Si l'enseignement routier était enseigné à l'école, le manuel sur ce sujet aurait une telle tâche. «Le réseau social N compte 2 000 serveurs, sur lesquels 150 000 fichiers de 900 Mo de code PHP et un cluster intermédiaire pour 50 machines. Le code est déployé sur les serveurs 2 fois par jour, sur le cluster intermédiaire, le code est mis à jour toutes les quelques minutes, et il existe des «correctifs» supplémentaires - de petits ensembles de fichiers qui sont disposés à leur tour sur tout ou sur la partie sélectionnée des serveurs, sans attendre le calcul complet. Question: ces conditions sont-elles considérées comme des charges élevées et comment les déployer? Écrivez au moins 5 options de déploiement. " Nous ne pouvons que rêver du livre de problèmes hyload, mais nous savons déjà que
Yuri Nasretdinov (
youROCK ) résoudrait définitivement ce problème et obtiendrait les «cinq».
Yuri ne s'est pas contenté d'une solution simple, mais a également fait un rapport dans lequel il a divulgué le concept du concept de «déploiement de code», a parlé de solutions classiques et alternatives aux déploiements PHP à grande échelle, analysé leurs performances et présenté le système de déploiement MDK.
Le concept de «déploiement de code»
En anglais, le terme «déployer» signifie mettre les troupes en alerte, et en russe, nous disons parfois «mettre le code au combat», ce qui signifie la même chose. Vous prenez le code dans celui déjà compilé ou dans l'original, s'il s'agit de PHP, téléchargez-le sur les serveurs qui servent le trafic utilisateur, puis, par magie, passez d'une manière ou d'une autre la charge d'une version du code à une autre. Tout cela est inclus dans le concept de «déploiement de code».
Le processus de déploiement comprend généralement plusieurs étapes.
- Récupérer le code du référentiel comme vous le souhaitez: cloner, récupérer, extraire.
- Assemblage - construire . Pour le code PHP, la phase de construction peut être manquante. Dans notre cas, il s'agit, en règle générale, de la génération automatique de fichiers de traduction, du téléchargement de fichiers statiques sur CDN et de certaines autres opérations.
- Livraison aux serveurs finaux - déploiement.
Une fois que tout est assemblé, la phase du déploiement immédiat commence - le
code est
versé sur les serveurs de production . C'est à propos de cette phase que
Badoo sera discuté.
Ancien système de déploiement à Badoo
Si vous avez un fichier avec une image du système de fichiers, comment le monter? Sous Linux, vous devez créer
un périphérique de boucle intermédiaire , y attacher un fichier et après cela, vous pouvez déjà monter ce périphérique de bloc.
Un périphérique en boucle est une béquille dont Linux a besoin pour monter une image de système de fichiers. Il existe des OS dans lesquels cette béquille n'est pas requise.

Comment le processus de déploiement utilise-t-il des fichiers, que nous appelons également «boucles» pour simplifier? Il existe un répertoire dans lequel se trouvent le code source et le contenu généré automatiquement. Nous prenons une image vide du système de fichiers - maintenant c'est EXT2, et plus tôt nous utilisions ReiserFS. Nous montons une image vide du système de fichiers dans un répertoire temporaire, y copions tout le contenu. Si nous n'avons pas besoin de quelque chose pour entrer en production, nous ne copions pas tout. Après cela, démontez le périphérique et obtenez l'image du système de fichiers dans lequel se trouvent les fichiers nécessaires. Ensuite, nous
archivons l'image et la téléchargeons sur tous les serveurs , nous la décompressons et la montons.
Autres solutions existantes
Tout d'abord, remercions
Richard Stallman - sans sa licence, la plupart des utilitaires que nous utilisons n'auraient pas existé.

J'ai classiquement divisé les méthodes de déploiement de code PHP en 4 catégories.
- Basé sur le système de contrôle de version : svn up, git pull, hg up.
- Basé sur l'utilitaire rsync - vers un nouveau répertoire ou "en haut".
- Déployez un fichier - quoi qu'il arrive: phar, hhbc, loop.
- La manière spéciale que Rasmus Lerdorf a suggérée est rsync, 2 répertoires et realpath_root .
Chaque méthode a ses avantages et ses inconvénients, raison pour laquelle nous les avons abandonnés. Considérez ces 4 méthodes plus en détail.
Déploiement basé sur le système de contrôle de version svn up
Je n'ai pas choisi SVN par hasard - selon mes observations, sous cette forme le déploiement existe précisément dans le cas de SVN. Le système est assez
léger , il vous permet
de déployer
rapidement et facilement - exécutez simplement svn up et vous avez terminé.
Mais cette méthode a un gros inconvénient: si vous faites svn up, et dans le processus de mise à jour du code source, lorsque de nouvelles requêtes proviennent du référentiel, ils verront l'état du système de fichiers qui n'existait pas dans le référentiel. Vous aurez une partie des fichiers nouveaux et une partie des anciens - il s'agit d'une
méthode de déploiement non atomique qui ne convient pas aux charges élevées, mais uniquement aux petits projets. Malgré cela, je connais des projets qui sont toujours déployés de cette façon, et jusqu'à présent, tout fonctionne pour eux.
Déploiement basé sur l'utilitaire rsync
Il existe deux options pour procéder: télécharger des fichiers à l'aide de l'utilitaire directement sur le serveur et télécharger «en haut» - mise à jour.
rsync dans un nouveau répertoire
Étant donné que vous versez d'abord tout le code dans un répertoire qui n'existe pas encore sur le serveur, puis que vous changez de trafic, cette méthode est
atomique - personne ne voit un état intermédiaire. Dans notre cas, la création de 150 000 fichiers et la suppression de l'ancien répertoire, qui contient également 150 000 fichiers, crée une
charge importante sur le sous-système de disque . Nous utilisons les disques durs très activement, et le serveur quelque part pendant une minute ne se sent pas très bien après une telle opération. Puisque nous avons 2000 serveurs, il faut remplir 900 Mo 2000 fois.
Ce schéma peut être amélioré si vous téléchargez d'abord sur un certain nombre de serveurs intermédiaires, par exemple, 50, puis les ajoutez au reste. Cela résout les problèmes possibles avec le réseau, mais le problème de la création et de la suppression d'un grand nombre de fichiers ne disparaît nulle part.
