Eh bien, nous savons déjà tout ce dont vous avez besoin pour programmer UDB. Mais c'est une chose à savoir et une autre à savoir. Par conséquent, nous discuterons aujourd'hui où et comment s'inspirer pour améliorer nos propres compétences, où acquérir de l'expérience. Comme le montre la
traduction de la documentation , il existe des connaissances sèches qui ne sont pas toujours liées à la pratique réelle (j'y ai attiré l'attention dans une note assez longue, à la dernière traduction à ce jour). En fait, les statistiques des vues d'articles montrent que de moins en moins de personnes lisent les traductions. Il a même été proposé d'interrompre ce cycle, comme inintéressant, mais il ne restait que deux parties, par conséquent, il a finalement été décidé de réduire le rythme de leur préparation. En général, la documentation du contrôleur est une chose nécessaire, mais pas autosuffisante. Où trouver l'inspiration?

Tout d'abord, je peux recommander l'excellent document
AN82156 Designing PSoC Creator Components with UDB Datapaths . Vous y trouverez des solutions typiques, ainsi que plusieurs projets standard. De plus, au début du document, le développement est effectué à l'aide de l'éditeur UDB, et vers la fin, à l'aide de Datapath Config Tool, c'est-à-dire que le document couvre tous les aspects du développement. Mais malheureusement, en regardant le prix d'une seule puce PSoC, je dirais que si cela ne peut résoudre que les problèmes décrits dans ce document, le contrôleur est largement surévalué. Les PWM et les ports série standard peuvent être réalisés sans PSoC. Heureusement, l'éventail des tâches PSoC est beaucoup plus large. Par conséquent, après avoir terminé la lecture de l'AN82156, nous commençons à chercher d'autres sources d'inspiration.
La prochaine source utile est les exemples fournis avec PSoC Creator. Je les ai déjà mentionnés dans une note à l'une des parties de la traduction de la documentation de l'entreprise (vous pouvez voir
ici ). Ils sont stockés approximativement ici (le disque peut différer):
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ psoc \ content \ CyComponentLibrary.
Vous devez rechercher les fichiers * .v, c'est-à-dire les textes verilog ou * .vhd, car la syntaxe du langage VHDL nécessite un peu plus d'être décrite, et dans ce langage, vous pouvez parfois trouver des nuances intéressantes cachées aux yeux du programmeur chez Verilog. Le problème est que ce ne sont pas des exemples, mais des solutions toutes faites. C'est merveilleux, ils sont parfaitement débogués, mais nous, simples programmeurs, avons des objectifs différents avec les programmeurs Cypress. Notre tâche est de faire quelque chose d'auxiliaire en peu de temps, après quoi nous commençons à l'utiliser dans nos projets, qui seront consacrés la plupart de notre temps. Il devrait idéalement résoudre les tâches qui nous sont assignées aujourd'hui, et si demain nous voulons insérer le même code dans un autre projet, où tout sera légèrement différent, alors demain nous le terminerons dans cette situation. Pour les développeurs Cypress, le composant est le produit final, ils peuvent donc y passer la plupart du temps. Et ils doivent prévoir tout-tout-tout. Alors quand j'ai regardé ces textes, je me suis sentie triste. Ils sont trop complexes pour quelqu'un qui vient de commencer à chercher où puiser l'inspiration pour ses premiers développements. Mais comme références, ces textes sont tout à fait appropriés. De nombreux designs précieux sont nécessaires pour créer vos propres objets.
Il y a aussi des coins très intéressants. Par exemple, il y a, maintenant je dirai dans le style de "l'huile de beurre", des modèles pour la modélisation (il y a longtemps, un professeur sévère m'a découragé de traduire la simulation d'une autre manière que la "modélisation"). Ils se trouvent dans le catalogue.
