Un bon service de réservation de taxi doit être sûr, fiable et rapide. L'utilisateur ne rentrera pas dans les détails: il est important pour lui qu'il clique sur le bouton Commander et reçoive une voiture dans les plus brefs délais, ce qui le livrera du point A au point B. S'il n'y a pas de voitures à proximité, le service doit en informer immédiatement afin que le client ne le fasse pas développé de fausses attentes. Mais si la plaque «No cars» s'affiche trop souvent, il est logique qu'une personne arrête simplement d'utiliser ce service et se rende chez un concurrent.
Dans cet article, je veux expliquer comment, à l'aide de l'apprentissage automatique, nous avons résolu le problème de la recherche de voitures dans un territoire à faible densité (en d'autres termes, où, à première vue, il n'y a pas de voitures). Et ce qui en est sorti.
Contexte
Pour appeler un taxi, l'utilisateur prend quelques étapes simples, et que se passe-t-il dans les entrailles du service?
À propos d'
ETA dans la broche , nous avons déjà écrit le
calcul du prix et le
choix du pilote le plus adapté . Et c'est une histoire sur la recherche de pilotes. Lorsqu'une commande est créée, la recherche s'effectue deux fois: sur le pin et sur la commande. La recherche sur la commande se déroule en deux étapes: recrutement des candidats et classement. Tout d'abord, il y a des pilotes candidats gratuits qui viennent le long du graphique routier. Ensuite, les bonus et le filtrage sont appliqués. Les candidats restants sont classés et le gagnant reçoit une offre de la commande. S'il accepte, alors affecté à la commande et se rend au point de livraison. S'il refuse, alors l'offre arrive à la suivante. S'il n'y a plus de candidats, la recherche recommence. Cela ne dure pas plus de trois minutes, après quoi la commande est annulée - épuisée.
