
Les développeurs sont fous des choses les plus étranges. Nous préférons tous nous considérer comme des êtres super rationnels, mais quand il s'agit de choisir une technologie particulière, nous tombons dans une sorte de folie, passant d'un commentaire sur HackerNews à un post sur un blog, et maintenant, comme dans l'oubli, nous sommes impuissants nous naviguons vers la source de lumière la plus brillante et nous nous inclinons docilement devant elle, ayant complètement oublié ce que nous cherchions à l'origine.
Ce n'est pas du tout ainsi que les gens rationnels prennent des décisions. Mais c'est exactement ainsi que les développeurs décident d'utiliser, par exemple, MapReduce.
Comme Joe Hellerstein l'a noté dans sa conférence sur les bases de données pour les étudiants de premier cycle (à la 54e minute):
Le fait est qu'il existe environ 5 entreprises dans le monde qui exécutent des tâches aussi ambitieuses. Quant à tout le monde ... ils dépensent des ressources incroyables pour fournir un système tolérant aux pannes dont ils n'ont vraiment pas besoin. Les gens avaient une sorte de "googleing" dans les années 2000: "nous ferons tout exactement comme le fait Google, parce que nous gérons également le plus grand service de traitement de données au monde ..." [ironise en secouant la tête et attend les rires du public]

Combien d'étages dans le bâtiment de votre centre de données? Google a décidé de rester à quatre, au moins dans ce centre de données particulier situé dans le comté de Mays, en Oklahoma.
Oui, votre système est plus résistant que vous n'en avez besoin, mais pensez à ce qu'il pourrait coûter. Le point n'est pas seulement la nécessité de traiter de grandes quantités de données. Vous échangez probablement un système complet - avec des transactions, des index et l'optimisation des requêtes - contre quelque chose de relativement faible. Il s'agit d'un pas en arrière significatif. Combien d'utilisateurs Hadoop le font consciemment? Combien d'entre eux prennent une décision vraiment équilibrée?
MapReduce / Hadoop est un exemple très simple. Même les adeptes du culte du fret ont déjà réalisé que les avions ne résoudraient pas tous leurs problèmes. Néanmoins, l'utilisation de MapReduce vous permet de faire une généralisation importante: si vous utilisez la technologie créée pour une grande entreprise, mais en même temps que vous résolvez de petits problèmes, vous agissez peut-être sans réfléchir. Pas même ainsi, il est fort probable que vous soyez guidé par des idées mystiques qui imitant des géants comme Google et Amazon, vous atteindrez les mêmes sommets.

Oui, cet article est un autre opposant au culte du cargo. Mais attendez, j'ai une liste de contrôle utile pour vous, que vous pouvez utiliser pour prendre des décisions plus éclairées.
Cadre cool: UNPHAT
La prochaine fois que vous chercherez sur Google une nouvelle technique intéressante pour (re) façonner votre système, je vous invite à arrêter et à utiliser simplement le framework UNPHAT :
- N'essayez même pas de réfléchir à des solutions possibles avant de comprendre le problème (comprendre) . Votre objectif principal est de «résoudre» le problème en termes de problème, pas en termes de solutions.
- Énumérez (eNumerate) plusieurs solutions possibles. Pas besoin de pointer immédiatement votre doigt sur votre option préférée.
- Envisagez une solution distincte, puis lisez la documentation (papier) , le cas échéant.
- Définissez le contexte historique dans lequel cette solution a été créée.
- Associez les avantages aux défauts. Analysez ce que les décideurs ont dû sacrifier pour atteindre leur objectif.
- Pensez (pensez) ! Réfléchissez sereinement et calmement à quel point cette solution est adaptée à vos besoins. Qu'est-ce qui doit exactement changer pour que vous changiez d'avis? Par exemple, combien moins de données devraient être, de sorte que vous préférez ne pas utiliser Hadoop?
Tu n'es pas amazone
Utiliser UNPHAT est facile. Rappelez-vous ma récente conversation avec une entreprise qui a décidé à la hâte d'utiliser Cassandra pour un processus intensif de lecture des données téléchargées la nuit.
Étant donné que je connaissais déjà la documentation Dynamo et savais que Cassandra est un système dérivé, j'ai compris que dans ces bases de données, l'accent était mis sur la capacité d'enregistrement (Amazon devait faire en sorte que l'action «ajouter au panier» ne soit jamais n'a pas échoué). J'ai également apprécié que les développeurs aient sacrifié l'intégrité des données - et en fait, toutes les fonctionnalités inhérentes aux SGBDR traditionnels. Mais après tout, la société avec laquelle j'ai parlé, la possibilité d'enregistrer n'était pas une priorité. Honnêtement, le projet signifiait la création d'un gros disque par jour.

