Les erreurs et les logiciels vont de pair depuis le tout début de l'ère de la programmation informatique. Au fil du temps, les développeurs ont développé un ensemble de pratiques pour tester et déboguer les programmes avant leur déploiement, mais ces pratiques ne conviennent plus aux systèmes modernes avec apprentissage en profondeur. Aujourd'hui, la pratique principale dans le domaine de l'apprentissage automatique peut être appelée formation sur un ensemble de données particulier, suivie d'une vérification sur un autre ensemble. De cette façon, vous pouvez calculer l'efficacité moyenne des modèles, mais il est également important de garantir la fiabilité, c'est-à-dire une efficacité acceptable dans le pire des cas. Dans cet article, nous décrivons trois approches pour repérer et éliminer les erreurs dans les modèles prédictifs formés: les tests contradictoires, l'apprentissage robuste et
la vérification formelle .
Les systèmes avec MO ne sont par définition pas stables. Même les systèmes qui gagnent contre une personne dans un certain domaine peuvent ne pas être en mesure de faire face à la solution de problèmes simples lors de différences subtiles. Par exemple, considérons le problème de la perturbation des images: un réseau de neurones qui peut mieux classer les images que les gens peut facilement faire croire que le paresseux est une voiture de course, ajoutant une petite fraction de bruit soigneusement calculé à l'image.
 Une entrée concurrente lorsqu'elle est superposée à une image standard peut confondre l'IA. Deux images extrêmes ne diffèrent pas de plus de 0,0078 pour chaque pixel. Le premier est classé comme un paresseux, avec une probabilité de 99%. Le second est comme une voiture de course avec une probabilité de 99%.
Une entrée concurrente lorsqu'elle est superposée à une image standard peut confondre l'IA. Deux images extrêmes ne diffèrent pas de plus de 0,0078 pour chaque pixel. Le premier est classé comme un paresseux, avec une probabilité de 99%. Le second est comme une voiture de course avec une probabilité de 99%.Ce problème n'est pas nouveau. Les programmes ont toujours eu des erreurs. Pendant des décennies, les programmeurs ont acquis un éventail impressionnant de techniques, des tests unitaires à la vérification formelle. Sur les programmes traditionnels, ces méthodes fonctionnent bien, mais l'adaptation de ces approches pour des tests rigoureux des modèles MO est extrêmement difficile en raison de l'échelle et du manque de structure dans les modèles qui peuvent contenir des centaines de millions de paramètres. Cela suggère la nécessité de développer de nouvelles approches pour assurer la fiabilité des systèmes MO.
Du point de vue du programmeur, un bug est tout comportement qui ne répond pas à la spécification, c'est-à-dire la fonctionnalité prévue du système. Dans le cadre de nos recherches sur l'IA, nous étudions des techniques pour évaluer si les systèmes MO répondent aux exigences non seulement sur les ensembles de formation et de test, mais également sur la liste des spécifications qui décrivent les propriétés souhaitées du système. Parmi ces propriétés, il peut y avoir une résistance à des changements suffisamment faibles dans les données d'entrée, des restrictions de sécurité qui empêchent les défaillances catastrophiques ou la conformité des prévisions avec les lois de la physique.
Dans cet article, nous aborderons trois problèmes techniques importants auxquels la communauté MO doit faire face pour travailler à rendre les systèmes MO robustes et conformes aux spécifications souhaitées:
- Vérification efficace de la conformité aux spécifications. Nous étudions des moyens efficaces de vérifier que les systèmes MO correspondent à leurs propriétés (par exemple, la stabilité et l'invariance) qui leur sont demandées par le développeur et les utilisateurs. Une approche pour trouver des cas dans lesquels un modèle peut s'éloigner de ces propriétés consiste à rechercher systématiquement les pires résultats de travail.
- Formation des modèles MO aux spécifications. Même s'il existe une quantité suffisamment importante de données d'apprentissage, les algorithmes MO standard peuvent produire des modèles prédictifs dont le fonctionnement ne répond pas aux spécifications souhaitées. Nous sommes tenus de réviser les algorithmes de formation afin qu'ils fonctionnent non seulement bien sur les données de formation, mais répondent également aux spécifications souhaitées.
- Preuve formelle de la conformité des modèles MO aux spécifications souhaitées. Des algorithmes doivent être développés pour confirmer que le modèle répond aux spécifications souhaitées pour toutes les données d'entrée possibles. Bien que le domaine de la vérification formelle étudie de tels algorithmes depuis plusieurs décennies, malgré ses progrès impressionnants, ces approches ne sont pas faciles à mettre à l'échelle pour les systèmes MO modernes.
