
Tout le monde perçoit uniquement les textes, que cette personne lise des nouvelles sur Internet ou des romans classiques de renommée mondiale. Cela s'applique également à une variété d'algorithmes et de techniques d'apprentissage automatique, qui comprennent les textes de manière plus mathématique, à savoir en utilisant un espace vectoriel de grande dimension.
Cet article est consacré à la visualisation des incorporations de mots Word2Vec à haute dimension à l'aide de t-SNE. La visualisation peut être utile pour comprendre comment Word2Vec fonctionne et comment interpréter les relations entre les vecteurs capturés à partir de vos textes avant de les utiliser dans des réseaux de neurones ou d'autres algorithmes d'apprentissage automatique. Comme données de formation, nous utiliserons des articles de Google Actualités et des œuvres littéraires classiques de Leo Tolstoï, l'écrivain russe qui est considéré comme l'un des plus grands auteurs de tous les temps.
Nous passons par le bref aperçu de l'algorithme t-SNE, puis passons au calcul des incorporations de mots à l'aide de Word2Vec, et enfin, passons à la visualisation des vecteurs de mots avec t-SNE dans l'espace 2D et 3D. Nous allons écrire nos scripts en Python en utilisant Jupyter Notebook.
Intégration de voisin stochastique distribué en T
T-SNE est un algorithme d'apprentissage automatique pour la visualisation de données, qui est basé sur une technique de réduction de dimensionnalité non linéaire. L'idée de base du t-SNE est de réduire l'espace dimensionnel en maintenant une distance relative par paire entre les points. En d'autres termes, l'algorithme mappe des données multidimensionnelles à deux dimensions ou plus, où les points qui étaient initialement éloignés l'un de l'autre sont également situés loin, et les points proches sont également convertis en points proches. On peut dire que t-SNE cherche une nouvelle représentation des données où les relations de voisinage sont préservées. La description détaillée de l'ensemble de la logique t-SNE se trouve dans l'article d'origine [1].
Le modèle Word2Vec
Pour commencer, nous devons obtenir des représentations vectorielles des mots. À cette fin, j'ai sélectionné Word2vec [2], c'est-à-dire un modèle prédictif efficace en termes de calcul pour l'apprentissage des incorporations de mots multidimensionnelles à partir de données textuelles brutes. Le concept clé de Word2Vec est de localiser des mots, qui partagent des contextes communs dans le corpus d'apprentissage, à proximité immédiate de l'espace vectoriel par rapport aux autres.
Comme données d'entrée pour la visualisation, nous utiliserons des articles de Google News et quelques romans de Leo Tolstoy. Des vecteurs pré-formés formés sur une partie de l'ensemble de données Google Actualités (environ 100 milliards de mots) ont été publiés par Google sur
la page officielle , nous allons donc l'utiliser.
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
En plus du modèle pré-formé, nous formerons un autre modèle sur les romans de Tolstoï en utilisant la bibliothèque Gensim [3]. Word2Vec prend des phrases comme données d'entrée et produit des vecteurs de mots comme sortie. Tout d'abord, il est nécessaire de télécharger le Punkt Phrase Tokenizer pré-formé, qui divise un texte en une liste de phrases en tenant compte des mots d'abréviation, des collocations et des mots, qui indiquent probablement un début ou une fin de phrases. Par défaut, le package de données NLTK n'inclut pas de jeton Punkt pré-formé pour le russe, nous utiliserons donc des modèles tiers de
github.com/mhq/train_punkt .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
Lors de la formation Word2Vec, les hyperparamètres suivants ont été utilisés:
- La dimensionnalité du vecteur caractéristique est de 200.
- La distance maximale entre les mots analysés dans une phrase est de 5.
- Ignore tous les mots dont la fréquence totale est inférieure à 5 par corpus.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualisation des incorporations de mots à l'aide de t-SNE
T-SNE est très utile dans le cas où il est nécessaire de visualiser la similitude entre des objets situés dans un espace multidimensionnel. Avec un grand ensemble de données, il devient de plus en plus difficile de créer un tracé t-SNE facile à lire, il est donc courant de visualiser des groupes de mots les plus similaires.