La recherche sur la broche est similaire à la recherche sur la commande, seule la commande n'est pas créée et la recherche elle-même n'est effectuée qu'une seule fois. Les paramètres simplifiés du nombre de candidats et du rayon de la recherche sont également utilisés. De telles simplifications sont nécessaires, car il y a un ordre de grandeur plus de broches que d'ordres, et la recherche est une opération assez difficile.
Le moment clé de notre histoire: si lors de la recherche préliminaire sur la broche il n'y avait pas de candidats appropriés, alors nous ne permettons pas de passer une commande. Au moins, c'était le cas auparavant.
Voici ce que l'utilisateur a vu dans l'application:
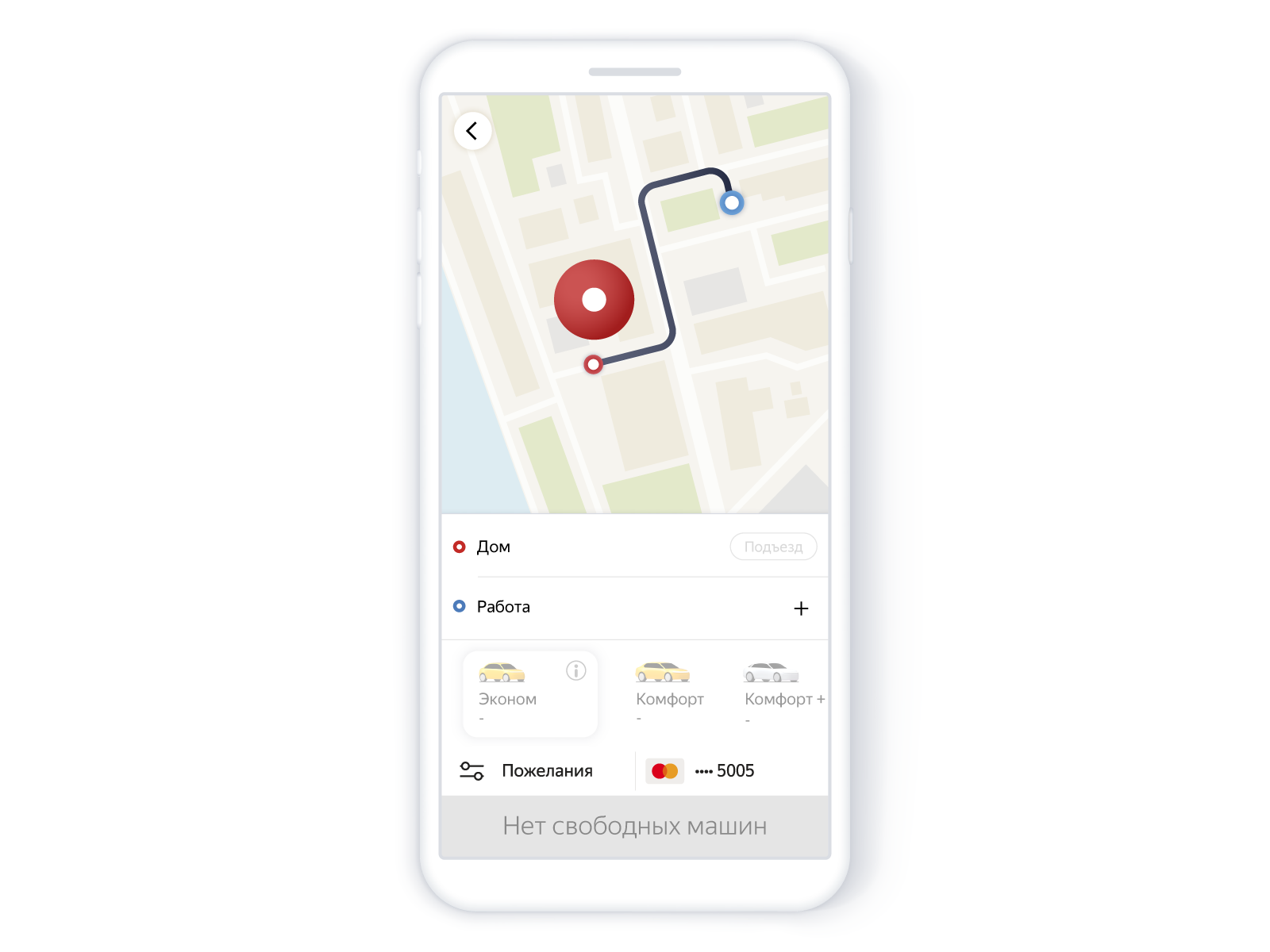
Rechercher des voitures sans voitures
Une fois que nous avions une hypothèse: peut-être, dans certains cas, la commande peut encore être complétée, même s'il n'y avait pas de voitures sur la broche. En effet, un certain temps s'écoule entre le pin et la commande, et la recherche sur la commande est plus complète et est parfois répétée plusieurs fois: pendant ce temps des pilotes libres peuvent apparaître. Nous savions également le contraire: si des pilotes ont été trouvés sur une épingle, alors ce n'est pas un fait qu'ils seront retrouvés lors de la commande. Parfois, ils disparaissent ou refusent tous la commande.
Pour tester cette hypothèse, nous avons lancé une expérience: nous avons arrêté de vérifier la présence de machines lors d'une recherche de broches pour un groupe de test d'utilisateurs, c'est-à-dire qu'ils ont eu la possibilité de passer une «commande sans voitures». Le résultat était assez inattendu:
si la voiture n'était pas sur la broche, alors dans 29% des cas c'était plus tard - lors de la recherche d'une commande! De plus, les commandes sans voiture ne diffèrent pas beaucoup des commandes habituelles en termes de taux d'annulation, de notes et d'autres indicateurs de qualité. Le nombre de commandes sans voiture représentait 5% de toutes les commandes, mais un peu plus de 1% de tous les voyages réussis.
