Je vous suggère de vous familiariser avec la transcription du rapport d'Alexander Sigachev d'Inventos "Le processus de développement et de test avec Docker + Gitlab CI"
Ceux qui commencent tout juste à mettre en œuvre le processus de développement et de test basé sur Docker + Gitlab CI posent souvent des questions de base. Par où commencer? Comment s'organiser? Comment tester?
Ce rapport est utile pour vous expliquer de manière structurée le processus de développement et de test à l'aide de Docker et Gitlab CI. Rapport 2017 lui-même. Je pense que ce rapport vous permet de tirer les bases, la méthodologie, l'idée, l'expérience d'utilisation.
Peu importe, s'il vous plaît, sous le chat.
Je m'appelle Alexander Sigachev. Je travaille pour Inventos. Je vais vous parler de mon expérience d'utilisation de Docker et de la façon dont nous l'implémentons progressivement sur des projets dans l'entreprise.
Sujet: Processus de développement utilisant Docker et Gitlab CI.
Ceci est mon deuxième discours sur Docker. Au moment du premier rapport, nous utilisions Docker uniquement en développement sur des machines de développement. Le nombre d'employés qui ont utilisé Docker était d'environ 2-3 personnes. Peu à peu, l'expérience a été acquise et nous sommes allés un peu plus loin. Lien vers notre premier rapport .
Que contiendra ce rapport? Nous partagerons notre expérience sur le râteau que nous avons collecté, les problèmes que nous avons résolus. Pas partout, c'était beau, mais autorisé à avancer.
Notre devise est: docker tout ce que nos mains atteignent.
Quels problèmes résolvons-nous?
Lorsqu'une entreprise a plusieurs équipes, le programmeur est une ressource partagée. Il y a des étapes où un programmeur est retiré d'un projet et donné pendant un certain temps à un autre projet.
Pour que le programmeur puisse s'y plonger rapidement, il doit télécharger le code source du projet et lancer l'environnement dès que possible, ce qui lui permettra d'avancer davantage dans la résolution des problèmes de ce projet.
Habituellement, si vous partez de zéro, la documentation du projet n'est pas suffisante. Seuls les anciens ont des informations sur la configuration. Les employés installent de manière indépendante leur lieu de travail en un à deux jours. Pour accélérer cela, nous avons utilisé Docker.
La raison suivante est la standardisation des paramètres dans le développement. D'après mon expérience, les développeurs prennent toujours l'initiative. Dans tous les cinq cas, un domaine personnalisé est entré, par exemple, vasya.dev. A proximité se trouve le voisin Petya, dont le domaine est petya.dev. Ils développent un site Web ou un composant du système en utilisant ce nom de domaine.
Lorsque le système se développe et que ces noms de domaine commencent à tomber dans la configuration, il y a alors un conflit d'environnements de développement et le chemin du site est réécrit.
La même chose se produit avec les paramètres de la base de données. Quelqu'un ne se soucie pas de la sécurité et travaille avec un mot de passe root vide. Quelqu'un au stade de l'installation MySQL a demandé un mot de passe et le mot de passe s'est avéré être un 123. Il arrive souvent que la configuration de la base de données change constamment en fonction de la validation du développeur. Quelqu'un a corrigé, quelqu'un n'a pas corrigé la configuration. Il y avait des astuces lorsque nous avons mis en place une sorte de configuration de test dans .gitignore et chaque développeur a dû installer une base de données. Cela a compliqué le processus de démarrage. Entre autres choses, vous devez vous souvenir de la base de données. La base de données doit être initialisée, un mot de passe doit être enregistré, un utilisateur doit être enregistré, une plaque doit être créée, etc.
Un autre problème est les différentes versions des bibliothèques. Il arrive souvent qu'un développeur travaille avec différents projets. Il y a un projet Legacy qui a commencé il y a cinq ans (à partir de 2017 - note. Ed.). Au début, nous avons commencé avec MySQL 5.5. Il y a aussi des projets modernes où nous essayons d'introduire des versions plus modernes de MySQL, par exemple 5.7 ou plus (en 2017 - note. Ed.)
Quiconque travaille avec MySQL sait que ces bibliothèques tirent des dépendances. Il est assez problématique de faire fonctionner 2 bases ensemble. À tout le moins, il est difficile pour les anciens clients de se connecter à la nouvelle base de données. Cela entraîne à son tour plusieurs problèmes.
Le problème suivant est lorsque le développeur travaille sur la machine locale, il utilise des ressources locales, des fichiers locaux, de la RAM locale. Toute l'interaction lors de l'élaboration de la solution au problème est réalisée dans le cadre du fait qu'elle fonctionne sur une seule machine. Un exemple est lorsque nous avons des serveurs principaux dans Production 3, et que le développeur enregistre les fichiers dans le répertoire racine et à partir de là, nginx prend les fichiers pour répondre à la demande. Lorsqu'un tel code tombe en production, il s'avère que le fichier est présent sur l'un des 3 serveurs.
Maintenant, la direction des microservices se développe. Lorsque nous divisons nos grandes applications en quelques petits composants qui interagissent les uns avec les autres. Cela vous permet de sélectionner la technologie pour une pile de tâches spécifique. Il vous permet également de partager le travail et le domaine de responsabilité entre les développeurs.
Frondend-developer, développant sur JS, n'affecte pratiquement pas Backend. Le développeur backend, à son tour, développe, dans notre cas, Ruby on Rails et n'interfère pas avec Frondend. L'interaction est effectuée à l'aide de l'API.
En prime, avec Docker, nous avons pu utiliser les ressources de Staging. Chaque projet, en raison de sa spécificité, nécessitait certains réglages. Physiquement, il était nécessaire de sélectionner un serveur virtuel et de les configurer séparément, ou de partager une sorte d'environnement variable, et les projets pouvaient s'influencer les uns les autres selon la version des bibliothèques.

Des outils Qu'utilisons-nous?
- Directement Docker lui-même. Dockerfile décrit les dépendances d'une application.
- Docker-compose est un bundle qui regroupe quelques-unes de nos applications Docker.
- GitLab que nous utilisons pour stocker le code source.
- Nous utilisons GitLab-CI pour l'intégration du système.

Le rapport comprend deux parties.
La première partie expliquera comment exécuter Docker sur des machines de développement.
La deuxième partie expliquera comment interagir avec GitLab, comment nous exécutons les tests et comment nous déployons sur Staging.