Vérifier la conformité du modèle avec les spécifications souhaitées
La résistance aux exemples concurrentiels est un problème assez bien étudié de la protection civile. L’une des principales conclusions tirées est l’importance d’évaluer les actions du réseau à la suite de fortes attaques et le développement de modèles transparents pouvant être analysés de manière assez efficace. Nous, ainsi que d'autres chercheurs, avons constaté que de nombreux modèles résistent aux exemples faibles et compétitifs. Cependant, ils fournissent une précision de près de 0% pour des exemples de concurrence plus forte (
Athalye et al., 2018 ,
Uesato et al., 2018 ,
Carlini et Wagner, 2017 ).
Bien que la plupart des travaux se concentrent sur de rares échecs dans le contexte de l'enseignement avec un enseignant (et il s'agit principalement d'une classification d'images), il est nécessaire d'étendre l'application de ces idées à d'autres domaines. Dans un travail récent avec une approche compétitive pour trouver des pannes catastrophiques, nous appliquons ces idées aux tests de réseaux formés avec renforcement et conçus pour être utilisés dans des endroits avec des exigences de sécurité élevées. L'un des défis du développement de systèmes autonomes est que, comme une erreur peut avoir des conséquences graves, même une faible probabilité de défaillance n'est pas considérée comme acceptable.
Notre objectif est de concevoir un «rival» qui aidera à reconnaître ces erreurs à l'avance (dans un environnement contrôlé). Si un adversaire peut déterminer efficacement les pires données d'entrée pour un modèle donné, cela nous permettra de détecter de rares cas d'échecs avant de le déployer. Comme pour les classificateurs d'images, évaluer comment travailler avec un adversaire faible vous donne un faux sentiment de sécurité lors du déploiement. Cette approche est similaire au développement de logiciels avec l'aide de la «red team» [red-teaming - impliquant une équipe de développement tierce qui joue le rôle d'attaquants afin de détecter les vulnérabilités / env. Cependant, cela va au-delà de la recherche de défaillances causées par des intrus, et inclut également des erreurs qui se produisent naturellement, par exemple, en raison d'une généralisation insuffisante.
Nous avons développé deux approches complémentaires pour tester la concurrence des réseaux d'apprentissage renforcés. Dans le premier, nous utilisons une optimisation sans dérivé pour minimiser directement la récompense attendue. Dans le second, nous apprenons une fonction de valeur contradictoire qui, dans l'expérience, prédit dans quelles situations le réseau peut échouer. Ensuite, nous utilisons cette fonction apprise pour l'optimisation, en nous concentrant sur l'évaluation des données d'entrée les plus problématiques. Ces approches ne constituent qu'une petite partie de l'espace riche et croissant d'algorithmes potentiels, et nous sommes très intéressés par le développement futur de ce domaine.
Les deux approches montrent déjà des améliorations significatives par rapport aux tests aléatoires. En utilisant notre méthode, en quelques minutes, il est possible de détecter des défauts qui devaient auparavant être recherchés toute la journée, ou peut-être introuvables du tout (
Uesato et al., 2018b ). Nous avons également constaté que les tests concurrentiels pouvaient révéler un comportement qualitativement différent des réseaux par rapport à ce que l'on pouvait attendre d'une évaluation sur un ensemble de tests aléatoires. En particulier, en utilisant notre méthode, nous avons constaté que les réseaux qui ont effectué la tâche d'orientation sur une carte en trois dimensions, et qui y font généralement face au niveau humain, ne peuvent pas trouver la cible dans des labyrinthes d'une simplicité inattendue (
Ruderman et al., 2018 ). Notre travail met également l'accent sur la nécessité de concevoir des systèmes sûrs contre les défaillances naturelles, et pas seulement contre les concurrents.
 En effectuant des tests sur des échantillons aléatoires, nous ne voyons presque jamais de cartes avec une forte probabilité d'échec, mais des tests compétitifs montrent l'existence de telles cartes. La probabilité de défaillance reste élevée même après la suppression de nombreux murs, c'est-à-dire la simplification des plans par rapport aux plans d'origine.
En effectuant des tests sur des échantillons aléatoires, nous ne voyons presque jamais de cartes avec une forte probabilité d'échec, mais des tests compétitifs montrent l'existence de telles cartes. La probabilité de défaillance reste élevée même après la suppression de nombreux murs, c'est-à-dire la simplification des plans par rapport aux plans d'origine.Formation sur le modèle de spécification
Les tests concurrentiels tentent de trouver un contre-exemple qui viole les spécifications. Souvent, il surestime la cohérence des modèles avec ces spécifications. D'un point de vue mathématique, la spécification est une sorte de relation qui doit être maintenue entre les données d'entrée et de sortie du réseau. Il peut prendre la forme d'une limite supérieure et inférieure ou de certains paramètres d'entrée et de sortie clés.