Choisissons quelques mots dans le vocabulaire du modèle Google News pré-formé et préparons des vecteurs de mots pour la visualisation.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
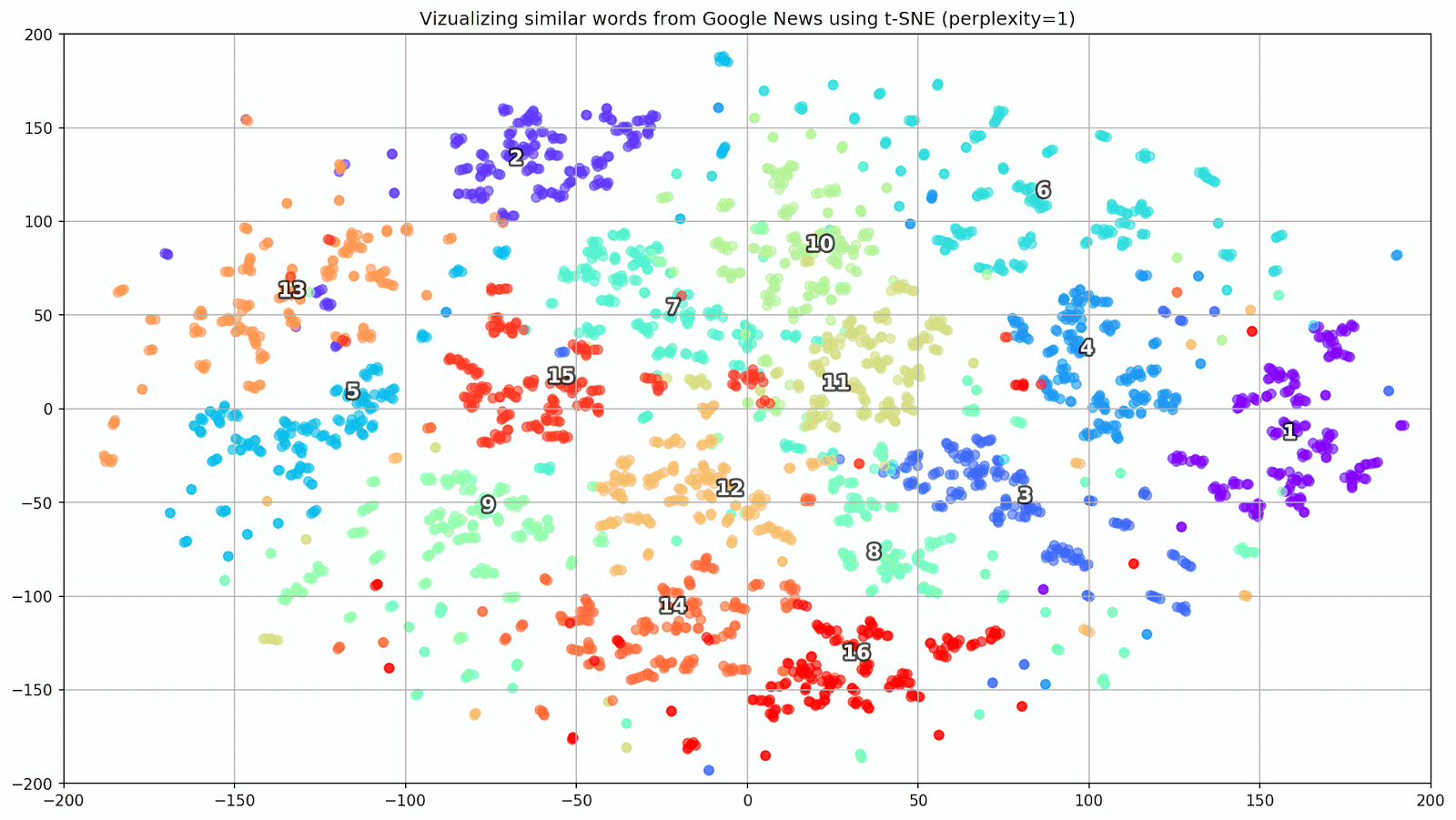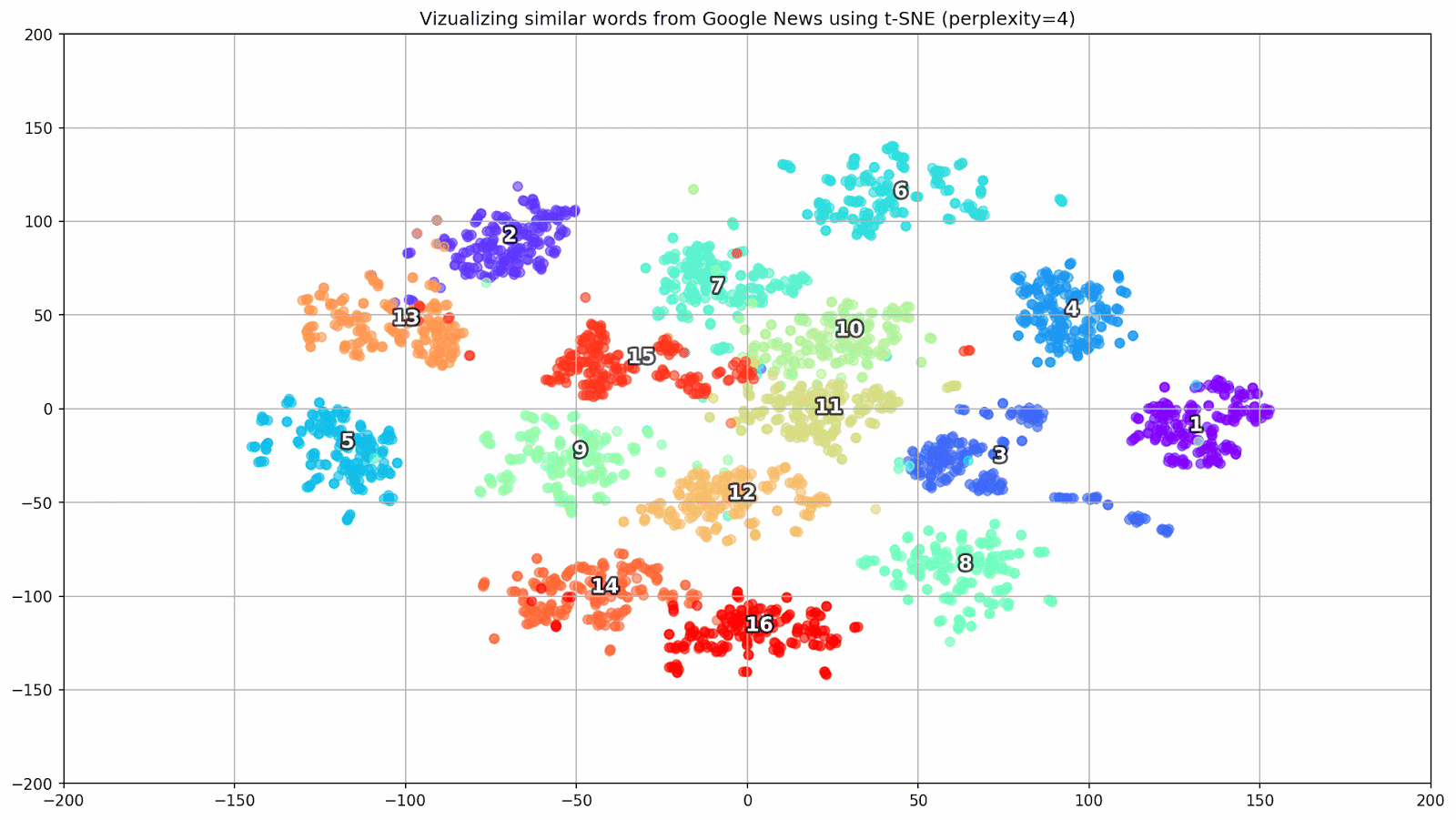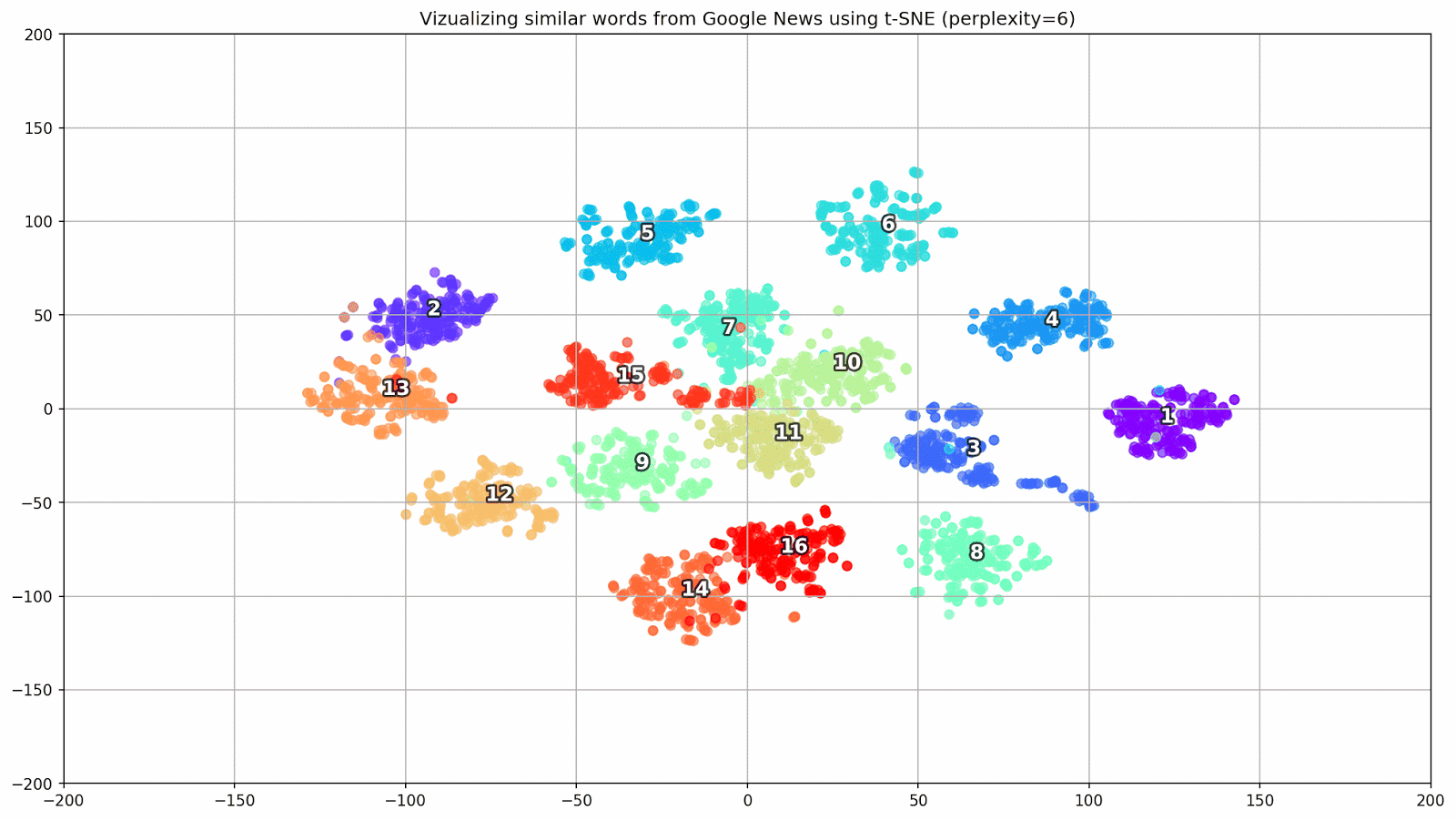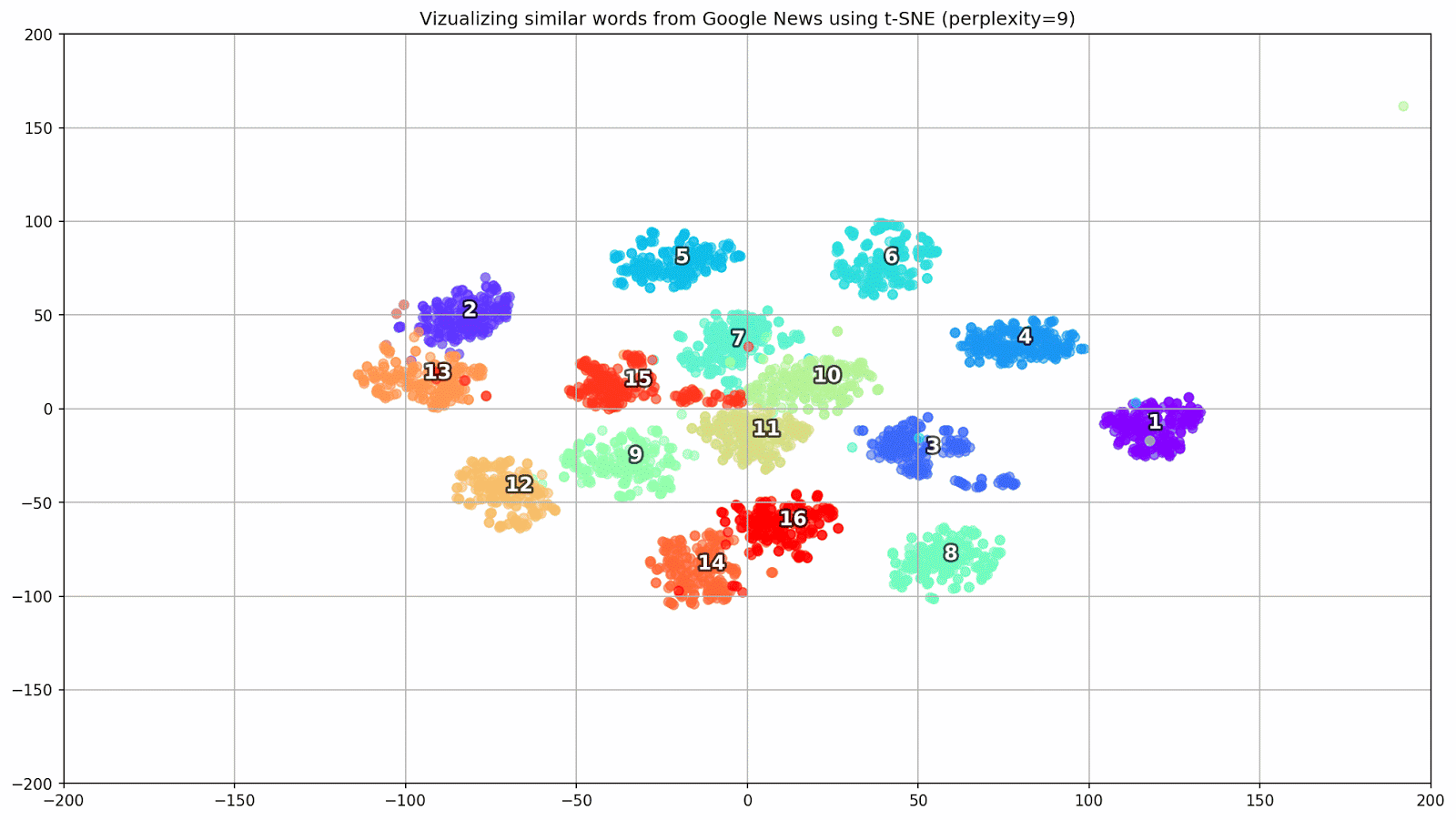 Fig. 1. L'effet de diverses valeurs de perplexité sur la forme des groupes de mots.
Fig. 1. L'effet de diverses valeurs de perplexité sur la forme des groupes de mots.Ensuite, nous passons à la partie fascinante de cet article, la configuration de t-SNE. Dans cette section, nous devons prêter notre attention aux hyperparamètres suivants.
- Le nombre de composants , c'est-à-dire la dimension de l'espace de sortie.
- La valeur de perplexité , qui, dans le contexte du t-SNE, peut être considérée comme une mesure fluide du nombre effectif de voisins. Il est lié au nombre de voisins les plus proches qui sont employés dans de nombreux autres apprenants (voir l'image ci-dessus). Selon [1], il est recommandé de sélectionner une valeur entre 5 et 50.
- Type d'initialisation initiale pour les incorporations.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Il convient de mentionner que le t-SNE a une fonction objectif non convexe, qui est minimisée en utilisant une optimisation de descente de gradient avec une initiation aléatoire, de sorte que différents essais produisent des résultats légèrement différents.
Ci-dessous, vous trouverez un script pour créer un nuage de points 2D à l'aide de Matplotlib, l'une des bibliothèques les plus populaires pour la visualisation de données en Python.
