Introduction aux systèmes d'exploitation
Bonjour, Habr! Je veux attirer votre attention sur une série d'articles-traductions d'une littérature intéressante à mon avis - OSTEP. Cet article décrit assez en profondeur le travail des systèmes d'exploitation de type Unix, à savoir le travail avec les processus, les différents planificateurs, la mémoire et d'autres composants similaires qui composent le système d'exploitation moderne. L'original de tous les matériaux que vous pouvez voir
ici . Veuillez noter que la traduction a été effectuée de manière non professionnelle (assez librement), mais j'espère avoir conservé le sens général.
Les travaux de laboratoire sur ce sujet peuvent être trouvés ici:
Autres parties:
Et vous pouvez regarder ma chaîne en
télégramme =)
Planification: file d'attente de commentaires à plusieurs niveaux
Dans cette conférence, nous parlerons des problèmes de développement de l’une des approches les plus
Planification appelée
file d'attente de rétroaction à plusieurs niveaux (MLFQ). L'ordonnanceur MLFQ a été décrit pour la première fois en 1962 par Fernando J. Corbató dans un système appelé Compatible Time-Sharing System (CTSS). Ces travaux (y compris des travaux ultérieurs sur Multics) ont ensuite été soumis au prix Turing. L'ordonnanceur a ensuite été amélioré et a acquis un aspect que l'on retrouve déjà dans certains systèmes modernes.
L'algorithme MLFQ tente de résoudre 2 problèmes transversaux fondamentaux.
Tout d'abord , il essaie d'optimiser le délai d'exécution, qui, comme nous l'avons examiné dans la conférence précédente, est optimisé en commençant au début de la file d'attente des tâches les plus courtes. Cependant, l'OS ne sait pas combien de temps fonctionnera tel ou tel processus, et c'est la connaissance nécessaire pour le fonctionnement des algorithmes SJF, STCF.
Deuxièmement , MLFQ essaie de rendre le système réactif aux utilisateurs (par exemple, ceux qui sont assis et regardent l'écran en attendant que la tâche soit terminée) et minimise ainsi le temps de réponse. Malheureusement, des algorithmes comme RR réduisent le temps de réponse, mais ils ont un très mauvais effet sur les métriques de délai d'exécution. D'où notre problème: comment concevoir un ordonnanceur qui répondra à nos exigences tout en ignorant la nature du processus en général? Comment l'ordonnanceur peut-il connaître les caractéristiques des tâches qu'il lance et prendre ainsi de meilleures décisions de planification?
L'essence du problème: comment planifier la formulation des tâches sans une parfaite connaissance? Comment développer un planificateur qui minimise simultanément le temps de réponse pour les tâches interactives et en même temps minimise le temps d'exécution sans connaître le temps pour terminer la tâche?Remarque: apprendre des événements précédents
La gamme MLFQ est un excellent exemple d'un système qui apprend des événements passés pour prédire l'avenir. Des approches similaires se retrouvent souvent dans le système d'exploitation (et dans de nombreuses autres branches de l'informatique, y compris les branches de prédiction matérielle et les algorithmes de mise en cache). Des déplacements similaires fonctionnent lorsque les tâches ont des phases comportementales et sont donc prévisibles.
Cependant, il faut être prudent avec une telle technique, car les prédictions peuvent très facilement s'avérer fausses et conduire le système à prendre des décisions pires que ce serait sans connaissance du tout.
MLFQ: règles de base
Considérez les règles de base de l'algorithme MLFQ. Bien qu'il existe plusieurs implémentations de cet algorithme, les approches de base sont similaires.
Dans l'implémentation que nous considérerons, dans MLFQ, il y aura plusieurs files d'attente distinctes, chacune ayant une priorité différente. À tout moment, une tâche prête à être exécutée se trouve dans une file d'attente. MLFQ utilise des priorités pour décider quelle tâche exécuter, c'est-à-dire une tâche avec une priorité plus élevée (une tâche de la file d'attente avec une priorité plus élevée) sera lancée en premier.
Il ne fait aucun doute que plusieurs tâches peuvent se trouver dans une file d'attente particulière, elles auront donc la même priorité. Dans ce cas, le moteur RR sera utilisé pour planifier le lancement parmi ces tâches.
Ainsi, nous arrivons à deux règles de base pour MLFQ:
- Règle 1: Si priorité (A)> Priorité (B), la tâche A démarrera (B ne sera pas)
- Règle 2: Si priorité (A) = priorité (B), A&B sont démarrés à l'aide de RR
Sur la base de ce qui précède, les éléments clés de la planification du MLFQ sont les priorités. Au lieu de définir une priorité fixe pour chaque tâche, MLFQ modifie sa priorité en fonction du comportement observé.
Par exemple, si une tâche quitte constamment le travail sur le CPU en attendant la saisie au clavier, MLFQ maintiendra la priorité du processus à un niveau élevé, car c'est ainsi que le processus interactif devrait fonctionner. Si, au contraire, la tâche utilise constamment et intensivement le CPU pendant une longue période, MLFQ diminuera sa priorité. Ainsi, MLFQ étudiera le comportement des processus au moment de leur fonctionnement et utilisera le comportement.
Tirons un exemple de l'apparence des files d'attente à un moment donné, puis nous obtenons quelque chose comme ceci:

Dans ce schéma, 2 processus A et B sont dans la file d'attente avec la priorité la plus élevée. Le processus C est quelque part au milieu, et le processus D est à la toute fin de la file d'attente. Selon les descriptions ci-dessus de l'algorithme MLFQ, le planificateur exécutera les tâches uniquement avec la priorité la plus élevée selon RR, et les tâches C, D seront sans travail.
Naturellement, un instantané statique ne donnera pas une image complète du fonctionnement de MLFQ.
Il est important de comprendre exactement comment l'image change au fil du temps.
Tentative 1: comment modifier la priorité
À ce stade, vous devez décider comment MLFQ changera le niveau de priorité de la tâche (et donc la position de la tâche dans la file d'attente) pendant son cycle de vie. Pour ce faire, vous devez garder à l'esprit le flux de travail: un certain nombre de tâches interactives avec un temps d'exécution court (et donc une libération fréquente du processeur) et plusieurs tâches longues qui utilisent le processeur tout leur temps de travail, tandis que le temps de réponse pour de telles tâches n'est pas important. Et donc, vous pouvez faire la première tentative pour implémenter l'algorithme MLFQ avec les règles suivantes:
- Règle 3: Lorsqu'une tâche entre dans le système, elle est mise en file d'attente avec le plus haut
- priorité.
- Règle 4a: Si une tâche utilise la totalité de la fenêtre de temps qui lui est allouée,
- la priorité baisse.
- Règle 4b: Si la tâche libère le CPU avant l'expiration de sa fenêtre de temps, alors elle
- reste avec la même priorité.
Exemple 1: une seule tâche de longue duréeComme vous pouvez le voir dans cet exemple, la tâche à l'admission est posée avec la plus haute priorité. Après une fenêtre temporelle de 10 ms, le processus est abaissé en priorité par le planificateur. Après la fenêtre de temps suivante, la tâche tombe finalement à la priorité la plus basse du système, où elle reste.
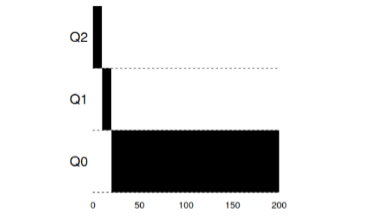 Exemple 2: Ils ont évoqué une courte tâche
Exemple 2: Ils ont évoqué une courte tâcheVoyons maintenant un exemple de la façon dont MLFQ tentera de se rapprocher de SJF. Il y a deux tâches dans cet exemple: A, qui est une tâche de longue durée qui occupe constamment le CPU, et B, qui est une courte tâche interactive. Supposons que A ait déjà fonctionné pendant un certain temps au moment où la tâche B arrive.
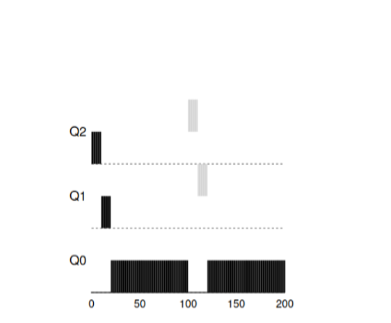
Dans ce graphique, les résultats du script sont visibles. La tâche A, comme toute tâche utilisant un processeur, est tout en bas. La tâche B arrivera à T = 100 et sera placée dans la file d'attente avec la priorité la plus élevée. Le temps de son travail étant court, il se terminera avant d'atteindre la dernière étape.
À partir de cet exemple, il faut comprendre l'objectif principal de l'algorithme: puisque l'algorithme ne connaît pas une tâche longue ou courte, il suppose tout d'abord que la tâche est courte et lui donne la plus haute priorité. Si c'est une tâche vraiment courte, alors elle sera accomplie rapidement, sinon si c'est une tâche longue, elle descendra lentement en priorité et prouvera bientôt que c'est une tâche vraiment longue qui ne nécessite pas de réponse.
Exemple 3: qu'en est-il des E / S?Jetez maintenant un œil à l'exemple d'E / S. Comme indiqué dans la règle 4b, si un processus libère un processeur sans utiliser pleinement son temps de processeur, il reste au même niveau de priorité. L'intention de cette règle est assez simple - si une tâche interactive effectue de nombreuses opérations d'E / S, par exemple, en attendant qu'un utilisateur appuie sur une touche ou une souris, une telle tâche libérera le processeur avant la fenêtre allouée. Nous ne voudrions pas omettre une telle tâche par priorité, et elle restera donc au même niveau.

Cet exemple montre comment l'algorithme fonctionnera avec de tels processus - une tâche interactive B, qui n'a besoin d'un processeur que pendant 1 ms avant d'effectuer le processus d'E / S, et une longue tâche A, qui utilise le processeur tout le temps.
MLFQ détient le processus B avec la plus haute priorité car il se poursuit tout le temps.
libérer le CPU. Si B est une tâche interactive, l'algorithme a alors atteint son objectif de lancer rapidement des tâches interactives.
Problèmes avec l'algorithme MLFQ actuelDans les exemples précédents, nous avons construit la version de base de MLFQ. Et il semble qu'il fasse bien et honnêtement son travail, en répartissant honnêtement le temps processeur entre les tâches longues et en permettant aux tâches courtes ou aux tâches accédant intensivement aux E / S de fonctionner rapidement. Malheureusement, cette approche contient plusieurs problèmes graves.
Premièrement , le problème de la faim: si le système a beaucoup de tâches interactives, ils consommeront tout le temps du processeur et donc pas une seule longue tâche n'aura la possibilité d'être exécutée (ils meurent de faim).
Deuxièmement , les utilisateurs intelligents pourraient écrire leurs programmes afin que
tromper le planificateur. L'astuce consiste à faire quelque chose pour
planificateur pour donner au processus plus de temps processeur. Algorithme qui
décrit ci-dessus est assez vulnérable à de telles attaques: avant que la fenêtre temporelle ne soit pratiquement
terminé, vous devez effectuer une opération d'E / S (pour certains, quel que soit le fichier)
et ainsi libérer le CPU. Ce comportement vous permettra de rester dans le même
la file d'attente elle-même et obtenir à nouveau un plus grand pourcentage de temps CPU. Si c'est fait
c'est correct (par exemple, 99% du temps de la fenêtre avant de libérer le CPU)
une telle tâche peut simplement monopoliser le processeur.
Enfin, un programme peut changer son comportement au fil du temps. Ces tâches
qui a utilisé le CPU peut devenir interactif. Dans notre exemple, similaire
les tâches ne recevront pas un traitement approprié de la part de l'ordonnanceur, comme d'autres
tâches (initiales) interactives.
Question au public: quelles attaques contre le planificateur pourraient être faites dans le monde moderne?
Tentative 2: augmentation de la priorité
Essayons de changer les règles et voyons si nous pouvons éviter des problèmes avec
le jeûne. Que pourrions-nous faire pour garantir que les
Les tâches CPU auront leur temps (même si ce n'est pas pour longtemps).
Comme solution simple au problème, vous pouvez proposer périodiquement
augmenter la priorité de toutes ces tâches dans le système. Il y a plusieurs façons.
pour y parvenir, essayons d'implémenter comme exemple quelque chose de simple: traduire
toutes les tâches à la fois dans la plus haute priorité, d'où la nouvelle règle:
- Règle 5 : Après une certaine période de S, transférez toutes les tâches du système vers la priorité la plus élevée.
Notre nouvelle règle résout deux problèmes à la fois. Tout d'abord, les processus
garanti de ne pas mourir de faim: les tâches de la plus haute priorité se partageront
temps processeur selon l'algorithme RR et donc tous les processus recevront
temps processeur. Deuxièmement, s'il existe un processus utilisé précédemment
seul le processeur devient interactif, alors il restera en ligne avec le supérieur
la priorité après une fois recevra une augmentation de priorité au plus haut.
Prenons un exemple. Dans ce scénario, envisagez un processus utilisant

CPU et deux processus interactifs courts. Sur la gauche de la figure, la figure montre le comportement sans augmenter la priorité, et donc la tâche longue commence à mourir de faim après l'arrivée de deux tâches interactives dans le système. Dans la figure de droite, toutes les 50 ms, la priorité est augmentée et donc tous les processus sont garantis pour recevoir du temps processeur et seront périodiquement démarrés. 50ms dans ce cas est pris comme exemple, en réalité ce nombre est un peu plus grand.
De toute évidence, l'ajout de temps pour une augmentation périodique de S
question logique: quelle valeur faut-il fixer? L'un des honorés
les ingénieurs système John Ousterhout ont appelé des quantités similaires dans des systèmes comme voo-doo
constante, car ils ont en quelque sorte exigé la magie noire pour corriger
exposant. Et, malheureusement, S a un tel arôme. Si vous définissez également la valeur
grandes - de longues tâches commenceront à mourir de faim. Et si vous définissez une valeur trop basse,
Les tâches interactives ne recevront pas le temps processeur approprié.
Tentative 3: Meilleure comptabilité
Nous avons maintenant un autre problème à résoudre: comment ne pas
laissez tricher notre planificateur? Coupables de cette opportunité sont
les règles 4a, 4b, qui permettent à la tâche de conserver la priorité, libérant le processeur
avant l'expiration du délai imparti. Comment y faire face?
La solution dans ce cas peut être considérée comme la meilleure prise en compte du temps CPU sur chaque
Niveau MLFQ. Au lieu d'oublier le temps utilisé par le programme
processeur pour la période allouée, vous devez le considérer et l'enregistrer. Après
le processus a pris du temps alloué à lui devrait être réduit à la prochaine
niveau de priorité. Maintenant, peu importe comment le processus utilise son temps - comment
calculant constamment sur le processeur ou autant d'appels. De cette façon
La règle 4 devrait être réécrite comme suit:
- Règle 4 : Une fois que la tâche a épuisé le temps qui lui est alloué dans la file d'attente actuelle (quel que soit le nombre de fois qu'elle a libéré le CPU), la priorité d'une telle tâche diminue (elle descend dans la file d'attente).
Regardons un exemple:

"
La figure montre ce qui se passe si vous essayez de tromper le planificateur, comment
si c'était avec les règles précédentes 4a, 4b, on obtient le résultat à gauche. Bonne nouvelle
la règle est le résultat à droite. Avant la protection, tout processus pouvait appeler des E / S jusqu'à la fin et
dominent ainsi le CPU, après avoir activé la protection, quel que soit le comportement
I / O, il descendra toujours la ligne et ne sera donc pas malhonnête
prendre possession des ressources CPU.
Amélioration de MLFQ et d'autres problèmes
Avec les améliorations ci-dessus, de nouveaux problèmes surgissent: l'un des principaux
questions - comment paramétrer un tel ordonnanceur? C'est-à-dire Combien devrait être
éclate? Quelle devrait être la taille de la fenêtre du programme dans la file d'attente? Comment
la priorité du programme devrait souvent être augmentée pour éviter la famine et
prendre en compte les changements de comportement du programme? À ces questions, il n’existe pas de
réponse et seulement des expériences avec les charges et la configuration ultérieure
le planificateur peut conduire à un équilibre satisfaisant.
Par exemple, la plupart des implémentations MLFQ vous permettent d'attribuer différents
intervalles de temps à différentes files d'attente. Files d'attente à priorité élevée généralement
de courts intervalles sont attribués. Ces files d'attente se composent de tâches interactives,
basculer entre ce qui est assez sensible et devrait prendre 10 ou moins
ms En revanche, les files d'attente de faible priorité consistent en de longues tâches utilisant
CPU Et dans ce cas, les longs intervalles de temps correspondent très bien (100 ms).
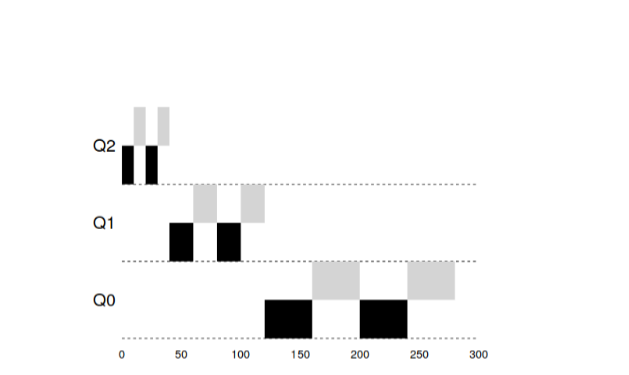
Dans cet exemple, 2 tâches ont fonctionné dans la file d'attente haute priorité 20
ms, cassé par des fenêtres pendant 10 ms. 40 ms dans la file d'attente moyenne (fenêtre à 20 ms) et dans la priorité basse
La fenêtre de temps d'attente est devenue 40 ms, où les tâches ont terminé leur travail.