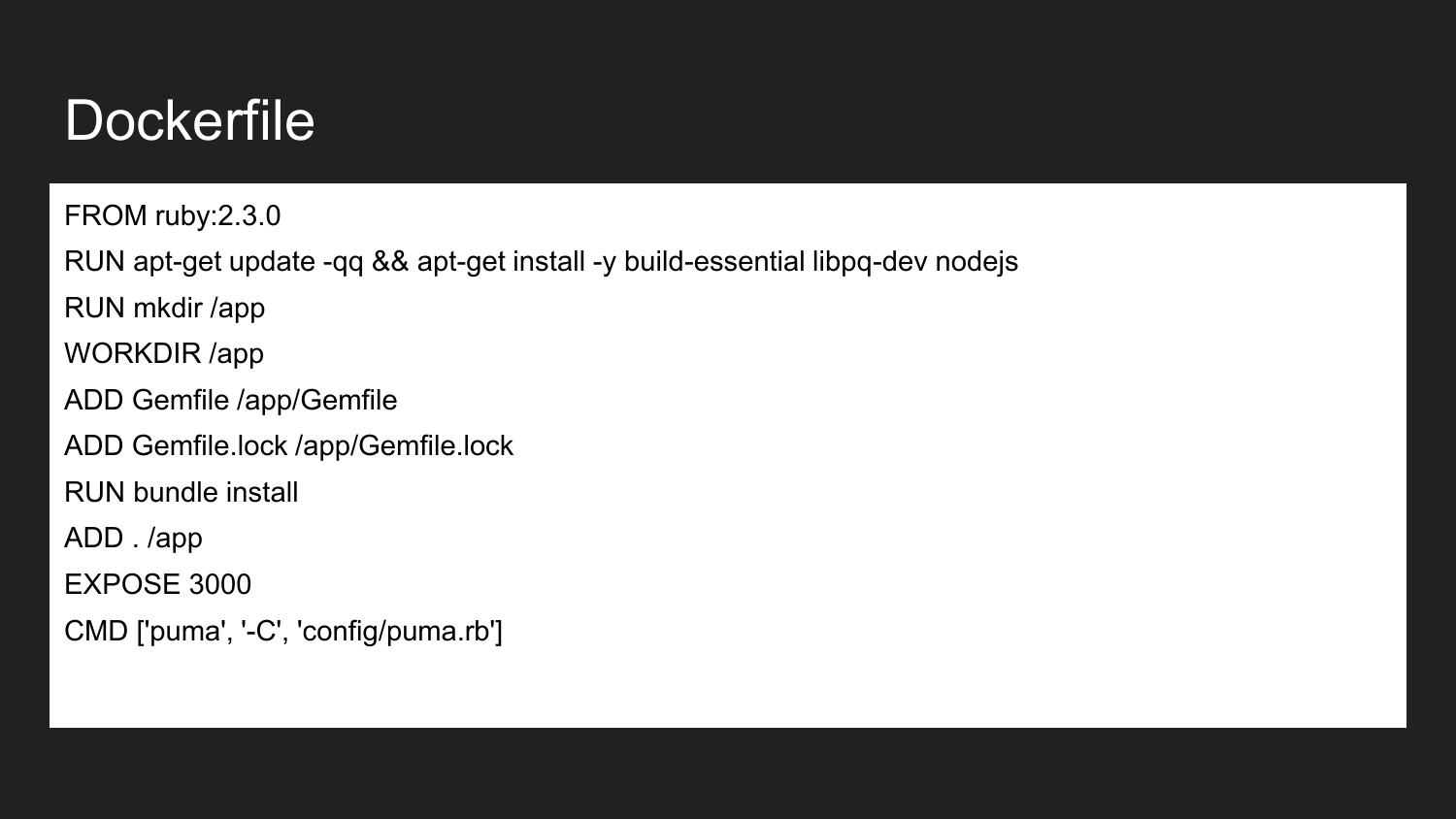
Docker est une technologie qui permet (en utilisant une approche déclarative) de décrire les composants nécessaires. Ceci est un exemple de Dockerfile. Ici, nous annonçons que nous héritons de l'image officielle de Ruby Docker: 2.3.0. Il contient la version 2.3 de Ruby installée. Nous installons les bibliothèques de build nécessaires et NodeJS. Nous décrivons que nous créons le répertoire /app . Attribuez le répertoire de l'application au répertoire de travail. Dans ce répertoire, nous plaçons le minimum requis Gemfile et Gemfile.lock. Ensuite, nous construisons les projets qui installent cette image de dépendance. Nous indiquons que le conteneur sera prêt à écouter sur le port externe 3000. La dernière commande est la commande qui lance directement notre application. Si nous exécutons la commande de démarrage du projet, l'application essaiera d'exécuter et de lancer la commande spécifiée.

Il s'agit d'un exemple minimal d'un fichier de composition de docker. Dans ce cas, nous montrons qu'il existe une connexion entre les deux conteneurs. Il s'agit directement du service de base de données et du service Web. Dans la plupart des cas, nos applications Web nécessitent une sorte de base de données comme backend pour le stockage des données. Puisque nous utilisons MySQL, l'exemple est avec MySQL - mais rien ne nous empêche d'utiliser une sorte de base de données d'amis (PostgreSQL, Redis).
Nous prenons l'image MySQL 5.7.14 de la source officielle avec le hub Docker inchangé. L'image responsable de notre application Web que nous collectons à partir du répertoire actuel. Il, lors du premier lancement, recueille une image pour nous. Ensuite, il lance la commande que nous exécutons ici. Si nous revenons en arrière, nous verrons que la commande de lancement via Puma a été définie. Puma est un service écrit en Ruby. Dans le deuxième cas, nous redéfinissons. Cette commande peut être arbitraire selon nos besoins ou nos tâches.
Nous décrivons également ce dont vous avez besoin pour transférer le port sur notre machine hôte à partir d'un conteneur de 3000 à 3000 ports. Cela se fait automatiquement en utilisant iptables et son propre mécanisme, qui est directement intégré à Docker.
Le développeur peut, comme précédemment, appliquer à toute adresse IP disponible, par exemple, 127.0.0.1 adresse IP locale ou externe de la machine.
La dernière ligne indique que le conteneur Web dépend du conteneur db. Lorsque nous appelons le lancement du conteneur Web, docker-compose démarre la base de données pour nous. Déjà au début de la base de données (en fait, après le démarrage du conteneur! Cela ne garantit pas la disponibilité de la base de données), nous lancerons une application, notre backend.
Cela vous permet d'éviter les erreurs lorsque la base de données n'est pas augmentée et vous permet d'économiser des ressources lorsque nous arrêtons le conteneur de base de données, libérant les ressources pour d'autres projets.

Ce qui nous donne l'utilisation de la base de données de dockerization sur le projet. Nous, tous les développeurs, corrigeons la version de MySQL. Cela vous permet d'éviter certaines erreurs qui peuvent se produire en cas de divergence de versions, lorsque la syntaxe, la configuration et les paramètres par défaut changent. Cela vous permet de spécifier un nom d'hôte commun pour la base de données, l'identifiant, le mot de passe. Nous nous éloignons des noms de zoo et des conflits dans les fichiers de configuration précédents.
Nous pouvons utiliser une configuration plus optimale pour l'environnement de développement, qui sera différente de la configuration par défaut. MySQL est configuré par défaut sur les machines faibles et ses performances prêtes à l'emploi sont très faibles.

Docker vous permet d'utiliser l'interpréteur Python, Ruby, NodeJS, PHP de la version souhaitée. Nous nous débarrassons de la nécessité d'utiliser une sorte de gestionnaire de versions. Auparavant, Ruby utilisait le package rpm, ce qui permettait de changer la version en fonction du projet. Cela permet également au conteneur Docker de migrer en douceur le code et de le versionner avec les dépendances. Nous n'avons aucun problème à comprendre la version de l'interpréteur et du code. Pour mettre à niveau la version, abaissez l'ancien conteneur et soulevez le nouveau conteneur. En cas de problème, nous pouvons abaisser le nouveau conteneur, soulever l'ancien conteneur.
Après avoir assemblé l'image, les conteneurs en développement et en production seront les mêmes. Cela est particulièrement vrai pour les grandes installations.
 Chez Frontend, nous utilisons JavaScipt et NodeJS.
Chez Frontend, nous utilisons JavaScipt et NodeJS.
Nous avons maintenant le dernier projet chez ReacJS. Le développeur a exécuté l'intégralité du conteneur et développé à l'aide du rechargement à chaud.
Ensuite, la tâche d'assemblage de JavaScipt est lancée et le code collecté dans la statique est fourni via les ressources d'économie nginx.