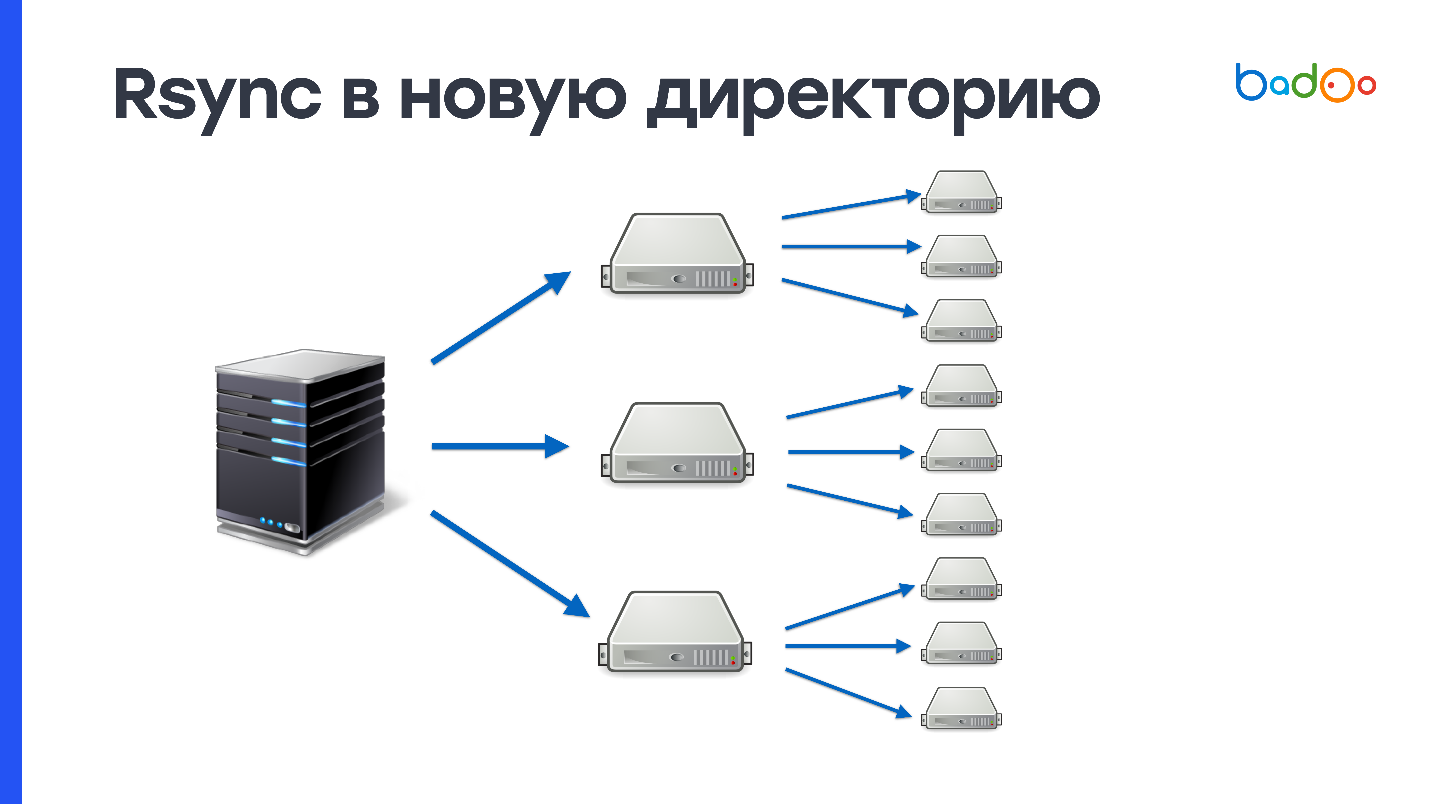
rsync sur le dessus
Si vous avez utilisé rsync, vous savez que cet utilitaire peut non seulement remplir des répertoires entiers, mais également mettre à jour les répertoires existants. L'envoi de modifications uniquement est un plus, mais puisque nous téléchargeons les modifications dans le même répertoire où nous servons le code de bataille, il y aura également une sorte d'état intermédiaire - c'est un inconvénient.
Soumettre des modifications fonctionne comme ceci. Rsync établit des listes de fichiers côté serveur à partir duquel le déploiement est effectué et côté réception. Après cela, il compte les statistiques de tous les fichiers et envoie la liste entière au côté récepteur. Sur le serveur à partir duquel le déploiement se déroule, la différence entre ces valeurs est prise en compte et il est déterminé quels fichiers doivent être envoyés.
Dans nos conditions, ce processus prend environ
3 Mo de trafic et 1 seconde de temps processeur . Il semble que ce ne soit pas grand-chose, mais nous avons 2 000 serveurs, et tout se passe au moins une minute de temps processeur. Ce n'est pas une méthode aussi rapide, mais certainement meilleure que d'envoyer le tout via rsync. Il reste à résoudre en quelque sorte le problème de l'atomicité et sera presque parfait.
Déployer un fichier
Quel que soit le fichier que vous téléchargez, il est relativement simple de le faire en utilisant BitTorrent ou l'utilitaire UFTP. Un fichier est plus facile à décompresser, peut être atomiquement remplacé sur Unix, et il est facile de vérifier l'intégrité du fichier généré sur le serveur de génération et livré aux machines cibles en calculant les montants MD5 ou SHA-1 à partir du fichier (dans le cas de rsync, vous ne savez pas ce qui se trouve sur les serveurs de destination )
Pour les disques durs, l'enregistrement séquentiel est un gros plus - un fichier de 900 Mo sera écrit sur un disque dur inoccupé en environ 10 secondes. Mais vous devez toujours enregistrer ces mêmes 900 Mo et les transférer sur le réseau.
Digression lyrique sur l'UFTP
Cet utilitaire Open Source a été initialement créé pour transférer des fichiers sur un réseau avec de longs retards, par exemple, via un réseau satellite. Mais UFTP s'est avéré approprié pour télécharger des fichiers sur un grand nombre de machines, car il fonctionne en utilisant le protocole UDP basé sur la multidiffusion. Une seule adresse de multidiffusion est créée, toutes les machines qui souhaitent recevoir le fichier s'y abonnent et les commutateurs s'assurent que des copies des paquets sont livrées à chaque machine. Nous déplaçons donc le fardeau de la transmission de données vers le réseau. Si votre réseau peut gérer cela, cette méthode fonctionne beaucoup mieux que BitTorrent.
