Dans les deux cas, nous avons choisi le seuil des statistiques correspondantes, auquel pas plus de 3% des exemples positifs de l'échantillon test sont éliminés et nous avons examiné la proportion d'exemples négatifs de chaque base de données qui est éliminée à ce seuil.

Comme vous pouvez le voir, l'approche Center Loss fait vraiment mieux pour filtrer les exemples négatifs. De plus, dans les deux cas, nous n'avions pas d'images d'exemples négatifs dans le processus d'apprentissage. C'est en fait très bon, car dans le cas général, obtenir une base représentative de tous les exemples négatifs du problème OCR n'est pas une tâche facile.
Nous avons appliqué cette approche au problème de la reconnaissance des caractères japonais (au deuxième niveau d'un modèle à deux niveaux), et le résultat nous a plu: le nombre d'erreurs de division linéaire a été considérablement réduit. Bien que les erreurs subsistent, elles peuvent déjà être classées par types spécifiques: qu'il s'agisse d'une paire de chiffres ou de hiéroglyphes avec un symbole de ponctuation collé. Pour ces erreurs, il était déjà possible de former une base synthétique d'exemples négatifs et de l'utiliser dans le processus d'apprentissage. Comment cela peut être fait et sera discuté plus loin.
Utilisation de la base d'exemples négatifs dans la formation
Si vous avez une collection d'exemples négatifs, il est stupide de ne pas l'utiliser dans le processus d'apprentissage. Mais réfléchissons à comment cela peut être fait.
Tout d'abord, considérons le schéma le plus simple: nous regroupons tous les exemples négatifs dans une classe distincte et ajoutons un autre neurone à la couche de sortie correspondant à cette classe. Maintenant, à la sortie, nous avons une distribution de probabilité pour la classe
N + 1 . Et nous lui enseignons la perte d'entropie croisée habituelle.
Le critère selon lequel l'exemple est négatif peut être considéré comme la valeur de la nouvelle réponse de réseau correspondante. Mais parfois, de vrais personnages de très mauvaise qualité peuvent être classés comme exemples négatifs. Est-il possible de faciliter la transition entre les exemples positifs et négatifs?
En fait, vous pouvez essayer de ne pas augmenter le nombre total de sorties, mais simplement faire en sorte que le modèle, lors de l'apprentissage, renvoie des réponses faibles pour toutes les classes lors de l'application d'exemples négatifs à l'entrée. Pour ce faire, nous ne pouvons pas ajouter explicitement la sortie
N + 1er au modèle, mais simplement ajouter la valeur de
–max des réponses pour toutes les autres classes à l'élément
N + 1er . Ensuite, lors de l'application d'exemples négatifs à l'entrée, le réseau essaiera d'en faire autant que possible, ce qui signifie que la réponse maximale essaiera d'en faire le moins possible.
Exactement un tel schéma que nous avons appliqué au premier niveau d'un modèle à deux niveaux pour les Japonais en combinaison avec l'approche Center Loss au deuxième niveau. Ainsi, certains des exemples négatifs ont été filtrés au premier niveau, et certains au second. En combinaison, nous avons déjà réussi à obtenir une solution prête à être intégrée dans l'algorithme de reconnaissance générale.
En général, on peut aussi se demander: comment utiliser la base d'exemples négatifs dans l'approche avec Center Loss? Il s'avère que d'une manière ou d'une autre, nous devons reporter les exemples négatifs qui sont situés à proximité des centres statistiques des classes dans l'espace attributaire. Comment intégrer cette logique dans la fonction de perte?
Soit
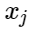
- des signes d'exemples négatifs, et
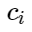
- centres de classes. Ensuite, nous pouvons considérer l'ajout suivant pour la fonction de perte:
Ici
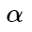
- un certain écart admissible entre le centre et les exemples négatifs, à l'intérieur duquel une pénalité est infligée aux exemples négatifs.
La combinaison de Center Loss avec l'additif décrit ci-dessus, nous avons réussi à appliquer, par exemple, pour certains classificateurs individuels dans le but de reconnaître les caractères coréens.
Conclusions
En général, toutes les approches de filtrage des soi-disant «exemples négatifs» décrits ci-dessus peuvent être appliquées à tous les problèmes de classification lorsque vous avez une classe implicitement très déséquilibrée par rapport au reste sans une bonne base de représentants, ce qui doit néanmoins être pris en compte d'une manière ou d'une autre . L'OCR n'est qu'une tâche particulière dans laquelle ce problème est le plus aigu.
Naturellement, tous ces problèmes ne se posent que lors de l'utilisation des réseaux de neurones comme modèle principal de reconnaissance des caractères individuels. Lorsque vous utilisez la reconnaissance de ligne de bout en bout en tant que modèle distinct, un tel problème ne se pose pas.
Groupe OCR New Technologies