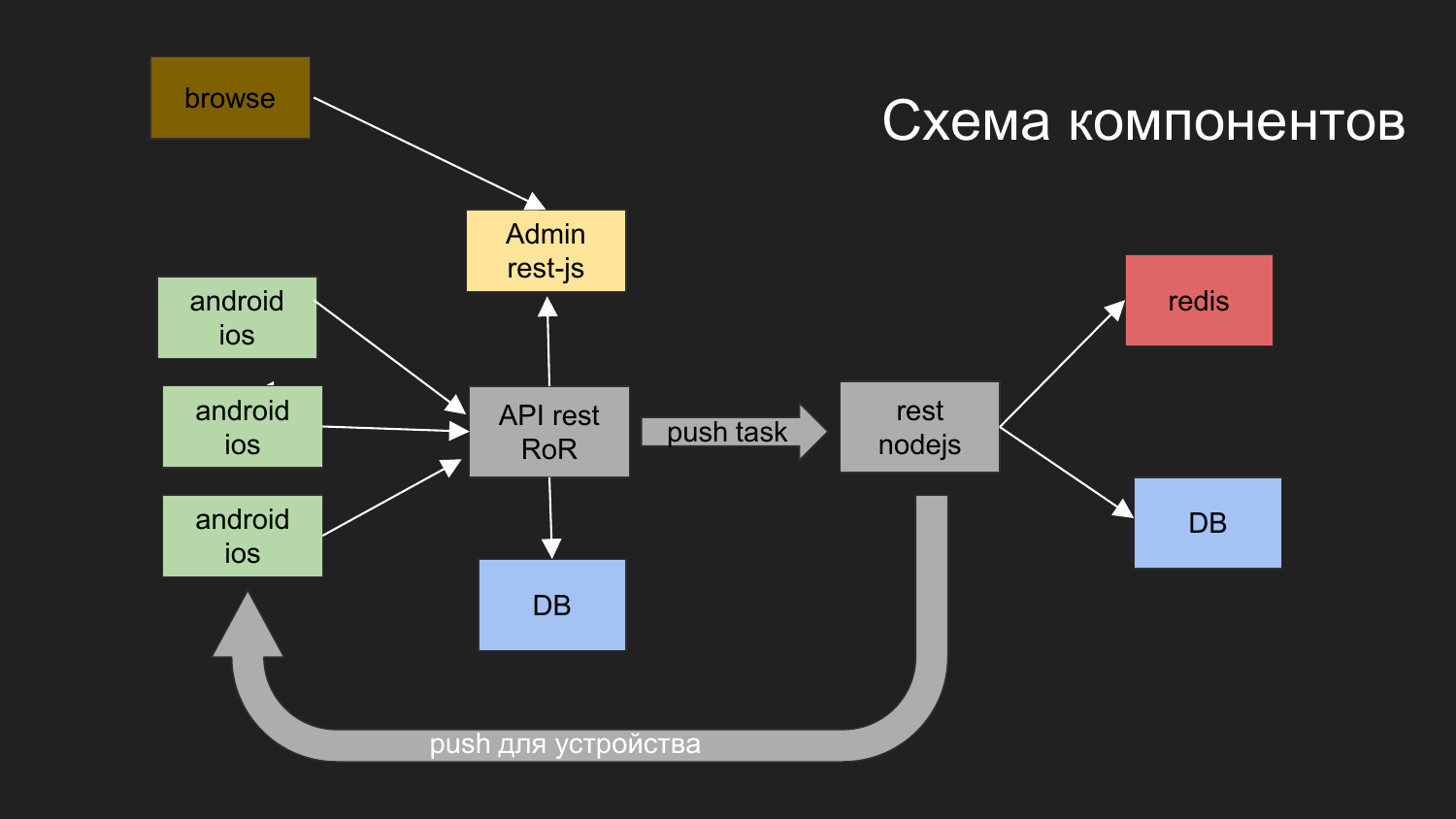
Ici, j'ai donné un diagramme de notre dernier projet.
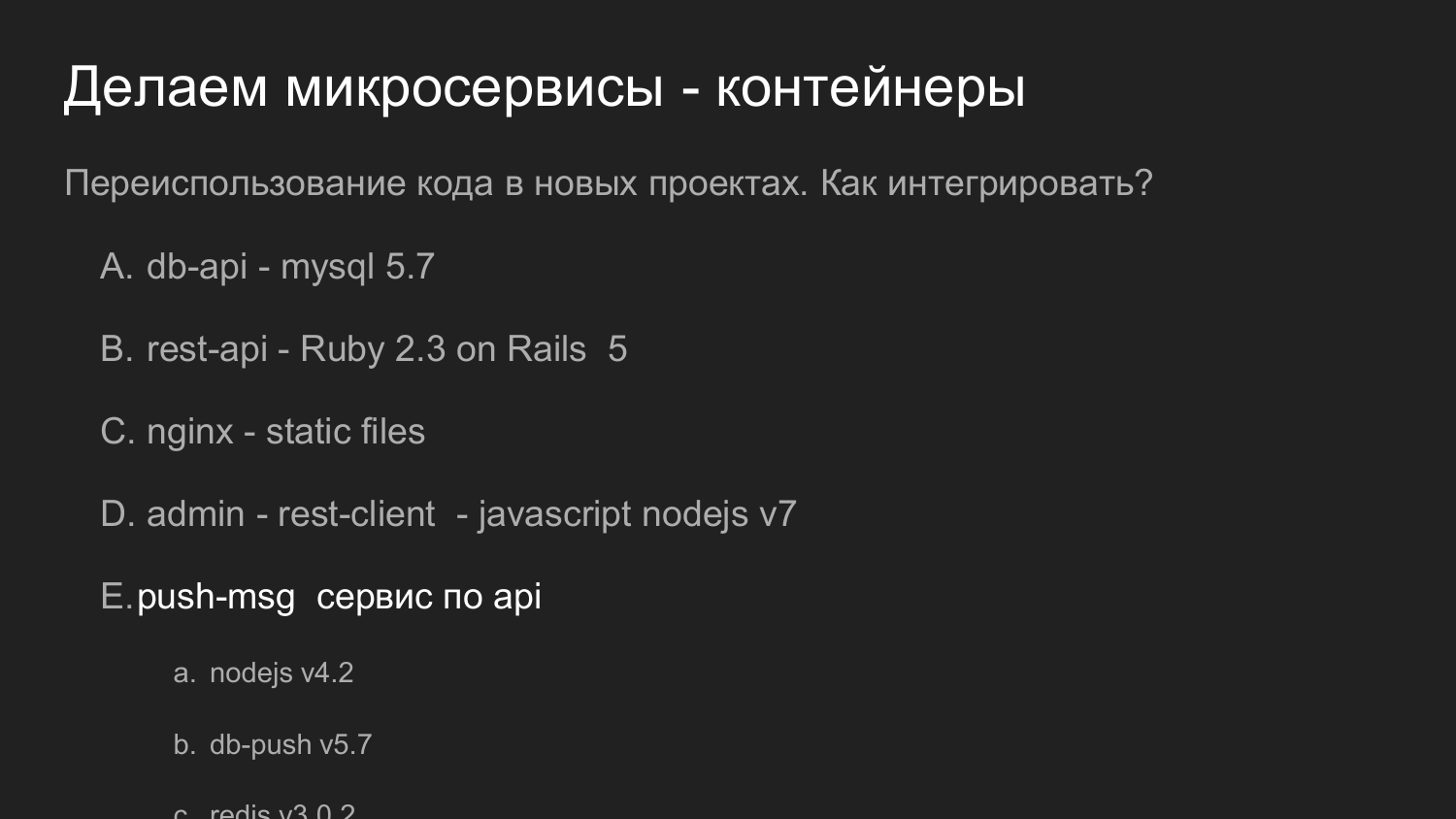
Quelles tâches avez-vous résolues? Nous avons besoin de construire un système avec lequel les appareils mobiles interagissent. Ils obtiennent des données. L'une des options consiste à envoyer des notifications push à cet appareil.
Qu'avons-nous fait pour cela?