Vous pouvez essayer cet utilitaire Open Source sur votre cluster. Malgré le fait qu'il fonctionne sur UDP, il dispose d'un mécanisme NACK - accusé de réception négatif, ce qui force les paquets de réacheminement perdus à la livraison.
Il s'agit d'un moyen fiable de déploiement .
Options de déploiement de fichier unique
tar.gzUne option qui combine les inconvénients des deux approches. Non seulement vous devez écrire 900 Mo sur le disque de manière séquentielle, après cela, vous devez à nouveau écrire les mêmes 900 Mo avec lecture-écriture aléatoire et créer 150 000 fichiers. Cette méthode est encore moins performante que rsync.
pharPHP prend en charge les archives au format phar (PHP Archive), sait comment donner leur contenu et inclure des fichiers. Mais tous les projets ne sont pas faciles à mettre dans un seul phar - vous avez besoin d'une adaptation de code. Tout simplement parce que le code de cette archive ne fonctionne pas. De plus, vous ne pouvez pas changer un fichier dans l'archive (
Yuri du futur: en théorie, vous pouvez toujours ), vous devez recharger l'intégralité de l'archive. De plus, malgré le fait que les archives phar fonctionnent avec OPCache, lors du déploiement, le cache doit être supprimé, car sinon il y aura des déchets dans OPCache à partir de l'ancien fichier phar.
hhbcCette méthode est native de HHVM - HipHop Virtual Machine et est utilisée par Facebook. Cela ressemble à une archive phar, mais elle ne contient pas les codes source, mais le code d'octets compilé de la machine virtuelle HHVM - l'interpréteur PHP de Facebook. Il est interdit de modifier quoi que ce soit dans ce fichier: vous ne pouvez pas créer de nouvelles classes, fonctions et certaines autres fonctionnalités dynamiques dans ce mode sont désactivées. En raison de ces limitations, la machine virtuelle peut utiliser des optimisations supplémentaires. Selon Facebook, cela peut amener jusqu'à 30% à la vitesse d'exécution du code. C'est probablement une bonne option pour eux. Il est également impossible de modifier un fichier ici (
Yuri du futur: en fait, c'est possible, car il s'agit d'une base sqlite ). Si vous souhaitez modifier une ligne, vous devez refaire l'archive entière à nouveau.
Pour cette méthode, il est
interdit d'utiliser eval et dynamic include. Il en est ainsi, mais pas tout à fait. Eval peut être utilisé, mais s'il ne crée pas de nouvelles classes ou fonctions, et include ne peut pas être créé à partir de répertoires en dehors de cette archive.
boucleCeci est notre ancienne version, et elle a deux gros avantages. Tout d'abord, il ressemble à un répertoire normal
. Vous montez la boucle, et pour le code, cela n'a pas d'importance - cela fonctionne avec des fichiers, à la fois sur l'environnement de développement et sur l'environnement de production. La deuxième boucle peut être montée en mode lecture et écriture, et changer un fichier, si vous devez encore changer quelque chose de toute urgence pour la production.
Mais la boucle a des inconvénients. Tout d'abord, cela fonctionne étrangement avec Docker. J'en parlerai un peu plus tard.
Deuxièmement, si vous utilisez un lien symbolique sur la dernière boucle en tant que document_root, vous aurez des problèmes avec OPCache. Il n'est pas très bon d'avoir un lien symbolique dans le chemin et commence à confondre les versions des fichiers à utiliser. Par conséquent, OPCache doit être réinitialisé lors du déploiement.
Un autre problème est que les
privilèges de superutilisateur sont requis pour monter des systèmes de fichiers. Et vous ne devez pas oublier de les monter au démarrage / redémarrage de la machine, car sinon il y aura un répertoire vide au lieu du code.
Problèmes avec docker
Si vous créez un conteneur Docker et y jetez un dossier dans lequel des «boucles» ou d'autres périphériques de bloc sont montés, deux problèmes surviennent à la fois: les nouveaux points de montage ne tombent pas dans le conteneur Docker et les «boucles» qui étaient au moment de la création Un conteneur Docker
ne peut pas être démonté car il est occupé par un conteneur Docker.
Naturellement, cela est généralement incompatible avec le déploiement, car le nombre de périphériques de boucle est limité et on ne sait pas comment le nouveau code doit tomber dans le conteneur.
Nous avons essayé de faire des choses étranges, par exemple, élever un
serveur NFS local ou monter un répertoire en utilisant SSHFS, mais pour diverses raisons cela n'a pas pris racine en nous. En conséquence, dans cron, nous avons enregistré rsync de la dernière «boucle» dans le répertoire courant, et il a exécuté la commande une fois par minute:
rsync /var/loop/<N>/ /var/www/
Ici
/var/www/ est le répertoire qui est promu dans le conteneur. Mais sur les machines qui ont des conteneurs Docker, nous n'avons pas besoin d'exécuter des scripts PHP souvent, donc rsync n'était pas atomique, ce qui nous convenait. Mais encore, cette méthode est très mauvaise, bien sûr. Je voudrais faire un système de déploiement qui fonctionne bien avec docker.
rsync, 2 répertoires et realpath_root
Cette méthode a été proposée par Rasmus Lerdorf, l'auteur de PHP, et il sait se déployer.
Comment faire un déploiement atomique, et de l'une des manières dont j'ai parlé? Prenez le lien symbolique et enregistrez-le en tant que document_root. À chaque instant, le lien symbolique pointe vers l'un des deux répertoires et vous faites rsync dans un répertoire voisin, c'est-à-dire vers celui vers lequel le code ne pointe pas.
