À partir du rapport du développeur senior Sergey Murylyov, vous pouvez en apprendre davantage sur le conteneur associatif multi-thread pour la bibliothèque standard, qui est développé dans le cadre du WG21. Sergey a parlé des avantages et des inconvénients des solutions populaires à ce problème et de la voie choisie par les développeurs.
- Vous avez probablement déjà deviné à partir du titre que le rapport d'aujourd'hui portera sur la façon dont nous, dans le cadre du groupe de travail 21, avons créé notre conteneur, similaire à std :: unordered_map, mais pour un environnement multi-thread.
Dans de nombreux langages de programmation - Java, C #, Python - cela existe déjà et est assez largement utilisé. Mais dans notre C ++ bien-aimé, le plus rapide et le plus productif, cela ne s'est pas produit. Mais nous avons consulté et décidé de faire une telle chose.

Avant d'ajouter quelque chose à la norme, vous devez réfléchir à la façon dont les gens l'utiliseront. Ensuite, pour créer une interface plus correcte, qui sera très probablement adoptée par la commission - de préférence sans aucun amendement. Et pour qu’en fin de compte, il n’y ait pas de telle chose qu’ils aient fait une chose,
L'option la plus connue et la plus utilisée est la mise en cache de gros calculs lourds. Il existe un service Memcached assez connu qui met simplement en cache les réponses du serveur Web en mémoire. Il est clair que vous pouvez faire à peu près la même chose du côté de votre candidature, si vous disposez d'un conteneur associatif compétitif. Les deux approches ont leurs avantages et leurs inconvénients. Mais si vous ne disposez pas d'un tel conteneur, vous devrez soit faire votre propre vélo ou utiliser une sorte de Memcached.
Un autre cas d'utilisation populaire est la déduplication des événements. Je pense que beaucoup dans cette salle écrivent toutes sortes de systèmes distribués et savent que les files d'attente distribuées sont souvent utilisées pour communiquer entre les composants, tels qu'Apache Kafka et Amazon Kinesis. Ils se distinguent par une telle fonctionnalité qu'ils peuvent envoyer plusieurs fois un message à un consommateur. Cela s'appelle au moins une fois la livraison, ce qui signifie une garantie de livraison au moins une fois: plus est possible, moins ne l'est pas.
Considérez cela en termes de vie réelle. Imaginez que nous ayons un backend d'une salle de chat ou d'un réseau social où la messagerie a lieu. Cela peut conduire au fait que quelqu'un a écrit un message et que quelqu'un a reçu plusieurs fois une notification push sur son téléphone portable. Il est clair que si les utilisateurs voient cela, ils n'en seront pas contents. On fait valoir que ce problème peut être résolu avec un si merveilleux conteneur multi-thread.
Le cas suivant, moins fréquemment utilisé, est celui où nous avons juste besoin d'enregistrer quelque chose côté serveur, des métadonnées pour l'utilisateur. Par exemple, nous pouvons gagner du temps lors de la dernière authentification de l'utilisateur, afin de comprendre quand, la prochaine fois, il lui sera demandé son nom d'utilisateur et son mot de passe.
La dernière option sur cette diapositive est les statistiques. À partir d'applications réelles, un exemple d'utilisation dans une machine virtuelle de Facebook peut être donné. Ils ont fait une machine virtuelle entière pour optimiser PHP et dans leur machine virtuelle, ils essaient d'écrire les arguments avec lesquels ils ont été appelés dans une table de hachage multi-thread pour toutes les fonctions intégrées. Et s'ils ont un résultat dans le cache, ils essaient de le donner tout de suite et ne comptent rien.

Ajouter quelque chose de grand et de compliqué à la norme n'est ni facile ni rapide. En règle générale, si quelque chose de gros est ajouté, il passe par la spécification technique. Actuellement, la norme évolue beaucoup pour étendre la prise en charge du multithreading dans la bibliothèque standard. Et en particulier, la proposition P0260R3 sur les files d'attente multithreads est en cours actuellement. Cette proposition concerne une structure de données très similaire à nous, et nos décisions de conception sont très similaires à bien des égards.
