Bonjour, Habr!
Nous vous rappelons qu'après le livre sur
Kafka, nous avons publié un travail tout aussi intéressant sur la bibliothèque d'
API Kafka Streams .

Jusqu'à présent, la communauté ne comprend que les limites de cet outil puissant. Ainsi, un article a récemment été publié, dont nous souhaitons vous présenter la traduction. D'après sa propre expérience, l'auteur explique comment créer un entrepôt de données distribué à partir de Kafka Streams. Bonne lecture!
La bibliothèque Apache
Kafka Streams dans le monde est utilisée en entreprise pour le traitement de streaming distribué sur Apache Kafka. L'un des aspects sous-estimés de ce cadre est qu'il vous permet de stocker un état local basé sur le traitement en streaming.
Dans cet article, je vais vous expliquer comment notre entreprise a su exploiter cette opportunité pour développer un produit pour la sécurité des applications cloud. À l'aide de Kafka Streams, nous avons créé des microservices à services partagés, chacun servant de source d'informations fiables et hautement tolérantes aux pannes sur l'état des objets dans le système. Pour nous, c'est un pas en avant en termes de fiabilité et de facilité de support.
Si vous êtes intéressé par une approche alternative qui vous permet d'utiliser une seule base de données centrale pour prendre en charge l'état formel de vos objets - lire, ce sera intéressant ...
Pourquoi nous pensions qu'il était temps de changer nos approches pour travailler avec un état partagéNous devions maintenir l'état de divers objets sur la base des rapports des agents (par exemple: le site a-t-il été attaqué)? Avant de passer à Kafka Streams, nous nous appuyions souvent sur une seule base de données centrale (+ API de service) pour gérer notre état. Cette approche a ses inconvénients: dans
les situations gourmandes en
données, la prise en charge de la cohérence et de la synchronisation devient un véritable défi. La base de données peut devenir un goulot d'étranglement, ou elle peut être en
condition de concurrence et souffrir d'imprévisibilité.
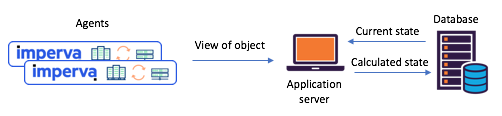 Figure 1: scénario typique à deux états rencontré avant la transition vers
Figure 1: scénario typique à deux états rencontré avant la transition vers
Kafka et Kafka Streams: les agents communiquent leurs soumissions via l'API, le statut mis à jour est calculé via une base de données centraleDécouvrez Kafka Streams - Il est désormais facile de créer des microservices d'état partagésIl y a environ un an, nous avons décidé de revoir en profondeur nos scénarios d'état partagé afin de faire face à de tels problèmes. Nous avons immédiatement décidé d'essayer Kafka Streams - on sait à quel point il est évolutif, hautement disponible et tolérant aux pannes, à quel point sa fonctionnalité de streaming est riche (transformations, y compris celles qui préservent l'état). Juste ce dont nous avions besoin, sans parler de la maturité et de la fiabilité du système de messagerie de Kafka.
Chacun des microservices préservant l'état que nous avons créés a été construit sur la base de l'instance Kafka Streams avec une topologie assez simple. Il se composait de 1) une source 2) un processeur avec un stockage permanent des clés et des valeurs 3) le drain:
 Figure 2: La topologie par défaut de nos instances de streaming pour les microservices avec état. Veuillez noter qu'il existe également un référentiel qui contient les métadonnées de planification.
Figure 2: La topologie par défaut de nos instances de streaming pour les microservices avec état. Veuillez noter qu'il existe également un référentiel qui contient les métadonnées de planification.Avec cette nouvelle approche, les agents composent des messages qui sont soumis au sujet d'origine et les consommateurs - par exemple, un service de notification par courrier - acceptent l'état partagé calculé via le stock (sujet de sortie).
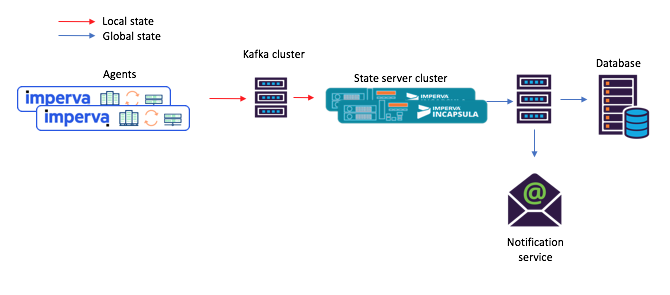 Figure 3: un nouvel exemple de flux de tâches pour un scénario avec des microservices partagés: 1) l'agent génère un message arrivant dans la rubrique Kafka d'origine; 2) un microservice avec un état partagé (en utilisant Kafka Streams) le traite et écrit l'état calculé dans le sujet Kafka final; après quoi 3) les consommateurs acceptent le nouvel étatHé, ce référentiel intégré de clés et de valeurs est en fait très utile!