Pour comprendre d'où viennent les exécuteurs de ces ordres, regardons leurs statuts lors de la recherche sur le pin:
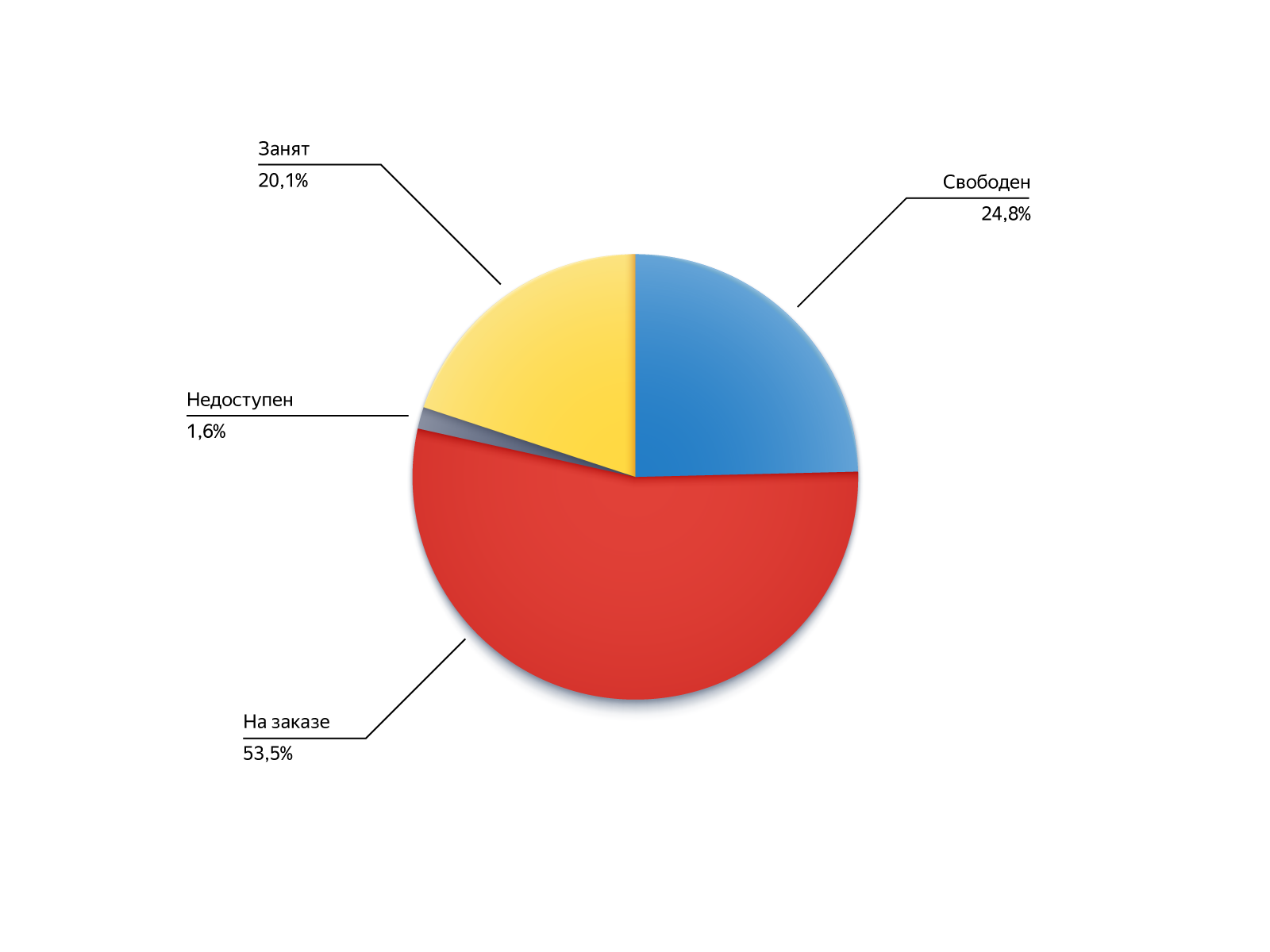
- Gratuit: était disponible, mais pour une raison quelconque, il ne s'est pas présenté aux candidats, par exemple, était trop loin;
- Sur commande: il était occupé, mais a réussi à se libérer ou à devenir disponible pour commander le long de la chaîne ;
- Occupé: la possibilité de prendre des commandes a été désactivée, mais le conducteur est ensuite revenu sur la ligne;
- Non disponible: le chauffeur n'était pas en ligne, mais il est apparu.
Ajoutez de la fiabilité
Les commandes supplémentaires sont importantes, mais 29% des recherches réussies signifient que dans 71% des cas, l'utilisateur attend depuis longtemps et, par conséquent, n'est parti nulle part. Bien que du point de vue de l'efficacité du système, ce n'est pas terrible, mais en fait, l'utilisateur reçoit de faux espoirs et passe du temps, après quoi il est contrarié et (éventuellement) cesse d'utiliser le service. Pour résoudre ce problème, nous avons appris à prédire la probabilité qu'une machine soit trouvée sur la commande.
Le schéma est le suivant:
- L'utilisateur met une épingle.
- Recherche sur la broche.
- S'il n'y a pas de voitures, nous prédisons: peut-être qu'elles apparaîtront.
- Et selon la probabilité, nous donnons ou ne donnons pas de commande, mais nous avertissons que la densité de voitures dans ce domaine est faible pour le moment.
