Bonjour, Habr! Je vous présente le billet, qui est une adaptation textuelle de la performance de
Stella Cotton à RailsConf 2018 et une traduction de l'article
"Construire une architecture orientée services avec Rails et Kafka" de Stella Cotton.
Récemment, la transition de l'architecture monolithique aux microservices est clairement visible. Dans ce guide, nous apprendrons les bases de Kafka et comment une approche événementielle peut améliorer votre application Rails. Nous parlerons également des problèmes de surveillance et d'évolutivité des services qui fonctionnent à travers une approche événementielle.
Qu'est-ce que Kafka?
Je suis sûr que vous aimeriez avoir des informations sur la façon dont vos utilisateurs sont arrivés sur votre plateforme ou sur les pages qu'ils visitent, les boutons sur lesquels ils cliquent, etc. Une application vraiment populaire peut générer des milliards d'événements et envoyer une énorme quantité de données aux services d'analyse, ce qui peut être un sérieux défi pour votre application.
En règle générale, une partie intégrante des applications Web nécessite le
flux de données dit en temps réel . Kafka fournit une connexion tolérante aux pannes entre les
producteurs , ceux qui génèrent des événements, et les
consommateurs , ceux qui reçoivent ces événements. Il peut même y avoir plusieurs producteurs et consommateurs dans une même application. À Kafka, chaque événement existe pour une durée donnée, de sorte que plusieurs consommateurs peuvent lire le même événement encore et encore. Le cluster Kafka comprend plusieurs courtiers qui sont des instances de Kafka.
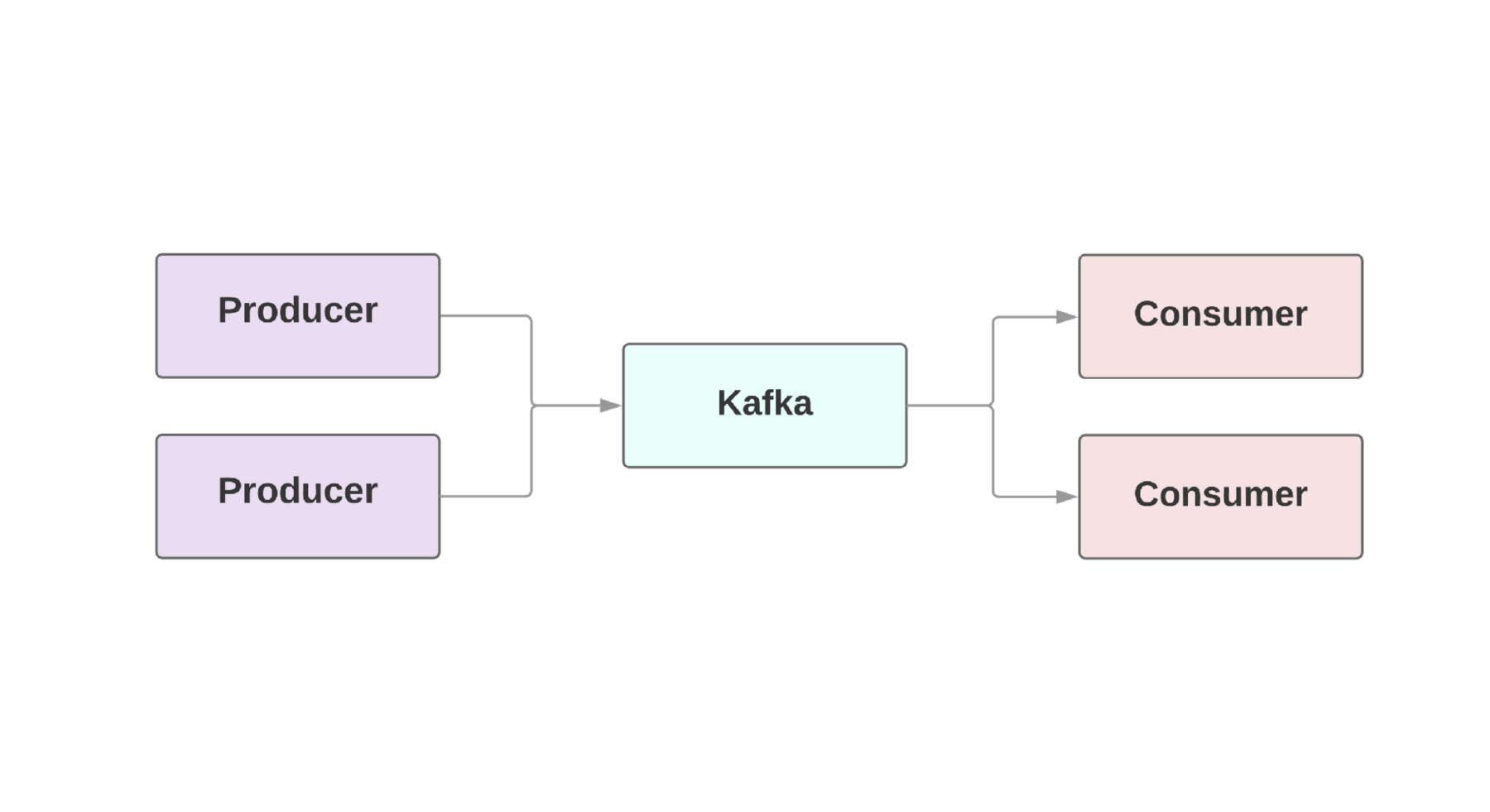
Une caractéristique clé de Kafka est la vitesse élevée du traitement des événements. Les systèmes de mise en file d'attente traditionnels, tels que AMQP, disposent d'une infrastructure qui surveille les événements traités pour chaque consommateur. Lorsque le nombre de consommateurs atteint un niveau décent, le système commence à peine à faire face à la charge, car il doit surveiller un nombre croissant de conditions. En outre, il existe de gros problèmes de cohérence entre le consommateur et le traitement des événements. Par exemple, vaut-il la peine de marquer immédiatement un message comme envoyé dès qu'il est traité par le système? Et si un consommateur tombe à l'autre bout sans recevoir de message?