Inspirés par cette observation, plusieurs chercheurs (
Raghunathan et al., 2018 ;
Wong et al., 2018 ;
Mirman et al., 2018 ;
Wang et al., 2018 ), y compris notre équipe de DeepMind (
Dvijotham et al., 2018 ;
Gowal et al., 2018 ), ont travaillé sur des algorithmes invariants aux tests compétitifs. Cela peut être décrit géométriquement - nous pouvons limiter (
Ehlers 2017 ,
Katz et al.2017 ,
Mirman et al., 2018 ) la pire violation de la spécification, limitant l'espace des données de sortie sur la base d'un ensemble d'entrées. Si cette limite est différenciable par les paramètres du réseau et peut être calculée rapidement, elle peut être utilisée pendant la formation. Ensuite, la frontière d'origine peut se propager à travers chaque couche du réseau.
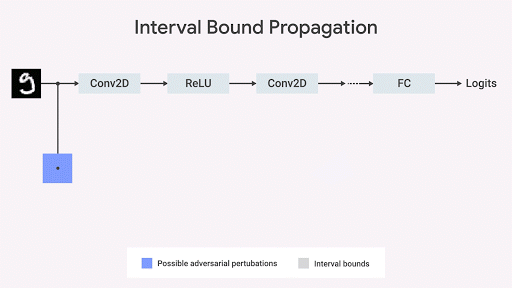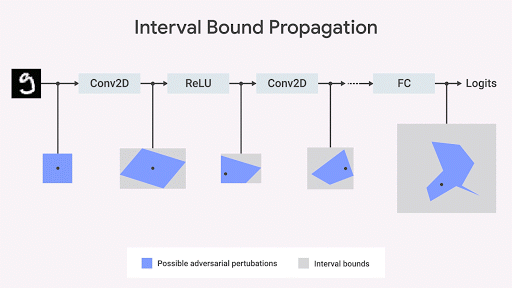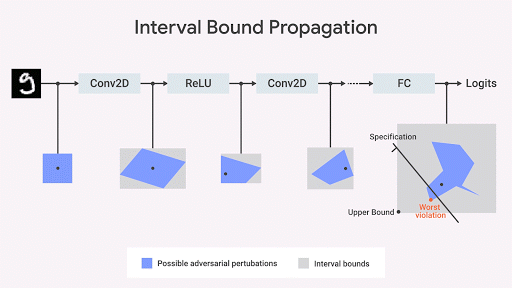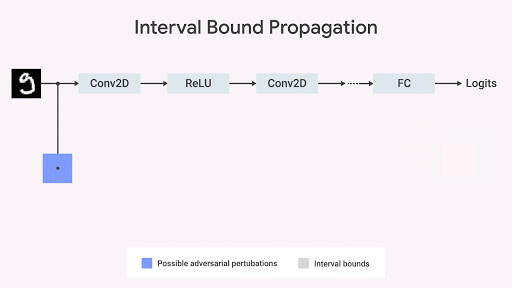
Nous montrons que la propagation de la frontière de l'intervalle est rapide, efficace et - contrairement à ce que l'on pensait auparavant - donne de bons résultats (
Gowal et al., 2018 ). En particulier, nous montrons qu'il peut réduire de manière prouvable le nombre d'erreurs (c'est-à-dire le nombre maximal d'erreurs que tout adversaire peut provoquer) par rapport aux classificateurs d'images les plus avancés sur les ensembles des bases de données MNIST et CIFAR-10.
Le prochain objectif sera d'étudier les abstractions géométriques correctes pour calculer des approximations excessives de l'espace de sortie. Nous voulons également former les réseaux afin qu'ils fonctionnent de manière fiable avec des spécifications plus complexes qui décrivent le comportement souhaité, comme l'invariance susmentionnée et le respect des lois physiques.
Vérification formelle
Des tests et une formation approfondis peuvent être très utiles pour créer des systèmes MO fiables. Cependant, des tests volumineux formellement et arbitrairement ne peuvent garantir que le comportement du système correspond à nos désirs. Dans les modèles à grande échelle, l'énumération de toutes les options de sortie possibles pour un ensemble d'entrée donné (par exemple, des modifications mineures de l'image) semble difficile à mettre en œuvre en raison du nombre astronomique de modifications possibles de l'image. Cependant, comme dans le cas de la formation, on peut trouver des approches plus efficaces pour définir des contraintes géométriques sur l'ensemble des données de sortie. La vérification formelle fait l'objet de recherches en cours chez DeepMind.