Dans l'application, cela ressemblait à ceci:
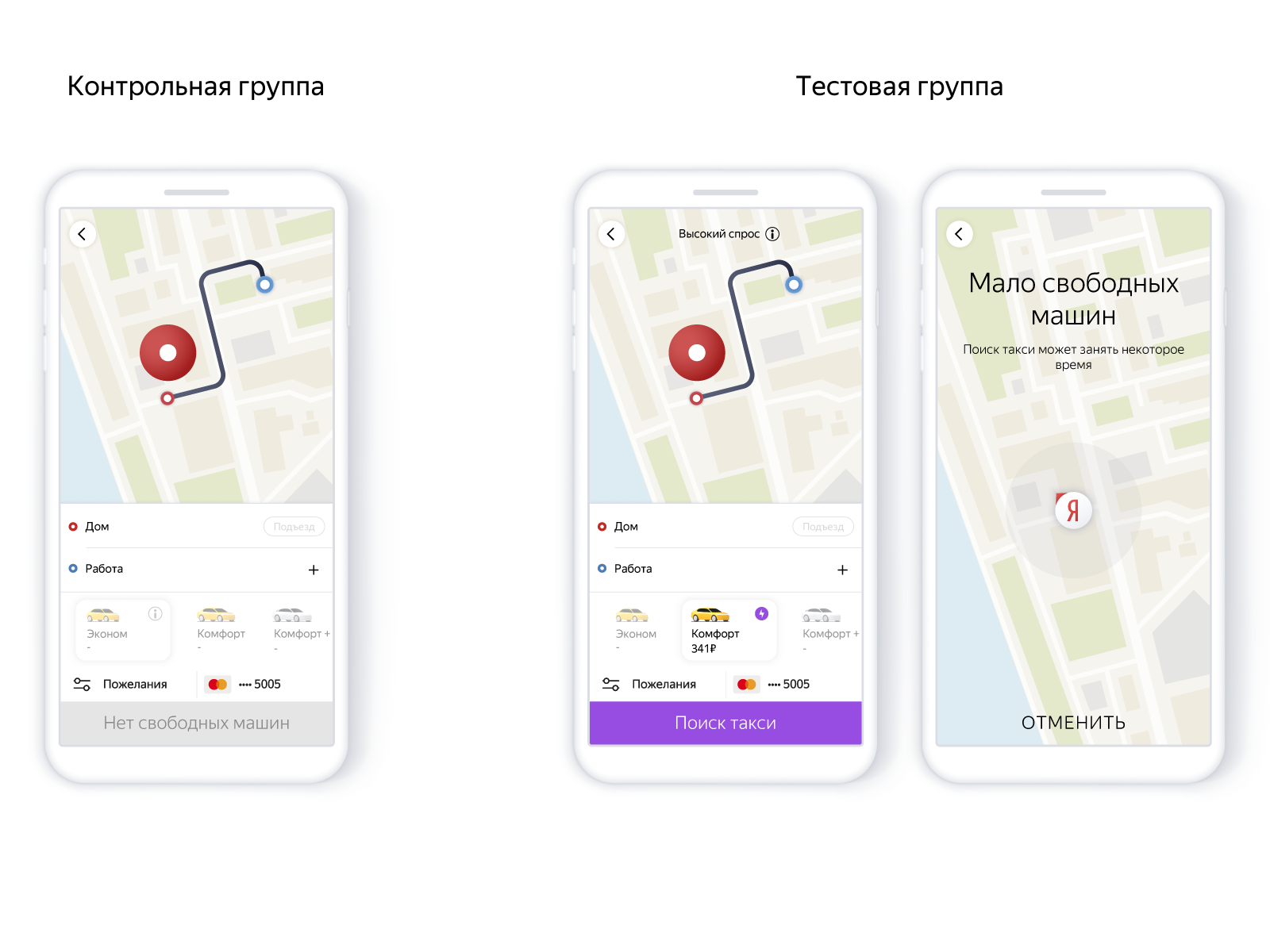
L'utilisation du modèle vous permet de créer soigneusement de nouvelles commandes, de ne pas rassurer une personne en vain. C'est-à-dire, pour ajuster le rapport de fiabilité et le nombre de commandes sans machines en utilisant le modèle de rappel de précision. La fiabilité du service affecte le désir de continuer à utiliser le produit, c'est-à-dire qu'au final, tout se résume au nombre de voyages.
