Bonjour, Habr! Je vous présente la traduction de l'article
«Envoy threading model» de Matt Klein.
Cet article m'a semblé assez intéressant, et comme Envoy est le plus souvent utilisé dans le cadre de kubernetes «istio» ou simplement «contrôleur d'entrée», la plupart des gens n'ont donc pas la même interaction directe avec lui que par exemple avec les installations typiques de Nginx ou Haproxy. Cependant, si quelque chose se casse, il serait bon de comprendre comment cela fonctionne de l'intérieur. J'ai essayé de traduire autant de texte que possible en russe, y compris des mots spéciaux, pour ceux qui sont pénibles à regarder, j'ai laissé les originaux entre crochets. Bienvenue au chat.
La documentation technique de bas niveau sur la base de code Envoy est actuellement assez rare. Pour résoudre ce problème, je prévois de créer une série d'articles de blog sur les différents sous-systèmes Envoy. Comme il s'agit du premier article, faites-moi savoir ce que vous pensez et ce qui pourrait vous intéresser dans les articles suivants.
L'une des questions techniques les plus courantes que j'obtiens à propos d'Envoy est une demande de description de bas niveau du modèle de filetage utilisé. Dans cet article, je décrirai comment Envoy mappe les connexions aux threads, ainsi qu'une description du système de stockage local de threads, qui est utilisé en interne pour rendre le code plus parallèle et plus performant.
Aperçu du filetage
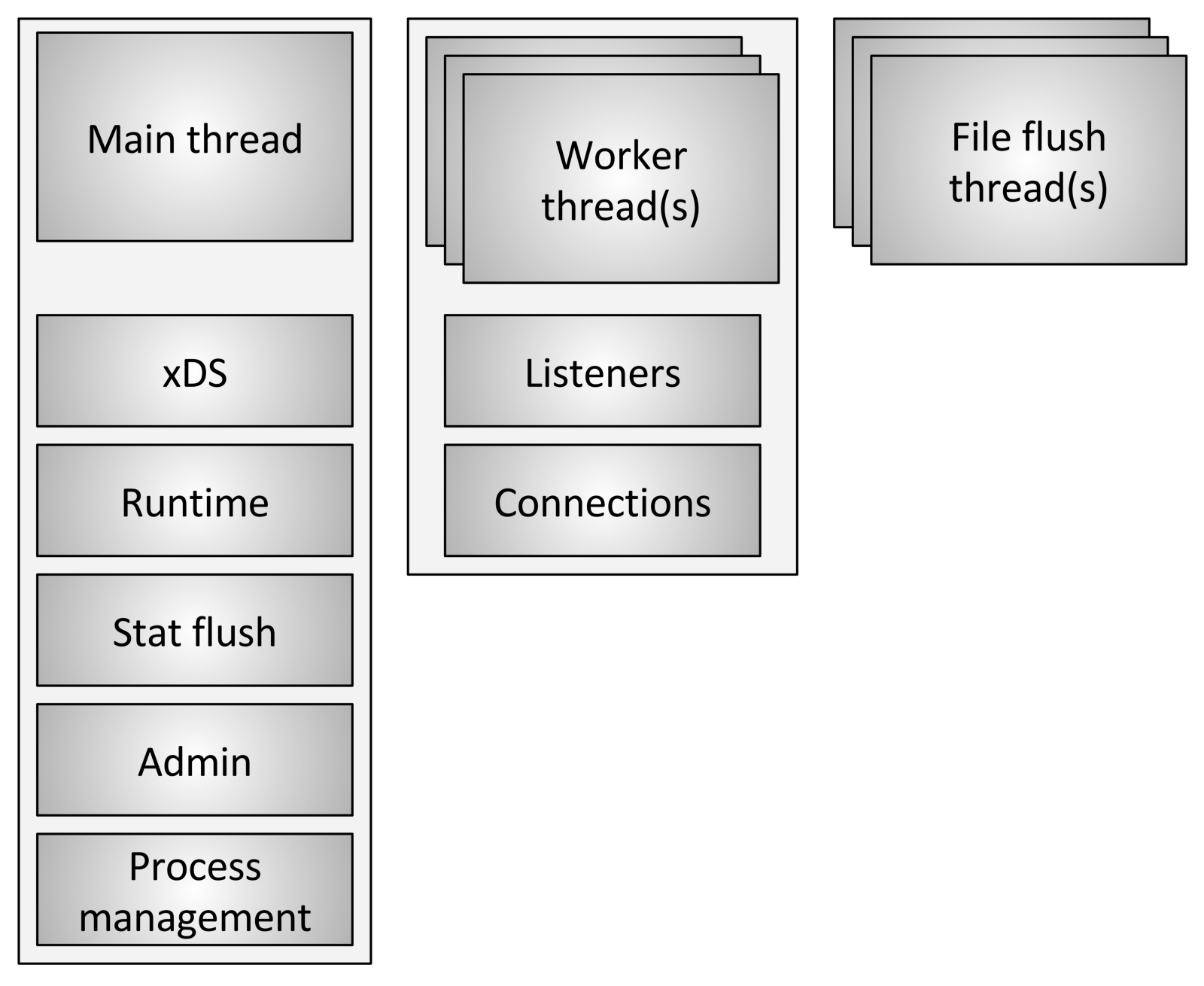 Envoy utilise trois types de flux différents:
Envoy utilise trois types de flux différents:- Principal: ce fil contrôle le début et la fin du processus, tout le traitement de l'API XDS (xDiscovery Service), y compris le DNS, la vérification de l'intégrité, la gestion générale du cluster et des services (runtime), la réinitialisation des statistiques, l'administration et la gestion générale processus - signaux Linux, redémarrage à chaud, etc. Tout ce qui se passe dans ce fil est asynchrone et non bloquant. En général, le thread principal coordonne tous les processus critiques de fonctionnalité, qui ne nécessitent pas un grand nombre de CPU pour terminer. Cela permet d'écrire la plupart du code de contrôle comme s'il s'agissait d'un seul thread.