Kafka possède également une architecture à sécurité intégrée. Le système s'exécute en cluster sur un ou plusieurs serveurs, qui peuvent être mis à l'échelle horizontalement en ajoutant de nouvelles machines. Toutes les données sont écrites sur le disque et copiées sur plusieurs courtiers. Afin de comprendre les possibilités d'évolutivité, il convient de jeter un coup d'œil à des sociétés telles que Netflix, LinkedIn, Microsoft. Tous envoient des milliards de messages par jour via leurs clusters Kafka!
Configurer Kafka dans Rails
Heroku fournit un
module complémentaire de cluster Kafka qui peut être utilisé pour n'importe quel environnement. Pour les applications rubis, nous vous recommandons d'utiliser la
gemme rubis-kafka . L'implémentation minimale ressemble à ceci:
Après avoir configuré la configuration, vous pouvez utiliser la gemme pour envoyer des messages. Grâce à l'envoi asynchrone d'événements, nous pouvons envoyer des messages de n'importe où:
class OrdersController < ApplicationController def create @comment = Order.create!(params) $kafka_producer.produce(order.to_json, topic: "user_event", partition_key: user.id) end end
Nous parlerons des formats de sérialisation ci-dessous, mais pour le moment, nous utiliserons le bon vieux JSON. L'argument de
topic fait référence au journal dans lequel Kafka écrit cet événement. Les sujets sont répartis dans différentes sections, ce qui vous permet de diviser les données d'un sujet particulier en différents courtiers pour une meilleure évolutivité et fiabilité. Et c'est vraiment une bonne idée d'avoir deux sections ou plus pour chaque sujet, car si l'une des sections tombe, vos événements seront enregistrés et traités de toute façon. Kafka garantit que les événements sont livrés dans l'ordre de la file d'attente dans la section, mais pas dans l'ensemble du sujet. Si l'ordre des événements est important, l'envoi de partition_key garantit que tous les événements d'un type particulier sont stockés sur la même partition.
