Test comparatif des caches multithreads implémentés en C / C ++ et description de la disposition du cache LRU / MRU de la série O (n) Cache ** RU
Au fil des décennies, de nombreux algorithmes de mise en cache ont été développés: LRU, MRU, ARC, et autres .... Cependant, lorsqu'un cache était nécessaire pour un travail multi-thread, Google sur ce sujet a donné une option et demie, et la question sur StackOverflow est généralement restée sans réponse. J'ai trouvé une solution de Facebook qui s'appuie sur des conteneurs thread-safe du référentiel Intel TBB . Ce dernier a également un cache LRU multi-thread est toujours en test bêta et donc, pour l'utiliser, vous devez spécifier explicitement dans le projet:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true
Sinon, le compilateur affichera une erreur car il y a une vérification dans le code Intel TBB:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif
Je voulais en quelque sorte comparer les performances des caches - lequel choisir? Ou écrivez le vôtre? Plus tôt, lorsque je comparais des caches à un seul fil ( lien ), j'ai reçu des offres pour essayer d'autres conditions avec d'autres clés et j'ai réalisé qu'un banc de test extensible plus pratique était nécessaire. Afin de rendre plus pratique l'ajout d'algorithmes concurrents aux tests, j'ai décidé de les envelopper dans l'interface standard:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; };
De même, les interfaces sont enveloppées: travailler avec le système d'exploitation, obtenir les paramètres, les cas de test, etc. Les sources sont présentées dans le référentiel . Il y a deux cas de test sur le stand: insérer / rechercher jusqu'à 1 000 000 éléments avec une clé à partir de nombres générés aléatoirement et jusqu'à 100 000 éléments avec une clé de chaîne (tirés de 10 Mo de lignes wiki.train.tokens). Pour évaluer le temps d'exécution, chaque cache de test est d'abord chauffé au volume cible sans mesure de temps, puis le sémaphore décharge les flux de la chaîne pour ajouter et rechercher des données. Le nombre de threads et les paramètres de scénario de test sont définis dans assets / settings.json . Les instructions de compilation étape par étape et une description des paramètres JSON sont décrites dans le référentiel WiKi . Le temps est suivi à partir du moment où le sémaphore est libéré jusqu'à l'arrêt du dernier thread. Voici ce qui s'est passé:
Test case1 - une clé sous la forme d'un tableau de nombres aléatoires uint64_t keyArray [3]:
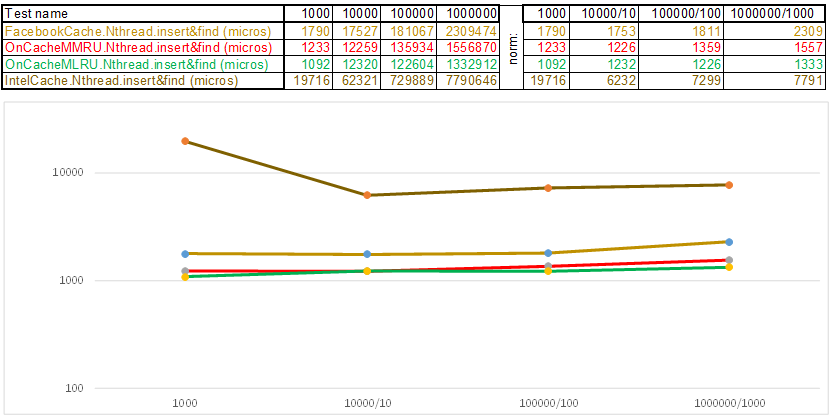
Test case2 - clé sous forme de chaîne:
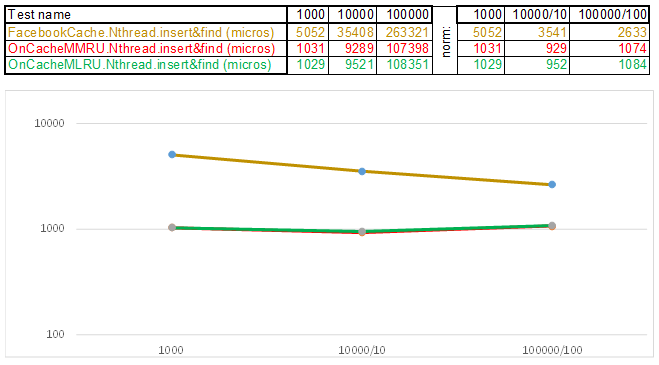
Veuillez noter que le volume de données insérées / recherchées à chaque étape du scénario de test augmente 10 fois. Ensuite, le temps consacré au traitement du volume suivant, je le divise par 10, 100, 1000, respectivement ... Si l'algorithme se comporte comme O (n) dans la complexité temporelle, alors la chronologie restera approximativement parallèle à l'axe X. Ensuite, je révélerai des connaissances sacrées, comme je l'ai géré obtenez une supériorité de 3 à 5 fois sur le cache Facebook dans les algorithmes de la série O (n) Cache ** RU lorsque vous travaillez avec une clé de chaîne:
- La fonction de hachage, au lieu de lire chaque lettre de la chaîne, transforme simplement un pointeur vers les données de chaîne en uint64_t keyArray [3] et compte la somme des entiers. Autrement dit, il fonctionne comme le programme "Devinez la mélodie" - et je suppose que la mélodie en 3 notes ... 3 * 8 = 24 lettres si c'est latin, et cela vous permet déjà de disperser assez bien les lignes dans des paniers de hachage. Oui, beaucoup de lignes peuvent être collectées dans un panier de hachage, et ici l'algorithme commence à accélérer:
- La liste des sauts dans chaque panier vous permet de sauter rapidement en premier dans différents hachages (id panier = hachage% nombre de paniers, donc différents hachages peuvent apparaître dans un même panier), puis dans le même hachage le long des sommets:
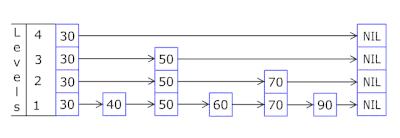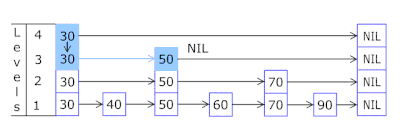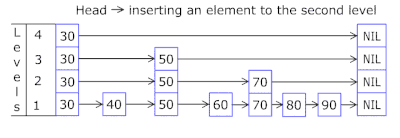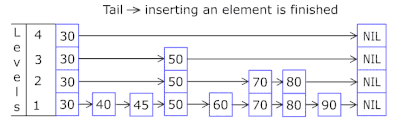
- Les nœuds dans lesquels les clés et les données sont stockées sont tirés du tableau de nœuds précédemment alloué, le nombre de nœuds coïncide avec la capacité du cache. L'identifiant atomique indique le nœud à prendre ensuite - s'il atteint la fin du pool de nœuds, il commence par 0 = donc l'allocateur va dans un cercle écrasant les anciens nœuds ( cache LRU dans OnCacheMLRU ).
Dans le cas où il est nécessaire que les éléments les plus populaires dans les requêtes de recherche soient stockés dans le cache, la deuxième classe OnCacheMMRU est créée , l'algorithme est le suivant: en plus de la capacité du cache, le constructeur de la classe passe également le deuxième paramètre uint32_t inutile, la limite de popularité est si le nombre de requêtes de recherche qui souhaitent le nœud actuel du pool cyclique est inférieur Si les limites sont inutiles, le nœud est réutilisé pour la prochaine opération d'insertion (il sera expulsé). Si sur ce cercle la popularité du nœud (std :: atomic <uint32_t> utilisé {0}) est élevée, alors au moment de demander l'allocateur du pool cyclique, le nœud pourra survivre, mais le compteur de popularité sera réinitialisé à 0. Il y aura donc un autre cercle de passe de l'allocateur sur un pool de nœuds et aura une chance de regagner en popularité afin de continuer à exister. C'est-à-dire qu'il s'agit d'un mélange des algorithmes MRU (où les plus populaires restent dans le cache pour toujours) et MQ (où la durée de vie est suivie). Le cache est constamment mis à jour et en même temps, il fonctionne très rapidement - au lieu de 10 serveurs, vous pouvez en mettre 1 ..
Dans l'ensemble, l'algorithme de mise en cache passe du temps sur les éléments suivants:
- Maintenance de l'infrastructure de cache (conteneurs, allocateurs, suivi de la durée de vie et de la popularité des éléments)
- Calcul de hachage et opérations de comparaison clés lors de l'ajout / de la recherche de données
- Algorithmes de recherche: arbre rouge-noir, table de hachage, liste de saut, ...