- Worker: Par défaut, Envoy crée un thread de travail pour chaque thread matériel du système, ce qui peut être contrôlé à l'aide de l'option
--concurrency . Chaque thread de travail démarre une boucle d'événement «non bloquante», qui est responsable de l'écoute de chaque écouteur, au moment de la rédaction (29 juillet 2017) il n'y a pas de partitionnement de l'auditeur, en recevant de nouveaux connexions, création d'une instance de la pile de filtres à connecter et traitement de toutes les opérations d'E / S pendant la durée de vie de la connexion. Encore une fois, cela permet à la plupart du code de traitement de connexion d'être écrit comme s'il s'agissait d'un seul thread. - Nettoyeur de fichiers: chaque fichier écrit par Envoy, principalement les journaux d'accès, possède actuellement un flux de blocage indépendant. Cela est dû au fait que l'écriture dans des fichiers mis en cache par le système de fichiers, même lors de l'utilisation de
O_NONBLOCK , peut parfois être bloquée (soupir). Lorsque les threads de travail doivent écrire dans un fichier, les données sont en fait déplacées vers un tampon en mémoire, où elles sont finalement vidées via le flux de vidage de fichier . Il s'agit d'un domaine de code où techniquement tous les threads de travail peuvent bloquer le même verrou tout en essayant de remplir la mémoire tampon.
Gestion des connexions
Comme expliqué brièvement ci-dessus, tous les threads de travail écoutent tous les écouteurs sans aucune segmentation. Ainsi, le noyau est utilisé pour envoyer correctement les sockets reçues aux threads de travail. Les cœurs modernes sont généralement très bons dans ce domaine, ils utilisent des fonctionnalités telles que l'augmentation de la priorité des entrées-sorties (IO) pour essayer de remplir le thread avec du travail, avant de commencer à utiliser d'autres threads qui écoutent également sur le même socket, et n'utilisent pas non plus le verrouillage circulaire (Spinlock) pour gérer chaque demande.