Nous nous sommes divisés en composants d'application tels que: la partie admin dans JS, le backend, qui fonctionne via l'interface REST sous Ruby on Rails. Le backend interagit avec la base de données. Le résultat généré est donné au client. L'administrateur avec le backend et la base de données interagit via l'interface REST.
Nous devions également envoyer des notifications push. Avant cela, nous avions un projet dans lequel un mécanisme a été mis en œuvre qui est chargé de fournir des notifications aux plates-formes mobiles.
Nous avons développé un tel schéma: l'opérateur du navigateur interagit avec le panneau d'administration, le panneau d'administration interagit avec le backend, la tâche est d'envoyer des notifications Push.
Les notifications push interagissent avec un autre composant implémenté sur NodeJS.
Des files d'attente sont en cours de création, puis l'envoi de notifications suit son propre mécanisme.
Deux bases de données sont dessinées ici. Pour le moment, avec l'aide de Docker, nous utilisons 2 bases de données indépendantes, qui ne sont en aucun cas connectées entre elles. De plus, ils ont un réseau virtuel commun et les données physiques sont stockées dans différents répertoires sur la machine du développeur.
La même chose, mais en chiffres. La réutilisation du code est importante ici.
Si plus tôt nous avons parlé de réutiliser du code sous forme de bibliothèques, dans cet exemple notre service, qui répond aux notifications push, est réutilisé comme un serveur complet. Il fournit une API. Et déjà avec notre nouveau développement interagit avec lui.
À cette époque, nous utilisions la version 4 de NodeJS. Maintenant (en 2017 - note. Ed.) Dans les développements récents, nous utilisons la version 7 de NodeJS. Aucun problème dans les nouveaux composants pour attirer de nouvelles versions de bibliothèques.
Si nécessaire, vous pouvez refactoriser et mettre à niveau la version NodeJS du service de notification Push.
Et si nous pouvons maintenir la compatibilité des API, nous pouvons la remplacer par d'autres projets qui ont été utilisés précédemment.

De quoi avez-vous besoin pour ajouter Docker? Ajoutez un Dockerfile à notre référentiel qui décrit les dépendances nécessaires. Dans cet exemple, les composants sont ventilés par logique. Il s'agit d'un ensemble minimal de développeurs backend.
Lors de la création d'un nouveau projet, créez un Dockerfile, décrivez l'écosystème souhaité (Python, Ruby, NodeJS). Le docker-compose décrit la dépendance nécessaire - la base de données. Nous décrivons que nous avons besoin d'une base de données de telle ou telle version, pour y stocker les données quelque part.
Nous utilisons un troisième conteneur séparé avec nginx pour rendre statique. Vous pouvez télécharger des photos. Le backend les place dans un volume pré-préparé, qui est également monté dans un conteneur avec nginx, qui donne de l'électricité statique.
Pour stocker la configuration nginx, mysql, nous avons ajouté le dossier Docker, dans lequel nous stockons les configurations nécessaires. Lorsqu'un développeur crée un référentiel git clone sur sa machine, il prépare déjà un projet pour le développement local. La question ne se pose pas quel port ou quels paramètres appliquer.

De plus, nous avons plusieurs composants: admin, inform-API, push-notifications.
Afin de tout exécuter, nous avons créé un autre référentiel appelé dockerized-app. Actuellement, nous utilisons plusieurs référentiels jusqu'à chaque composant. Ils diffèrent simplement logiquement - dans GitLab, cela ressemble à un dossier, et sur la machine du développeur, un dossier pour un projet spécifique. Un niveau ci-dessous sont les composants qui seront combinés.
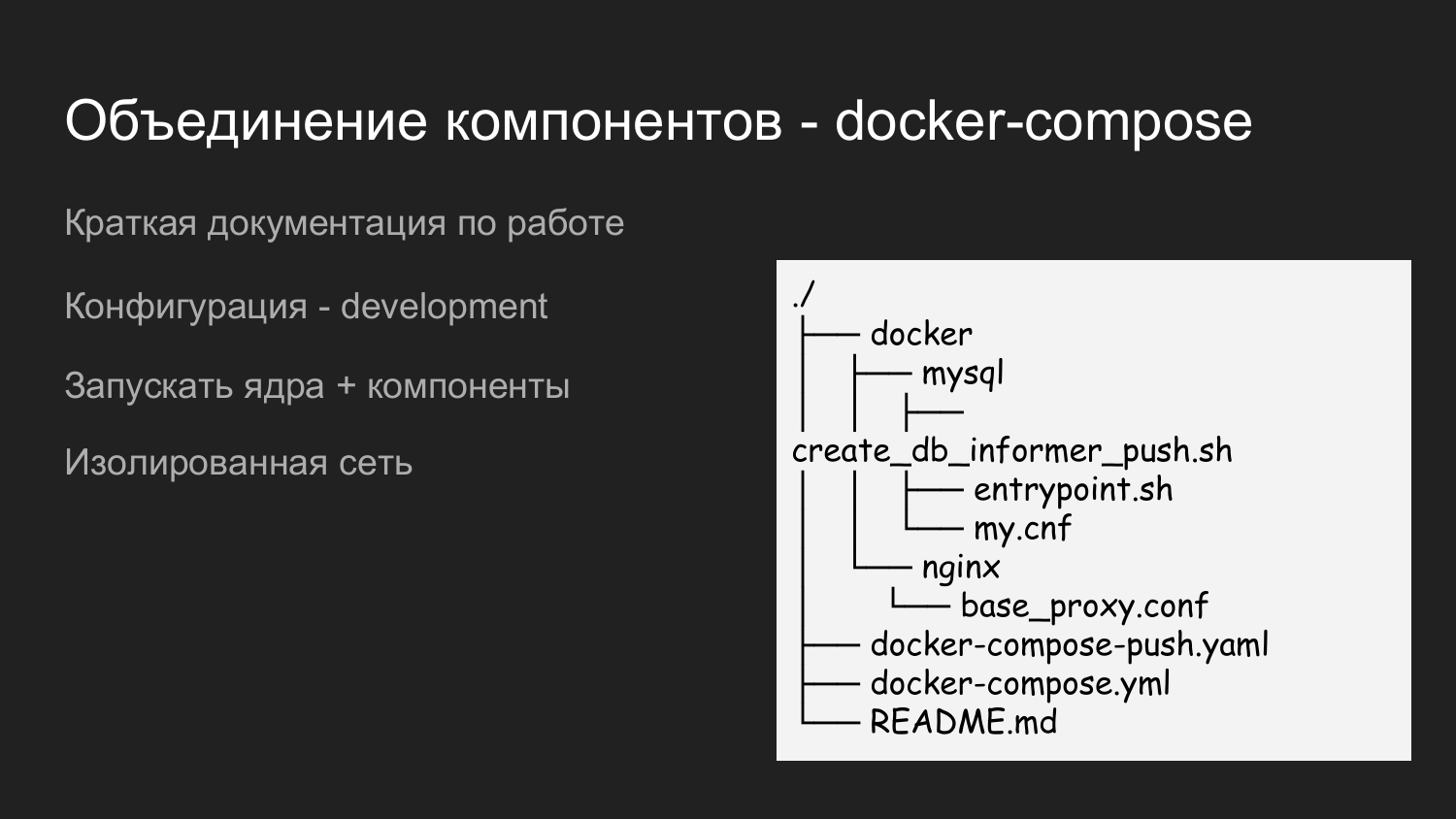
Ceci est un exemple du contenu de l'application dockerized. Nous apportons également le catalogue Docker ici, dans lequel nous remplissons les configurations requises pour les interactions de tous les composants. Il y a README.md, qui décrit brièvement comment démarrer un projet.
Ici, nous avons utilisé deux fichiers de composition de docker. Cela se fait afin de pouvoir s'exécuter par étapes. Lorsqu'un développeur travaille avec le noyau, il n'a pas besoin de notifications Push, puis il lance simplement le fichier docker-compose et, en conséquence, la ressource est enregistrée.