Kafka pour vos services
Certaines des fonctionnalités qui font de Kafka un outil utile en font également un RPC de basculement entre les services. Jetez un œil à un exemple d'application de commerce électronique:
def create_order create_order_record charge_credit_card
Lorsque l'utilisateur passe une commande, la fonction
create_order est
create_order . Cela crée une commande dans le système, déduit de l'argent de la carte et envoie un e-mail avec confirmation. Comme vous pouvez le constater, les deux dernières étapes sont effectuées dans des services distincts.
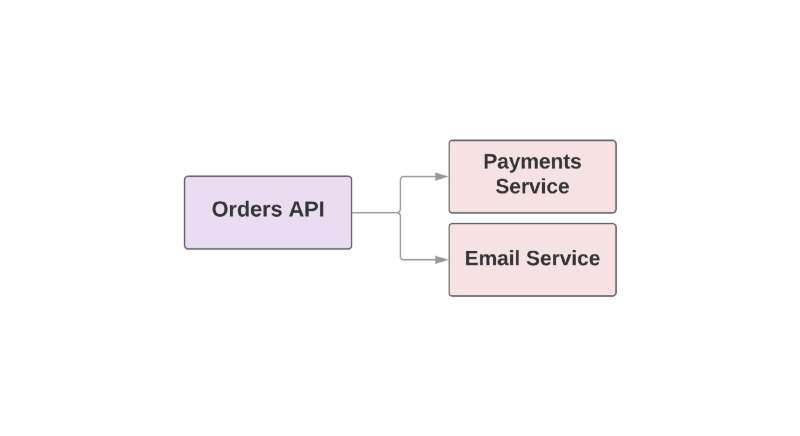
L'un des problèmes de cette approche est que le service supérieur dans la hiérarchie est responsable de la surveillance de la disponibilité du service en aval. Si le service d'envoi de lettres s'est avéré être une mauvaise journée, le service supérieur doit en être informé. Et si le service d'envoi n'est pas disponible, vous devez répéter un certain ensemble d'actions. Comment Kafka peut-il aider dans cette situation?
Par exemple:
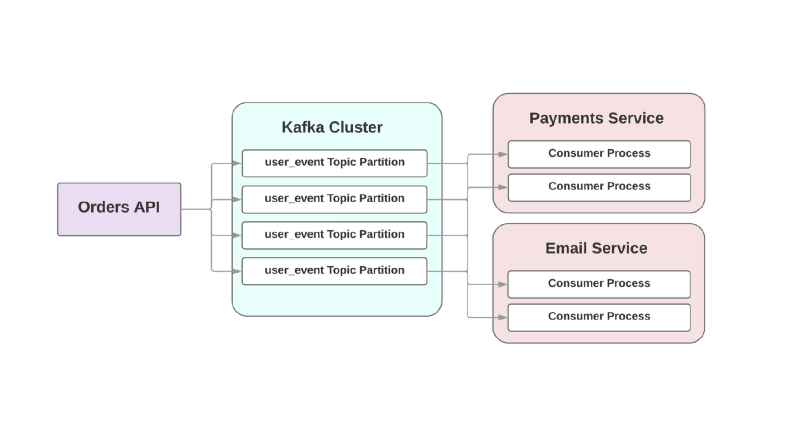
Dans cette approche événementielle, un service supérieur peut enregistrer un événement dans Kafka qu'une commande a été créée. En raison de l'approche dite
au moins une fois , l'événement sera enregistré au moins une fois à Kafka et sera mis à la disposition des consommateurs en aval pour lecture. Si le service d'envoi de lettres se trouve, l'événement attendra sur disque jusqu'à ce que le consommateur se lève et le lise.
Un autre problème avec l'architecture orientée RPC est dans les systèmes à croissance rapide: l'ajout d'un nouveau service en aval entraîne des changements en amont. Par exemple, vous souhaitez ajouter une étape supplémentaire après avoir créé une commande. Dans un monde axé sur les événements, vous devrez ajouter un autre consommateur pour gérer un nouveau type d'événement.

Intégration d'événements dans une architecture orientée services
Un article intitulé «
Que voulez-vous dire par« événementiel »par Martin Fowler traite de la confusion autour des applications événementielles. Lorsque les développeurs discutent de tels systèmes, ils parlent en fait d'un grand nombre d'applications différentes. Afin de donner une compréhension générale de la nature de ces systèmes, Fowler a défini plusieurs modèles architecturaux.