Une fois qu'une connexion est acceptée sur un thread de travail, elle ne quitte jamais ce thread. Tous les autres traitements de la connexion sont entièrement traités dans le thread de travail, y compris tout comportement de transfert.
Cela a plusieurs conséquences importantes:- Tous les pools de connexions dans Envoy sont dans un flux de travail. Ainsi, bien que les pools de connexions HTTP / 2 établissent une seule connexion à chaque hôte en amont à la fois, s'il y a quatre threads de travail, il y aura quatre connexions HTTP / 2 à l'hôte en amont dans un état stable.
- La raison pour laquelle Envoy fonctionne de cette façon est qu'en stockant tout dans un même flux de travail, presque tout le code peut être écrit sans blocage et comme s'il était à un seul thread. Cette conception facilite l'écriture de beaucoup de code et évolue incroyablement bien pour un nombre presque illimité de workflows.
- Cependant, l'une des principales conclusions est que du point de vue du pool de mémoire et de l'efficacité de la connexion, il est en fait très important de configurer le paramètre
--concurrency . Le fait d'avoir plus de threads de travail que nécessaire entraînera une perte de mémoire, créant plus de connexions inactives et ralentissant la vitesse d'accès au pool de connexions. Chez Lyft, nos conteneurs sidecar envoyés fonctionnent avec une concurrence très faible, de sorte que les performances sont à peu près équivalentes aux services à côté desquels ils se trouvent. Nous exécutons Envoy en tant que proxy Edge (Edge) uniquement avec une concurrence maximale.
Que signifie non bloquant?
Le terme "non bloquant" a jusqu'à présent été utilisé à plusieurs reprises pour discuter du fonctionnement des threads principal et de travail. Tout le code est écrit à condition que rien ne soit jamais bloqué. Cependant, ce n'est pas entièrement vrai (ce qui n'est pas entièrement vrai?).
Envoy utilise plusieurs verrous de processus longs:- Comme déjà mentionné, lors de l'écriture des journaux d'accès, tous les threads de travail obtiennent le même verrou avant de remplir le tampon de journal en mémoire. Le temps de maintien du verrou doit être très faible, mais il est possible que ce verrou soit mis à l'épreuve avec une concurrence élevée et un débit élevé.
- Envoy utilise un système très sophistiqué pour traiter les statistiques locales au flux. Ce sera le sujet d'un article séparé. Cependant, je mentionnerai brièvement que dans le cadre du traitement local des statistiques de flux, il est parfois nécessaire d'obtenir un verrou pour le «magasin de statistiques» central. Ce verrou ne devrait jamais être nécessaire.
- Le thread principal a périodiquement besoin d'une coordination avec tous les workflows. Cela se fait en «publiant» du thread principal vers les threads de travail, et parfois depuis les threads de travail vers le thread principal. Pour l'envoi, le blocage est nécessaire afin que le message publié puisse être mis en file d'attente pour une remise ultérieure. Ces serrures ne doivent jamais être soumises à une concurrence sérieuse, mais elles peuvent toujours être bloquées techniquement.
- Lorsque Envoy écrit un journal dans le flux d'erreurs système (erreur standard), il reçoit un verrou sur l'ensemble du processus. Dans l'ensemble, la journalisation locale d'Envoy est considérée comme terrible en termes de performances, il n'y a donc pas beaucoup d'attention portée à son amélioration.
- Il existe plusieurs autres verrous aléatoires, mais aucun d'entre eux n'est critique pour les performances et ne doit jamais être contesté.
Thread stockage local
En raison de la façon dont Envoy sépare les responsabilités du thread principal des tâches de workflow, il est nécessaire qu'un traitement complexe puisse être effectué sur le thread principal, puis fourni à chaque workflow avec un degré élevé de concurrence. Cette section décrit le système Envoy Thread Local Storage (TLS) à un niveau élevé. Dans la section suivante, je décrirai comment il est utilisé pour gérer le cluster.

