Contexte
Au cours des deux dernières années, j'ai participé à un grand nombre d'entrevues. Pour chacun d'eux, j'ai interrogé les requérants sur le principe de la responsabilité exclusive (ci-après SRP). Et la plupart des gens ne savent rien du principe. Et même parmi ceux qui pouvaient lire la définition, presque personne ne pouvait dire comment ils utilisent ce principe dans leur travail. Ils ne pouvaient pas dire comment SRP affecte le code qu'ils écrivent ou l'examen du code de leurs collègues. Certains d'entre eux avaient également l'idée fausse que SRP, comme l'ensemble de SOLID, n'est pertinent que pour la programmation orientée objet. De plus, souvent, les gens ne pouvaient pas identifier les cas évidents de violation de ce principe, simplement parce que le code était écrit dans le style recommandé par le cadre bien connu.
Redux est un excellent exemple d'un cadre dont la directive viole SRP.
Questions de SRP
Je veux commencer par la valeur de ce principe, avec les avantages qu'il apporte. Et je tiens également à noter que le principe s'applique non seulement à la POO, mais aussi à la programmation procédurale, fonctionnelle et même déclarative. Le HTML, en tant que représentant de ce dernier, peut et doit également être décomposé, surtout maintenant lorsqu'il est contrôlé par des cadres d'interface utilisateur tels que React ou Angular. En outre, le principe s'applique à d'autres domaines d'ingénierie. Et non seulement l'ingénierie, il y avait une telle expression dans les sujets militaires: «diviser pour mieux régner», qui est dans l'ensemble l'incarnation du même principe. La complexité tue, divisez-la en parties et vous gagnerez.
En ce qui concerne les autres domaines d'ingénierie, ici sur le moyeu, il y avait un article intéressant sur la façon dont l'avion en cours de développement avait des moteurs en panne, n'est pas passé en marche arrière à la demande du pilote. Le problème était qu'ils avaient mal interprété l'état du châssis. Au lieu de s'appuyer sur les systèmes contrôlant le châssis, le contrôleur du moteur lit directement les capteurs, les interrupteurs de fin de course, etc. situés dans le châssis. Il a également été mentionné dans l'article que le moteur doit subir une longue certification avant même d'être installé sur un prototype d'avion. Et la violation de SRP dans ce cas a clairement conduit au fait que lors du changement de conception du châssis, le code dans le contrôleur du moteur devait être modifié et recertifié. Pire encore, une violation de ce principe valait presque l'avion et la vie du pilote. Heureusement, notre programmation quotidienne ne menace pas de telles conséquences, cependant, vous ne devez toujours pas négliger les principes d'écriture d'un bon code. Et voici pourquoi:
- La décomposition du code réduit sa complexité. Par exemple, si la solution au problème vous oblige à écrire du code avec une complexité cyclomatique de quatre, alors la méthode qui est responsable de résoudre deux de ces problèmes en même temps nécessitera du code avec la complexité 16. Si elle est divisée en deux méthodes, la complexité totale sera de 8. Bien sûr, ce n'est pas toujours revient au montant contre le travail, mais la tendance sera à peu près la même de toute façon.
- Le test unitaire du code décomposé est simplifié et plus efficace.
- Le code décomposé crée moins de résistance au changement. Lors de modifications, il est moins probable de commettre une erreur.
- Le code est de mieux en mieux structuré. La recherche de quelque chose dans le code organisé en fichiers et dossiers est beaucoup plus facile que dans un grand footcloth.
- La séparation du code passe-partout de la logique métier conduit au fait que la génération de code peut être appliquée dans un projet.
Et tous ces signes vont de pair, ce sont des signes du même code. Vous n'avez pas à choisir entre, par exemple, un code bien testé et un code bien structuré.
