Bonjour à tous. La bibliothèque du réseau neuronal est décrite dans mon dernier
article . Ici, j'ai décidé de montrer comment vous pouvez utiliser le réseau formé de TF (Tensorflow) dans votre décision, et si cela en vaut la peine.
Sous la coupe, une comparaison avec l'implémentation originale de TF, une application de démonstration pour reconnaître des images, enfin ... des conclusions. Peu importe, s'il vous plaît.
Vous pouvez découvrir comment fonctionne ResNet, par exemple,
ici .
Voici la structure du réseau en chiffres:
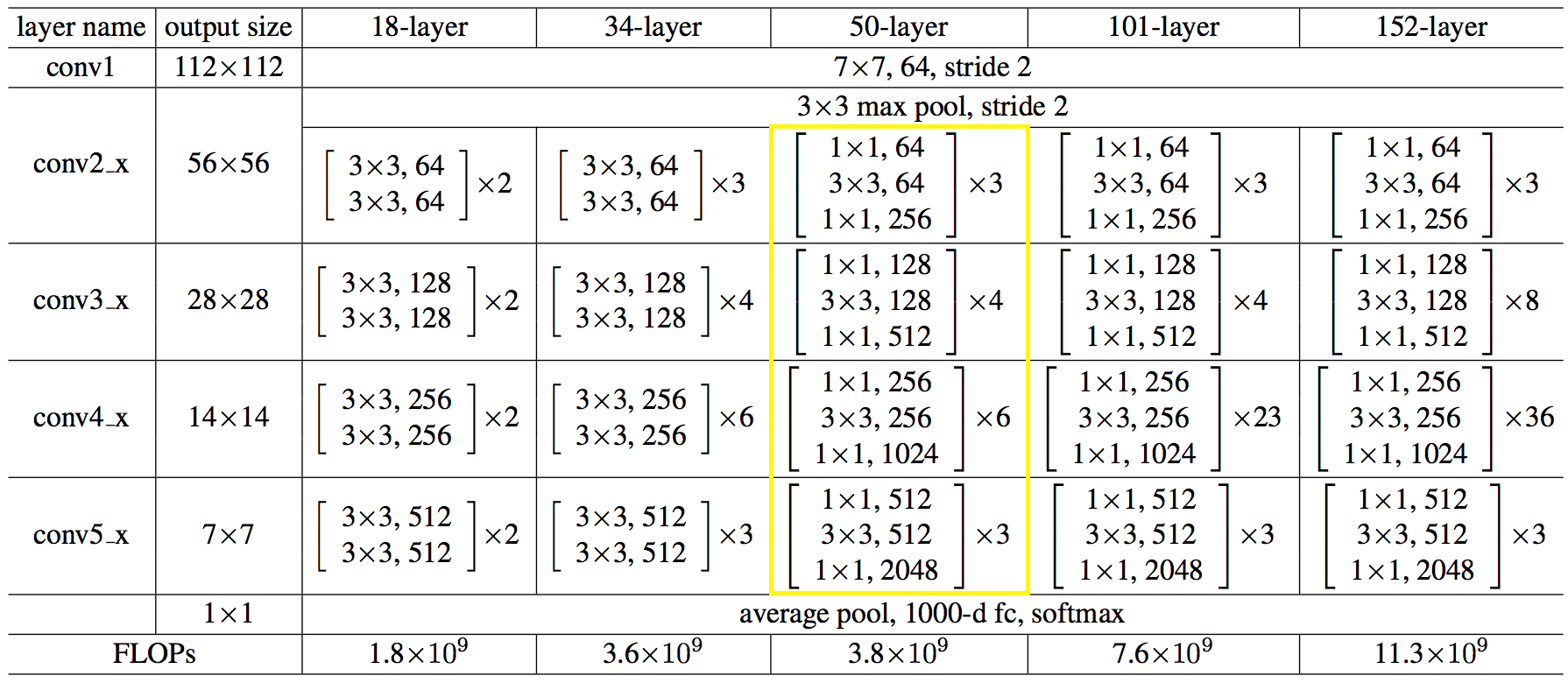
Le code s'est avéré être pas plus simple et pas plus compliqué que python.