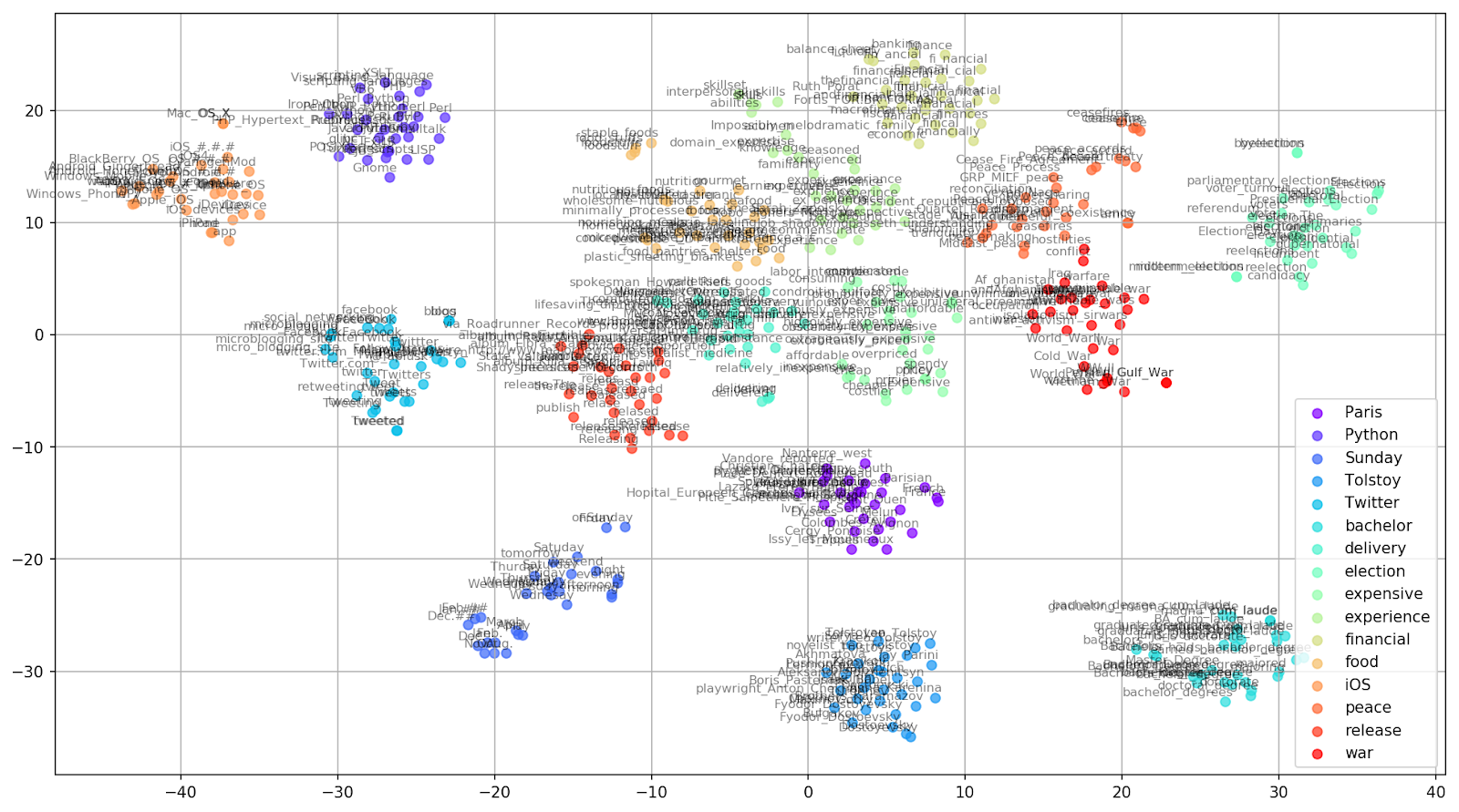 Fig. 2. Clusters de mots similaires de Google Actualités (pré-complexité = 15).
Fig. 2. Clusters de mots similaires de Google Actualités (pré-complexité = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
Dans certains cas, il peut être utile de tracer tous les vecteurs de mots à la fois afin de voir l'image entière. Analysons maintenant Anna Karenina, un roman épique de passion, d'intrigue, de tragédie et de rédemption.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
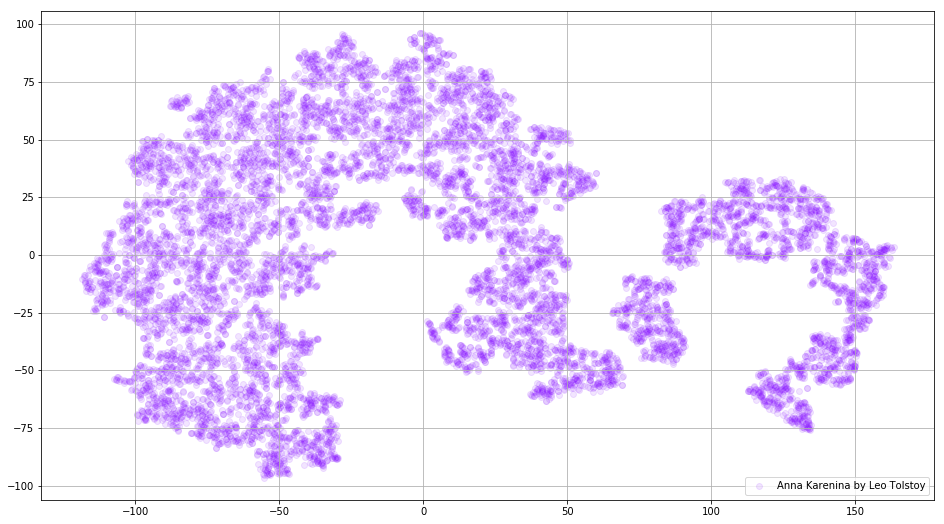
 Fig. 3. Visualisation du modèle Word2Vec formé sur Anna Karenina.