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim.
Le répertoire le plus intéressant pour le programmeur sur Verilogue est:
E: \ Program Files (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim \ presynth \ vlg.
La description des composants dans la documentation est bonne. Mais les modèles de comportement pour tous les composants standard sont décrits ici. Parfois, c'est mieux que la documentation (qui est écrite dans un langage lourd, et certains détails essentiels sont omis). Lorsque le comportement de tel ou tel composant n'est pas clair, il vaut la peine de commencer à essayer de le comprendre précisément en affichant les fichiers de ce répertoire. Au début, j'ai essayé de rechercher sur Google, mais très souvent, je ne rencontrais sur les forums trouvés que des raisonnements et pas de détails. Voici précisément les détails.
Néanmoins, le livre de référence est merveilleux, mais où chercher un manuel, de quoi apprendre? Honnêtement, il n'y a rien de spécial. Il n'y a pas beaucoup de bons exemples prêts à l'emploi pour l'éditeur UDB. J'ai eu beaucoup de chance que lorsque j'ai soudainement décidé de jouer aux LED RGB, je suis tombé sur un bel exemple sous l'éditeur UDB (j'ai écrit à ce sujet dans l'
article qui a commencé tout le cycle). Mais si vous travaillez beaucoup avec un moteur de recherche, il y aura toujours des exemples pour l'outil de configuration de Datapath, c'est pourquoi j'ai fait l'
article précédent pour que tout le monde comprenne comment utiliser cet outil. Et une merveilleuse page sur laquelle de nombreux exemples sont collectés se trouve
ici .
Sur cette page sont des développements réalisés par des développeurs tiers, mais vérifiés par Cypress. C'est exactement ce dont nous avons besoin: nous sommes également des développeurs tiers, mais nous voulons apprendre de quelque chose qui est vérifié avec précision. Regardons un exemple où j'ai trouvé cette page - une calculatrice matérielle à racine carrée. Les utilisateurs finaux l'incluent dans le chemin de traitement du signal, jetant un composant sur le circuit. Dans cet exemple, nous nous entraînerons à analyser un code similaire, puis tout le monde pourra commencer la natation indépendante. Ainsi, l'exemple nécessaire peut être téléchargé à partir du
lien .
Nous l'examinons. Il existe des exemples (que tout le monde considérera indépendamment) et il y a des bibliothèques situées dans le répertoire \ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib.
Pour chaque type (entier ou virgule fixe) et pour chaque bit, il existe une solution. Cela doit être noté. La polyvalence est bonne lors du développement dans l'éditeur UDB, mais lors du développement à l'aide de l'outil d'édition de Datapath, comme vous pouvez le voir, les gens sont tourmentés comme ça. N'ayez pas peur si vous ne pouvez pas le faire universellement (mais si cela fonctionne mieux).
Au niveau supérieur (circuits), je ne m'arrêterai pas, nous étudions non pas avec PSoC, mais avec UDB. Examinons une option de complexité moyenne - 16 bits, mais entier. Il se trouve dans le répertoire CJCU_B_Isqrt16_v1_0.
La première chose à faire est d'étendre le graphique de transition du firmware. Sans cela, nous ne devinerons même pas quel type d'algorithme de racine carrée a été appliqué, car Google propose un choix de plusieurs algorithmes fondamentalement différents.
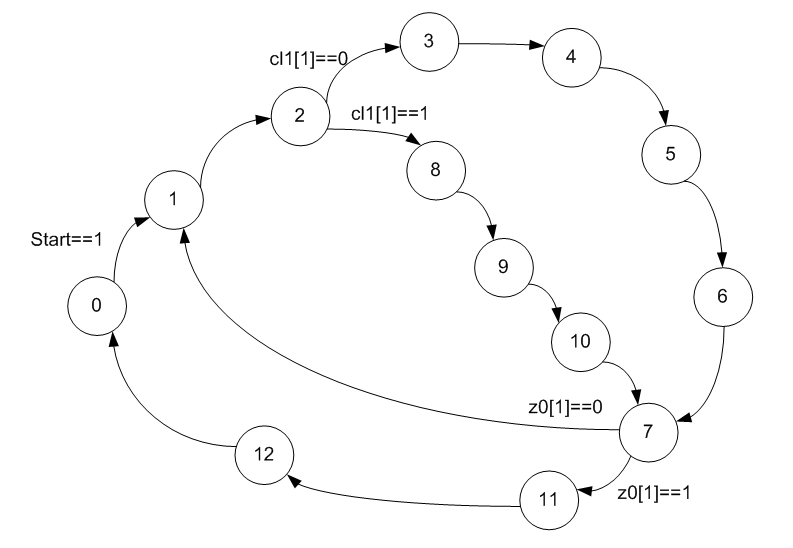
Jusqu'à présent, rien n'est clair, mais c'est prévisible. Besoin d'ajouter plus d'informations. Nous examinons le codage d'état. Il est frappant de constater qu'ils ne sont pas codés dans le code binaire incrémentiel habituel.