Il était juste nécessaire de réduire le temps de fonctionnement de chacun de ces éléments, étant donné que l'algorithme le plus simple est temporellement complexe et souvent le plus efficace, car toute logique prend des cycles CPU. Autrement dit, quoi que vous écriviez, ce sont des opérations qui devraient être payantes en temps par rapport à la méthode d'énumération simple: tandis que la fonction suivante est appelée, l'énumération devra passer par cent ou deux nœuds supplémentaires. Dans cette optique, les caches multi-thread perdront toujours en mode single-thread, car la protection des paniers via std :: shared_mutex et des nœuds via std :: atomic_flag in_use n'est pas gratuite. Par conséquent, pour l'émission sur le serveur, j'utilise le cache à thread unique OnCacheSMRU dans le thread principal du serveur Epoll (seules les opérations longues sur le travail avec le SGBD, le disque, la cryptographie sont effectuées dans des workflows parallèles). Pour une évaluation comparative, une version monothread des cas de test est utilisée:
Test case1 - une clé sous la forme d'un tableau de nombres aléatoires uint64_t keyArray [3]:

Test case2 - clé sous forme de chaîne:
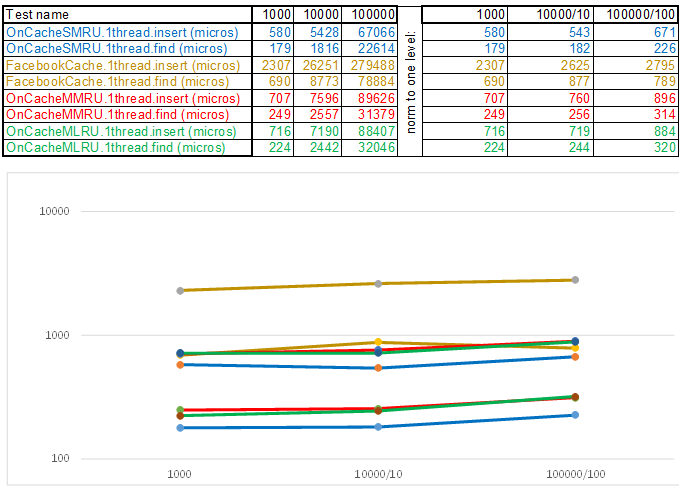
En conclusion, je veux vous dire quoi d'autre intéressant peut être extrait des sources du banc d'essai:
- La bibliothèque d'analyse JSON, qui consiste en un seul fichier specjson.h, est un petit algorithme simple et rapide pour ceux qui ne veulent pas faire glisser quelques mégaoctets de code de quelqu'un d'autre dans leur projet afin d'analyser le fichier de paramètres ou le JSON entrant d'un format connu.
- Une approche avec injection de l'implémentation d'opérations spécifiques à la plateforme sous la forme (classe LinuxSystem: public ISystem {...}) au lieu du traditionnel (#ifdef _WIN32). Il est plus pratique d'encapsuler, par exemple, des sémaphores, de travailler avec des bibliothèques et des services connectés dynamiquement - dans les classes, il n'y a que du code et des en-têtes provenant d'un système d'exploitation spécifique. Si vous avez besoin d'un autre système d'exploitation, vous injectez une autre implémentation (classe WindowsSystem: public ISystem {...}).
- Le stand va à CMake - il est pratique d'ouvrir le projet CMakeLists.txt dans Qt Creator ou Microsoft Visual Studio 2017. Travailler avec le projet via CmakeLists.txt vous permet d'automatiser certaines opérations préparatoires - par exemple, copier des fichiers de cas de test et des fichiers de configuration dans le répertoire d'installation:
- Pour ceux qui maîtrisent les nouvelles fonctionnalités de C ++ 17, ceci est un exemple de travail avec std :: shared_mutex, std :: allocator <std :: shared_mutex>, static thread_local dans les modèles (il y a des nuances - où allouer?), Lancement d'un grand nombre de tests dans threads de différentes manières avec la mesure du temps d'exécution:
- Instructions étape par étape sur la façon de compiler, configurer et exécuter ce banc de test - WiKi .
Si vous n'avez pas encore d'instructions étape par étape pour un système d'exploitation pratique, je vous serai reconnaissant de la contribution au référentiel pour la mise en œuvre d'ISystem et des instructions de compilation étape par étape (pour WiKi) ... Ou écrivez-moi simplement - j'essaierai de trouver le temps de lever la machine virtuelle et de décrire les étapes de l'assemblage.