Amazon vend beaucoup de tout. Si la fonction «ajouter au panier» cessait soudainement de fonctionner, ils perdraient BEAUCOUP d'argent. Vous avez un problème du même ordre?
Cette société a décidé d'utiliser Cassandra car il a fallu plusieurs minutes pour terminer la requête PostgreSQL en question, et ils ont décidé qu'il s'agissait de limitations techniques de la part de leur matériel. Après avoir clarifié quelques points, nous avons réalisé que la table se composait d'environ 50 millions de lignes de 80 octets chacune. Il faudrait environ 5 secondes pour le lire à partir du SSD si vous deviez le parcourir complètement. C'est lent, mais il est toujours deux fois plus rapide que la vitesse d'exécution des requêtes à ce moment-là.
À ce stade, j'avais beaucoup de questions (U = comprendre, comprendre le problème!) Et j'ai commencé à peser environ 5 stratégies différentes qui pourraient résoudre le problème d'origine (N = eNumerate, énumérer quelques solutions possibles!), Mais en tout cas il était déjà clair pour le moment que l'utilisation de Cassandra était fondamentalement la mauvaise décision. Tout ce dont ils avaient besoin était d'un peu de patience pour mettre en place, probablement un nouveau design pour la base de données et, éventuellement (quoique peu probable), le choix d'une technologie différente ... Mais certainement pas un stockage de données de valeur clé avec enregistrement intensif que Amazon a créé pour leur panier!
Vous n'êtes pas LinkedIn
J'ai été très surpris de constater qu'une startup étudiante a décidé de construire son architecture autour de Kafka. C'était incroyable. Autant que je sache, leur entreprise n'effectuait que quelques dizaines de très grandes opérations par jour. Peut-être quelques centaines les jours les plus réussis. Avec cette bande passante, le principal entrepôt de données pourrait être des entrées manuscrites dans un livre ordinaire.
À titre de comparaison, rappelez-vous que Kafka a été créé pour gérer tous les événements analytiques sur LinkedIn. C'est juste une énorme quantité de données. Il y a encore quelques années, c'était environ 1 billion d'événements par jour , avec une charge de pointe de 10 millions de messages par seconde. Bien sûr, je comprends que Kafka peut être utilisé pour travailler avec des charges plus faibles, mais à 10 commandes de moins?

Le Soleil, étant un objet très massif, et qui n'est que 6 ordres de grandeur plus lourd que la Terre.
Peut-être que les développeurs ont même pris une décision délibérée, basée sur les besoins attendus et une bonne compréhension de l'objectif de Kafka. Mais je pense qu'ils étaient plutôt alimentés par l'enthousiasme communautaire (généralement justifié) pour Kafka et ne se demandaient presque jamais si c'était vraiment l'outil dont ils avaient besoin. Imaginez ... 10 commandes!
Je l'ai déjà dit? Tu n'es pas amazone
L'approche de conception architecturale qui leur offre une évolutivité encore plus populaire que l'entrepôt de données distribué d'Amazon est une architecture orientée services. Comme Werner Vogels l'a noté dans une interview accordée à Jim Gray en 2006 , Amazon s'est rendu compte en 2001 qu'ils avaient du mal à faire évoluer la partie frontale et qu'une architecture orientée services pouvait les aider. Cette idée a infecté un développeur après l'autre, tandis que les startups, composées de quelques développeurs et presque pas de clients, n'ont pas commencé à diviser leurs logiciels en nanoservices.
Au moment où Amazon a décidé de passer à SOA (architecture orientée services), ils comptaient environ 7800 employés et leurs ventes dépassaient les 3 milliards de dollars .