Les définitions existantes ne fonctionnent pas
L'une des définitions est: «il ne devrait y avoir qu'une seule raison de changer le code (classe ou fonction)». Le problème avec cette définition est qu'elle entre en conflit avec le principe Open-Close, le deuxième du groupe de principes SOLID. Sa définition: "le code doit être ouvert pour l'extension et fermé pour le changement." Une raison du changement par rapport à l'interdiction totale du changement. Si nous révélons plus en détail ce que l'on veut dire ici, il s'avère qu'il n'y a pas de conflit entre les principes, mais il y a certainement un conflit entre les définitions floues.
La deuxième définition, plus directe, est: "le code ne devrait avoir qu'une seule responsabilité". Le problème avec cette définition est que c'est la nature humaine de tout généraliser.
Par exemple, il y a une ferme qui élève des poulets, et à ce moment-là, la ferme n'a qu'une seule responsabilité. Et donc la décision est également prise d'élever des canards. Instinctivement, nous appellerons cela une ferme avicole, plutôt que d'admettre qu'il y a maintenant deux responsabilités. Ajoutez-y des moutons, et c'est maintenant une ferme pour animaux de compagnie. Ensuite, nous voulons y cultiver des tomates ou des champignons, et trouver le nom suivant encore plus généralisé. Il en va de même pour la «seule raison» du changement. Cette raison peut être aussi généralisée que l'imagination suffit.
Un autre exemple est la classe de gestionnaire de station spatiale. Il ne fait rien d'autre, il gère uniquement la station spatiale. Comment aimez-vous cette classe avec une responsabilité?
Et, puisque j'ai mentionné Redux lorsque le demandeur d'emploi connaît cette technologie, je pose également la question suivante: un réducteur SRP typique viole-t-il?
Le réducteur, je me souviens, comprend la déclaration switch, et il arrive qu'elle se développe à des dizaines voire des centaines de cas. Et la seule responsabilité du réducteur est de gérer les transitions d'état de votre application. C'est, littéralement, certains candidats ont répondu. Et aucun indice ne pouvait faire décoller cette opinion.
Au total, si une sorte de code semble satisfaire le principe SRP, mais en même temps ça sent désagréable - sachez pourquoi cela se produit. Parce que la définition du «code doit avoir une seule responsabilité» ne fonctionne tout simplement pas.
Définition plus appropriée
Par essais et erreurs, j'avais une meilleure définition:
La responsabilité du code ne devrait pas être trop grandeOui, vous devez maintenant «mesurer» la responsabilité d'une classe ou d'une fonction. Et si elle est trop grande, vous devez diviser cette grande responsabilité en plusieurs responsabilités plus petites. Pour revenir à l'exemple de la ferme, même la responsabilité d'élever des poulets peut être trop grande et il est logique de séparer en quelque sorte les poulets de chair des poules pondeuses, par exemple.
Mais comment le mesurer, comment déterminer que la responsabilité de ce code est trop grande?
Malheureusement, je n'ai pas de méthodes mathématiquement précises, seulement empiriques. Et surtout, cela vient avec l'expérience, les développeurs novices ne sont pas du tout capables de décomposer le code, les plus avancés sont mieux à le posséder, même s'ils ne peuvent pas toujours décrire pourquoi ils le font et comment cela tombe sur des théories comme SRP.
- Complexité cyclomatique métrique. Malheureusement, il existe des moyens de masquer cette métrique, mais si vous la collectez, il est possible qu'elle affiche les emplacements les plus vulnérables de votre application.
- La taille des fonctions et des classes. Une fonction de 800 lignes n'a pas besoin d'être lue pour comprendre que quelque chose ne va pas.
- Beaucoup d'importations. Une fois que j'ai ouvert un fichier dans le projet d'une équipe voisine et que j'ai vu tout un écran d'importations, j'ai appuyé sur la page et de nouveau il n'y avait que des importations à l'écran. Ce n'est qu'après la deuxième pression que j'ai vu le début du code. Vous pouvez dire que tous les IDE modernes peuvent masquer les importations sous le "signe plus", mais je dis qu'un bon code n'a pas besoin de cacher les "odeurs". De plus, j'avais besoin de réutiliser un petit morceau de code et je l'ai supprimé de ce fichier à un autre, et un quart ou même un tiers des importations se sont déplacés derrière ce morceau. Ce code n'y appartenait manifestement pas.