Comme déjà décrit, le thread principal traite presque toutes les fonctions de gestion et la fonctionnalité du plan de contrôle dans le processus Envoy. Le plan de contrôle est un peu surchargé ici, mais si vous le regardez dans le processus Envoy lui-même et le comparez avec le transfert que les threads de travail effectuent, cela semble approprié. En règle générale, le processus de thread principal effectue un certain travail, puis il doit mettre à jour chaque thread de travail conformément au résultat de ce travail,
tandis que le thread de travail n'a pas besoin de définir un verrou sur chaque accès .
Le système Envoy TLS (Thread local storage) fonctionne comme suit:- Le code exécuté dans le thread principal peut allouer un emplacement TLS pour l'ensemble du processus. Bien que cela soit abstrait, en pratique c'est un index dans un vecteur qui fournit un accès O (1).
- Le flux principal peut définir des données arbitraires dans son emplacement. Lorsque cela est fait, les données sont publiées dans chaque flux de travail en tant qu'événement de boucle d'événement normal.
- Les threads de travail peuvent lire à partir de leur emplacement TLS et récupérer toutes les données de thread local qui y sont disponibles.
Bien qu'il s'agisse d'un paradigme très simple et incroyablement puissant, il est très similaire au concept de blocage de RCU (lecture-copie-mise à jour). En substance, les workflows ne voient jamais de modifications de données dans les emplacements TLS au moment de l'exécution. Le changement ne se produit que pendant la période de repos entre les événements professionnels.
Envoy utilise cela de deux manières différentes:- En stockant différentes données sur chaque workflow, l'accès à ces données se fait sans aucun blocage.
- En stockant un pointeur global sur des données globales en lecture seule sur chaque thread de travail. Ainsi, chaque thread de travail possède un compteur de référence de données, qui ne peut pas être réduit pendant l'exécution du travail. Ce n'est que lorsque tous les employés se calmeront et téléchargeront de nouvelles données partagées que les anciennes données seront détruites. Il est identique au RCU.
Filetage de mise à jour de cluster
Dans cette section, je décrirai comment TLS (Thread local storage) est utilisé pour gérer un cluster. La gestion des clusters comprend le traitement de l'API xDS et / ou DNS, ainsi que la vérification de l'intégrité.