Code C ++ pour créer un réseau:auto net = sn::Net(); net.addNode("In", sn::Input(), "conv1") .addNode("conv1", sn::Convolution(64, 7, 3, 2, sn::batchNormType::beforeActive, sn::active::none, mode), "pool1_pad") .addNode("pool1_pad", sn::Pooling(3, 2, sn::poolType::max, mode), "res2a_branch1 res2a_branch2a"); convBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, 1, "res2a_branch", "res2b_branch2a res2b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, "res2b_branch", "res2c_branch2a res2c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256}, 3, "res2c_branch", "res3a_branch1 res3a_branch2a", mode); convBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, 2, "res3a_branch", "res3b_branch2a res3b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3b_branch", "res3c_branch2a res3c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3c_branch", "res3d_branch2a res3d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3d_branch", "res4a_branch1 res4a_branch2a", mode); convBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, 2, "res4a_branch", "res4b_branch2a res4b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4b_branch", "res4c_branch2a res4c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4c_branch", "res4d_branch2a res4d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4d_branch", "res4e_branch2a res4e_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4e_branch", "res4f_branch2a res4f_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4f_branch", "res5a_branch1 res5a_branch2a", mode); convBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, 2, "res5a_branch", "res5b_branch2a res5b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5b_branch", "res5c_branch2a res5c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5c_branch", "avg_pool", mode); net.addNode("avg_pool", sn::Pooling(7, 7, sn::poolType::avg, mode), "fc1000") .addNode("fc1000", sn::FullyConnected(1000, sn::active::none, mode), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
→ Le code complet est disponible
iciVous pouvez le faire plus facilement, charger l'architecture du réseau et les poids à partir de fichiers,
comme ceci: string archPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Struct.json", weightPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Weights.dat"; std::ifstream ifs; ifs.open(archPath, std::ifstream::in); if (!ifs.good()){ cout << "error open file : " + archPath << endl; system("pause"); return false; } ifs.seekg(0, ifs.end); size_t length = ifs.tellg(); ifs.seekg(0, ifs.beg); string jnArch; jnArch.resize(length); ifs.read((char*)jnArch.data(), length);
Fait une demande d'intérêt. Vous pouvez télécharger
ici . Le volume est important en raison des poids du réseau. Les sources sont là, vous pouvez les utiliser comme exemple.
L'application a été créée uniquement pour l'article, elle ne sera pas prise en charge, elle n'a donc pas été incluse dans le référentiel du projet.

Maintenant, ce qui s'est passé par rapport à TF.
Indications après une série de 100 images, en moyenne. Machine: i5-2400, GF1050, Win7, MSVC12.
Les valeurs des résultats de reconnaissance correspondent au troisième caractère.
→
Code de testEn fait, tout est déplorable bien sûr.
Pour le CPU, j'ai décidé de ne pas utiliser MKL-DNN, j'ai moi-même pensé à le finir: redistribué la mémoire pour une lecture séquentielle, chargé au maximum les registres vectoriels. Peut-être était-il nécessaire de conduire à une multiplication matricielle et / ou à d'autres hacks. Reposé ici, au début c'était pire, il serait plus correct d'utiliser tout de même MKL.
Sur le GPU, du temps est consacré à la copie de la mémoire de / vers la mémoire de la carte vidéo et toutes les opérations ne sont pas effectuées sur le GPU.
Quelles conclusions peut-on tirer de toute cette agitation:
- non pas pour se montrer, mais pour utiliser des solutions éprouvées bien connues, elles leur sont déjà venues à l'esprit plus ou moins. Il s'est assis sur mxnet lui-même une fois, et a travaillé dur avec l'usage indigène, plus sur celui ci-dessous;
- N'essayez pas d'utiliser l'interface C native des frameworks ML. Et utilisez-les dans le langage sur lequel les développeurs se sont concentrés, à savoir le python.
Un moyen simple d'utiliser la fonctionnalité ML de votre langue est de faire un processus de service sur python et de lui envoyer des images sur le socket, vous obtenez une répartition des responsabilités et l'absence de code lourd.
Peut-être tout. L'article était court, mais les conclusions, je pense, sont précieuses et s'appliquent non seulement au BC.
Je vous remercie
PS:
si quelqu'un a le désir et la force d'essayer de rattraper TF,
bienvenue !)
PS2:
baissa les mains plus tôt. Il a pris une pause fumée, l'a repris et tout a fonctionné.
Pour le CPU, le casting vers la multiplication matricielle a aidé, comme je le pensais.
Pour le GPU, j'ai sélectionné toutes les opérations dans une bibliothèque distincte, de sorte que sans copier sur le CPU et vice versa, le seul inconvénient de cette approche était que je devais réécrire (dupliquer) tous les opérateurs, bien que certaines choses coïncident, mais ne les lient pas.
En général, voici comment maintenant:
Autrement dit, au moins l'inférence s'est avérée encore plus rapide que sur TF.
Le code de test n'a pas changé.