En fait, l'un des concepts de base de leur conception est que leur interface est différente de la file d'attente standard std ::. À quoi ça sert? Si vous regardez la file d'attente standard, puis pour en extraire un élément, vous devez effectuer deux opérations. Vous devez effectuer une opération frontale pour compter et une opération pop pour supprimer. Si nous travaillons dans des conditions de multithreading, nous pouvons avoir une sorte d'opération sur la file d'attente entre ces deux appels, et il peut arriver que nous considérions un élément et en supprimions un autre, ce qui semble conceptuellement incorrect. Par conséquent, ces deux appels y ont été remplacés par un, et quelques autres appels de la catégorie des essais push et try pop ont été ajoutés. Mais l'idée générale est qu'un conteneur multi-thread ne sera pas le même qu'une interface normale.
Les files d'attente multithread ont également de nombreuses implémentations différentes qui résolvent plusieurs tâches différentes. La tâche la plus courante est la tâche des producteurs et des consommateurs, lorsque nous avons des threads qui produisent certaines tâches et que certains threads prennent des tâches de la file d'attente et les traitent.
Le deuxième cas est celui où nous avons juste besoin d'une sorte de file d'attente synchronisée. Dans le cas des fabricants et des consommateurs, nous obtenons une file d'attente limitée au haut et au bas. Si nous essayons, relativement parlant, d'extraire d'une file d'attente vide, alors nous entrons dans un état d'attente. Et la même chose se produit à peu près si nous essayons d'ajouter quelque chose qui ne rentre pas dans la file d'attente en taille.
Dans cette proposition, il est également décrit que nous avons une interface distincte qui nous permet de distinguer la mise en œuvre que nous avons à l'intérieur de la serrure, ou la serrure libre. Le fait qu'ici partout dans la proposition est écrit sans verrou, en fait, il est écrit dans les livres comme sans attente. Cela signifie que notre algorithme fonctionne pour un nombre fixe d'opérations. Verrouiller librement signifie un peu différent, mais ce n'est pas le but.
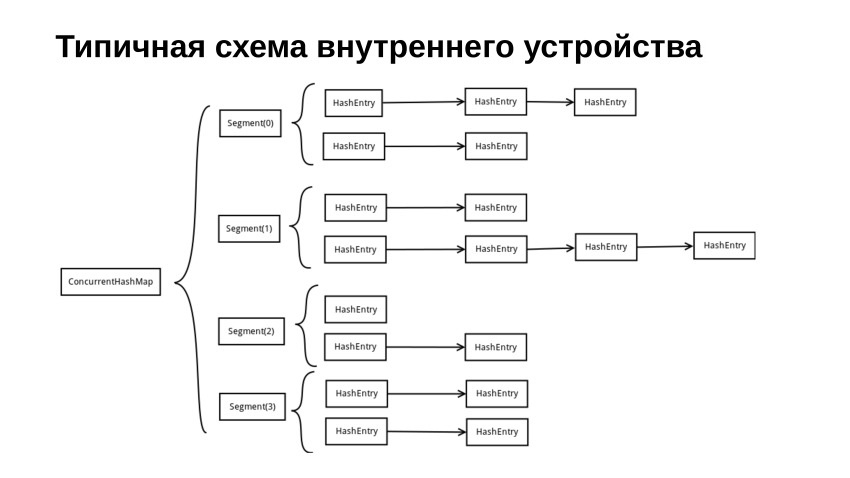
Examinons un diagramme typique de la façon dont l'implémentation de notre table de hachage pourrait ressembler si elle est bloquée. Nous l'avons divisé en plusieurs segments. Chaque segment, en règle générale, contient une sorte de verrou, tel que Mutex, Spinlock, ou quelque chose d'encore plus délicat. Et en plus de Mutex ou Spinlock, il contient également la table de hachage habituelle, qui est protégée par cette activité.