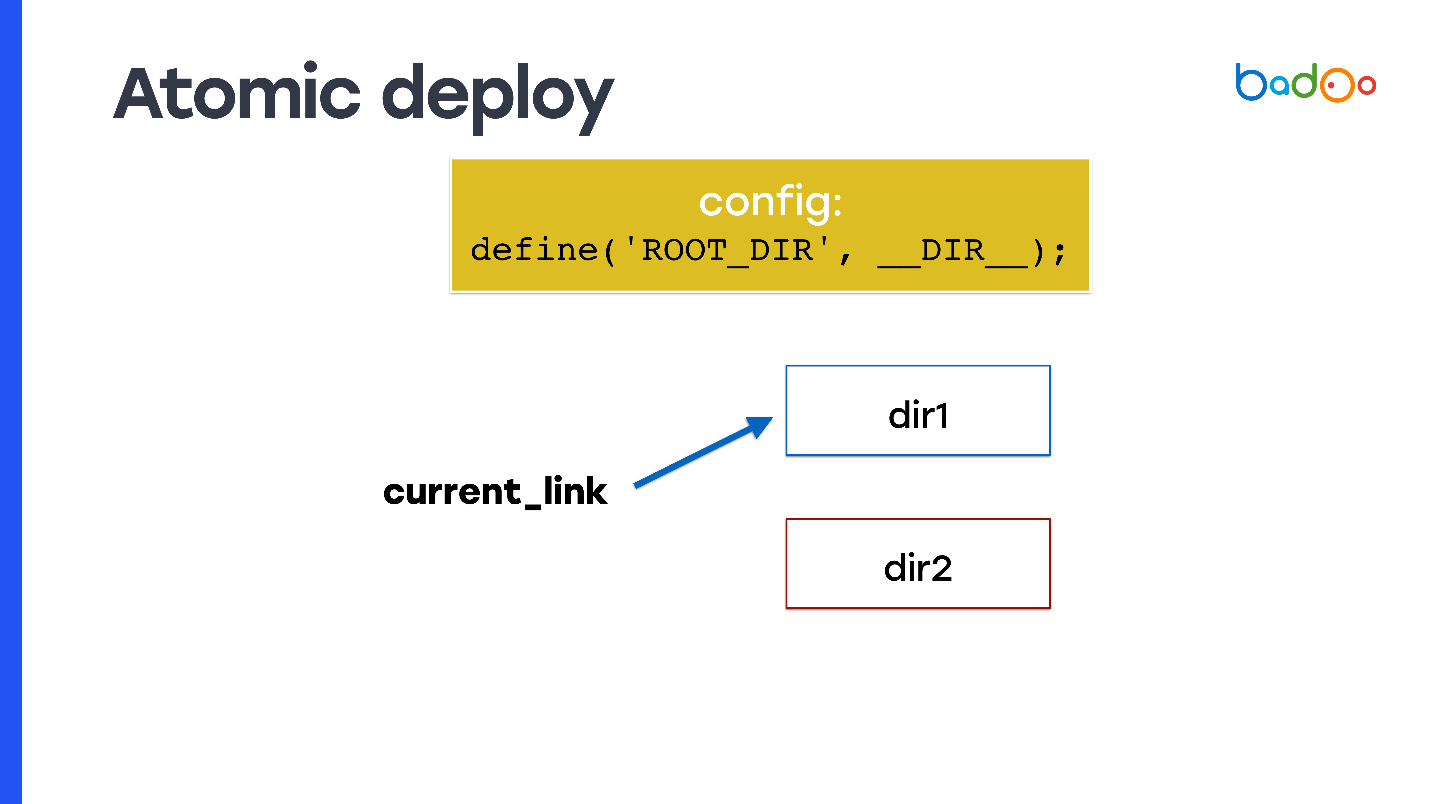
Mais le problème se pose: le code PHP ne sait pas dans quel répertoire il a été lancé. Par conséquent, vous devez utiliser, par exemple, une variable que vous écrirez quelque part au début de la configuration - elle fixera le répertoire à partir duquel le code a été exécuté et à partir de quels nouveaux fichiers doivent être inclus. Sur une diapositive, cela s'appelle
ROOT_DIR .
Utilisez cette constante lors de l'accès à tous les fichiers du code que vous utilisez en production. Vous obtenez donc la propriété atomicity: les demandes qui arrivent avant que vous ayez changé de lien symbolique continuent à inclure des fichiers de l'ancien répertoire dans lesquels vous n'avez rien changé, et les nouvelles demandes qui sont arrivées après le changement de lien symbolique commencent à fonctionner à partir du nouveau répertoire et sont servies nouveau code.

Mais cela doit être écrit dans le code. Tous les projets ne sont pas prêts pour cela.
À la manière de Rasmus
Rasmus suggère au lieu de modifier manuellement le code et de créer des constantes pour modifier légèrement Apache ou utiliser nginx.
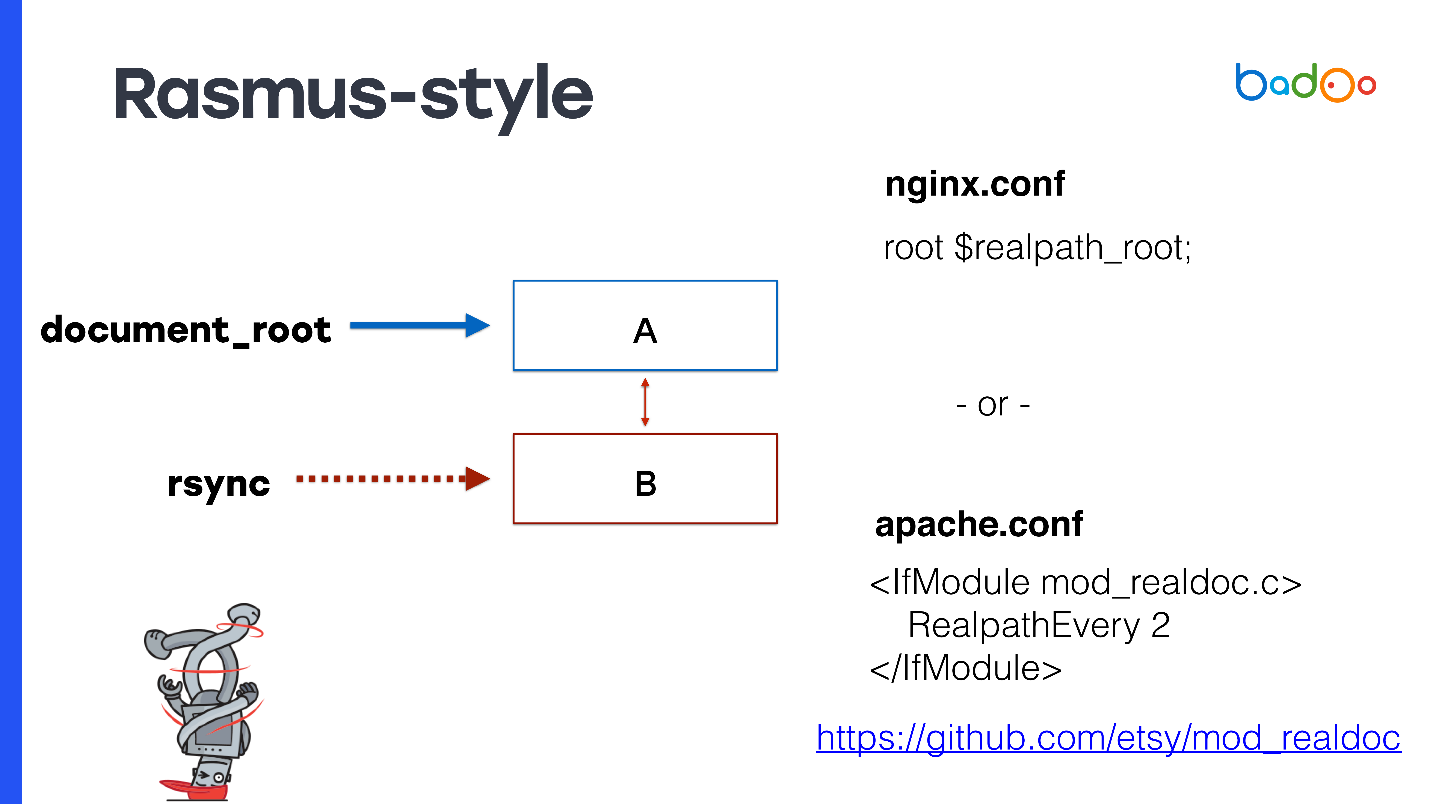
Pour document_root, spécifiez le lien symbolique vers la dernière version. Si vous avez nginx, vous pouvez enregistrer
root $realpath_root , pour Apache, vous aurez besoin d'un module séparé avec les paramètres qui peuvent être vus sur la diapositive. Cela fonctionne comme ceci - lorsqu'une demande arrive, nginx ou Apache de temps en temps considère realpath () du chemin, l'enregistrant à partir des liens symboliques, et passe ce chemin comme document_root. Dans ce cas, document_root pointera toujours vers un répertoire normal sans liens symboliques, et votre code PHP n'aura peut-être pas à penser à quel répertoire il est appelé.
Cette méthode présente des avantages intéressants - de vrais chemins arrivent à OPCache PHP, ils ne contiennent pas de lien symbolique. Même le tout premier fichier auquel la demande est arrivée sera déjà plein et il n'y aura aucun problème avec OPCache. Puisque document_root est utilisé, cela fonctionne avec n'importe quel projet PHP. Vous n'avez rien à adapter.
Il ne nécessite pas de rechargement fpm, il n'est pas nécessaire de réinitialiser OPCache pendant le déploiement, c'est pourquoi le serveur de processeur est très occupé, car il doit à nouveau analyser tous les fichiers. Dans mon expérience, la réinitialisation d'OPCache d'environ une demi-minute a augmenté la consommation du processeur d'un facteur 2 à 3. Ce serait bien de le réutiliser et cette méthode vous permet de le faire.
Maintenant les inconvénients. Comme vous ne réutilisez pas OPCache et que vous avez 2 répertoires, vous devez stocker une copie du fichier en mémoire pour chaque répertoire - sous OPCache, 2 fois plus de mémoire est requise.
Il existe une autre limitation qui peut sembler étrange:
vous ne pouvez pas déployer plus d'une fois tous les max_execution_time . Sinon, le même problème se produira, car pendant que rsync va dans l'un des répertoires, les requêtes peuvent toujours être traitées.
Si vous utilisez Apache pour une raison quelconque, vous avez besoin d'un
module tiers que Rasmus a également écrit.
Rasmus dit que le système est bon et je vous le recommande également. Pour 99% des projets, il convient aussi bien aux nouveaux projets qu'aux projets existants. Mais, bien sûr, nous ne sommes pas comme ça et avons décidé d'écrire notre propre décision.
Nouveau système - MDK
Fondamentalement, nos exigences ne sont pas différentes de celles de la plupart des projets Web. Nous voulons juste un
déploiement rapide sur la mise en scène et la production, une
faible consommation de ressources , la réutilisation d'OPCache et une restauration rapide.
Mais il y a deux autres exigences qui peuvent différer des autres. Tout d'abord, c'est la possibilité d'
appliquer des correctifs de manière atomique . Nous appelons les correctifs des changements dans un ou plusieurs fichiers qui régissent quelque chose sur la production. Nous voulons le faire rapidement. En principe, le système proposé par Rasmus fait face à la tâche de correction.
Nous avons également des
scripts CLI qui peuvent fonctionner pendant plusieurs heures , et ils devraient toujours fonctionner avec une version cohérente du code. Dans ce cas, les solutions ci-dessus, malheureusement, ne nous conviennent pas, ou nous devons avoir beaucoup de répertoires.
Solutions possibles:
- boucle xN (-staging, -docker, -opcache);
- rsync xN (-production, -opcache xN);
- SVN xN (-production, -opcache xN).
Ici N est le nombre de calculs effectués en quelques heures. Nous pouvons en avoir des dizaines, ce qui signifie qu'il faut dépenser une très grande quantité d'espace pour des copies supplémentaires du code.
Par conséquent, nous avons mis au point un nouveau système et l'avons appelé
MDK. Il signifie
Multiversion Deployment Kit , un outil de déploiement multi-version. Nous l'avons fait sur la base des hypothèses suivantes.
Nous avons pris l'architecture de stockage d'arborescence de Git. Nous devons avoir une version cohérente du code dans lequel le script fonctionne, c'est-à-dire que nous avons besoin d'instantanés. Les instantanés sont pris en charge par LVM, mais là, ils sont implémentés de manière inefficace par des systèmes de fichiers expérimentaux comme Btrfs et Git. Nous avons pris la mise en œuvre des instantanés de Git.
Renommé tous les fichiers de file.php en file.php. <version>. Étant donné que tous les fichiers que nous avons sont simplement stockés sur le disque, alors si nous voulons stocker plusieurs versions du même fichier, nous devons ajouter un suffixe avec la version.
J'adore Go, donc pour la vitesse j'ai écrit un système sur Go.Fonctionnement du kit de déploiement multiversion
Nous avons pris l'idée des instantanés de Git. Je l'ai simplifié un peu et je vous explique comment il est implémenté dans MDK.