S'il y a un besoin d'intégration avec les notifications push, alors docker-compose.yaml et docker-compose-push.yaml sont lancés.
Étant donné que docker-compose.yaml et docker-compose-push.yaml se trouvent dans le dossier, un seul réseau virtuel est automatiquement créé.
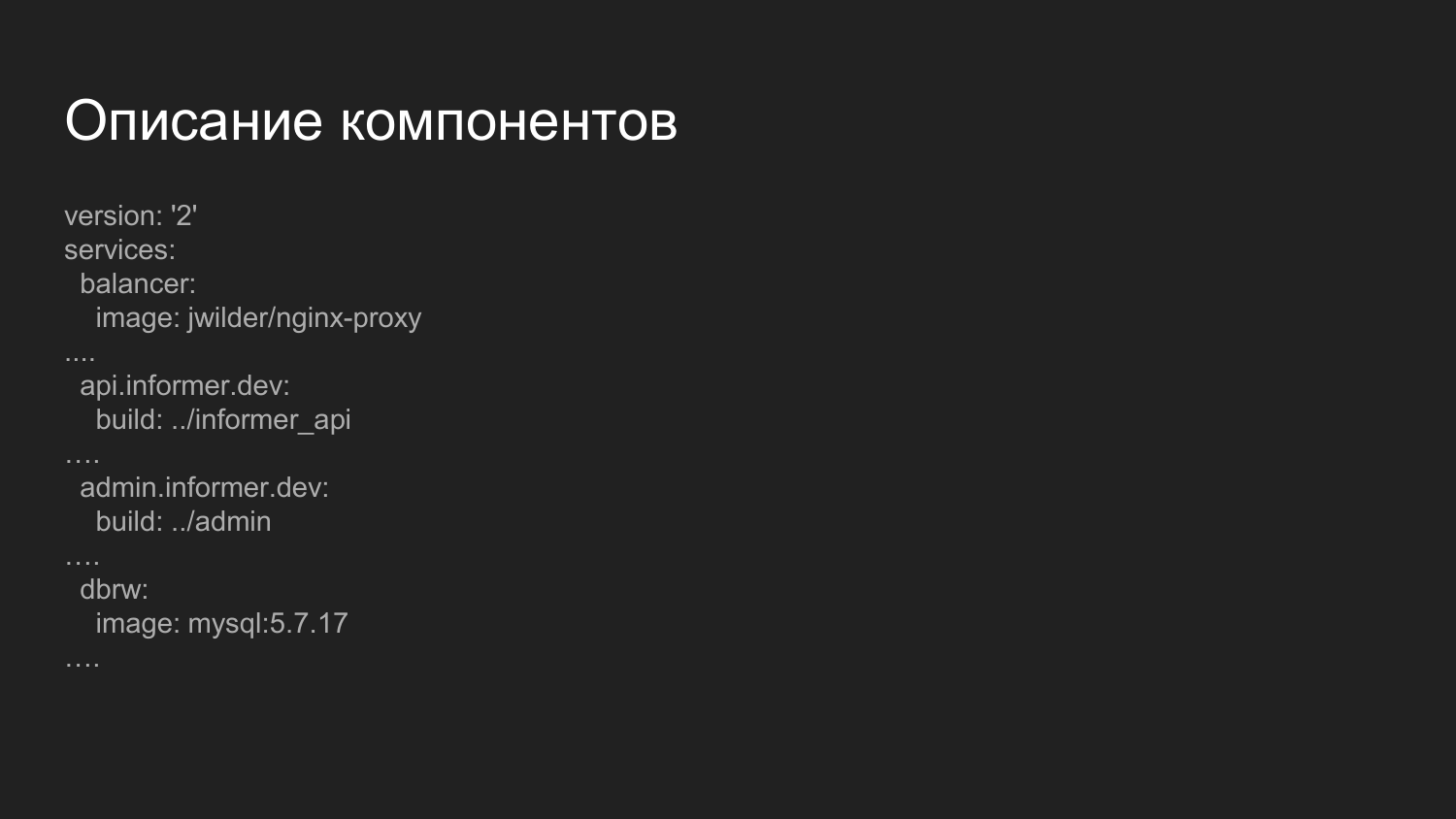
Description des composants. Il s'agit d'un fichier plus avancé chargé de collecter les composants. Qu'est-ce qui est remarquable ici? Nous présentons ici le composant d'équilibrage.
Il s'agit d'une image Docker prête à l'emploi dans laquelle nginx est lancé et d'une application qui écoute le socket Docker. Dynamique, lorsque les conteneurs s'allument et s'éteignent, la configuration nginx se régénère. Nous distribuons la gestion des composants par des noms de domaine de troisième niveau.
Pour l'environnement de développement, nous utilisons le domaine .dev - api.informer.dev. Les applications avec le domaine .dev sont disponibles sur la machine du développeur local.
Ensuite, les configurations sont transférées à chaque projet et tous les projets sont lancés ensemble en même temps.
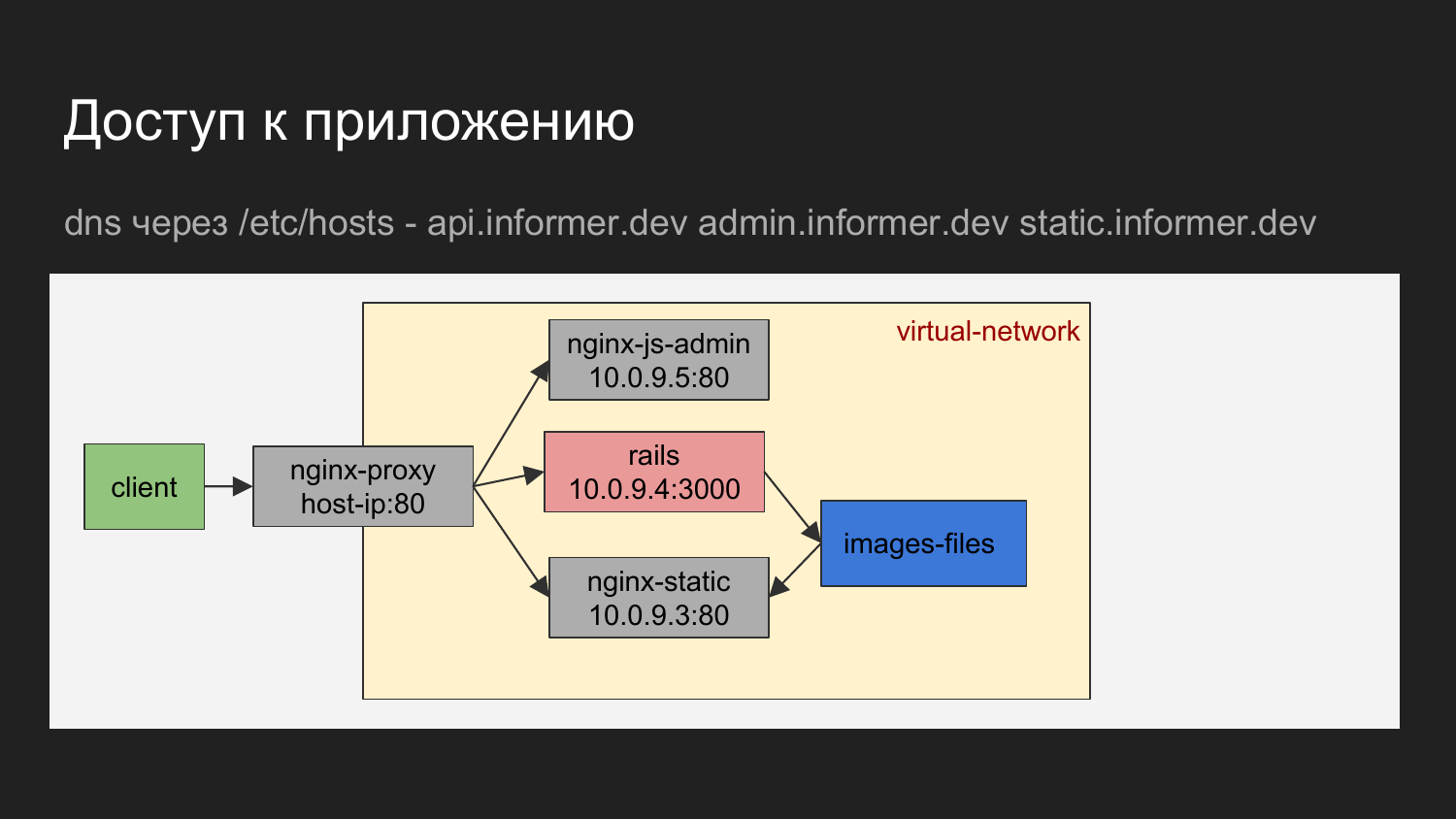
S'il est représenté graphiquement, il s'avère que le client est notre navigateur ou un outil avec lequel nous effectuons des demandes pour l'équilibreur.
