Les journaux sont une partie importante du système, vous permettant de comprendre qu'il fonctionne (ou ne fonctionne pas), comme prévu. Dans les conditions de l'architecture de microservices, le travail avec les journaux devient une discipline distincte d'une Olympiade spéciale. Vous devez résoudre immédiatement un tas de questions:
- comment écrire des journaux à partir de l'application;
- où écrire les journaux;
- comment livrer les journaux pour le stockage et le traitement;
- comment traiter et stocker les journaux.
L'utilisation des technologies de conteneurisation, désormais très répandues, ajoute du sable au sommet du râteau au champ d'options pour résoudre le problème.
Juste à propos de ce décodage du rapport de Yuri Bushmelev "Map rake on the field of collection and delivery of logs"
Peu importe, s'il vous plaît, sous le chat.
Je m'appelle Yuri Bushmelev. Je travaille chez Lazada. Aujourd'hui, je vais parler de la façon dont nous avons fait nos journaux, comment nous les avons collectés et ce que nous y écrivons.

D'où venons-nous? Qui sommes nous Lazada est la boutique en ligne n ° 1 dans six pays d'Asie du Sud-Est. Tous ces pays sont distribués par des centres de données. Il y a maintenant 4 centres de données. Pourquoi est-ce important? Parce que certaines décisions étaient dues au fait qu'il existe un lien très faible entre les centres. Nous avons une architecture de microservice. J'ai été surpris de constater que nous avons déjà 80 microservices. Lorsque j'ai commencé la tâche avec les journaux, il n'y en avait que 20. De plus, il y a un héritage PHP assez important, avec lequel vous devez également vivre et supporter. Tout cela nous génère actuellement plus de 6 millions de messages par minute dans l'ensemble du système. De plus, je montrerai comment nous essayons de vivre avec et pourquoi.

Nous devons en quelque sorte vivre avec ces 6 millions de messages. Que devons-nous en faire? 6 millions de messages dont vous avez besoin:
- envoyer depuis l'application
- accepter pour la livraison
- livrer pour analyse et stockage.
- analyser
- en quelque sorte stocker.

Lorsque trois millions de messages sont apparus, j'avais à peu près le même aspect. Parce que nous avons commencé avec quelques centimes. Il est clair que les journaux d'application y sont écrits. Par exemple, je n'ai pas pu me connecter à la base de données, j'ai pu me connecter à la base de données, mais je n'ai pas pu lire quelque chose. Mais en plus de cela, chacun de nos microservices écrit également un journal d'accès. Chaque demande arrivant à un microservice tombe dans le journal. Pourquoi on fait ça? Les développeurs veulent pouvoir tracer. Dans chaque journal d'accès, il y a un champ traceid, le long duquel une interface spéciale déroule davantage la chaîne entière et affiche magnifiquement la trace. Trace montre comment la demande s'est déroulée, ce qui aide nos développeurs à traiter rapidement les déchets non identifiés.

Comment vivre avec ça? Je vais maintenant décrire brièvement le domaine des options - comment en général ce problème est résolu. Comment résoudre le problème de la collecte, du transfert et du stockage des journaux.

Comment écrire depuis l'application? Il est clair qu'il existe différentes manières. En particulier, il existe de bonnes pratiques, comme nous le disent les camarades à la mode. Il y a une ancienne école sous deux formes, comme l'ont dit les grands-pères. Il existe d'autres moyens.

Avec la collecte de journaux sur la même situation. Il n'y a pas beaucoup d'options pour résoudre cette partie particulière. Il y en a déjà plus, mais pas autant.

Mais avec la livraison et l'analyse ultérieure - le nombre de variations commence à exploser. Je ne décrirai pas chaque option maintenant. Je pense que les principales options sont entendues par tous ceux qui étaient intéressés par le sujet.

Je vais montrer comment nous l'avons fait à Lazada et comment tout a commencé.

Il y a un an, je suis venu à Lazada et ils m'ont envoyé dans un projet sur les grumes. C'était comme ça. Le journal de l'application a été écrit sur stdout et stderr. Ils ont tout fait à la mode. Mais ensuite, les développeurs l'ont jeté hors des flux standard, puis là, les spécialistes de l'infrastructure vont le régler d'une manière ou d'une autre. Entre les spécialistes de l'infrastructure et les développeurs, il y a aussi des libérateurs qui ont dit: "euh ... d'accord, enveloppons-les simplement dans un fichier avec un shell, c'est tout." Et comme tout cela se trouve dans le conteneur, ils l'ont emballé directement dans le conteneur lui-même, ont téléchargé le catalogue à l'intérieur et l'ont mis là. Je pense qu'il est à peu près évident pour tout le monde ce qui en est ressorti.

Voyons un peu plus loin. Comment délivrons-nous ces journaux? Quelqu'un a choisi td-agent, qui est en fait couramment, mais pas tout à fait couramment. Je ne comprenais toujours pas la relation de ces deux projets, mais ils semblent être à peu près la même chose. Et ce fluentd, écrit en Ruby, lit les fichiers journaux, les analyse en JSON pour certaines périodes régulières. Puis il les a envoyés à Kafka. Et dans Kafka pour chaque API, nous avions 4 sujets distincts. Pourquoi 4? Parce qu'il y a du live, il y a de la mise en scène, et parce qu'il y a stdout et stderr. Les développeurs leur donnent naissance et les ingénieurs d'infrastructure doivent les créer à Kafka. De plus, Kafka était contrôlée par un autre département. Par conséquent, il était nécessaire de créer un ticket pour qu'ils créent 4 sujets pour chaque API là-bas. Tout le monde l'a oublié. En général, il y avait des déchets et des fumées.
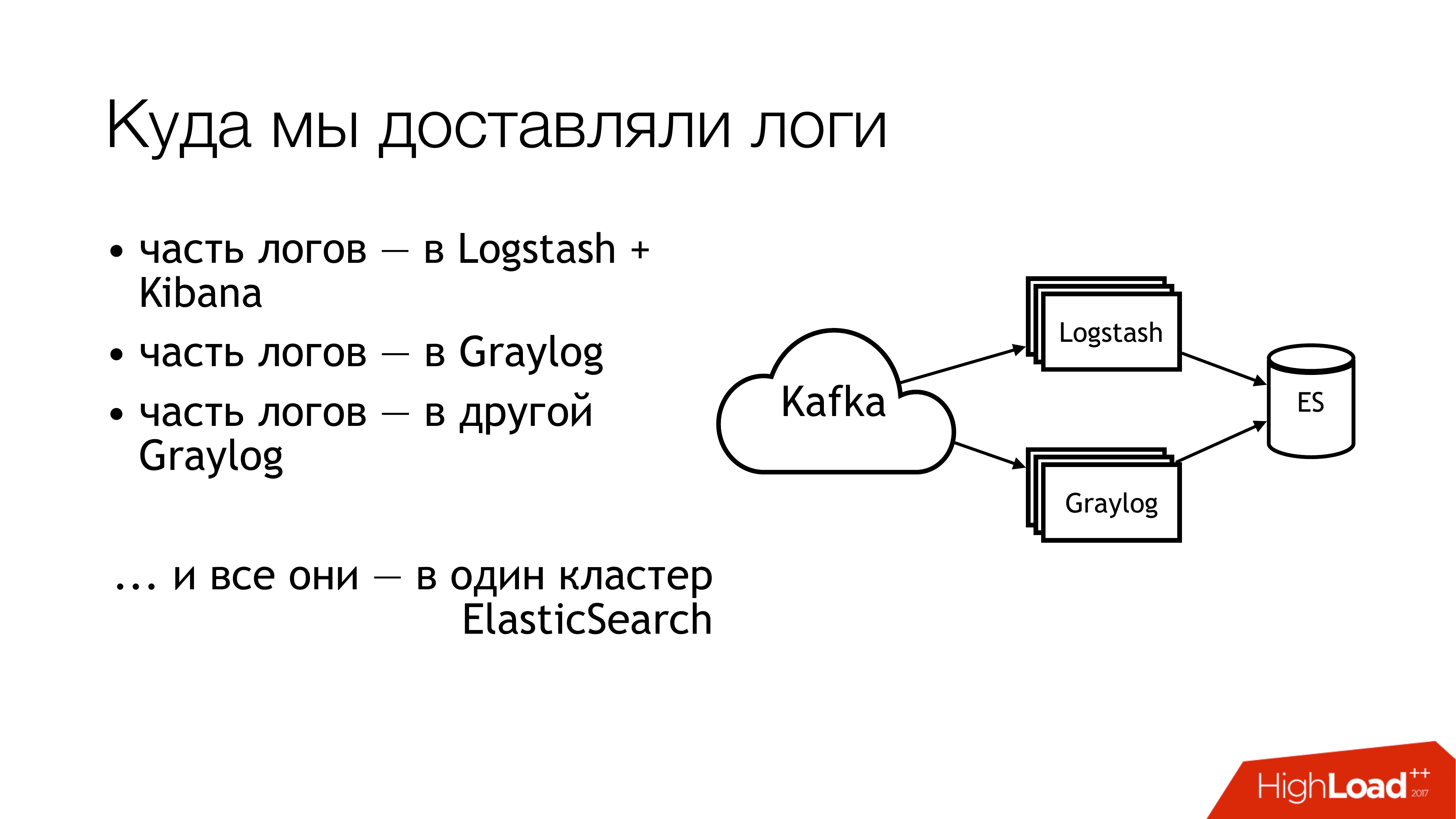
Qu'avons-nous fait ensuite avec ça? Nous l'avons envoyé à Kafka. Plus loin de Kafka, la moitié des grumes s'est envolée pour Logstash. L'autre moitié des journaux a été partagée. Une partie a volé dans un Graylog, une partie - dans un autre Graylog. En conséquence, tout cela s'est envolé dans un cluster Elasticsearch. Autrement dit, tout ce gâchis est finalement tombé là. Vous n'avez pas à faire ça!

Voici à quoi cela ressemble si vous regardez à distance d'en haut. Ne fais pas ça! Ici, les chiffres indiquent immédiatement les zones à problème. Il y en a plus, mais 6 sont vraiment très problématiques, avec lesquelles vous devez faire quelque chose. Je vais en parler séparément maintenant.

Ici (1,2,3), nous écrivons des fichiers et, en conséquence, voici trois râteaux à la fois.
Le premier (1) est que nous devons les écrire quelque part. Je ne voudrais pas toujours donner à l'API la possibilité d'écrire directement dans un fichier. Il est souhaitable que l'API soit isolée dans le conteneur, et encore mieux, qu'elle soit en lecture seule. Je suis un administrateur système, j'ai donc une vision légèrement alternative de ces choses.
Le deuxième point (2,3) - nous avons beaucoup de demandes venant à l'API. L'API écrit de nombreuses données dans un fichier. Les fichiers augmentent. Nous devons les faire pivoter. Sinon, il n'y a aucun moyen d'obtenir des disques. Leur rotation est mauvaise car ils sont redirigés via le shell vers un répertoire. Nous ne pouvons en aucun cas le déplacer. On ne peut pas dire à une application de redécouvrir les descripteurs. Parce que les développeurs vous regarderont comme un idiot: «Quels sont les descripteurs? Nous écrivons généralement à stdout. » Les ingénieurs d'infrastructure ont fait copytruncate dans logrotate, qui ne fait qu'une copie du fichier et trankeytit l'original. En conséquence, entre ces processus de copie, l'espace disque se termine généralement.
(4) Nous avions différents formats et nous étions dans différentes API. Ils étaient légèrement différents, mais l'expression rationnelle devait être écrite différemment. Comme tout cela était contrôlé par Puppet, il y avait un grand nombre de classes avec leurs cafards. De plus, td-agent la plupart du temps pouvait manger de la mémoire, stupide, il pouvait simplement prétendre que cela fonctionnait et ne rien faire. Dehors, il était impossible de comprendre qu'il ne faisait rien. Au mieux, il tombera et quelqu'un viendra le chercher plus tard. Plus précisément, l'alerte arrivera et quelqu'un passera la main.

(6) Et le plus de déchets et de déchets - c'était Elasticsearch. Parce que c'était une ancienne version. Parce que nous n'avions pas de maîtres dédiés à cette époque. Nous avions des journaux hétérogènes dans lesquels les champs pouvaient se croiser. Différents journaux d'applications différentes pourraient être écrits avec les mêmes noms de champ, mais en même temps, il pourrait y avoir des données différentes à l'intérieur. Autrement dit, un journal est fourni avec Entier dans le champ, par exemple, niveau. Un autre journal contient String dans le champ de niveau. En l'absence de cartographie statique, une chose aussi merveilleuse est obtenue. Si, après la rotation de l'index dans elasticsearch, le premier message avec une chaîne est arrivé, alors nous vivons normalement. Et s'il est arrivé en premier avec Integer, tous les messages ultérieurs qui sont arrivés avec String sont simplement ignorés. Parce que le type de champ ne correspond pas.

Nous avons commencé à poser ces questions. Nous avons décidé de ne pas rechercher les coupables.

Mais quelque chose doit être fait! La chose évidente est de fixer des normes. Nous avions déjà des normes. Nous en avons eu un peu plus tard. Heureusement, un format de journal uniforme pour toutes les API était déjà approuvé à l'époque. Il est inscrit directement dans les normes d'interaction des services. Par conséquent, ceux qui souhaitent recevoir des journaux doivent les écrire dans ce format. Si quelqu'un n'écrit pas de journaux dans ce format, nous ne garantissons rien.
De plus, je voudrais établir une norme unique pour les méthodes d'enregistrement, de livraison et de collecte des journaux. En fait, où les écrire et comment les livrer. La situation idéale est lorsque les projets utilisent la même bibliothèque. Voici une bibliothèque de journalisation distincte pour Go, il existe une bibliothèque distincte pour PHP. Tout le monde que nous avons - tout le monde devrait les utiliser. Pour le moment, je dirais que nous l'obtenons à 80%. Mais certains continuent de manger des cactus.
Et là (sur la diapositive) apparaissait à peine «SLA pour la livraison de journaux». Il n'est pas encore là, mais nous y travaillons. Parce que c'est très pratique lorsque l'infra dit que si vous écrivez dans tel ou tel format à tel ou tel endroit et pas plus de N messages par seconde, alors nous sommes susceptibles de livrer tel ou tel là-bas. Cela soulage un tas de maux de tête. S'il y a un SLA, alors c'est tout simplement merveilleux!

Comment avons-nous commencé à résoudre le problème? Le râteau principal était avec td-agent. Il n'était pas clair où allaient les journaux. Sont-ils livrés? Vont-ils? Où sont-ils? Par conséquent, le premier élément a été décidé de remplacer td-agent. J'ai brièvement esquissé les options pour le remplacer.
Fluentd Premièrement, je l'ai rencontré lors d'un précédent emploi et il y tombait aussi périodiquement. Deuxièmement, c'est la même chose, seulement de profil.
Filebeat. Comment était-ce pratique pour nous? Le fait qu'il soit en Go, et nous avons beaucoup d'expertise en Go. En conséquence, si cela, nous pourrions en quelque sorte l'ajouter pour nous-mêmes. Par conséquent, nous ne l'avons pas pris. De sorte que même aucune tentation ne devait commencer à le réécrire pour vous-même.
La solution évidente pour le sysadmin est tous les syslogs dans cette quantité (syslog-ng / rsyslog / nxlog).
Ou écrivez quelque chose de notre côté, mais nous l'avons laissé tomber, tout comme le battement de fichiers. Si vous écrivez quelque chose, il vaut mieux écrire quelque chose d'utile pour les affaires. Pour la livraison des journaux, il est préférable de prendre quelque chose de prêt.
Par conséquent, le choix se résumait en fait au choix entre syslog-ng et rsyslog. Il s'est penché vers rsyslog simplement parce que nous avions déjà des classes pour rsyslog dans Puppet, et je n'ai trouvé aucune différence évidente entre eux. Qu'est-ce que Syslog, qu'est-ce que Syslog? Oui, quelqu'un a une documentation pire, quelqu'un a mieux. Il sait comment, et il - d'une manière différente.

Et un peu sur rsyslog. Tout d'abord, c'est cool car il a beaucoup de modules. Il a RainerScript lisible par l'homme (un langage de configuration moderne). Le bonus impressionnant est que nous pouvons émuler le comportement de l'agent td en utilisant ses moyens habituels, et rien n'a changé pour les applications. Autrement dit, nous changeons td-agent en rsyslog, mais nous ne touchons pas à tout le reste. Et immédiatement, nous obtenons une livraison de travail. Ensuite, mmnormalize est une chose géniale dans rsyslog. Il vous permet d'analyser les journaux, mais pas d'utiliser Grok et regexp. Elle crée un arbre de syntaxe abstrait. Il analyse les journaux approximativement, car le compilateur analyse les codes source. Cela vous permet de travailler très rapidement, de consommer peu de CPU et, en général, c'est très cool. Il y a des tonnes d'autres bonus. Je ne m'arrêterai pas à leur sujet.

Rsyslog a encore un tas de défauts. Ils sont à peu près les mêmes que les bonus. Les principaux problèmes - vous devez être capable de le faire cuire et vous devez sélectionner la version.
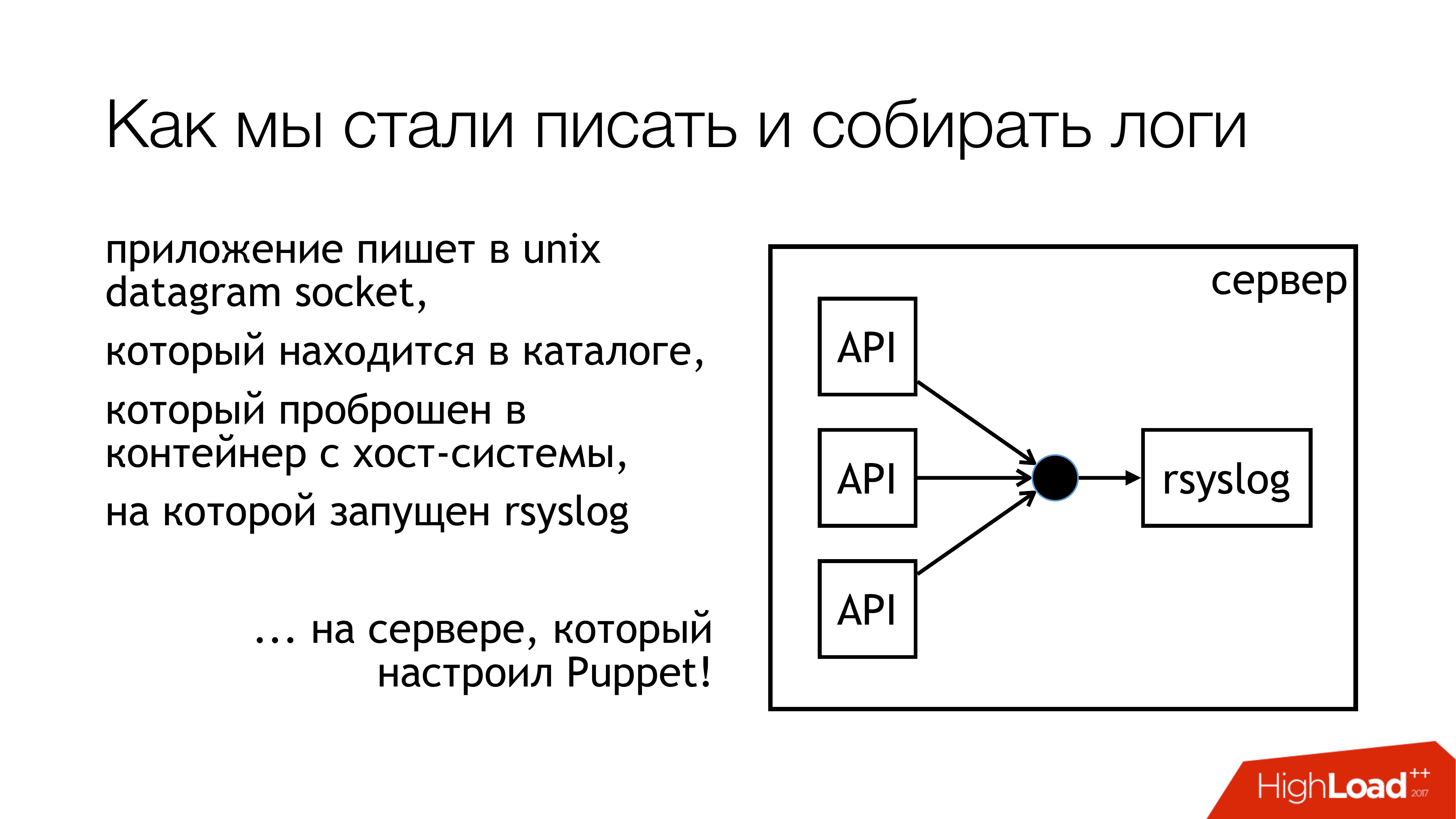
Nous avons décidé d'écrire des journaux sur le socket Unix. Et pas dans / dev / log, parce que nous avons de la bouillie dans les journaux système, il y a du journald dans ce pipeline. Écrivons donc sur un socket personnalisé. Nous l'attachons à un ensemble de règles distinct. Nous n'interférerons pas. Tout sera transparent et clair. Nous l'avons donc fait. Le répertoire avec ces sockets est standardisé et est transmis à tous les conteneurs. Les conteneurs peuvent voir la prise dont ils ont besoin, l'ouvrir et l'écrire.
Pourquoi pas un fichier? Parce que tout le monde a lu un article sur Badushechka , qui a essayé de transférer le fichier vers docker, et il s'est avéré qu'après avoir redémarré rsyslog, le descripteur de fichier change, et docker perd ce fichier. Il garde ouvert autre chose, mais pas la même prise où ils écrivent. Nous avons décidé que nous contournerions ce problème, et en même temps, nous contournerions le problème de blocage.

Rsyslog effectue les actions indiquées sur la diapositive et envoie les journaux soit au relais soit à Kafka. Kafka correspond à l'ancienne. Relais - J'ai essayé d'utiliser rsyslog pur pour fournir des journaux. Sans Message Queue, outils rsyslog standard. Fondamentalement, cela fonctionne.

Mais il y a des nuances avec la façon de les entasser plus tard dans cette partie (Logstash / Graylog / ES). Cette partie (rsyslog-rsyslog) est utilisée entre les centres de données. Voici un lien TCP compressé, qui vous permet d'économiser de la bande passante et, par conséquent, d'augmenter en quelque sorte la probabilité que nous recevions une sorte de journaux d'un autre centre de données dans des conditions où le canal est plein. Parce que nous avons l'Indonésie, où tout va mal. C'est là que se situe ce problème constant.

Nous avons réfléchi à la façon dont nous surveillons réellement, avec quelle probabilité les journaux que nous avons enregistrés à partir de l'application atteignent-ils cette fin? Nous avons décidé d'obtenir les métriques. Rsyslog a son propre module de collecte de statistiques, qui a une sorte de compteurs. Par exemple, il peut vous montrer la taille de la file d'attente ou le nombre de messages reçus lors d'une telle action. Quelque chose peut déjà leur être retiré. De plus, il a des compteurs personnalisés qui peuvent être configurés et il vous montrera, par exemple, le nombre de messages que certaines API ont écrit. Ensuite, j'ai écrit rsyslog_exporter en Python, et nous avons tout envoyé à Prométhée et tracé. Les métriques de Graylog voulaient vraiment, mais jusqu'à présent, nous n'avons pas eu le temps de les configurer.

Quels sont les problèmes? Des problèmes sont survenus avec le fait que nous avons découvert (SOUDEMENT!) Que nos API Live écrivent 50 000 messages par seconde. Il s'agit uniquement d'une API en direct sans mise en scène. Et Graylog nous montre seulement 12 mille messages par seconde. Et une question raisonnable s'est posée, mais où sont les restes? D'où nous avons conclu que Graylog ne peut tout simplement pas faire face. Ils ont regardé, et, en effet, Graylog avec Elasticsearch ne maîtrisait pas ce flux.
De plus, d'autres découvertes que nous avons faites au cours du processus.
L'écriture sur le socket est bloquée. Comment est-ce arrivé? Lorsque j'ai utilisé rsyslog pour la livraison, à un moment donné, notre canal entre les centres de données s'est rompu. La livraison s'est levée à un endroit, la livraison s'est levée à un autre endroit. Tout cela est arrivé à une machine avec des API qui écrivent dans le socket rsyslog. Il y avait une file d'attente. Ensuite, la file d'attente pour l'écriture sur le socket Unix a été remplie, ce qui par défaut est de 128 paquets. Et la prochaine écriture () dans l'application est bloquée. Lorsque nous avons examiné la bibliothèque que nous utilisons dans les applications sur Go, il a été écrit que l'écriture dans le socket se produit en mode non bloquant. Nous étions sûrs que rien ne bloquait. Parce que nous avons lu un article sur Badushechka qui a écrit à ce sujet. Mais il y a un moment. Autour de cet appel, il y avait toujours un cycle sans fin dans lequel une tentative était constamment faite pour pousser le message dans la prise. Nous ne l'avons pas remarqué. J'ai dû réécrire la bibliothèque. Depuis lors, il a changé plusieurs fois, mais maintenant nous nous sommes débarrassés des verrous dans tous les sous-systèmes. Par conséquent, vous pouvez arrêter rsyslog et rien ne tombera.
Il est nécessaire de surveiller la taille des files d'attente, ce qui permet de ne pas marcher sur ce râteau. Premièrement, nous pouvons surveiller quand nous commençons à perdre des messages. Deuxièmement, nous pouvons contrôler qu'en principe nous avons des problèmes de livraison.
Et un autre moment désagréable - une amplification 10 fois dans une architecture de microservices - c'est très facile. Nous n'avons pas beaucoup de demandes entrantes, mais à cause du graphique que ces messages parcourent, à cause des journaux d'accès, nous augmentons vraiment la charge sur les journaux environ une fois sur dix. Malheureusement, je n'ai pas eu le temps de calculer les chiffres exacts, mais les microservices - ils le sont. Il faut garder cela à l'esprit. Il s'avère qu'à l'heure actuelle, le sous-système de collecte de journaux est le plus chargé dans Lazada.

Comment résoudre le problème elasticsearch? Si vous devez obtenir rapidement les journaux en un seul endroit, afin de ne pas exécuter sur toutes les machines et de ne pas les collecter là-bas, utilisez le stockage de fichiers. Cela est garanti de fonctionner. Il est fabriqué à partir de n'importe quel serveur. Il vous suffit d'y coller les disques et de mettre syslog. Après cela, vous êtes assuré d'avoir tous les journaux en un seul endroit. De plus, il sera déjà possible d'ajuster lentement elasticsearch, graylog, autre chose. Mais vous aurez déjà tous les journaux et, de plus, vous pourrez les stocker dans un nombre suffisant de baies de disques.

Au moment de mon rapport, le circuit a commencé à ressembler à ceci. Nous avons pratiquement arrêté d'écrire dans le fichier. Maintenant, très probablement, nous désactiverons les restes. Sur les machines locales exécutant l'API, nous arrêterons d'écrire dans les fichiers. Tout d'abord, il existe un stockage de fichiers qui fonctionne très bien. Deuxièmement, la place sur ces machines est constamment épuisée, il est nécessaire de la surveiller en permanence.
Cette partie avec Logstash et Graylog, ça monte vraiment. Par conséquent, nous devons nous en débarrasser. Vous devez choisir une chose.

Nous avons décidé de jeter Logstash et Kibana. Parce que nous avons un service de sécurité. Quelle est la connexion? La connexion est que Kibana sans X-Pack et sans Shield ne permet pas de différencier les droits d'accès aux journaux. Par conséquent, ils ont pris Graylog. Il a tout. Je ne l'aime pas, mais ça marche. Nous avons acheté du fer neuf, y avons mis du Graylog frais et déplacé tous les journaux aux formats stricts dans un Graylog distinct. Nous avons résolu le problème avec différents types de domaines identiques sur le plan organisationnel.

Ce qui est exactement inclus dans le nouveau Graylog. Nous venons de tout enregistrer dans le docker. Nous avons pris un tas de serveurs, déployé trois instances Kafka, 7 serveurs Graylog version 2.3 (parce que je voulais Elasticsearch version 5). HDD . indexing rate 100 . 140 .

! . 6 . Graylog . - .

. SSD. . 160 . , , .

. , , , , high availability. . , . , failover .
Graylog.
rate limit , API, bandwidth .
, - SLA c , . , .
.

, , . -, . -, syslog — . -, rsyslog , . .
.
: - … (filebeat?)
: . . API , , . pipe. : « , , »? , , : « , ».
: HDFS?
: . , , , , long term solution.
: .
: . "" .
: rsyslog. TCP, UDP. UDP, ?
: . , , . , : « , - , - », «! , , , .» . , ? , ? best effort. , 100% . . .
: API - , , ? - .
: , . . , . , API . rsyslog . API , , timestamp . Graylog, timestamp. .
: Timestamp .
: Timestamp API. , , . NTP. API timestamp . rsyslog .
: . , . ? ?
: . - . , . . Log Relay. Rsyslog . . . . . . , (), Graylog. storage. , , . . .
: ?
: ( ) .
: , ?
: , . . , Go API, . , socket. . . socket. , . . , . prometheus, Grafana . . , .
: elasticsearch . ?
: .
: ?
: . .
: rsyslog - ?
: unix socket. 128 . . . , 128 . , , , , . , . .
c : JSON?
: JSON relay, . Graylog, JSON . , , rsyslog. issue, .
c : Kafka? RabbitMQ? Graylog ?
: Graylog . Graylog . . . , , . rsyslog elasticsearch Kibana. . , Graylog Kibana. Logstash . , rsyslog. elasticsearch. Graylog - . . .
Kafka. . , , . . , , . RabbitMQ… c RabbitMQ. RabbitMQ . , . , . . . Graylog AMQP 0.9, rsyslog AMQP 1.0. , , . . Kafka. . omkafka rsyslog, , , rsyslog. .
Question : Utilisez-vous Kafka parce que vous en aviez? Pas utilisé à d'autres fins?
Réponse : Kafka, qui a été utilisé par l'équipe Data Sience. Il s'agit d'un projet complètement distinct, sur lequel, malheureusement, je ne peux rien dire. Je ne sais pas. Elle était dirigée par l'équipe Data Science. Lorsque les journaux ont commencé, ils ont décidé de l'utiliser pour ne pas mettre le leur. Nous avons maintenant mis à jour Graylog et nous avons perdu la compatibilité, car il existe une ancienne version de Kafka. Nous devions acheter le nôtre. En même temps, nous nous sommes débarrassés de ces quatre sujets pour chaque API. Nous avons créé un sujet large pour tous en direct, un sujet large pour toutes les mises en scène et simplement tout y faire. Graylog ratisse tout cela en parallèle.
Question : Pourquoi ce chamanisme avec des prises est-il nécessaire? Avez-vous essayé d'utiliser le pilote de journal syslog pour les conteneurs?
Réponse : Au moment où nous avons posé cette question, nous avions une relation tendue avec le docker. C'était docker 1.0 ou 0.9. Docker lui-même était bizarre. Deuxièmement, si vous y enfoncez également les journaux ... J'ai une suspicion non vérifiée qu'il passe tous les journaux par lui-même, via le démon docker. Si nous avons une API qui devient folle, les autres API sont bloquées dans le fait qu'elles ne peuvent pas envoyer stdout et stderr. Je ne sais pas où cela mènera. J'ai une suspicion au niveau du sentiment que vous n'avez pas besoin d'utiliser le pilote docker syslog à cet endroit. Notre département de tests fonctionnels possède son propre cluster Graylog avec journaux. Ils utilisent des pilotes de journal docker et tout semble bien se passer là-bas. Mais ils écrivent immédiatement GELF à Graylog. Nous, à ce moment où tout cela était en place, nous en avions besoin pour fonctionner. Peut-être plus tard, quand quelqu'un viendra et dira qu'il fonctionne normalement depuis cent ans, nous essaierons.
Question : Vous effectuez la livraison entre les centres de données sur rsyslog. Pourquoi pas à Kafka?
Réponse : Nous faisons les deux, et donc en réalité. Pour deux raisons. Si le canal est complètement mort, nous avons tous les journaux, même sous forme compressée, nous ne l'explorerons pas. Et la kafka leur permet simplement de se perdre dans le processus. De cette façon, nous nous débarrassons de coller ces journaux. Nous utilisons simplement Kafka dans ce cas directement. Si nous avons un bon canal et que nous voulons le libérer, alors nous utilisons leur rsyslog. Mais en fait, vous pouvez le configurer pour qu'il supprime lui-même ce qui n'a pas rampé. Pour le moment, nous utilisons simplement la livraison rsyslog directement, quelque part Kafka.