Il existe deux types de fichiers dans MDK. Le premier est les
cartes. Les images ci-dessous sont marquées en vert et correspondent aux répertoires du référentiel. Le deuxième type est
directement les fichiers, qui se trouvent au même endroit que d'habitude, mais avec un suffixe sous la forme d'une version de fichier. Les fichiers et les cartes sont versionnés en fonction de leur contenu, dans notre cas simplement MD5.
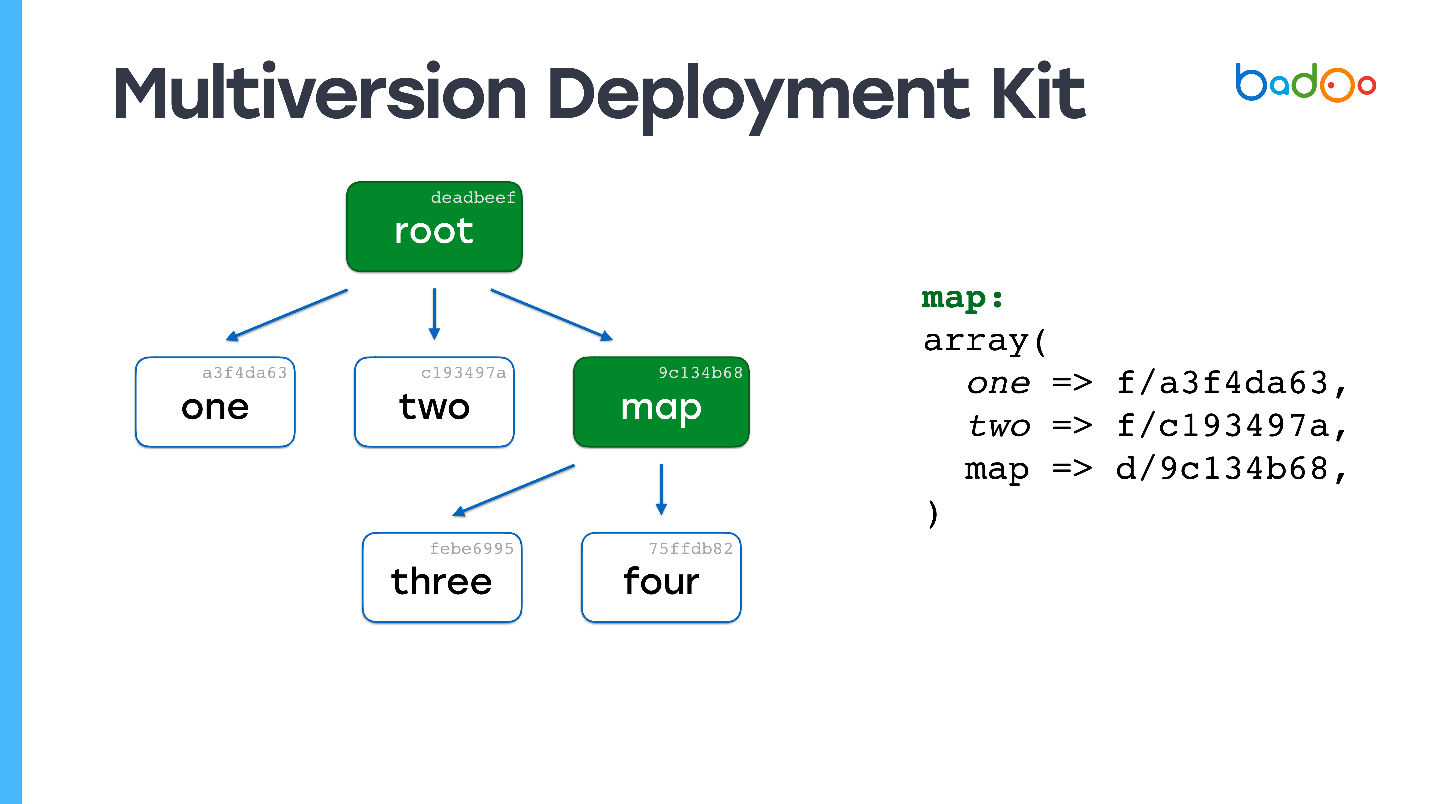
Supposons que nous ayons une hiérarchie de fichiers dans laquelle la
carte racine se réfère à certaines versions de fichiers provenant d'autres cartes , et qu'ils se réfèrent à leur tour à d'autres fichiers et cartes et corrigent certaines versions. Nous voulons changer une sorte de fichier.

Vous avez peut-être déjà vu une image similaire: nous changeons le fichier au deuxième niveau d'imbrication, et dans la carte correspondante - map *, la version du fichier trois * est mise à jour, son contenu est modifié, la version change - et la version change également dans la carte racine. Si nous changeons quelque chose, nous obtenons toujours une nouvelle carte racine, mais tous les fichiers que nous n'avons pas modifiés sont réutilisés.
Les liens restent vers les mêmes fichiers qu'ils étaient. C'est l'idée principale de créer des instantanés de quelque manière que ce soit, par exemple, dans
ZFS, il est implémenté de la même manière.
Comment MDK se trouve sur un disque

Nous avons sur le disque: un
lien symbolique vers la dernière carte racine - le code qui sera servi à partir du Web, plusieurs versions de cartes racine, plusieurs fichiers, éventuellement avec des versions différentes, et dans les sous-répertoires, il y a des cartes pour les répertoires correspondants.
Je prévois la question: "
Et comment cela traite-t-il la demande Web? À quels fichiers le code utilisateur parviendra-t-il? "
Oui, je vous ai trompé - il existe également des fichiers sans version, car si vous recevez une demande pour index.php, et que vous ne l'avez pas dans le répertoire, le site ne fonctionnera pas.

Tous les fichiers PHP ont des fichiers, que nous appelons des
talons , car ils contiennent deux lignes: exigent du fichier dans lequel la fonction qui sait comment travailler avec ces cartes est déclarée, et exigent de la version souhaitée du fichier.
<?php require_once "mdk.inc"; require mdk_resolve_path("a.php");
Ceci est fait ainsi, et non lié à la dernière version, car si vous excluez
b.php du fichier
a.php sans version, alors puisque require_once est écrit, le système se souviendra de la carte racine à partir de laquelle il est parti, il l'utilisera, et Obtenez une version cohérente des fichiers.