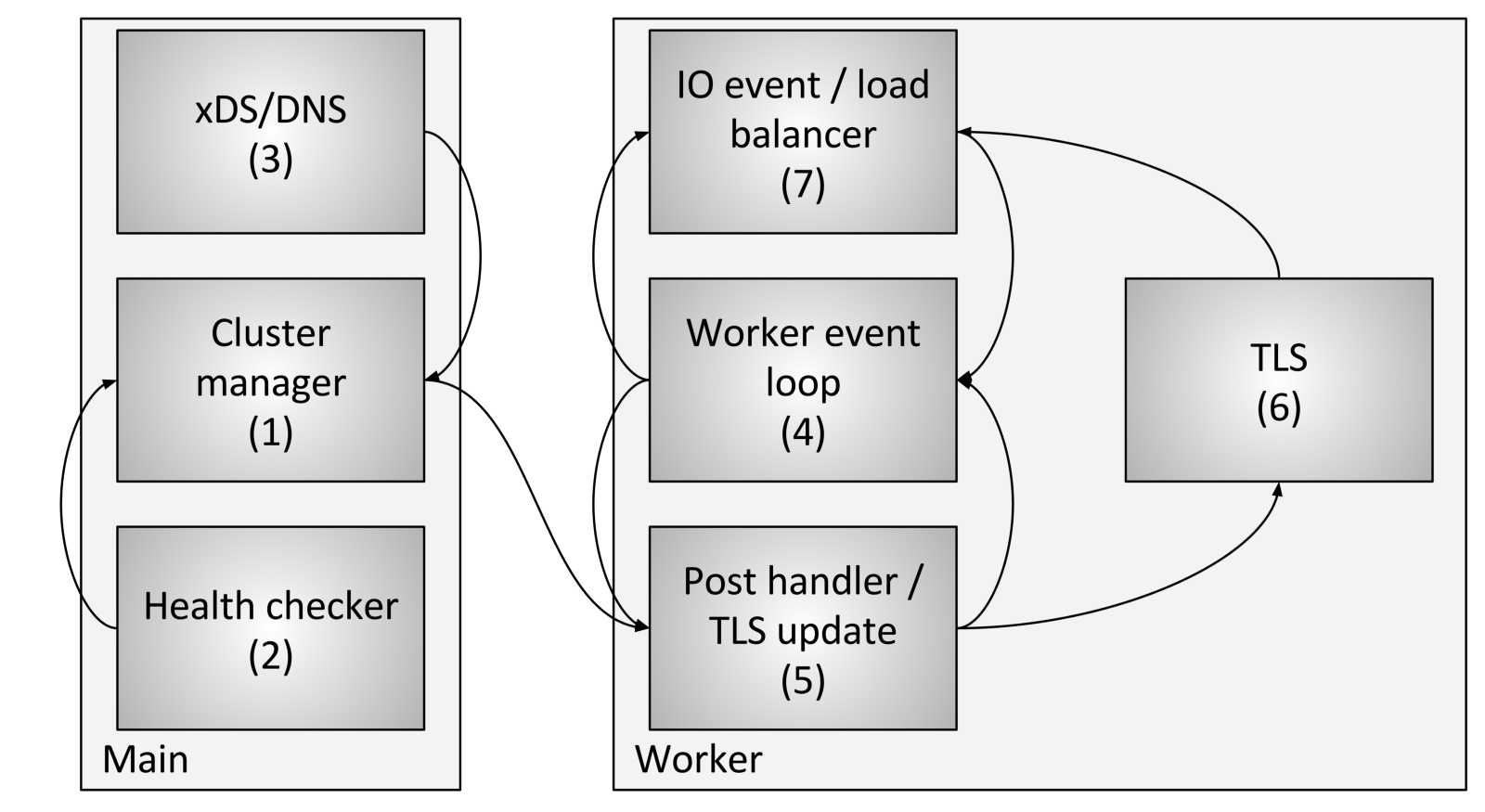 La gestion des flux de cluster comprend les composants et étapes suivants:
La gestion des flux de cluster comprend les composants et étapes suivants:- Cluster Manager est un composant d'Envoy qui gère tous les clusters connus en amont, les API CDS (Cluster Discovery Service), SDS (Secret Discovery Service) et EDS (Endpoint Discovery Service), DNS et les vérifications externes actives. santé (bilan de santé). Il est responsable de la création d'une représentation «finalement cohérente» de chaque cluster en amont qui inclut les hôtes découverts, ainsi que l'état de santé.
- Le vérificateur d'intégrité effectue une vérification d'intégrité active et rend compte des modifications de l'état d'intégrité au gestionnaire de cluster.
- CDS (Cluster Discovery Service) / SDS (Secret Discovery Service) / EDS (Endpoint Discovery Service) / DNS sont effectués pour déterminer l'appartenance au cluster. Le changement d'état est renvoyé au gestionnaire de cluster.
- Chaque flux de travail exécute constamment une boucle d'événements.
- Lorsque le gestionnaire de cluster détermine que l'état du cluster a changé, il crée un nouvel instantané de cluster en lecture seule et l'envoie à chaque thread de travail.
- Au cours de la prochaine période de dormance, le flux de travail mettra à jour l'instantané dans l'emplacement TLS dédié.
- Lors d'un événement d'E / S que l'hôte doit déterminer pour l'équilibrage de charge, l'équilibreur de charge demandera un emplacement TLS (Thread local storage) pour obtenir les informations d'hôte. Aucun verrou n'est requis pour cela. Notez également que TLS peut également déclencher des événements pendant la mise à niveau, de sorte que les équilibreurs de charge et d'autres composants puissent recompter les caches, les structures de données, etc. Cela dépasse le cadre de cet article, mais est utilisé à divers endroits dans le code.
En utilisant la procédure ci-dessus, Envoy peut traiter chaque demande sans aucun verrou (autre que ceux décrits précédemment). Outre la complexité du code TLS lui-même, la plupart du code n'a pas besoin de comprendre comment fonctionne le multithreading, et il peut être écrit en mode monothread. Cela facilite l'écriture de la plupart du code en plus de performances supérieures.