L'implémentation Solaris OS MLFQ est une classe de planificateurs à temps partagé.
Le planificateur fournit un ensemble de tableaux qui déterminent exactement comment il doit
changer la priorité du processus sur sa durée de vie, quelle devrait être la taille
la fenêtre sélectionnée et la fréquence à laquelle vous devez augmenter les priorités de la tâche. Admin
les systèmes peuvent interagir avec cette table et faire en sorte que le planificateur se comporte
d'une manière différente. Par défaut, il y a 60 files d'attente incrémentielles dans ce tableau.
taille de fenêtre de 20 ms (haute priorité) à plusieurs centaines de ms (priorité la plus basse), et
également avec un coup de pouce de toutes les tâches une fois par seconde.
Les autres planificateurs MLFQ n'utilisent pas de table ou de
les règles qui sont décrites dans cette conférence, au contraire, ils calculent les priorités en utilisant
formules mathématiques. Ainsi, par exemple, le planificateur dans FreeBSD utilise la formule pour
calculer la priorité actuelle d'une tâche en fonction de la quantité de processus
CPU utilisé. De plus, l'utilisation du CPU se désintègre avec le temps, et ainsi
Ainsi, l'augmentation de priorité se produit quelque peu différemment que décrit ci-dessus. C'est ainsi
appelé algorithmes de désintégration. Depuis la version 7.1, FreeBSD utilise le planificateur ULE.
Enfin, de nombreux planificateurs ont d'autres fonctionnalités. Par exemple, certains
les planificateurs réservent les niveaux les plus élevés pour le système d'exploitation et ainsi
de cette façon, aucun processus utilisateur ne peut obtenir la priorité la plus élevée dans
système. Certains systèmes vous permettent de donner des conseils pour vous aider.
le planificateur pour définir correctement les priorités. Par exemple, en utilisant la commande
nicevous pouvez augmenter ou diminuer la priorité de la tâche et ainsi augmenter ou
réduire les chances du programme pour le temps processeur.
MLFQ: Résumé
Nous avons décrit une approche de planification appelée MLFQ. Son nom
Il est conclu dans le principe du travail - il dispose de plusieurs files d'attente et utilise un retourpour déterminer la priorité de la tâche.La forme finale des règles sera la suivante:- Règle 1 : Si priorité (A)> Priorité (B), la tâche A démarrera (B ne sera pas)
- Règle 2 : Si priorité (A) = priorité (B), A&B sont démarrés à l'aide de RR
- Règle 3 : lorsqu'une tâche entre dans le système, elle est mise en file d'attente avec la priorité la plus élevée.
- Règle 4 : Une fois que la tâche a épuisé le temps qui lui est alloué dans la file d'attente actuelle (quel que soit le nombre de fois où elle a libéré le processeur), la priorité d'une telle tâche diminue (elle descend dans la file d'attente).
- Règle 5 : Après une certaine période de S, transférez toutes les tâches du système vers la priorité la plus élevée.
MLFQ est intéressant pour la raison suivante - au lieu d'exiger des connaissances sur lanature de la tâche à l'avance, l'algorithme examine le comportement passé de la tâche etétablit des priorités en conséquence. Ainsi, il essaie de s'asseoir sur deux chaises à la fois - pour atteindre la productivité pour les petites tâches (SJF, STCF) et exécuter honnêtement de longuestâches de chargement de CPU. Par conséquent, de nombreux systèmes, y compris BSD et leurs dérivés,Solaris, Windows, Mac, utilisent une certaine forme d'algorithmeMLFQ comme planificateur comme base.Matériaux supplémentaires:
- manpages.debian.org/stretch/manpages/sched.7.fr.html
- en.wikipedia.org/wiki/Scheduling_ (informatique)
- pages.lip6.fr/Julia.Lawall/atc18-bouron.pdf
- www.usenix.org/legacy/event/bsdcon03/tech/full_papers/roberson/roberson.pdf
- chebykin.org/freebsd-process-scheduling