Pour le reste des fichiers, nous avons juste un lien symbolique vers la dernière version.
Comment déployer à l'aide de MDK
Le modèle est très similaire à git push.
- Envoyez le contenu de la carte racine.
- Du côté de la réception, nous examinons les fichiers manquants. Étant donné que la version du fichier est déterminée par le contenu, nous n'avons pas besoin de le télécharger une deuxième fois ( Yuri du futur: sauf dans le cas où il y aura une collision d'un MD5 raccourci, qui s'est toujours produit une fois en production ).
- Demandez le fichier manquant.
- Nous passons au deuxième point et plus loin dans un cercle.
Exemple
Supposons qu'il existe un fichier nommé "un" sur le serveur. Envoyez-lui une carte racine.

Dans la carte racine, les flèches en pointillés indiquent des liens vers des fichiers que nous n'avons pas. Nous connaissons leurs noms et versions car ils sont sur la carte. Nous les demandons au serveur. Le serveur envoie et il s'avère que l'un des fichiers est également une carte.
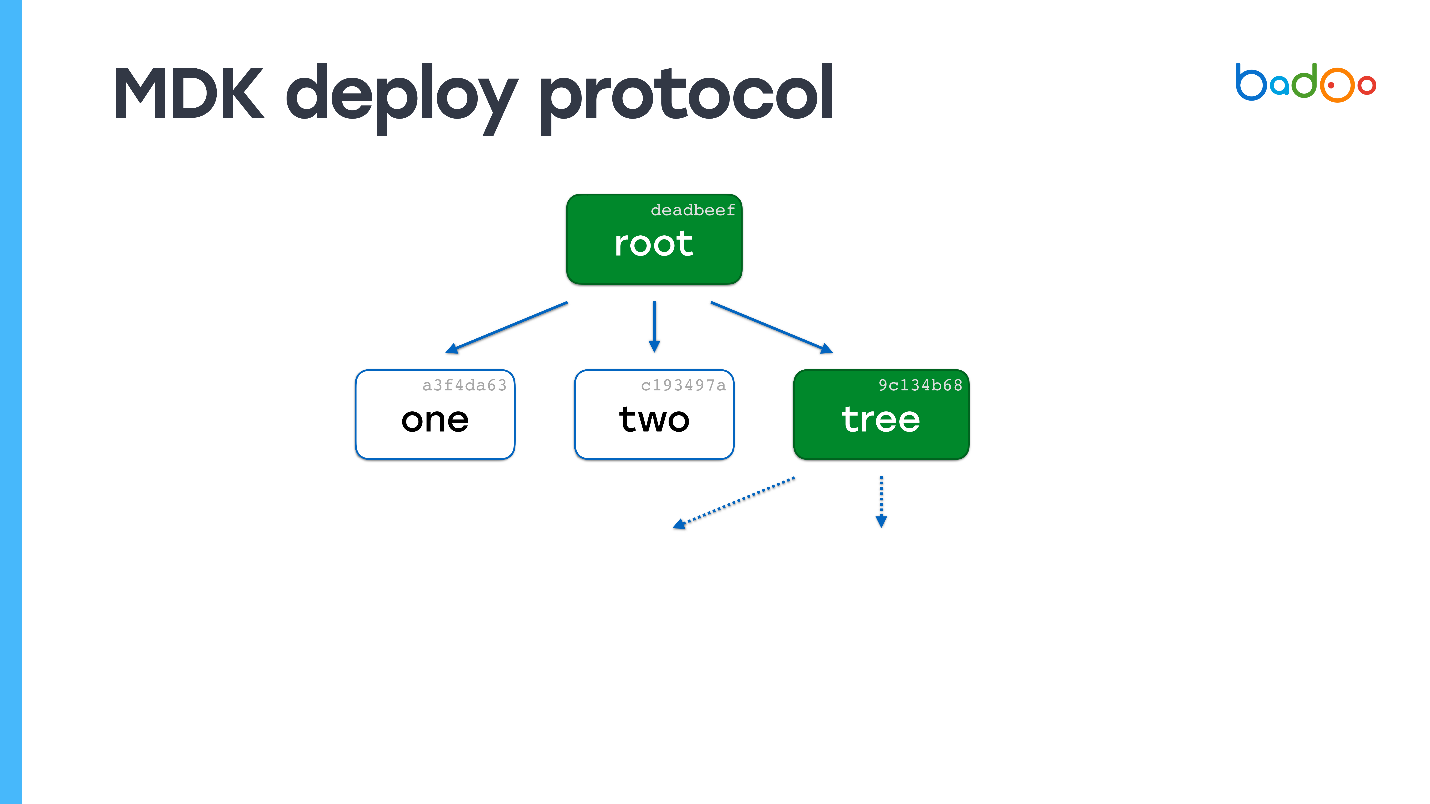
Nous regardons - nous n'avons pas un seul fichier du tout. Encore une fois, nous demandons les fichiers manquants. Le serveur les envoie. Il ne reste plus de cartes - le processus de déploiement est terminé.