Fig. 3. Visualisation du modèle Word2Vec formé sur Anna Karenina.L'image entière peut être encore plus informative si nous cartographions les plongements initiaux dans l'espace 3D. En ce moment, jetons un œil à Guerre et Paix, l'un des romans vitaux de la littérature mondiale et l'une des plus grandes réalisations littéraires de Tolstoï.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
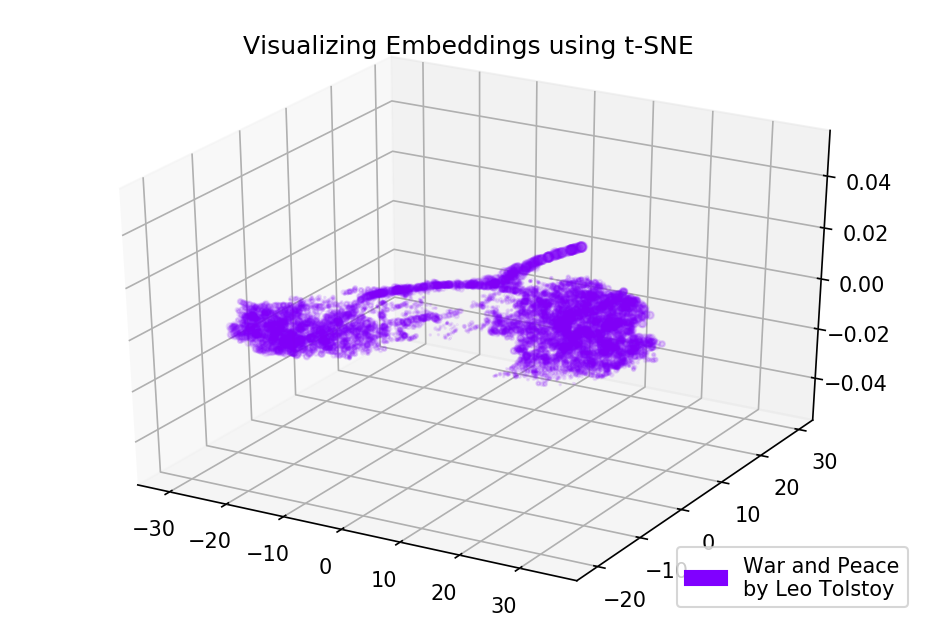 Fig. 4. Visualisation du modèle Word2Vec formé sur la guerre et la paix.
Fig. 4. Visualisation du modèle Word2Vec formé sur la guerre et la paix.Les résultats
Voilà à quoi ressemblent les textes issus de la prospective Word2Vec et t-SNE. Nous avons tracé un tableau assez informatif pour des mots similaires de Google Actualités et deux diagrammes pour les romans de Tolstoï. De plus, encore une chose, les GIF! Les GIF sont impressionnants, mais tracer des GIF est presque le même que tracer des graphiques réguliers. J'ai donc décidé de ne pas les mentionner dans l'article, mais vous pouvez trouver le code pour la génération d'animations dans les sources.
Le code source est disponible sur
Github .
L'article a été initialement publié dans
Towards Data Science .
Les références
- L. Maate et G. Hinton, «Visualizing data using t-SNE», Journal of Machine Learning Research, vol. 9, pp. 2579-2605, 2008.
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado et J. Dean, «Représentations distribuées des mots et des phrases et leur compositionnalité», Advances in Neural Information Processing Systems, pp. 3111-3119, 2013.
- R. Rehurek et P. Sojka, «Software Framework for Topic Modeling with Large Corpora», Actes de l'atelier LREC 2010 sur les nouveaux défis pour les cadres PNL, 2010.