J'ai déjà mentionné cette approche dans mes articles, mais je n'ai jamais pu l'utiliser dans des exemples spécifiques. Permettez-moi de vous rappeler que la configuration dynamique RAM ALU n'a que trois entrées d'adresse. Autrement dit, ALU peut effectuer l'une des huit opérations. Si l'automate a plus d'états, alors la règle «chaque état a son propre fonctionnement» devient impossible. Par conséquent, des états sont sélectionnés dans lesquels les opérations pour l'ALU sont identiques, ils ont trois bits fournis à l'adresse RAM de la configuration dynamique (généralement de faible ordre), ils sont codés de la même manière et le reste de différentes manières. Comment ajouter un tel solitaire est déjà un problème de développeur. Les développeurs du code étudié se sont pliés exactement comme indiqué ci-dessus.
Ajoutez ces informations au graphique et coloriez les états qui exécutent la même fonction dans ALU dans des couleurs similaires.
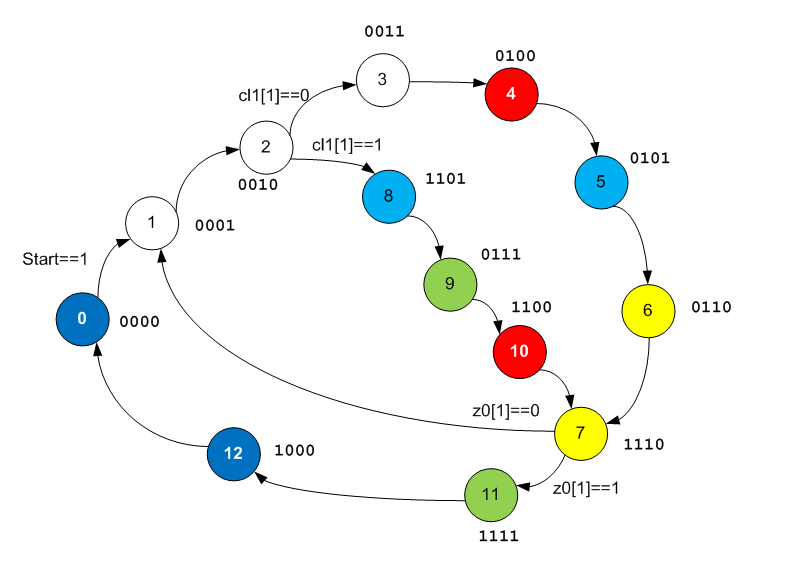
Aucun modèle ne s'est encore manifesté, mais nous continuons d'ouvrir le graphique. Nous ouvrons Datapath Edit Tool et nous y étudions déjà la logique.
Veuillez noter que nous avons deux blocs Datapath connectés en chaîne. Lorsque nous faisons quelque chose de nous-mêmes, nous pouvons également en avoir besoin (cependant, l'outil d'édition de Datapath peut créer des blocs déjà liés dans une chaîne, donc ce n'est pas effrayant):
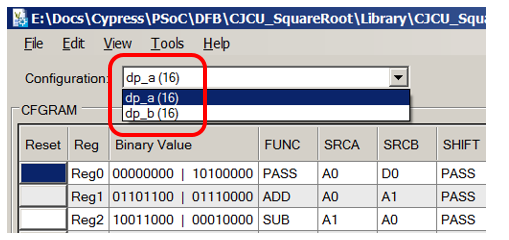
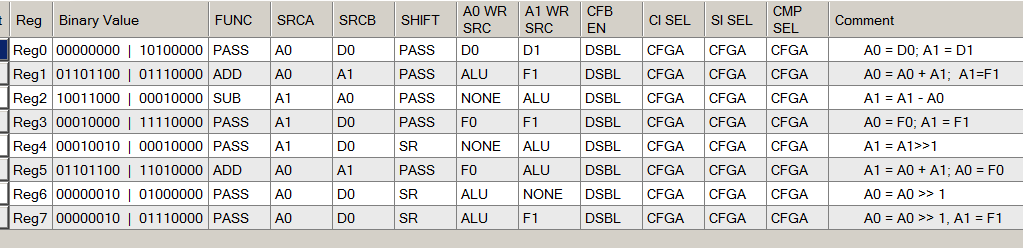
Lors de la lecture (et du remplissage) du graphique correspondant à ALU, nous ouvrons toujours un document avec la figure suivante:

Certes, les développeurs de cet exemple ont pris soin de nous et ont rempli les champs de commentaires. Nous pouvons maintenant les utiliser pour comprendre ce qui est configuré. Dans le même temps, nous constatons pour nous-mêmes que la rédaction de commentaires est toujours utile à la fois pour ceux qui accompagneront le code, et pour nous, quand dans six mois nous oublierons tout.
Nous regardons le code X000 correspondant aux états 0 et 12:

D'après le commentaire, il est déjà clair ce qui se passe là-bas (le contenu du registre D0 est copié dans le registre A0, et le contenu de D1 est copié dans le registre A1. Sachant cela, nous formons notre intuition pour l'avenir et trouvons une entrée similaire dans les champs de paramètres:

Là, nous voyons que l'ALU fonctionne en mode
PASS , le registre à décalage est également
PASS , de sorte qu'aucune autre action n'est réellement effectuée.
En chemin, nous regardons le texte dans Verilog et voyons où la valeur des registres D0 et D1 est égale:

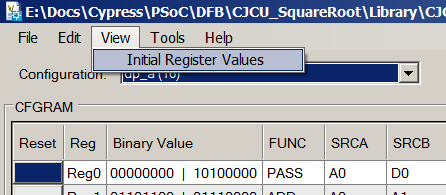
Si vous le souhaitez, la même chose peut être vue dans Datapath Config Tool, en choisissant View-> Initial Register Values:
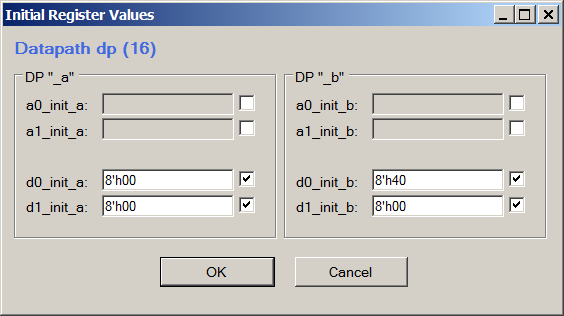
Pour la visualisation, il est plus pratique d'analyser directement le code Verilog, de créer votre propre version - travaillez via l'éditeur afin de ne pas garder la syntaxe à l'esprit.
De même, nous analysons (d'abord, en lisant dans les commentaires) toutes les autres fonctions d'ALU:
Nous refaisons le graphe de transition de l'automate en tenant compte des nouvelles connaissances:

Quelque chose se profile déjà, mais jusqu'à présent, je ne peux mettre en confiance aucun des algorithmes trouvés par Google sur ce graphique. Au contraire, à propos de certains, vous pouvez dire avec certitude que ce n'est pas eux, mais même pour le crédible, je ne peux toujours pas répondre avec certitude que ce sont eux. Confond l'utilisation active des registres FIFO F0 et F1. Généralement dans le dossier
\ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib \ CJCU_Isqrt_v1_0 \ API \ CJCU_Isqrt.c
on peut voir que F1 est utilisé pour passer l'argument et retourner le résultat:

Même texte:void `$INSTANCE_NAME`_ComputeIsqrtAsync(uint`$regWidth` square) { /* Set up FIFOs, start the computation. */ CY_SET_REG`$dpWidth`(`$INSTANCE_NAME`_F1, square); CY_SET_REG8(`$INSTANCE_NAME`_CTL, 0x01); } … uint`$resultWidth` `$INSTANCE_NAME`_ReadIsqrtAsync() { /* Read back result. */ return CY_GET_REG`$dpWidth`(`$INSTANCE_NAME`_F1); }
Mais un argument et un résultat. Et pourquoi y a-t-il tant d'appels au FIFO en cours de travail? Et qu'est-ce que FIFO0 a à voir avec ça? Coupez-moi en morceaux, mais il semble que les auteurs aient profité du mode que l'on rencontrait dans les traductions de la documentation, alors qu'au lieu d'un FIFO à part entière, ce bloc faisait office de registre unique. Supposons que les auteurs aient décidé d'élargir l'ensemble de registres. Si oui, alors leur méthodologie nous sera utile dans nos travaux pratiques, étudions les détails. En fait, la documentation parle de différentes approches pour travailler avec FIFO. Vous pouvez - ainsi, vous pouvez - ainsi, mais vous pouvez - en quelque sorte. Et pas de détails. Encore une fois, nous avons la chance de découvrir les meilleures pratiques internationales. Que font les auteurs avec FIFO?
Tout d'abord, ce sont les affectations de signaux:
wire f0_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_4); wire f1_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_3 || state == B_SQRT_STATE_9 || state == B_SQRT_STATE_11); wire fifo_dyn = (state == B_SQRT_STATE_0 || state == B_SQRT_STATE_12);
Deuxièmement, voici une connexion à Datapath:
/* input */ .f0_load(f0_load), /* input */ .f1_load(f1_load), /* input */ .d0_load(1'b0), /* input */ .d1_load(fifo_dyn),
D'après la description du contrôleur, il n'est pas particulièrement clair ce que tout cela signifie. Mais à partir de la note d'application, j'ai découvert que ce paramètre est à blâmer pour tout:

Soit dit en passant, précisément en raison de ce paramètre, ce bloc ne peut pas être décrit à l'aide de l'éditeur UDB. Lorsque ces bits de contrôle sont à l'état
ON , FIFO peut fonctionner sur différentes sources et récepteurs. Si
Dx_LOAD est égal à un, alors
Fx échange avec le bus système, s'il est nul, alors avec le registre sélectionné ici:

Il s'avère que F0 échange toujours avec le registre A0, et F1 dans les états 12 et 0 - avec le bus système (pour télécharger le résultat et charger l'argument), dans les autres états - avec A1.
De plus, à partir du code Verilog, nous avons découvert que dans F0 les données seront chargées dans les états 1 et 4, et dans F1 - dans les états 1, 3, 9, 11.
Ajoutez les connaissances acquises au graphique. Afin d'éviter toute confusion lors de la séquence des opérations, il était également temps de remplacer la marque d'affectation «a la UDB Editor» par des flèches Verilog, pour souligner que la source est la valeur du signal qu'il avait avant d'entrer dans le bloc.