Autres sous-systèmes utilisant TLS
TLS (Thread local storage) et RCU (Read Copy Update) sont largement utilisés dans Envoy.
Exemples d'utilisation:- Le mécanisme de modification des fonctionnalités pendant l'exécution: la liste actuelle des fonctionnalités activées est calculée dans le thread principal. Chaque flux de travail est ensuite fourni avec un instantané en lecture seule à l'aide de la sémantique RCU.
- Remplacement des tables de routage : pour les tables de routage fournies par le RDS (Route Discovery Service), les tables de routage sont créées dans le thread principal. Un instantané en lecture seule sera fourni ultérieurement à chaque flux de travail à l'aide de la sémantique RCU (Read Copy Update). Cela rend la modification des tables de routage atomiquement efficace.
- Mise en cache d'en-tête HTTP: Il s'avère que le calcul de l'en-tête HTTP pour chaque demande (lors de l'exécution de ~ 25K + RPS par cœur) est assez coûteux. Envoy calcule l'en-tête de manière centralisée environ toutes les demi-secondes et le fournit à chaque employé via TLS et RCU.
Il existe d'autres cas, mais les exemples précédents devraient permettre de bien comprendre à quoi sert TLS.
Pièges de performance connus
Bien qu'Envoy fonctionne assez bien dans l'ensemble, il existe quelques domaines bien connus qui nécessitent une attention lorsqu'ils sont utilisés avec une concurrence et une bande passante très élevées:
- Comme déjà décrit dans cet article, actuellement tous les threads de travail sont verrouillés lorsqu'ils écrivent dans le tampon de mémoire du journal d'accès. Avec une concurrence élevée et un débit élevé, il sera nécessaire de regrouper les journaux d'accès pour chaque flux de travail en raison d'une livraison non ordonnée lors de l'écriture dans le fichier final. Vous pouvez également créer un journal d'accès distinct pour chaque flux de travail.
- Bien que les statistiques soient très optimisées, avec une concurrence et un débit très élevés, il y aura probablement une concurrence atomique sur les statistiques individuelles. La solution à ce problème consiste en des compteurs pour un flux de travail avec une réinitialisation périodique des compteurs centraux. Cela sera discuté dans un prochain post.
- L'architecture existante ne fonctionnera pas correctement si Envoy est déployé dans un scénario dans lequel il y a très peu de connexions qui nécessitent des ressources de traitement importantes. Il n'y a aucune garantie que les communications seront réparties également entre les workflows. Cela peut être résolu en équilibrant les connexions de travail, dans lequel la capacité à échanger des connexions entre les flux de travail sera réalisée.
Conclusion
Le modèle de filetage Envoy est conçu pour fournir une facilité de programmation et une concurrence massive en raison de l'utilisation potentiellement inutile de la mémoire et des connexions si elles ne sont pas configurées correctement. Ce modèle lui permet de fonctionner très bien avec un nombre très élevé de threads et de débit.
Comme je l'ai brièvement mentionné sur Twitter, une conception peut également s'exécuter au-dessus d'une pile réseau entièrement fonctionnelle en mode utilisateur, comme le DPDK (Data Plane Development Kit), ce qui peut entraîner des serveurs réguliers à traiter des millions de demandes par seconde avec un traitement L7 complet. Il sera très intéressant de voir ce qui sera construit dans les prochaines années.
Un dernier petit commentaire: on m'a souvent demandé pourquoi nous avions choisi C ++ pour Envoy. La raison, comme précédemment, est qu'il est toujours le seul langage de niveau industriel largement parlé sur lequel construire l'architecture décrite dans cet article. C ++ n'est certainement pas adapté à tous ou même à de nombreux projets, mais pour certains cas d'utilisation, il reste le seul outil pour faire le travail (pour faire le travail).
Liens vers le code
Liens vers des fichiers avec des interfaces et des implémentations d'en-tête discutés dans cet article: