Dans le processus de transition d'une application monolithique vers une architecture de microservices, nous sommes confrontés à de nouveaux problèmes.
Dans une application monolithique, il est généralement assez simple de déterminer dans quelle partie du système une erreur s'est produite. Très probablement, le problème est dans le code du monolithe lui-même ou dans la base de données. Mais lorsque nous commençons à chercher un problème dans l'architecture de microservices, tout n'est pas si évident. Vous devez trouver le chemin complet parcouru par la demande du début à la fin, pour la sélectionner parmi des centaines de microservices. De plus, beaucoup d'entre eux ont également leurs propres référentiels, ce qui peut également provoquer des erreurs logiques, ainsi que des problèmes de performances et de tolérance aux pannes.

Pendant longtemps, je cherchais un outil qui aiderait à faire face à de tels problèmes (j'en ai écrit sur Habré: 1 , 2 ), mais au final j'ai fait ma propre solution open source. Dans l'article, je parle des avantages de l'approche du maillage de service et partage un nouvel outil pour sa mise en œuvre.
Le traçage distribué est une solution courante au problème de la recherche d'erreurs dans les systèmes distribués. Mais que se passe-t-il si le système n'a pas encore mis en œuvre une telle approche pour collecter des informations sur les interactions réseau, ou pire, dans la partie du système, il fonctionne déjà correctement, et dans la partie non, car il n'est pas ajouté aux anciens services? Pour déterminer la cause racine exacte du problème, vous devez avoir une image complète de ce qui se passe dans le système. Il est particulièrement important de comprendre quels microservices sont impliqués dans les principaux chemins critiques de l'entreprise.
Ici, une approche de maillage de service peut venir à notre aide, qui traitera de toutes les machines pour collecter des informations sur le réseau à un niveau inférieur à celui des services eux-mêmes. Cette approche nous permet d'intercepter tout le trafic et de l'analyser à la volée. De plus, les applications à ce sujet ne devraient même rien savoir.
Approche du maillage de service
L'idée principale de l'approche du maillage de service est d'ajouter une autre couche d'infrastructure sur le réseau, ce qui nous permettra de faire des choses avec l'interaction interservices. La plupart des implémentations fonctionnent comme suit: un conteneur sidecar supplémentaire avec un proxy transparent est ajouté à chaque microservice, à travers lequel tout le trafic de service entrant et sortant est transmis. Et c'est ici que nous pouvons effectuer l'équilibrage des clients, appliquer des politiques de sécurité, introduire des restrictions sur le nombre de demandes et collecter des informations importantes sur l'interaction des services en production.
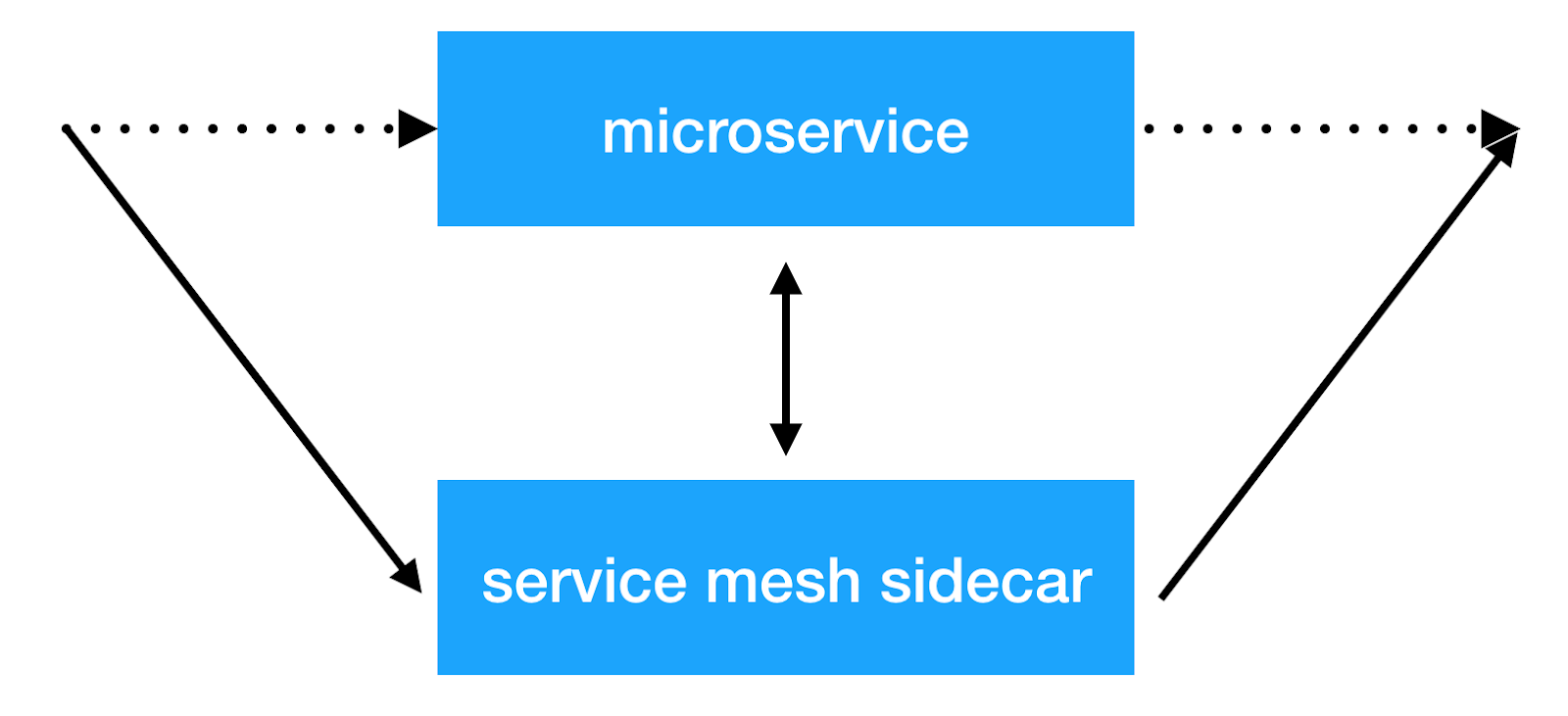
Des solutions
Il existe déjà plusieurs implémentations de cette approche: Istio et linkerd2 . Ils offrent de nombreuses fonctionnalités prêtes à l'emploi. Mais en même temps un gros frais généraux vient aux ressources. De plus, plus la grappe dans laquelle un tel système fonctionne est importante, plus il faudra de ressources pour entretenir la nouvelle infrastructure. À Avito, nous exploitons des clusters kubernetes avec des milliers d'instances de service (et leur nombre continue de croître rapidement). Dans l'implémentation actuelle, Istio consomme environ 300 Mo de RAM par instance de service. En raison du grand nombre de fonctionnalités, l'équilibrage transparent affecte également le temps de réponse total des services (jusqu'à 10 ms).
En conséquence, nous avons examiné exactement les fonctionnalités dont nous avions besoin en ce moment et avons décidé que la principale raison pour laquelle nous avons commencé à mettre en œuvre de telles solutions était la capacité de collecter de manière transparente les informations de traçage de l'ensemble du système. Nous voulions également contrôler l'interaction des services et effectuer diverses manipulations avec les en-têtes qui sont transférés entre les services.
Finalement, nous sommes arrivés à notre décision: Netramesh .
Netramesh
Netramesh est une solution maillée de service légère avec une évolutivité infinie quel que soit le nombre de services dans le système.
Les principaux objectifs de la nouvelle solution étaient une faible surcharge de ressources et de hautes performances. Parmi les principales fonctionnalités, nous avons immédiatement voulu pouvoir envoyer de manière transparente des plages de traçage à notre système Jaeger.