- Tests unitaires. Si vous avez encore du mal à déterminer le niveau de responsabilité, forcez-vous à passer des tests. Si vous devez écrire deux douzaines de tests sur le but principal d'une fonction, sans compter les cas limites, etc., alors la décomposition est nécessaire.
- Il en va de même pour trop d'étapes préparatoires au début du test et de contrôles à la fin. Sur Internet, en passant, vous pouvez trouver la déclaration utopique que le soi-disant Il ne devrait y avoir qu'une seule assertion dans le test. Je crois que toute bonne idée arbitraire, portée à l'absolu, peut devenir absurdement impossible.
- La logique métier ne doit pas dépendre directement d'outils externes. Le pilote Oracle, Express routes, il est souhaitable de séparer tout cela de la logique métier et / ou de se cacher derrière les interfaces.
Quelques points:
Bien sûr, comme je l'ai déjà mentionné, il y a un revers à la médaille, et 800 méthodes sur une ligne peuvent ne pas être meilleures qu'une méthode sur 800 lignes, il devrait y avoir un équilibre en tout.
La seconde - je ne couvre pas la question de savoir où mettre tel ou tel code en conformité avec sa responsabilité. Par exemple, les développeurs ont parfois des difficultés à tirer trop de logique dans la couche DAL.
Troisièmement, je ne propose aucune limite stricte spécifique comme «pas plus de 50 lignes par fonction». Cette approche implique uniquement une direction pour le développement des développeurs, et peut-être des équipes. Il travaille pour moi, il doit gagner de l'argent pour les autres.
Et enfin, si vous passez par TDD, cela seul vous fera sûrement décomposer le code bien avant d'écrire ces 20 tests avec 20 assertions chacun.
Séparation de la logique métier du code passe-partout
En parlant des règles d'un bon code, vous ne pouvez pas vous passer d'exemples. Le premier exemple concerne la séparation du code passe-partout.
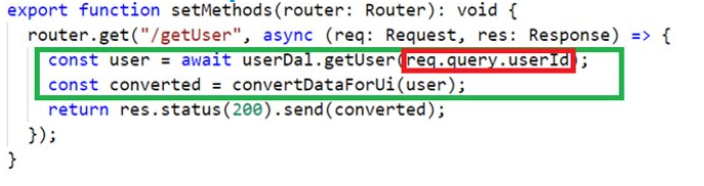
Cet exemple montre comment le code principal est généralement écrit. Les gens écrivent généralement une logique inextricablement avec le code indiquant les paramètres au serveur Web Express tels que l'URL, la méthode de demande, etc.
J'ai marqué la logique métier comme marqueur vert et le code entrecoupé de rouge qui interagit avec les paramètres de requête (rouge).
Je partage toujours ces deux responsabilités de cette façon:

Dans cet exemple, toutes les interactions avec Express se trouvent dans un fichier distinct.
À première vue, il pourrait sembler que le deuxième exemple n'a pas apporté d'améliorations, il y avait 2 fichiers au lieu d'un, des lignes supplémentaires sont apparues, qui n'existaient pas auparavant - le nom de la classe et la signature de la méthode. Et puis que donne cette séparation de code? Tout d'abord, le «point d'entrée de l'application» n'est plus Express. Il s'agit maintenant d'une fonction Typescript régulière. Ou une fonction javascript, que ce soit C #, qui écrit WebAPI sur quoi.