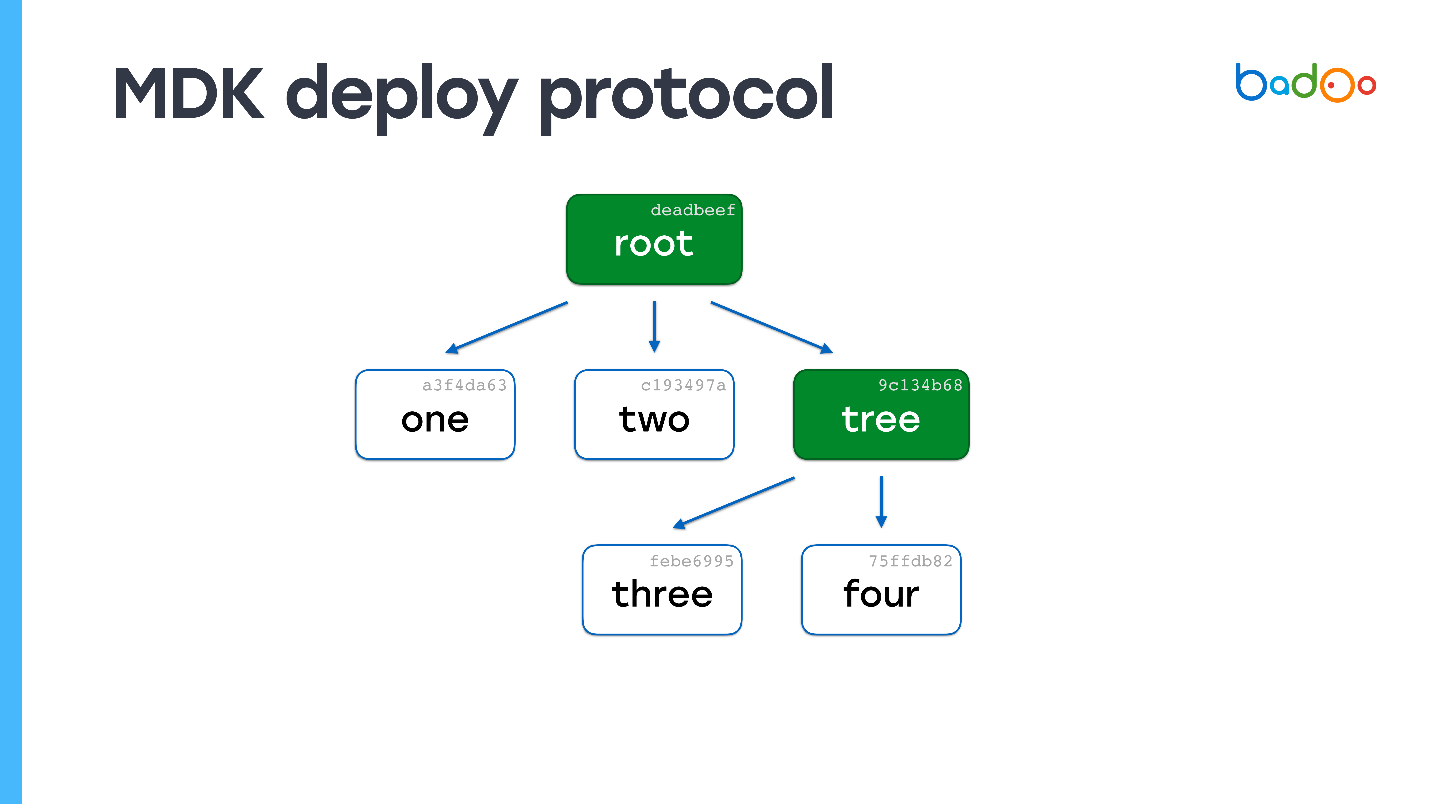
Vous pouvez facilement deviner ce qui se passera si les fichiers sont 150 000, mais l'un a changé. Nous verrons dans la carte racine qu'une carte est manquante, passons par le niveau d'imbrication et obtenons un fichier. En termes de complexité de calcul, le processus n'est pratiquement pas différent de la copie directe de fichiers, mais en même temps la cohérence et les instantanés du code sont préservés.
MDK n'a aucun inconvénient :) Il vous permet de
déployer rapidement et atomiquement de petites modifications , et les
scripts fonctionnent pendant des jours , car nous pouvons laisser tous les fichiers qui ont été déployés en une semaine. Ils occuperont une quantité assez adéquate d'espace. Vous pouvez également réutiliser OPCache et le CPU ne mange presque rien.
Le suivi est assez difficile, mais possible . Tous les fichiers sont versionnés par contenu, et vous pouvez écrire cron, qui parcourra tous les fichiers et vérifiera le nom et le contenu. Vous pouvez également vérifier que la carte racine fait référence à tous les fichiers, qu'il n'y a pas de liens rompus. De plus, pendant le déploiement, l'intégrité est vérifiée.
Vous pouvez
facilement annuler les modifications , car toutes les anciennes cartes sont en place. On peut juste jeter la carte, tout sera là tout de suite.
Pour moi, plus le fait que
MDK soit écrit en Go signifie que cela fonctionne rapidement.
Je vous ai encore trompé, il y a encore des inconvénients. Pour que le projet fonctionne avec le système,
une modification importante du code est nécessaire, mais c'est plus simple qu'il n'y paraît à première vue.
Le système est très complexe , je ne recommanderais pas de l'implémenter si vous n'avez pas des exigences telles que Badoo. De plus, de toute façon, tôt ou tard, l'endroit se termine, donc le
garbage collector est requis .
Nous avons écrit des utilitaires spéciaux pour éditer des fichiers - les vrais, pas les talons, par exemple, mdk-vim. Vous spécifiez le fichier, il trouve la version souhaitée et le modifie.
MDK en chiffres
Nous avons 50 serveurs en transit, sur lesquels nous déployons pendant 3-5 s
. Par rapport à tout sauf rsync, c'est très rapide. En
production, nous déployons environ
2 minutes , de petits correctifs -
5-10 s .
Si, pour une raison quelconque, vous avez perdu le dossier entier avec le code sur tous les serveurs (ce qui ne devrait jamais arriver :)), le
processus de téléchargement complet prend environ 40 minutes . Cela nous est arrivé une fois, mais la nuit avec un minimum de trafic. Par conséquent, personne n'a été blessé. Le deuxième fichier était sur une paire de serveurs pendant 5 minutes, donc cela ne vaut pas la peine d'être mentionné.
Le système n'est pas en Open Source, mais si vous êtes intéressé, écrivez dans les commentaires - il peut être présenté (
Yuri du futur: le système n'est toujours pas en Open Source au moment d'écrire ces lignes ).
Conclusion
Écoutez Rasmus, il ne ment pas . À mon avis, sa méthode rsync avec realpath_root est la meilleure, bien que les boucles fonctionnent également très bien.
Pensez avec votre tête : regardez exactement ce dont votre projet a besoin et n'essayez pas de créer un vaisseau spatial où il y a suffisamment de «maïs». Mais si vous avez encore des exigences similaires, un système similaire à MDK vous conviendra.
Nous avons décidé de revenir sur ce sujet, qui a été discuté sur HighLoad ++ et, peut-être, n'a pas reçu l'attention voulue, car ce n'était qu'une des nombreuses briques pour atteindre des performances élevées. Mais maintenant, nous avons une conférence professionnelle PHP Russie distincte entièrement dédiée à PHP. Et ici, nous nous en sortons vraiment pleinement. Nous parlerons en détail des performances , des normes et des outils - beaucoup à ce sujet, y compris le refactoring .
Abonnez-vous à la chaîne Telegram avec les mises à jour du programme de la conférence et rendez-vous le 17 mai.