L'équilibreur de nom de domaine détermine le conteneur auquel accéder.
Il peut s'agir de nginx, qui donne une zone d'administration JS. Cela peut être nginx, qui donne l'API ou les fichiers statiques qui sont donnés à nginx sous forme de chargement d'images.
Le diagramme montre que les conteneurs sont connectés par un réseau virtuel et sont cachés derrière le proxy.
Sur la machine du développeur, vous pouvez vous tourner vers le conteneur connaissant l'IP, mais nous ne l'utilisons essentiellement pas. La nécessité d'un traitement direct ne se pose pratiquement pas.

Quel exemple chercher pour docker l'application? À mon avis, un bon exemple est l'image de docker officielle pour MySQL.
C'est assez compliqué. Il existe de nombreuses versions. Mais sa fonctionnalité vous permet de couvrir de nombreux besoins qui peuvent survenir au cours du développement ultérieur. Si vous passez du temps et découvrez comment tout cela interagit, je pense que vous n'aurez aucun problème d'auto-implémentation.
Dans hub.docker.com, il existe généralement des liens vers github.com, qui fournissent des données brutes directement à partir desquelles vous pouvez assembler l'image vous-même.
Plus loin dans ce référentiel se trouve le script docker-endpoint.sh, qui est responsable de l'initialisation initiale et du traitement ultérieur du lancement de l'application.
Dans cet exemple, il est également possible de configurer à l'aide de variables d'environnement. En définissant la variable d'environnement lors du démarrage d'un seul conteneur ou via docker-compose, nous pouvons dire que nous devons définir un mot de passe vide pour docker sur pour root dans MySQL ou tout ce que nous voulons.
Il existe une option pour créer un mot de passe aléatoire. Nous disons que nous avons besoin d'un utilisateur, nous devons définir un mot de passe pour l'utilisateur et nous devons créer une base de données.
Dans nos projets, nous avons légèrement unifié le Dockerfile, qui est responsable de l'initialisation. Là, nous avons corrigé nos besoins pour ne faire qu'une extension des droits d'utilisateur que l'application utilise. Cela a permis à l'avenir de simplement créer une base de données à partir de la console d'application. Les applications Ruby ont une commande pour créer, modifier et supprimer des bases de données.

Ceci est un exemple de ce à quoi ressemble une version particulière de MySQL sur github.com. Vous pouvez ouvrir le dockerfile et voir comment l'installation se déroule là-bas.
Docker-endpoint.sh Script responsable du point d'entrée. Lors de l'initialisation initiale, certaines étapes de préparation sont nécessaires et toutes ces actions sont effectuées uniquement dans le script d'initialisation.

Nous passons à la deuxième partie.
Pour stocker le code source, nous sommes passés à gitlab. Il s'agit d'un système assez puissant doté d'une interface visuelle.
L'un des composants de Gitlab est Gitlab CI. Il vous permet de décrire les commandes de suivi qui seront ensuite utilisées pour organiser un système de livraison de code ou exécuter des tests automatiques.
Rapport sur Gitlab CI 2 https://goo.gl/uohKjI - un rapport du club Ruby Russia - assez détaillé et peut-être qu'il vous intéressera.

Nous allons maintenant examiner ce qui est nécessaire pour activer Gitlab CI. Pour démarrer Gitlab CI, il nous suffit de placer le fichier .gitlab-ci.yml à la racine du projet.
Nous décrivons ici que nous voulons effectuer une séquence d'états tels que tester, déployer.
Nous exécutons des scripts qui appellent directement docker-compose l'assembly de notre application. Ceci est un exemple de backend.
Ensuite, nous disons qu'il est nécessaire de conduire des migrations pour changer la base de données et exécuter des tests.
Si les scripts sont exécutés correctement et ne renvoient pas de code d'erreur, le système passe en conséquence à la deuxième étape du déploiement.
La phase de déploiement est actuellement mise en œuvre pour la mise en scène. Nous n'avons pas organisé de redémarrage en douceur.
Nous éteignons de force tous les conteneurs, puis nous soulevons à nouveau tous les conteneurs, collectés au premier stade pendant les tests.
Nous l'exécutons pour l'environnement variable actuel de migration de base de données, qui a été écrit par les développeurs.
Il y a une note qui s'applique uniquement à la branche principale.
Lors du changement d'autres branches n'est pas exécuté.
Il est possible d'organiser des déploiements sur les succursales.
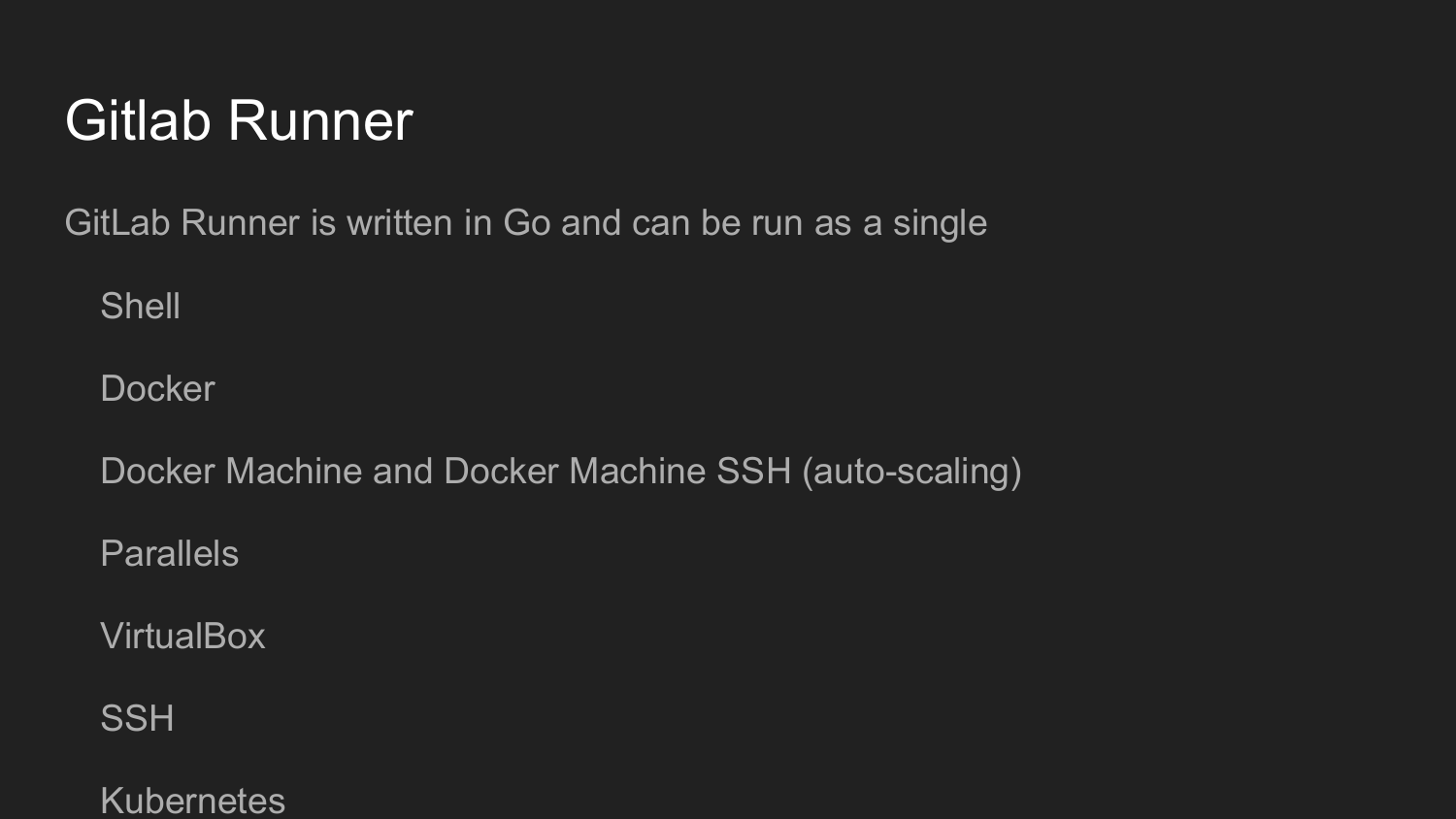
Pour mieux organiser cela, nous devons installer Gitlab Runner.