Figure 3: un nouvel exemple de flux de tâches pour un scénario avec des microservices partagés: 1) l'agent génère un message arrivant dans la rubrique Kafka d'origine; 2) un microservice avec un état partagé (en utilisant Kafka Streams) le traite et écrit l'état calculé dans le sujet Kafka final; après quoi 3) les consommateurs acceptent le nouvel étatHé, ce référentiel intégré de clés et de valeurs est en fait très utile!Comme mentionné ci-dessus, notre topologie à état partagé contient un magasin de clés et de valeurs. Nous avons trouvé plusieurs options pour son utilisation, et deux d'entre elles sont décrites ci-dessous.
Option 1: utiliser le magasin de clés et le magasin de valeurs pour les calculsNotre premier référentiel de clés et de valeurs contenait des données auxiliaires dont nous avions besoin pour les calculs. Par exemple, dans certains cas, l'État partagé a été déterminé sur la base d'un principe de «vote majoritaire». Dans le référentiel, il était possible de conserver tous les derniers rapports d'agent sur l'état d'un certain objet. Ensuite, en recevant un nouveau rapport d'un agent, nous pourrions l'enregistrer, extraire des rapports de tous les autres agents sur l'état du même objet du référentiel et répéter le calcul.
La figure 4 ci-dessous montre comment nous avons ouvert l'accès à la clé et au magasin de valeurs à la méthode de traitement du processeur, afin que nous puissions ensuite traiter le nouveau message.
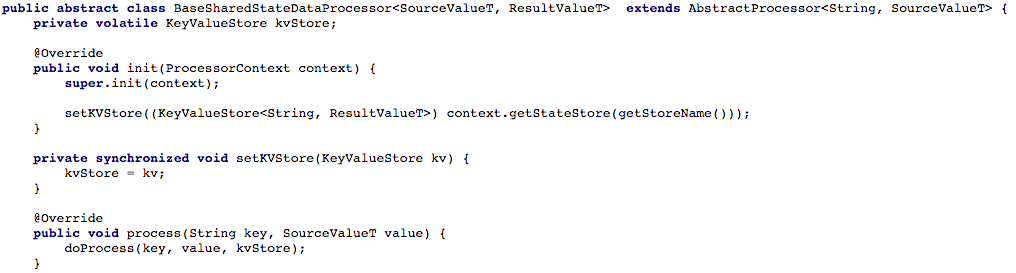 Figure 4: nous ouvrons l'accès au stockage des clés et des valeurs pour la méthode de traitement du processeur (après cela, dans chaque script travaillant avec un état partagé, vous devez implémenter la méthode
Figure 4: nous ouvrons l'accès au stockage des clés et des valeurs pour la méthode de traitement du processeur (après cela, dans chaque script travaillant avec un état partagé, vous devez implémenter la méthode doProcess )Option n ° 2: création d'une API CRUD au-dessus de Kafka StreamsAprès avoir ajusté notre flux de tâches de base, nous avons commencé à essayer d'écrire une API CREST RESTful pour nos microservices à service partagé. Nous voulions pouvoir extraire l'état de tout ou partie des objets, ainsi que définir ou supprimer l'état de l'objet (ceci est utile avec le support côté serveur).
Pour prendre en charge toutes les API Get State, chaque fois que nous devions recalculer l'état pendant le traitement, nous le plaçons dans le référentiel intégré de clés et de valeurs pendant une longue période. Dans ce cas, il devient assez simple d'implémenter une telle API en utilisant une seule instance de Kafka Streams, comme indiqué dans la liste ci-dessous:
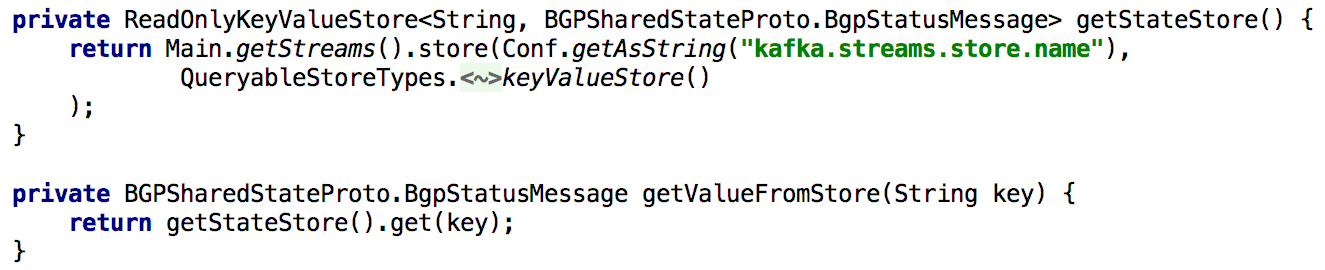 Figure 5: utilisation du stockage intégré des clés et des valeurs pour obtenir l'état précalculé d'un objet
Figure 5: utilisation du stockage intégré des clés et des valeurs pour obtenir l'état précalculé d'un objetLa mise à jour de l'état d'un objet via l'API est également facile à mettre en œuvre. En principe, pour cela, il vous suffit de créer un producteur Kafka et, avec son aide, de créer un disque dans lequel un nouvel état est créé. Cela garantit que tous les messages générés via l'API seront traités de la même manière que ceux reçus d'autres producteurs (par exemple, des agents).