Jetons un coup d'œil à ces modèles. Si vous voulez en savoir plus, je vous conseille de lire son
rapport au GOTO Chicago 2017.
Notification d'événement
Le premier modèle Fowler est appelé
Notification d'événement . Dans ce scénario, le service producteur informe les consommateurs de l'événement avec un minimum d'informations:
{ "event": "order_created", "published_at": "2016-03-15T16:35:04Z" }
Si les consommateurs ont besoin de plus d'informations sur l'événement, ils font une demande au producteur et obtiennent plus de données.
Transfert d'état porté par l'événement
Le deuxième modèle est appelé
transfert d'état transporté par événement . Dans ce scénario, le producteur fournit des informations supplémentaires sur l'événement et le consommateur peut stocker une copie de ces données sans effectuer d'appels supplémentaires:
{ "event": "order_created", "order": { "order_id": 98765, "size": "medium", "color": "blue" }, "published_at": "2016-03-15T16:35:04Z" }
Source de l'événement
Fowler a appelé le troisième modèle
Event-Sourced et il est plutôt architectural. La sortie du modèle implique non seulement la communication entre vos services, mais aussi la préservation de la présentation de l'événement. Cela garantit que même si vous perdez la base de données, vous pouvez toujours restaurer l'état de l'application en exécutant simplement le flux d'événements enregistré. En d'autres termes, chaque événement enregistre un certain état de l'application à un certain moment.
Le gros problème avec cette approche est que le code d'application change toujours, et avec lui le format ou la quantité de données que le producteur donne peut changer. Cela rend la restauration de l'état de l'application problématique.
Séparation des responsabilités de requête de commande
Et le dernier modèle est
Ségrégation de responsabilité de requête de commande , ou CQRS. L'idée est que les actions que vous appliquez à l'objet, par exemple: créer, lire, mettre à jour, doivent être divisées en différents domaines. Cela signifie qu'un service doit être responsable de la création, un autre de la mise à jour, etc. Dans les systèmes orientés objet, tout est souvent stocké dans un seul service.
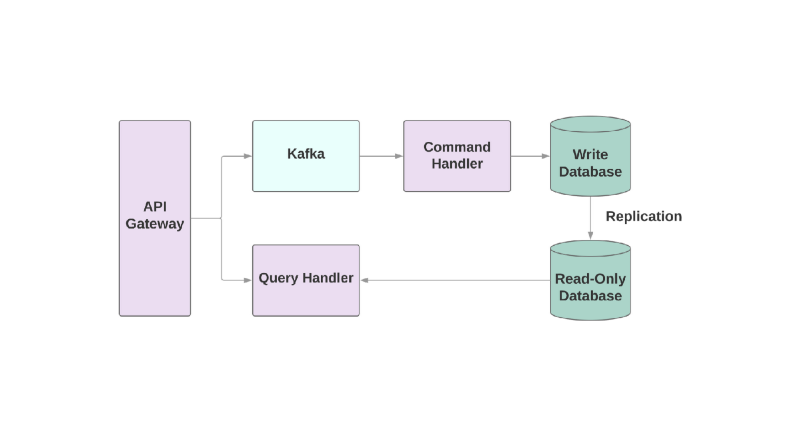
Un service qui écrit dans la base de données lit le flux d'événements et traite les commandes. Mais toutes les demandes se produisent uniquement dans la base de données en lecture seule. La division de la logique de lecture et d'écriture en deux services différents augmente la complexité, mais vous permet d'optimiser les performances séparément pour ces systèmes.
Les problèmes
Parlons de certains des problèmes que vous pourriez rencontrer lors de l'intégration de Kafka dans votre application orientée services.