Dans cette image, nous avons une table de hachage, qui est faite sur les listes. En fait, dans notre implémentation de référence, nous avons écrit une table de hachage avec un adressage ouvert pour des raisons de performances. Les considérations de performances sont fondamentalement les mêmes que pourquoi std :: vector est plus rapide que std :: list car le vecteur, relativement parlant, est stocké séquentiellement en mémoire. Lorsque nous le parcourons, nous avons un accès séquentiel, qui est bien mis en cache. Si nous utilisons une sorte de feuilles, nous aurons toutes sortes de sauts entre les différentes sections de la mémoire. Et le tout, en règle générale, se termine par le fait que nous perdons de la productivité.
Au tout début, lorsque nous voulons trouver quelque chose dans cette table de hachage, nous prenons le code de hachage de la clé. Vous pouvez le prendre modulo et faire autre chose avec lui pour obtenir le numéro de segment, et dans le segment que nous recherchons, comme dans une table de hachage régulière, mais en même temps, bien sûr, nous prenons le verrou.

Les principales idées de notre conception. Bien sûr, nous avons également créé une interface qui ne correspond pas à std :: unordered_map. La raison en est la suivante. Par exemple, dans std :: unordered_map ordinaire, nous avons une chose aussi merveilleuse que les itérateurs. Premièrement, toutes les implémentations ne peuvent pas les prendre en charge normalement. Et ceux qui peuvent prendre en charge, en règle générale, sont des implémentations sans verrouillage qui nécessitent soit une récupération de place, soit une sorte de pointeurs intelligents qui nettoient la mémoire derrière.
En plus de cela, nous avons lancé plusieurs autres types d'opérations. En fait, les itérateurs, ils sont en de nombreux endroits. Par exemple, ils sont en Java. Mais, en règle générale, curieusement, ils ne se synchronisent pas là-bas. Et si vous essayez de faire quelque chose avec eux à partir de différents threads, ils peuvent facilement entrer dans un état non valide, et vous pouvez obtenir une exception en Java, et si vous écrivez ceci sur les avantages, alors ce sera probablement un comportement non défini, ce qui est encore pire . Et d'ailleurs, sur le sujet des comportements indéfinis: à mon avis, les camarades de Facebook dans leur folie de bibliothèque, qui est publiée en open source sur GitHub, l'ont fait. Je viens de copier l'interface avec Java et d'obtenir de merveilleux itérateurs.
Nous n'avons pas non plus de problème de mémoire, c'est-à-dire que si nous ajoutons quelque chose au conteneur et prenons de la mémoire pour cela, nous ne le rendrons pas, même si nous supprimons tout. Une autre condition préalable à cette décision était que nous ayons une table de hachage avec un adressage ouvert à l'intérieur. Il fonctionne sur une structure de données linéaire qui, comme le vecteur, ne rend pas de mémoire.
Le prochain moment conceptuel est qu'en aucun cas nous ne donnerons à quiconque des liens extérieurs et des pointeurs vers des objets internes. Cela a été fait précisément pour éviter la nécessité d'une collecte de déchets et non pour appliquer des pointeurs intelligents. Il est clair que si nous stockons des objets suffisamment grands, leur stockage par valeur à l'intérieur ne sera pas rentable. Mais, dans ce cas, nous pouvons toujours les envelopper dans une sorte de pointeurs intelligents de notre choix. Et, si nous voulons, par exemple, faire une sorte de synchronisation sur les valeurs, nous pouvons les envelopper dans une sorte de boost :: synchronized_value.
Nous avons vu qu'il y a quelque temps, la classe shared_ptr a été supprimée de la méthode qui renvoyait le nombre de liens actifs vers cet objet. Et nous sommes arrivés à la conclusion que nous devons également supprimer plusieurs fonctions, à savoir, size, count, empty, buckets_count, car dès que nous renvoyons cette valeur de la fonction, elle cesse immédiatement d'être valide, car quelqu'un peut changer le même moment.
Lors d'une de nos précédentes réunions, ils nous ont demandé d'ajouter une sorte de mode afin que nous puissions accéder à notre conteneur en mode monothread, comme un std :: unordered_map classique. Une telle sémantique nous permet de distinguer clairement où nous travaillons en mode multithread et où non. Et pour éviter certaines situations désagréables lorsque les gens prennent un conteneur multi-thread, attendez-vous à ce que tout se passe bien avec eux, prenez des itérateurs, puis soudain, il s'avère que tout est mauvais.