Un peu de précision-rappelL'une des tâches de base de l'apprentissage automatique est le problème de classification: affecter un objet à l'une des deux classes. Dans ce cas, le résultat du fonctionnement de l'algorithme d'apprentissage automatique devient souvent une estimation numérique d'appartenance à l'une des classes, par exemple une estimation de probabilité. Cependant, les actions qui sont effectuées sont généralement binaires: si nous avons une voiture, nous la mettons en ordre, et sinon, non. Pour être précis, nous appellerons le modèle un algorithme qui produit une estimation numérique, et le classificateur - une règle qui se rapporte à l'une des deux classes (1 ou –1). Pour créer un classificateur basé sur l'évaluation du modèle, vous devez sélectionner un seuil d'évaluation. Comment exactement - dépend fortement de la tâche.
Supposons que nous fassions un test (classificateur) pour une maladie rare et dangereuse. Sur la base des résultats du test, nous envoyons le patient pour un examen plus détaillé, ou nous disons: «En bonne santé, rentrez chez vous». Pour nous, envoyer une personne malade à la maison est bien pire que d'examiner en vain une personne en bonne santé. Autrement dit, nous voulons que le test fonctionne pour autant de personnes vraiment malades que possible. Cette valeur est appelée rappel =
. Le rappel idéal du classificateur est de 100%. Une situation dégénérée consiste à envoyer tout le monde pour examen, puis le rappel sera également de 100%.
Cela arrive et vice versa. Par exemple, nous fabriquons un système de test pour les étudiants, et il a un détecteur de triche. Si soudainement un contrôle ne fonctionne pas pour certains cas de tricherie, cela est désagréable, mais pas critique. D'un autre côté, il est extrêmement mauvais de blâmer injustement les étudiants pour ce qu'ils n'ont pas fait. Autrement dit, il est important pour nous que parmi les réponses positives du classifieur, il y ait autant de réponses correctes que possible, peut-être au détriment de leur nombre. Vous devez donc maximiser la précision =
. Si des opérations commencent à se produire sur tous les objets, la précision sera alors égale à la fréquence de la classe déterminée dans l'échantillon.
Si l'algorithme donne une valeur numérique de probabilité, alors, en choisissant différents seuils, vous pouvez obtenir différentes valeurs de rappel de précision.
Dans notre tâche, la situation est la suivante. Le rappel est le nombre de commandes que nous pouvons offrir, la précision est la fiabilité de ces commandes. Voici la courbe précision-rappel de notre modèle:
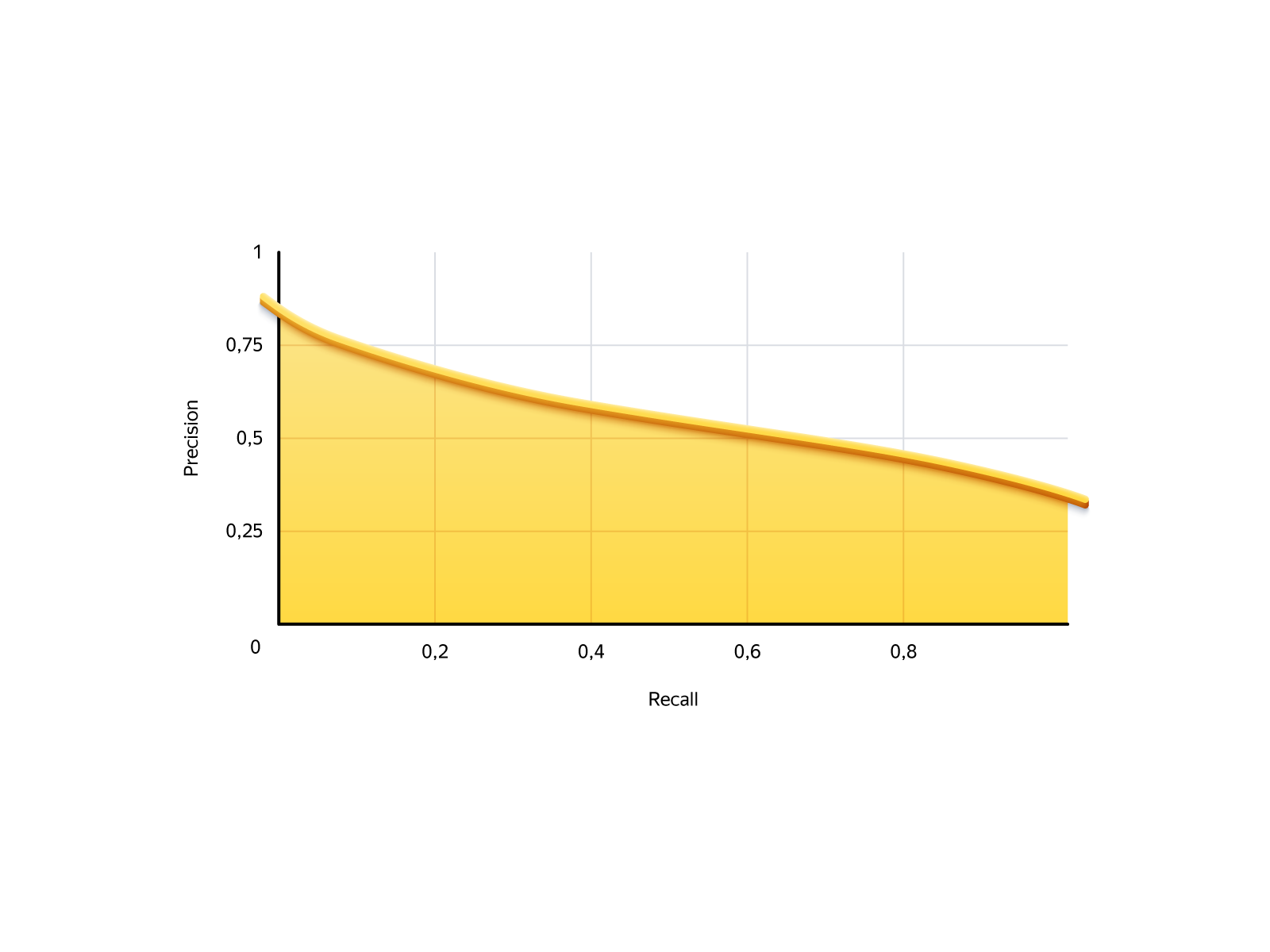