Aujourd'hui, la plupart des solutions cloud sont implémentées sur Golang. Et, bien sûr, il y a des raisons à cela. L'écriture d'applications réseau Golang qui fonctionnent de manière asynchrone avec les E / S et s'adaptent aux noyaux selon les besoins est pratique et assez simple. Et, ce qui est également très important, les performances sont suffisantes pour résoudre ce problème. Par conséquent, nous avons également choisi Golang.
Performances
Nous avons concentré nos efforts sur la réalisation de performances maximales. Pour une solution déployée à côté de chaque instance du service, une petite consommation de RAM et de temps processeur est requise. Et, bien sûr, le délai de réponse devrait également être faible.
Voyons quels sont les résultats.
RAM
Netramesh consomme ~ 10 Mo sans trafic et 50 Mo maximum avec une charge allant jusqu'à 10 000 RPS par instance.
Le proxy d'envoi Istio consomme toujours ~ 300 Mo dans nos clusters avec des milliers d'instances. Cela ne vous permet pas de le mettre à l'échelle de l'ensemble du cluster.
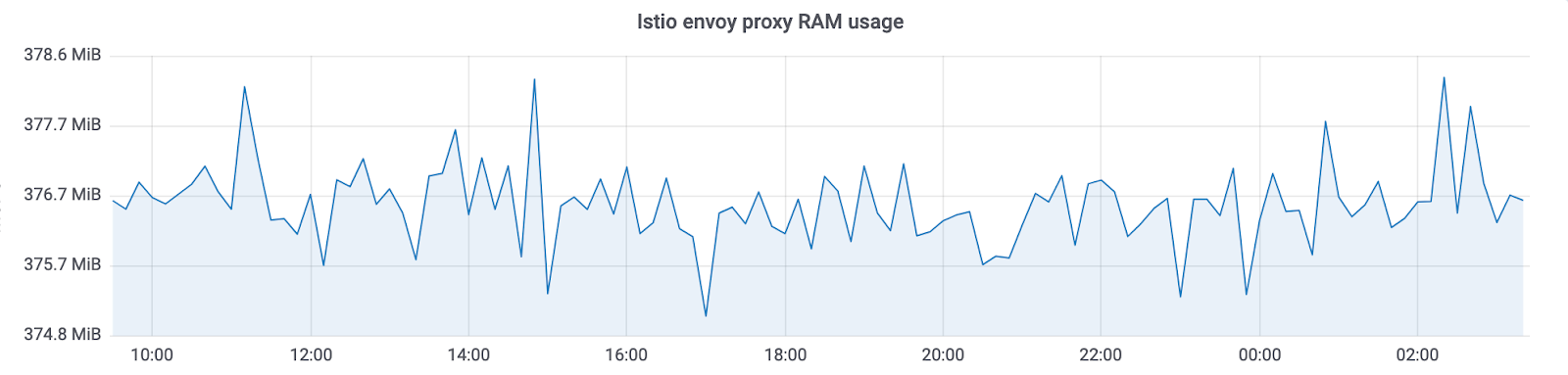

Avec Netramesh, nous avons obtenu ~ 10 fois moins de consommation de mémoire.
CPU
L'utilisation du processeur est relativement égale sous charge. Cela dépend du nombre de demandes par unité de temps au sidecar. Valeurs à 3000 requêtes par seconde en pointe:


Il y a un autre point important: Netramesh - une solution sans plan de contrôle et sans charge ne consomme pas de temps CPU. Avec Istio, sidecar met toujours à jour les points de terminaison du service. En conséquence, nous pouvons voir une telle image sans charge:

Nous utilisons HTTP / 1 pour communiquer entre les services. L'augmentation du temps de réponse pour Istio lors de la transmission par mandataire a été de 5 à 10 ms, ce qui est beaucoup pour les services prêts à répondre en une milliseconde. Avec Netramesh, ce temps est passé à 0,5-2 ms.