 Figure 6: Vous pouvez définir l'état d'un objet à l'aide du producteur KafkaUne complication mineure: Kafka a de nombreuses partitions.
Figure 6: Vous pouvez définir l'état d'un objet à l'aide du producteur KafkaUne complication mineure: Kafka a de nombreuses partitions.Ensuite, nous voulions répartir la charge de traitement et améliorer la disponibilité en fournissant un cluster de microservices à service partagé pour chaque scénario. La configuration nous a été donnée aussi simple que possible: après avoir configuré toutes les instances pour qu'elles fonctionnent avec le même ID d'application (et avec les mêmes serveurs de démarrage), presque tout le reste s'est fait automatiquement. Nous avons également défini que chaque rubrique source sera composée de plusieurs partitions, afin que chaque instance puisse se voir attribuer un sous-ensemble de ces partitions.
Je mentionnerai également qu'il est normal de faire une copie de sauvegarde du magasin d'état, de sorte que, par exemple, en cas de récupération après un échec, transférez cette copie vers une autre instance. Pour chaque magasin d'état dans Kafka Streams, une rubrique répliquée est créée avec un journal des modifications (dans lequel les mises à jour locales sont suivies). Ainsi, Kafka sécurise constamment le magasin d'État. Par conséquent, en cas de défaillance de l'une ou l'autre instance de Kafka Streams, le magasin d'état peut être rapidement restauré vers une autre instance, où iront les partitions correspondantes. Nos tests ont montré que cela peut être fait en quelques secondes même s'il y a des millions d'enregistrements dans le référentiel.
Passer d'un microservice de services partagés à un cluster de microservices, il devient moins trivial d'implémenter l'API Get State. Dans la nouvelle situation, le référentiel d'état de chaque microservice ne contient qu'une partie de l'image globale (les objets dont les clés ont été mappées sur une partition particulière). Nous avons dû déterminer sur quelle instance l'état de l'objet dont nous avions besoin était contenu, et nous l'avons fait en fonction des métadonnées de flux, comme indiqué ci-dessous:
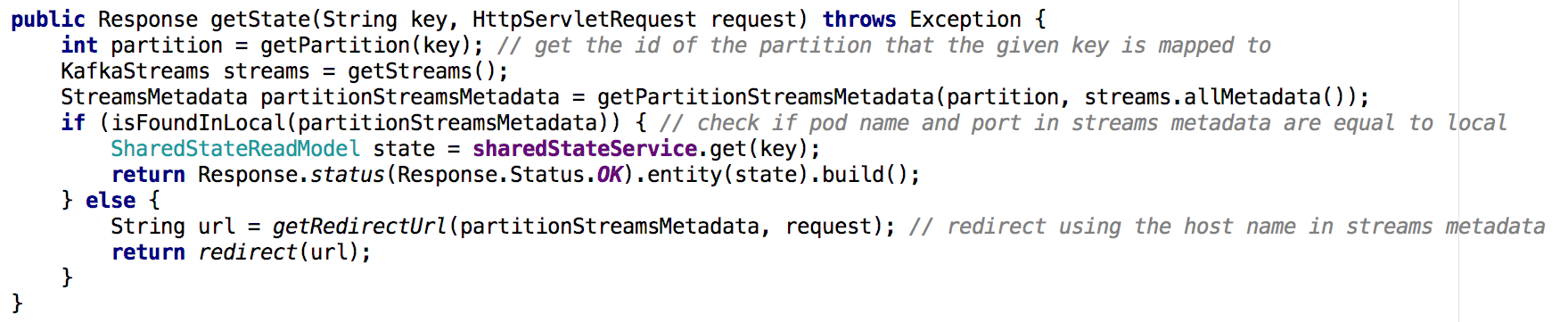 Figure 7: à l'aide de métadonnées de flux, nous déterminons à partir de quelle instance demander l'état de l'objet souhaité; une approche similaire a été utilisée avec l'API GET ALLConstatations clés
Figure 7: à l'aide de métadonnées de flux, nous déterminons à partir de quelle instance demander l'état de l'objet souhaité; une approche similaire a été utilisée avec l'API GET ALLConstatations clésLes magasins d'État de Kafka Streams peuvent, de facto, servir de base de données distribuée,
- reproduit en continu dans kafka
- En plus d'un tel système, il est facile de créer une API CRUD
- Le traitement de plusieurs partitions est un peu plus compliqué
- Il est également possible d'ajouter un ou plusieurs magasins d'état à la topologie de flux pour stocker des données auxiliaires. Cette option peut être utilisée pour:
- Stockage à long terme des données nécessaires aux calculs dans le traitement en streaming
- Stockage à long terme de données pouvant être utiles la prochaine fois que l'instance de flux est initialisée
- bien plus ...
Grâce à ces avantages et à d'autres, Kafka Streams est idéal pour prendre en charge le statut mondial dans un système distribué comme le nôtre. Kafka Streams s'est avéré très fiable en production (dès le moment de son déploiement, nous n'avons pratiquement pas perdu de messages), et nous sommes sûrs que cela ne se limite pas à ses capacités!