La salle de concert Bill Graham Auditorium à San Francisco peut accueillir 7 000 personnes. Amazon comptait environ 7 800 employés lorsqu'ils sont passés à SOA.
Cela ne signifie pas que vous devez reporter la transition vers la SOA jusqu'à ce que votre entreprise atteigne le niveau de 7800 employés ... pensez toujours avec votre propre tête . Est-ce vraiment la meilleure solution pour votre tâche? Quelle est exactement la tâche qui vous attend et existe-t-il d'autres moyens de la résoudre?
Si vous me dites que le travail de votre organisation, qui se compose de 50 développeurs, augmente simplement sans SOA, alors je me suis demandé pourquoi tant de grandes entreprises fonctionnent simplement à merveille en utilisant une seule application, mais bien organisée.
Même Google n'est pas Google.
Des exemples d'utilisation de systèmes pour traiter des flux de données très chargés (Hadoop ou Spark) peuvent vraiment être déroutants. Très souvent, les SGBD traditionnels sont mieux adaptés à la charge, et parfois la quantité de données est si petite que même la mémoire disponible leur suffirait. Saviez-vous que vous pouvez acheter 1 To de RAM quelque part pour 10 000 $? Même si vous aviez un milliard d'utilisateurs, vous seriez toujours en mesure de fournir à chacun d'eux 1 Ko de RAM.
Peut-être que cela ne suffira pas pour votre charge, car vous devrez lire et écrire sur le disque. Mais avez-vous vraiment besoin de plusieurs milliers de disques pour lire et écrire? Voici combien de données vous avez en fait? GFS et MapReduce ont été créés pour résoudre des problèmes informatiques sur Internet ... par exemple, pour recalculer l'index de recherche sur Internet .
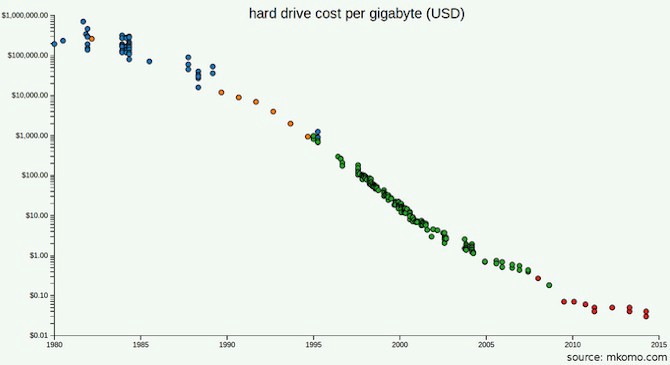
Les prix des disques durs sont désormais bien inférieurs à ceux de 2003 lors de la publication de la documentation GFS.
Peut-être que vous avez lu la documentation GFS et MapReduce et que vous avez remarqué que l'un des problèmes pour Google n'était pas la quantité de données, mais la bande passante (vitesse de traitement): ils utilisaient le stockage distribué car cela prenait trop de temps pour transférer des octets à partir des disques. Mais quelle sera la bande passante des appareils que vous utiliserez cette année? Étant donné que vous n'avez même pas besoin d'autant d'appareils que Google en aurait besoin, serait-il préférable d'acheter simplement des disques plus modernes? Combien cela coûtera-t-il d'utiliser un SSD?
Vous souhaitez peut-être envisager l’évolutivité à l’avance. Avez-vous déjà fait tous les calculs nécessaires? Allez-vous accumuler des données plus rapidement que les prix des SSD ne baissent? Combien de fois votre entreprise devra-t-elle se développer pour que toutes les données disponibles ne tiennent plus sur un seul appareil? En 2016, Stack Exchange traitait 200 millions de requêtes par jour avec prise en charge de seulement 4 serveurs SQL : le principal pour Stack Overflow, un de plus pour tout le reste et deux copies.
Encore une fois, vous pouvez recourir à UNPHAT et toujours décider d'utiliser Hadoop ou Spark. Et la décision peut même être juste. L'essentiel est que vous utilisiez vraiment la bonne technologie pour résoudre votre problème . Soit dit en passant, cela est bien connu de Google: lorsqu'ils ont décidé que MapReduce n'était pas adapté à l'indexation, ils ont cessé de l'utiliser.
Tout d'abord, comprenez le problème
Mon message n'est peut-être pas quelque chose de nouveau, mais c'est peut-être sous cette forme qu'il vous répondra ou peut-être qu'il vous sera simplement facile de vous souvenir de l'UNPHAT et de l'appliquer dans la vie. Sinon, vous pouvez regarder Rich Hickey parler au Hammock Driven Development ou au livre de Paul , How to Solve it , ou à Hamming ’s The Art of Doing Science and Engineering . Parce que la principale chose que nous demandons tous est de réfléchir!
Et comprenez vraiment le problème que vous essayez de résoudre. Dans les mots inspirants de Paul:
« Il est insensé de répondre à une question que vous ne comprenez pas. C'est triste de viser un objectif que vous ne voulez pas atteindre. "
Traduction russe
Traduction: Alexander Tregubov
Édité par Alexey Ivanov (@ponchiknews)
Communauté: @ponchiknews
Figure: Équipe de contenu LucidChart