Évolutivité
Une petite quantité de ressources dépensées par chaque proxy permet de le placer à côté de chaque service. Netramesh a été créé intentionnellement sans composant de plan de contrôle pour simplement maintenir la légèreté de chaque side-car. Souvent dans les solutions de maillage de service, le plan de contrôle distribue des informations de découverte de service à chaque side-car. Parallèlement, il contient des informations sur les délais d'attente, les paramètres d'équilibrage. Tout cela vous permet de faire beaucoup de choses utiles, mais, malheureusement, gonfle la taille du sidecar'y.
Découverte de service

Netramesh n'ajoute aucun mécanisme supplémentaire pour la découverte de services. Tout le trafic est acheminé de manière transparente via le sidecar netra.
Netramesh prend en charge le protocole d'application HTTP / 1. Une liste configurable de ports est utilisée pour le déterminer. En règle générale, il existe plusieurs ports sur un système qui communiquent via HTTP. Par exemple, nous utilisons 80, 8890, 8080 pour interagir avec les services et les demandes externes. Dans ce cas, ils peuvent être définis à l'aide de la NETRA_HTTP_PORTS environnement NETRA_HTTP_PORTS .
Si vous utilisez Kubernetes en tant qu'orchestre et son mécanisme d'entités de service pour l'interaction intracluster entre services, le mécanisme reste exactement le même. Tout d'abord, le microservice obtient l'adresse IP du service à l'aide de kube-dns et lui ouvre une nouvelle connexion. Cette connexion est d'abord établie avec le netra-sidecar local, et tous les paquets TCP arrivent initialement dans netra. Ensuite, netra-sidecar établit une connexion avec la destination d'origine. NAT sur le pod IP sur le nœud reste exactement le même que sans netra.
Suivi distribué et défilement du contexte
Netramesh fournit les fonctionnalités nécessaires pour envoyer des plages de suivi sur les interactions HTTP. Netra-sidecar analyse le protocole HTTP, mesure les retards de demande, récupère les informations nécessaires dans les en-têtes HTTP. En fin de compte, nous obtenons toutes les traces dans un seul système Jaeger. Pour un réglage fin , vous pouvez également utiliser les variables d'environnement fournies par la bibliothèque officielle jaeger go .


Mais il y a un problème. Jusqu'à ce que les services génèrent et transmettent un en-tête Uber spécial, nous ne verrons pas les plages de traçage connectées dans le système. Et c'est ce dont nous avons besoin pour trouver rapidement la cause des problèmes. Ici, Netramesh a de nouveau une solution. Les proxys lisent les en-têtes HTTP et, s'ils n'ont pas d'id de trace uber, le génèrent. Netramesh stocke également des informations sur les demandes entrantes et sortantes dans le sidecar et les compare en enrichissant les en-têtes nécessaires des demandes sortantes. Il suffit de lancer un seul en X-Request-Id tête X-Request-Id , qui peut être configuré à l'aide de la NETRA_HTTP_REQUEST_ID_HEADER_NAME environnement NETRA_HTTP_REQUEST_ID_HEADER_NAME . Pour contrôler la taille du contexte dans Netramesh, vous pouvez définir les variables d'environnement suivantes: NETRA_TRACING_CONTEXT_EXPIRATION_MILLISECONDS (la durée pendant laquelle le contexte sera stocké) et NETRA_TRACING_CONTEXT_CLEANUP_INTERVAL (périodicité du nettoyage du contexte).
Il est également possible de combiner plusieurs chemins dans votre système en les marquant avec un marqueur de session spécial. Netra vous permet de définir HTTP_HEADER_TAG_MAP pour transformer les en-têtes HTTP en balises d'intervalle de suivi appropriées. Cela peut être particulièrement utile pour les tests. Après avoir réussi le test fonctionnel, vous pouvez voir quelle partie du système a été affectée par le filtrage par la clé de session correspondante.