Du point de vue de l'analyse de l'algorithme, tout est déjà clair. Nous avons devant nous une modification d'un tel algorithme:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 30; // The second-to-top bit is set: use 1u << 14 for uint16_t type; use 1uL<<30 for uint32_t type // "one" starts at the highest power of four <= than the argument. while (one > op) { one >>= 2; } while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Ce n'est que par rapport à notre système qu'il ressemblera davantage à ceci:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 14; // The second-to-top bit is set while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Les états 4 et 10 codent explicitement la chaîne:
res >>= 1;
pour différentes branches.
La ligne est:
one >>= 2;
il est explicitement codé soit par une paire d'états 6 et 7, soit par une paire d'états 9 et 7. Pour l'instant, je veux m'exclamer: "Eh bien, les inventeurs sont les mêmes auteurs!", mais très bientôt, il deviendra clair pourquoi il y a une telle difficulté avec deux branches (dans le code C il y a une branche et solution de contournement).
L'état 2 code une branche conditionnelle. L'état 7 code une instruction de boucle. L'opération de comparaison à l'étape 2 est très coûteuse. En général, dans la plupart des étapes, le registre A0 contient la variable un. Mais à l'étape 1, la variable one est déchargée dans F0, et à la place la valeur de
res + one est chargée, puis à l'étape 2 la soustraction est effectuée à des fins de comparaison, et aux étapes 3 et 8, la valeur de
one est restaurée. Pourquoi, à l'étape 4, A0 est à nouveau copié dans F0, je n'ai pas compris. C'est peut-être une sorte de rudiment.
Reste à savoir qui est
res et qui est
op . Nous savons que la condition compare op et res + one. Dans l'état 1, A0 (
un ) et A1 sont ajoutés. Donc, A1 est
res . Il s'avère que dans l'état 11 A1 est également
res , et c'est lui qui entre en F1, qui est alimenté en sortie de la fonction. F1 dans l'état 1 est clairement
op . Je propose d'introduire la différenciation des couleurs du
pantalon des variables. Nous désignons
res comme rouge,
op comme vert et
un comme marron (pas tout à fait contrasté, mais les autres couleurs sont encore moins contrastées).
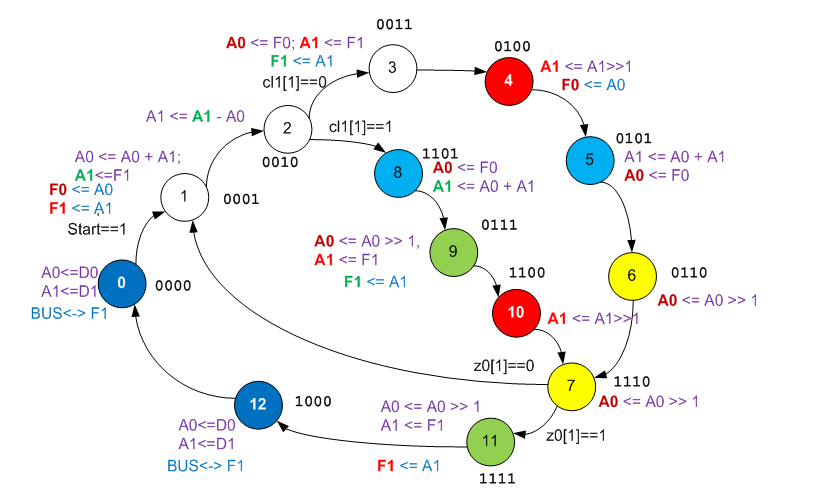
En fait, toute la vérité est révélée. Nous voyons comment A1 change temporairement de F1 pour effectuer des comparaisons et des calculs, comment la même différence est utilisée à la fois pour la comparaison (en fait, générer le bit C) et pour participer à la formule. On voit même pourquoi l'espace vide (bypass) dans l'algorithme C est encodé par une longue branche du graphe de transition de l'automate (dans cette branche, les registres sont échangés identiques à l'échange intervenant dans la branche principale du code). Nous voyons tout.
La seule question qui ne cesse de me tourmenter est de savoir comment les auteurs ont fait passer FIFO en mode mono-octet? La documentation indique que pour cela, vous devez augmenter les bits CLR dans le registre de contrôle auxiliaire en une unité, mais je ne vois pas que l'API a de tels enregistrements. Peut-être que quelqu'un va comprendre cela et écrire dans les commentaires.
Eh bien, et de développer quelque chose qui leur est propre - dans l'ordre inverse, en utilisant les compétences acquises.
Conclusion
Pour développer les compétences de développement de «firmware» basés sur UDB, il est utile non seulement de lire la documentation, mais aussi de s'inspirer des conceptions d'autres personnes. Le code fourni avec PSoC Creator peut être utile comme référence, et les modèles de comportement inclus avec le compilateur vous aideront à mieux comprendre ce que signifiait la documentation. L'article fournit également un lien vers un ensemble d'exemples de fabricants tiers et montre le processus d'analyse d'un de ces exemples.
Sur ce point, le cycle des articles protégés par le droit d'auteur sur l'utilisation de l'UDB peut être considéré comme achevé. Je serais heureux s'il aidait quelqu'un à acquérir des connaissances utiles dans la pratique. Il y a quelques traductions de documentation à venir, mais les statistiques montrent que presque personne ne les lit. Ils sont planifiés proprement afin de ne pas laisser tomber le sujet en bref.