La communauté MO a développé quelques idées intéressantes pour calculer les limites géométriques exactes de l'espace de sortie du réseau (Katz et al. 2017,
Weng et al., 2018 ;
Singh et al., 2018 ). Notre approche (
Dvijotham et al., 2018 ), basée sur l'optimisation et la dualité, consiste à formuler le problème de vérification en termes d'optimisation, qui cherche à trouver la plus grande violation de la propriété testée. La tâche devient calculable si des idées issues de la dualité sont utilisées dans l'optimisation. En conséquence, nous obtenons des contraintes supplémentaires qui spécifient les limites calculées lors du déplacement de l'intervalle lié [propagation liée à l'intervalle] à l'aide des plans dits de coupe. Il s'agit d'une approche fiable mais incomplète: il peut y avoir des cas où la propriété qui nous intéresse est satisfaite, mais la frontière calculée par cet algorithme n'est pas assez stricte pour que la présence de cette propriété puisse être formellement prouvée. Cependant, après avoir reçu la frontière, nous obtenons une garantie formelle de l'absence de violations de cette propriété. Dans la fig. Ci-dessous cette approche est illustrée graphiquement.

Cette approche nous permet d'étendre l'applicabilité des algorithmes de vérification sur des réseaux plus généraux (fonctions d'activateur, architectures), des spécifications générales et des modèles GO plus complexes (modèles génératifs, processus neuronaux, etc.) et des spécifications qui vont au-delà de la fiabilité concurrentielle (
Qin , 2018 ).
Perspectives
Le déploiement d'OG dans des situations à haut risque comporte ses propres défis et difficultés, ce qui nécessite le développement de technologies d'évaluation qui sont garanties de détecter les erreurs improbables. Nous pensons qu'une formation cohérente sur les spécifications peut améliorer considérablement les performances par rapport aux cas où les spécifications découlent implicitement des données de formation. Nous attendons avec impatience les résultats des études d'évaluation concurrentielle en cours, des modèles de formation robustes et la vérification des spécifications formelles.
Beaucoup plus de travail sera nécessaire pour que nous puissions créer des outils automatisés qui garantissent que les systèmes d'IA dans le monde réel "feront tout correctement". En particulier, nous sommes très heureux de progresser dans les domaines suivants:
- Formation pour l'évaluation et la vérification compétitives. Avec la mise à l'échelle et la sophistication des systèmes d'IA, il devient de plus en plus difficile de concevoir des algorithmes compétitifs d'évaluation et de vérification suffisamment adaptés au modèle d'IA. Si nous pouvons utiliser toute la puissance de l'IA pour l'évaluation et la vérification, ce processus peut être étendu.
- Développement d'outils accessibles au public pour l'évaluation et la vérification de la concurrence: il est important de fournir aux ingénieurs et autres personnes utilisant l'IA des outils faciles à utiliser qui éclairent les modes de défaillance possibles du système d'IA avant que cette défaillance n'entraîne de graves conséquences négatives. Cela nécessitera une certaine normalisation des évaluations concurrentielles et des algorithmes de vérification.
- Élargir le spectre des exemples concurrentiels. Jusqu'à présent, une grande partie du travail sur les exemples concurrentiels s'est concentrée sur la stabilité des modèles aux petits changements, généralement dans la zone d'image. Cela est devenu un excellent terrain d'essai pour développer des approches d'évaluation compétitives, de formation fiable et de vérification. Nous avons commencé à étudier diverses spécifications pour des propriétés directement liées au monde réel, et nous attendons avec impatience les résultats des recherches futures dans ce sens.
- Spécifications de formation. Les spécifications qui décrivent le comportement «correct» des systèmes d'IA sont souvent difficiles à formuler avec précision. Au fur et à mesure que nous créons des systèmes de plus en plus intelligents capables de comportements complexes et travaillant dans un environnement non structuré, nous devrons apprendre à créer des systèmes qui peuvent utiliser des spécifications partiellement formulées et obtenir d'autres spécifications à partir des commentaires.
DeepMind s'engage à avoir un impact positif sur la société grâce au développement et au déploiement responsables des systèmes MO. Pour nous assurer que la contribution des développeurs soit garantie, nous devons faire face à de nombreux obstacles techniques. Nous avons l'intention de contribuer à ce domaine et sommes heureux de travailler avec la communauté pour résoudre ces problèmes.