Lors de cette réunion à Hawaï, toute une proposition a été rédigée contre nous. :) On nous a dit que de telles choses n'avaient pas leur place dans la norme, car il existe de nombreuses façons de créer votre conteneur associatif multi-thread.
Chacun a ses avantages et ses inconvénients - et on ne sait pas comment utiliser ce que nous réussissons finalement. En règle générale, il est utilisé lorsque vous avez besoin d'une sorte de performance extrême. Et il semble que notre solution en boîte ne convient pas, il faut l'optimiser pour chaque cas spécifique.
Le deuxième point de cette proposition était que notre interface n'est pas compatible avec le fait que Facebook a posté sur GitHub depuis sa bibliothèque standard.
En fait, il n'y avait pas de problème particulier là-bas. Il y avait simplement une question de la catégorie "Je n'ai pas lu, mais condamne". Ils ont juste regardé - l'interface est différente, ce qui signifie qu'elle n'est pas compatible.
L'idée de la proposition était également que des tâches similaires devraient être résolues à l'aide de la conception dite basée sur des politiques, quand il est nécessaire de créer un paramètre de modèle supplémentaire dans lequel vous pouvez passer un masque de bits avec quelles fonctionnalités nous voulons activer et lesquelles désactiver. En effet, cela semble un peu sauvage et conduit au fait que nous obtenons environ 2 ^ n implémentations, où n est le nombre de fonctionnalités différentes.

Dans le code, cela ressemble à ceci. Nous avons une sorte de paramètre et un certain nombre de constantes prédéfinies qui peuvent y être passées. Curieusement, cette proposition a été rejetée.

Parce que, en fait, le comité a déjà adopté la position que de telles choses devraient être lorsque la file d'attente multithread passe par SG1. Il n'y a même pas eu de vote sur cette question. Mais deux questions ont été mises aux voix.
Le premier. Beaucoup de gens nous voulaient du côté de notre implémentation de référence pour soutenir la lecture sans prendre de verrous. Pour que nous ayons une lecture complètement non bloquante. Cela a vraiment du sens: en règle générale, le cas d'utilisation le plus populaire est la mise en cache. Et c'est très bénéfique pour nous d'avoir une lecture rapide.
Deuxième moment. Tout le monde a beaucoup entendu parler de l'ami précédent qui a parlé de la conception basée sur les politiques. Tout le monde avait une idée - mais quoi, laissez-moi parler de mon idée aussi! Et tout le monde a voté pour une conception basée sur les politiques. Même si je dois dire que toute cette histoire dure depuis un certain temps, et devant nous, nos collègues d'Intel, d'Arch Robinson et d'Anton Malakhov le faisaient. Et ils avaient déjà plusieurs propositions à ce sujet. Ils ont juste proposé d'ajouter une implémentation sans verrouillage basée sur l'algorithme
SeepOrderedList . Et ils avaient également une conception basée sur des politiques avec la plainte de mémoire.
Et cette proposition n'aimait pas le Library Evolution Working Group. Il a été conclu avec la raison que nous aurons simplement une augmentation illimitée du nombre de mots dans la norme. Il sera tout simplement impossible de prévisualiser adéquatement et de simplement implémenter dans le code.
Nous n'avons aucun commentaire sur les idées elles-mêmes. Nous avons des commentaires, pour la plupart, sur la mise en œuvre des références. Et bien sûr, nous avons quelques idées qui peuvent être introduites pour le rendre plus clair. Mais essentiellement, la prochaine fois, nous irons avec la même proposition. Nous espérons sincèrement que nous n'aurons pas, comme pour les modules, cinq appels avec la même proposition. Nous croyons sincèrement en nous-mêmes, et nous serons autorisés à passer au prochain appel, et que le groupe de travail sur l'évolution de la bibliothèque insistera néanmoins sur notre opinion et ne nous permettra pas de faire avancer la conception basée sur les politiques. Parce que notre adversaire ne s'arrête pas. Il a décidé de prouver à tout le monde que c'était nécessaire. Mais comme on dit, le temps nous le dira. J'ai tout, merci de votre attention.