Ceci, à son tour, vous permet d'effectuer diverses actions qui ne sont pas disponibles dans le premier exemple. Par exemple, vous pouvez écrire des tests de comportement sans avoir à lancer Express, sans utiliser de requêtes http dans le test. Et même s'il n'y a pas besoin de mouiller, remplacez l'objet Router par votre objet «test», maintenant le code d'application peut simplement être appelé directement depuis le test.
Une autre fonctionnalité intéressante fournie par cette décomposition est que vous pouvez maintenant écrire un générateur de code qui analysera userApiService et l'utilisera pour générer du code qui connecte ce service à Express. Dans mes futures publications, je prévois d'indiquer ce qui suit: la génération de code ne fera pas gagner de temps dans le processus d'écriture de code. Les coûts du générateur de code ne seront pas rentables du fait que vous n'avez plus besoin de copier ce passe-partout. La génération de code sera payante par le fait que le code qu'elle produit n'a pas besoin de support, ce qui fera gagner du temps et, surtout, les nerfs des développeurs à long terme.
Diviser et conquérir
Cette méthode d'écriture de code existe depuis longtemps, je ne l'ai pas inventée moi-même. Je viens juste de conclure qu'il est très pratique lors de l'écriture de la logique métier. Et pour cela, j'ai trouvé un autre exemple fictif, montrant comment vous pouvez rapidement et facilement écrire du code qui est immédiatement bien décomposé et également auto-documenté par des méthodes de nommage.
Supposons qu'un analyste d'entreprise vous demande de créer une méthode qui envoie un rapport d'employé à une compagnie d'assurance. Pour ce faire:
- Les données doivent être extraites de la base de données
- Convertir au format souhaité
- Envoyer le rapport résultant
De telles exigences ne sont pas toujours écrites explicitement, parfois une telle séquence peut être implicite ou clarifiée lors d'une conversation avec l'analyste. Dans le processus de mise en œuvre de la méthode, ne vous précipitez pas pour ouvrir des connexions à la base de données ou au réseau, essayez plutôt de traduire cet algorithme simple dans le code "tel quel". Quelque chose comme ça:
async function sendEmployeeReportToProvider(reportId){ const data = await dal.getEmployeeReportData(reportId); const formatted = reportDataService.prepareEmployeeReport(data); await networkService.sendReport(formatted); }
Avec cette approche, il s'avère être un code assez simple, facile à lire et à tester, même si je pense que ce code est trivial et n'a pas besoin d'être testé. Et il était de la responsabilité de cette méthode de ne pas envoyer de rapport, sa responsabilité était de diviser cette tâche complexe en trois sous-tâches.
Ensuite, nous revenons aux exigences et découvrons que le rapport doit comprendre une section sur les salaires et une section sur les heures travaillées.
function prepareEmployeeReport(reportData){ const salarySection = prepareSalarySection(reportData); const workHoursSection = prepareWorkHoursSection(reportData); return { salarySection, workHoursSection }; }
Et ainsi de suite, nous continuons à diviser la tâche jusqu'à ce que la mise en œuvre de petites méthodes qui sont presque triviales reste.
Interaction avec le principe d'ouverture-fermeture
Au début de l'article, j'ai dit que les définitions des principes de SRP et d'Open-Close se contredisent. Le premier dit qu'il doit y avoir une raison pour le changement, le second dit que le code doit être fermé pour le changement. Et les principes eux-mêmes, non seulement ne se contredisent pas, au contraire, ils travaillent en synergie les uns avec les autres. Les 5 principes SOLID visent un seul bon objectif - dire au développeur quel code est «mauvais» et comment le changer pour qu'il devienne «bon». L'ironie - je viens de remplacer 5 responsabilités par une autre responsabilité.
Donc, en plus de l'exemple précédent avec l'envoi du rapport à la compagnie d'assurance, imaginez qu'un analyste d'entreprise vient à nous et nous dit que nous devons maintenant ajouter une deuxième fonctionnalité au projet. Le même rapport doit être imprimé.
Imaginez qu'il y ait un développeur qui pense que SRP "ne concerne pas la décomposition".