Cet utilitaire est écrit en Golang. Il s'agit d'un fichier unique, comme c'est la coutume dans le monde de Golang, qui ne nécessite aucune dépendance.
Au démarrage, nous enregistrons le Gitlab Runner.
Nous obtenons la clé dans l'interface web de Gitlab.
Ensuite, nous appelons la commande init sur la ligne de commande.
Configurer Gitlab Runner en mode dialogue (Shell, Docker, VirtualBox, SSH)
Le code sur Gitlab Runner s'exécutera à chaque validation, en fonction du paramètre .gitlab-ci.yml.
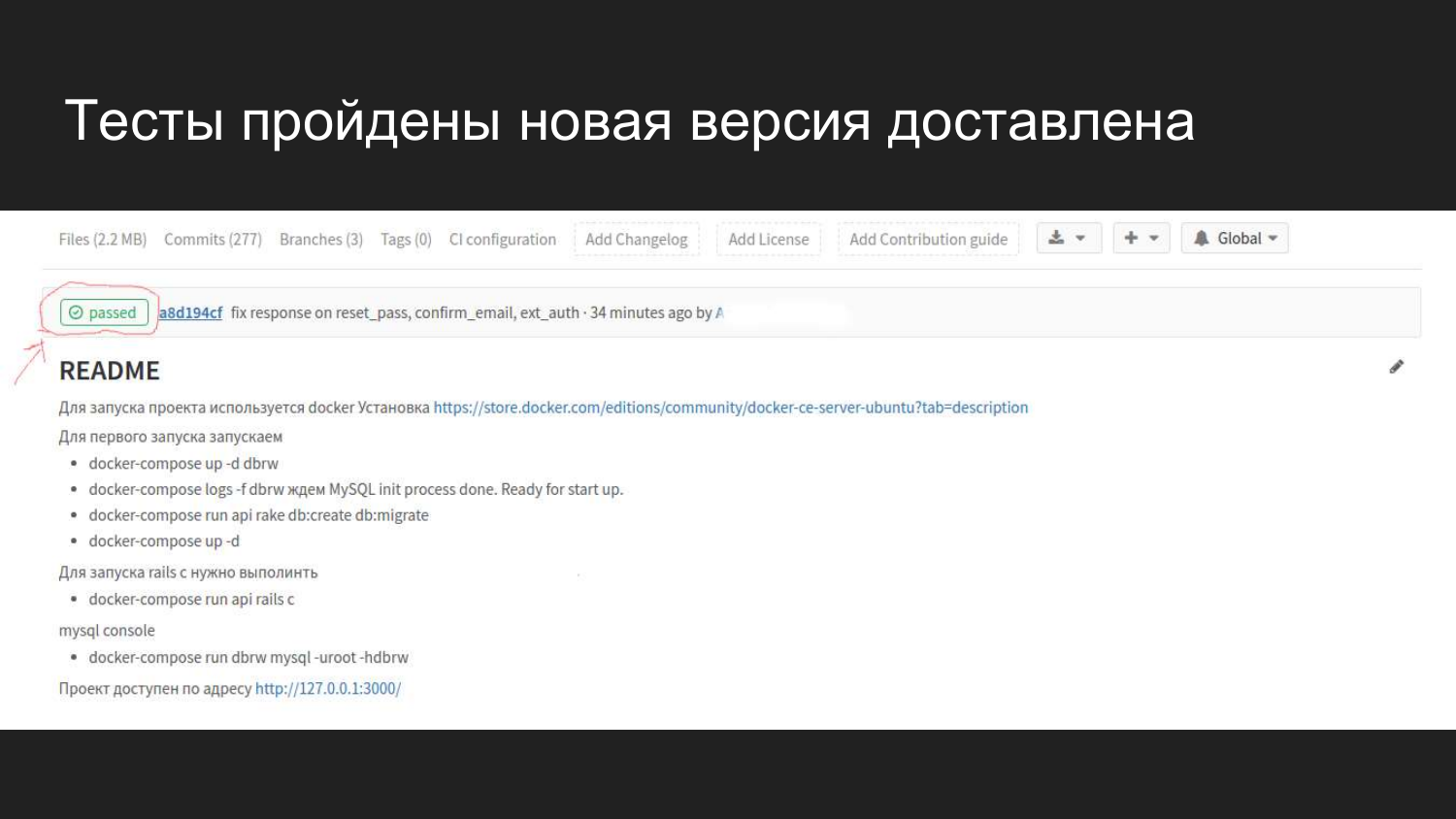
À quoi cela ressemble visuellement dans Gitlab dans une interface Web. Après avoir connecté GItlab CI, un indicateur apparaît qui indique l'état actuel de la construction.
Nous voyons qu'un commit a été fait il y a 4 minutes, qui a passé tous les tests et n'a causé aucun problème.