Le premier problème pourrait être celui des consommateurs lents. Dans un système orienté événements, vos services devraient pouvoir traiter les événements instantanément lorsqu'ils sont reçus d'un service supérieur. Sinon, ils se bloqueront simplement sans aucune alerte sur le problème ou les délais. Le seul endroit où vous pouvez définir des délais d'attente est une connexion socket avec les courtiers Kafka. Si le service ne gère pas l'événement assez rapidement, la connexion peut être interrompue par un délai d'attente, mais la restauration du service nécessite du temps supplémentaire, car la création de telles sockets est coûteuse.
Si le consommateur est lent, comment pouvez-vous augmenter la vitesse de traitement des événements? Dans Kafka, vous pouvez augmenter le nombre de consommateurs dans un groupe, afin que davantage d'événements puissent être traités en parallèle. Mais au moins 2 consommateurs seront nécessaires pour un service: en cas de chute, les sections endommagées peuvent être réaffectées.
Il est également très important de disposer de mesures et d'alertes pour surveiller la vitesse de traitement des événements.
ruby-kafka peut fonctionner avec les alertes ActiveSupport, il dispose également de modules StatsD et Datadog, qui sont activés par défaut. De plus, la gemme fournit une
liste de mesures recommandées pour la surveillance.
Un autre aspect important de la construction de systèmes avec Kafka est la conception de consommateurs capables de gérer les défaillances. Kafka est garanti d'envoyer un événement au moins une fois; exclu le cas où le message n'a pas été envoyé du tout. Mais il est important que les consommateurs soient prêts à gérer des événements récurrents. Une façon de procéder consiste à toujours utiliser
UPSERT pour ajouter de nouveaux enregistrements à la base de données. Si l'enregistrement existe déjà avec les mêmes attributs, l'appel sera essentiellement inactif. De plus, vous pouvez ajouter un identifiant unique à chaque événement et ignorer simplement les événements qui ont déjà été traités précédemment.
Formats de données
L'une des surprises lorsque vous travaillez avec Kafka peut être son attitude simple vis-à-vis du format des données. Vous pouvez envoyer n'importe quoi en octets et les données seront envoyées au consommateur sans aucune vérification. D'une part, cela donne de la flexibilité et vous permet de ne pas vous soucier du format des données. D'un autre côté, si le producteur décide de modifier les données envoyées, il est possible qu'un consommateur finisse par se casser.
Avant de construire une architecture orientée événement, sélectionnez un format de données et analysez comment cela aidera à l'avenir à enregistrer et à développer des schémas.
Bien entendu, l'un des formats recommandés est JSON. Ce format est lisible par l'homme et pris en charge par tous les langages de programmation connus. Mais il y a des pièges. Par exemple, la taille des données finales dans JSON peut devenir extrêmement grande. Le format est requis pour stocker des paires clé-valeur, ce qui est suffisamment flexible, mais les données sont dupliquées à chaque événement. La modification du schéma est également une tâche difficile car il n'y a pas de prise en charge intégrée pour la superposition d'une clé sur une autre si vous devez renommer le champ.
L'équipe qui a créé Kafka conseille
Avro comme système de sérialisation. Les données sont envoyées sous forme binaire, et ce n'est pas le format le plus lisible par l'homme, mais à l'intérieur, il existe un support plus fiable pour les circuits. L'entité finale dans Avro comprend à la fois le schéma et les données. Avro prend également en charge les types simples, tels que les nombres, et les types complexes: dates, tableaux, etc. En outre, il vous permet d'inclure de la documentation à l'intérieur du schéma, ce qui vous permet de comprendre l'objectif d'un champ spécifique dans le système et contient de nombreux autres outils intégrés pour travailler avec le schéma.
avro-builder est un joyau créé par Salsify qui offre un DSL de type rubis pour créer des schémas. Vous pouvez en savoir plus sur Avro dans
cet article .
Information additionnelle
Si vous souhaitez savoir comment héberger Kafka ou comment il est utilisé dans Heroku, plusieurs rapports peuvent vous intéresser.
Jeff Chao à DataEngConf SF '17 «
Au-delà de 50 000 partitions: comment Heroku fonctionne et repousse les limites de Kafka à grande échelle »
Pavel Pravosud à la conférence Dreamforce '16 «
Dogfooding Kafka: comment nous avons construit le flux d'événements de la plate-forme en temps réel de Heroku »
Ayez une belle vue!