En conséquence, ce principe ne lui indiquait pas la nécessité d'une décomposition, et il réalisa toute la première tâche en une seule fonction. Après que la tâche lui soit venue, il combine les deux responsabilités en une seule, car ils ont beaucoup en commun et généralise son nom. Maintenant, cette responsabilité est appelée «rapport de service». L'implémentation de ceci ressemble à ceci:
async function serveEmployeeReportToProvider(reportId, serveMethod){ switch(serveMethod) { case sendToProvider: case print: default: throw; } }
Rappelle du code dans votre projet? Comme je l'ai dit, les deux définitions directes du SRP ne fonctionnent pas. Ils ne transmettent pas au développeur des informations selon lesquelles un tel code ne peut pas être écrit. Et quel code peut être écrit. Il n'y avait qu'une seule raison pour que le développeur modifie ce code. Il a simplement rappelé la raison précédente, a ajouté l'interrupteur et est calme. Et ici, le principe du principe Open-Close entre en scène, qui dit directement qu'il était impossible de modifier un fichier existant. Il était nécessaire d'écrire du code de sorte que lors de l'ajout de nouvelles fonctionnalités, il était nécessaire d'ajouter un nouveau fichier et non d'en modifier un existant. Autrement dit, un tel code est mauvais du point de vue de deux principes à la fois. Et si le premier n'a pas aidé à le voir, le second devrait aider.
Et comment la méthode diviser pour régner résout-elle le même problème:
async function printEmployeeReport(reportId){ const data = await dal.getEmployeeReportData(reportId); const formatted = reportDataService.prepareEmployeeReport(data); await printService.printReport(formatted); }
Ajoutez une nouvelle fonction. Je les appelle parfois une «fonction de script» car ils ne portent pas d'implémentations, ils déterminent la séquence d'appel des éléments décomposés de notre responsabilité. Évidemment, les deux premières lignes, les deux premières responsabilités décomposées coïncident avec les deux premières lignes de la fonction précédemment mise en œuvre. Tout comme les deux premières étapes de deux tâches décrites par un analyste d'entreprise coïncident.
Ainsi, pour ajouter de nouvelles fonctionnalités au projet, nous avons ajouté une nouvelle méthode de script et un nouveau printService. Les anciens fichiers n'ont pas été modifiés. Autrement dit, cette méthode d'écriture de code est bonne du point de vue de deux principes. Et SRP et Open-Close
Alternative
Je voulais également mentionner une manière alternative et concurrente d'obtenir un code bien décomposé qui ressemble à ceci - nous écrivons d'abord le code «sur le front», puis le remodelons en utilisant diverses techniques, par exemple, selon le livre de Fowler «Refactoring». Ces méthodes m'ont rappelé l'approche mathématique du jeu d'échecs, où vous ne comprenez pas exactement ce que vous faites en termes de stratégie, vous calculez uniquement le "poids" de votre position et essayez de le maximiser en faisant des mouvements. Je n'ai pas aimé cette approche pour une petite raison - nommer des méthodes et des variables est déjà difficile, et quand elles n'ont pas de valeur commerciale, cela devient impossible. Par exemple, si ces techniques suggèrent que vous devez sélectionner 6 lignes identiques d'ici et de là, puis les mettre en surbrillance, comment devez-vous appeler cette méthode? someSixIdenticalLines ()?
Je veux faire une réservation - je ne pense pas que cette méthode soit mauvaise, je n'ai tout simplement pas pu apprendre à l'utiliser.
Total
En suivant le principe, vous pouvez trouver des avantages.
La définition de «il doit y avoir une seule responsabilité» ne fonctionne pas.
Il existe une meilleure définition et un certain nombre de caractéristiques indirectes, le code sent la nécessité de se décomposer.
L'approche «diviser pour mieux régner» vous permet d'écrire immédiatement du code bien structuré et auto-documenté.