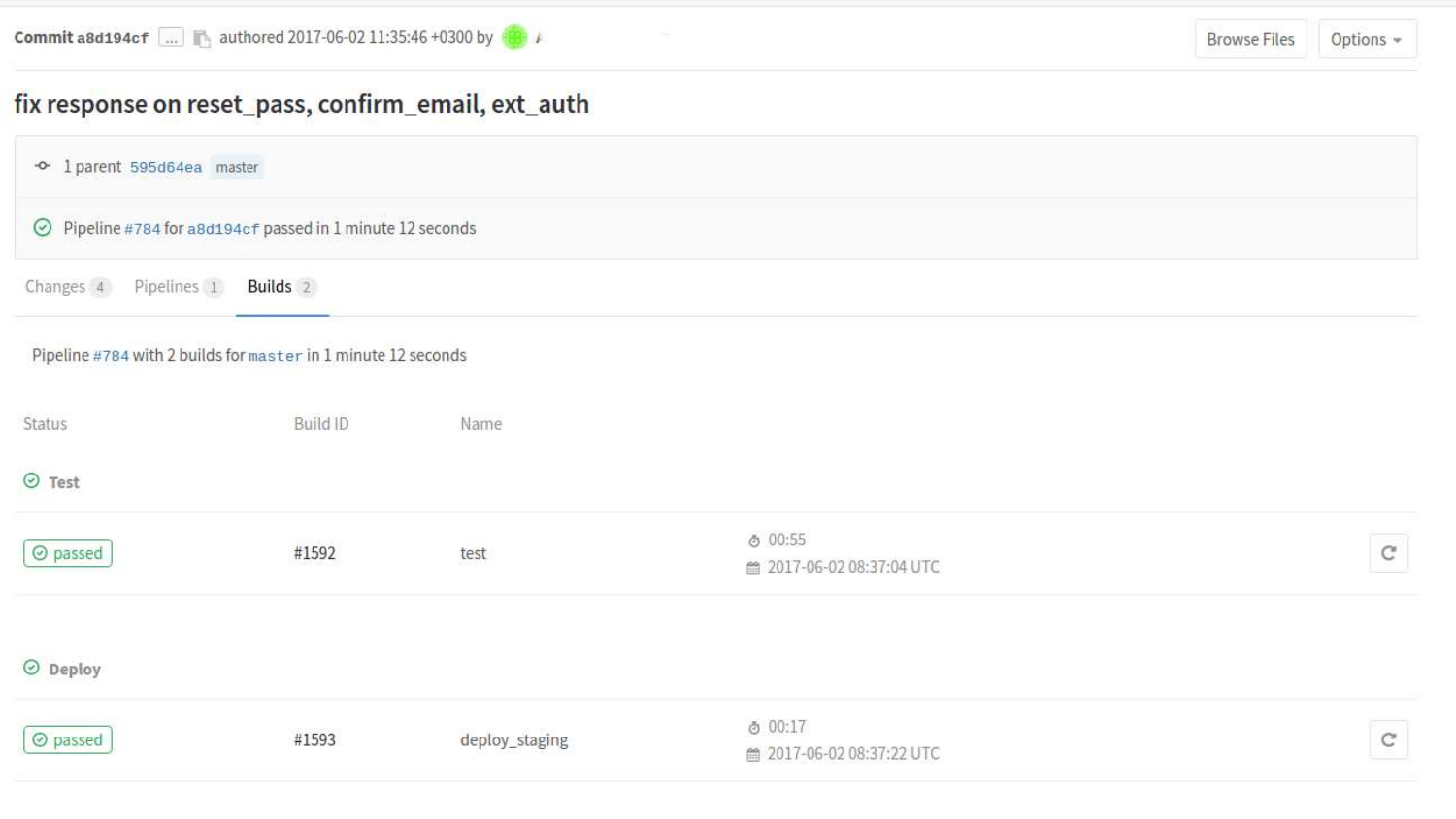
Nous pouvons examiner les versions plus en détail. Nous voyons ici que deux États sont déjà passés. Test de l'état et de l'état du déploiement lors de la mise en attente.
Si nous cliquons sur une construction spécifique, alors il y aura une sortie console des commandes qui ont été lancées dans le processus selon .gitlab-ci.yml.
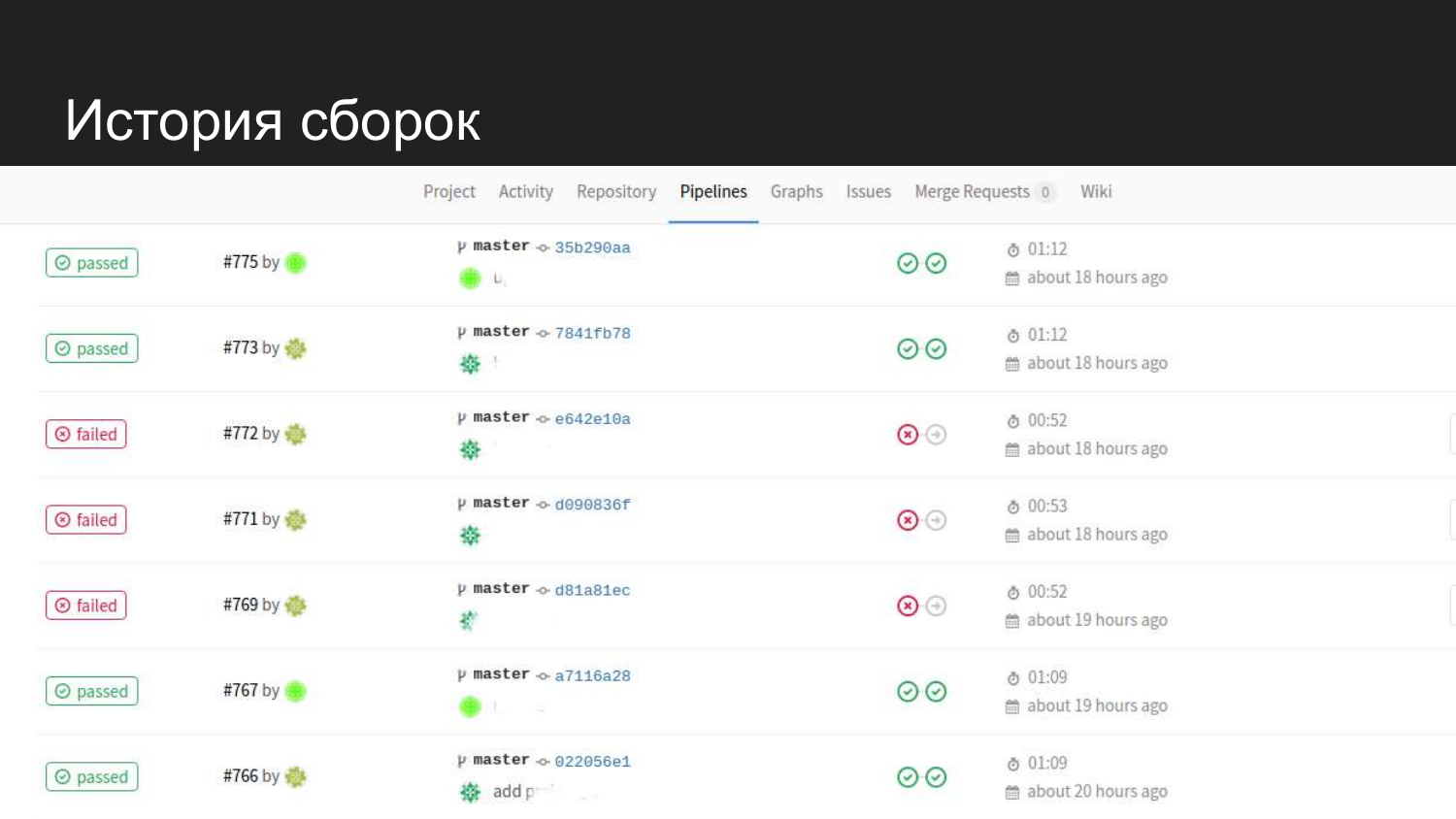
Voilà à quoi ressemble l'histoire de notre produit. On voit qu'il y a eu des tentatives réussies. Lorsque des tests sont soumis, il ne passe pas à l'étape suivante et le code de transfert n'est pas mis à jour.

Quelles tâches avons-nous résolues lors de la mise en scène lorsque nous avons introduit Docker? , , , .
.
Docker-compose .
, Docker . Docker-compose .
, .
— staging .
production 80 443 , WEB.

? Gitlab Runner .
Gitlab Gitlab Runner, - , .
Gitlab Runner, .
nginx-proxy .
, . .
80 , .

? root. root root .
, root , root.
- , , , , .
? , .
, ?
ID (UID) ID (GID).
ID 1000.
Ubuntu. Ubuntu ID 1000.
?
Docker. , . , - , .
, .
.
Docker Docker Swarm, . - Docker Swarm.
. . . web-.