Déterminer la source de la demande
Pour déterminer d'où vient la demande, vous pouvez utiliser la fonction pour ajouter automatiquement un en-tête avec une source. À l'aide de la NETRA_HTTP_X_SOURCE_HEADER_NAME environnement NETRA_HTTP_X_SOURCE_HEADER_NAME vous pouvez spécifier le nom de l'en-tête qui sera automatiquement défini. À l'aide de NETRA_HTTP_X_SOURCE_VALUE vous pouvez définir la valeur dans laquelle l'en-tête X-Source sera défini pour toutes les demandes sortantes.
Cela vous permet de répartir uniformément sur tout le réseau la distribution de cet en-tête utile. Ensuite, vous pouvez déjà l'utiliser dans les services et l'ajouter aux journaux et aux métriques.
Trafic Netramesh et routage interne
Netramesh se compose de deux composants principaux. Le premier, netra-init, établit des règles de réseau pour intercepter le trafic. Il utilise des règles de redirection iptables pour intercepter tout ou partie du trafic sur le sidecar, qui est le deuxième composant principal de Netramesh. Vous pouvez configurer les ports que vous souhaitez intercepter pour les sessions TCP entrantes et sortantes: INBOUND_INTERCEPT_PORTS, OUTBOUND_INTERCEPT_PORTS .
L'outil a également une fonctionnalité intéressante - le routage probabiliste. Si vous utilisez Netramesh exclusivement pour collecter des plages de traçage, dans un environnement de production, vous pouvez économiser des ressources et activer le routage probabiliste à l'aide des variables NETRA_INBOUND_PROBABILITY et NETRA_OUTBOUND_PROBABILITY (de 0 à 1). La valeur par défaut est 1 (tout le trafic est intercepté).
Après une interception réussie, netra sidecar accepte une nouvelle connexion et utilise l'option de socket SO_ORIGINAL_DST pour obtenir la destination d'origine. Netra ouvre ensuite une nouvelle connexion à l'adresse IP d'origine et établit une communication TCP bidirectionnelle entre les parties, en écoutant tout le trafic traversant. Si le port est défini comme HTTP, Netra essaiera de l'analyser et de le router. Si l'analyse HTTP échoue, Netra se repliera sur TCP et sur les octets proxy de manière transparente.
Création d'un graphe de dépendances
Après avoir reçu beaucoup d'informations de traçage dans Jaeger, je veux obtenir un graphique complet des interactions dans le système. Mais si votre système est suffisamment chargé et que des milliards de plages de traçage s'accumulent par jour, leur agrégation ne devient pas une tâche aussi simple. Il existe un moyen officiel de le faire: les dépendances d'étincelles . Cependant, il faudra des heures pour construire le graphique complet et forcer le jeu de données entier à être téléchargé depuis Jaeger au cours des dernières 24 heures.
Si vous utilisez Elasticsearch pour stocker des plages de traçage, vous pouvez utiliser un utilitaire simple sur Golang qui construira le même graphique en quelques minutes en utilisant les fonctionnalités et capacités d'Elasticsearch.
Comment utiliser Netramesh
Netra peut simplement être ajouté à n'importe quel service exécutant n'importe quel orchestrateur. Vous pouvez voir un exemple ici .
Pour le moment, Netra n'a pas la capacité de déployer automatiquement le sidecar sur les services, mais il est prévu de l'implémenter.
Futur Netramesh
L'objectif principal de Netramesh est d'atteindre des coûts de ressources minimaux et de hautes performances, offrant les principales opportunités d'observabilité et de contrôle de l'interaction interservices.
À l'avenir, Netramesh bénéficiera de la prise en charge de protocoles de niveau application autres que HTTP. Dans un avenir proche, il y aura la possibilité d'un routage L7.
Utilisez Netramesh si vous rencontrez des problèmes similaires et écrivez-nous des questions et suggestions.