Il y a deux cas extrêmes: ne permettre à personne de commander et permettre à tout le monde de commander. Si vous n'autorisez personne, le rappel sera 0: nous ne créons pas de commandes, mais aucune d'entre elles n'échouera. Si vous autorisez tout le monde, le rappel sera de 100% (nous recevrons toutes les commandes possibles), et la précision - 29%, soit 71% des commandes se révéleront mauvaises.
Comme signes, nous avons utilisé différents paramètres du point de départ:
- Heure / lieu.
- État du système (nombre de voitures occupées de tous les tarifs et broches à proximité).
- Paramètres de recherche (rayon, nombre de candidats, restrictions).
Détails sur les symptômes
Conceptuellement, nous voulons distinguer deux situations:
- «Dead Forest» - il n'y a pas de voitures ici pour le moment.
- "Malchanceux" - il y a des voitures, mais il n'y en avait pas de appropriées lors de la recherche.
Un exemple de «malchanceux» est s'il y a une forte demande dans le centre vendredi soir. Il y a beaucoup de commandes, il y en a beaucoup qui en veulent beaucoup, il n'y a pas assez de pilotes du tout. Cela peut arriver de cette façon: il n'y a pas de pilotes appropriés dans la broche. Mais littéralement, en quelques secondes, ils apparaissent, car à ce moment-là, il y a beaucoup de pilotes et leur statut est en constante évolution.
Par conséquent, diverses fonctionnalités du système à proximité du point A se sont avérées être de bonnes fonctionnalités:
- Le nombre total de voitures.
- Le nombre de voitures en commande.
- Nombre de machines non disponibles à la commande dans l'état "Occupé".
- Le nombre d'utilisateurs.
Après tout, plus il y a de voitures, plus il est probable que l'une d'entre elles deviendra disponible.
En fait, il est important pour nous non seulement d'avoir des voitures, mais aussi de faire des voyages réussis. Par conséquent, il était possible de prédire la probabilité d'un voyage réussi. Mais nous avons décidé de ne pas le faire, car cette valeur dépend fortement de l'utilisateur et du pilote.
CatBoost a été utilisé comme algorithme d'apprentissage du modèle. Pour la formation, nous avons utilisé les données obtenues de l'expérience. Après la mise en œuvre, il a été nécessaire de collecter des données de formation, permettant parfois à un petit nombre d'utilisateurs de passer une commande contrairement à la décision du modèle.
Résumé
Les résultats de l'expérience se sont avérés attendus: l'utilisation du modèle peut augmenter considérablement le nombre de voyages réussis en raison de commandes sans voiture, mais en même temps ne pas réduire la fiabilité.
À l'heure actuelle, le mécanisme est lancé dans toutes les villes et tous les pays et, avec lui, environ 1% des voyages réussis ont lieu. De plus, dans certaines villes à faible densité de voitures, la part de ces déplacements atteint 15%.
Autres postes de technologie de taxi