
RabbitMQ est un courtier de messages écrit en langage Erlang qui vous permet d'organiser un cluster de basculement avec réplication complète des données sur plusieurs nœuds, où chaque nœud peut gérer les demandes de lecture et d'écriture. Avec de nombreux clusters Kubernetes en production, nous prenons en charge un grand nombre d'installations RabbitMQ et sommes confrontés à la nécessité de migrer les données d'un cluster à un autre sans interruption.
Cette opération nous a été nécessaire dans au moins deux cas:
- Transfert de données d'un cluster RabbitMQ qui n'est pas dans Kubernetes vers un nouveau cluster qui est déjà «optimisé» (c'est-à-dire qui fonctionne dans les pods K8s).
- Migration de RabbitMQ dans Kubernetes d'un espace de noms à un autre (par exemple, si les chemins sont délimités par des espaces de noms, alors pour transférer l'infrastructure d'un chemin à un autre).
La recette proposée dans l'article se concentre sur des situations (mais pas du tout limitées à celles-ci) dans lesquelles il existe un ancien cluster RabbitMQ (par exemple, de 3 nœuds), situé soit dans des K8, soit sur d'anciens serveurs. Une application hébergée dans Kubernetes fonctionne avec elle (déjà là ou dans le futur):

... et nous sommes confrontés au défi de le migrer vers une nouvelle production à Kubernetes.
Tout d'abord, une approche générale de la migration elle-même sera décrite, puis des détails techniques sur sa mise en œuvre.
Algorithme de migration
La première étape, préliminaire, avant toute action consiste à vérifier que le mode haute disponibilité (
HA ) est activé dans l'ancienne installation RabbitMQ. La raison est évidente: nous ne voulons pas perdre de données. Pour effectuer cette vérification, vous pouvez aller dans le panneau d'administration RabbitMQ et dans l'onglet Admin → Stratégies assurez-vous que la valeur
ha-mode: all :

L'étape suivante consiste à créer un nouveau cluster RabbitMQ dans des pods Kubernetes (dans notre cas, par exemple, composé de 3 nœuds, mais leur nombre peut être différent).
Après cela, nous fusionnons les anciens et les nouveaux clusters RabbitMQ, obtenant un seul cluster (de 6 nœuds):
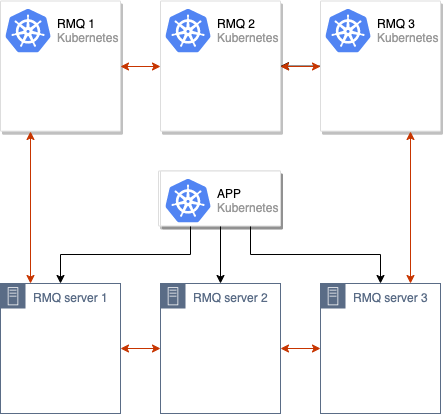
Le processus de synchronisation des données entre l'ancien et le nouveau cluster RabbitMQ est lancé. Une fois que toutes les données sont synchronisées entre tous les nœuds du cluster, nous pouvons basculer l'application pour utiliser le nouveau cluster:
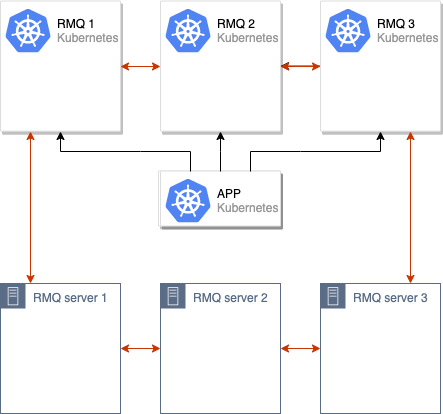
Après ces opérations, il suffit de supprimer les anciens nœuds du cluster RabbitMQ, et le déplacement peut être considéré comme terminé:

Nous avons utilisé ce schéma à plusieurs reprises dans notre production. Cependant, pour leur propre confort, nous l'avons implémenté dans le cadre d'un système spécialisé qui distribue des configurations RMQ typiques sur des ensembles de clusters Kubernetes
(pour ceux qui sont curieux: nous parlons d' opérateur d'addon , dont nous avons récemment parlé ) . Ci-dessous sont présentées des instructions individuelles que chacun peut appliquer sur ses installations pour essayer la solution proposée en action.
Nous essayons en pratique
Prérequis
Les détails sont très simples:
- Cluster Kubernetes (le minikube convient également);
- Cluster RabbitMQ (peut être déployé sur du métal nu et créé en tant que cluster régulier dans Kubernetes à partir du graphique Helm officiel).
Pour l'exemple décrit ci-dessous, j'ai déployé RMQ sur Kubernetes et l'ai nommé
rmq-old .
Préparation du stand
1. Téléchargez le graphique Helm et modifiez-le un peu:
helm fetch --untar stable/rabbitmq-ha
Pour plus de commodité, nous définissons un mot de passe,
ErlangCookie et définissons la stratégie
ha-all afin que par défaut les files d'attente soient synchronisées entre tous les nœuds du cluster RMQ:
rabbitmqPassword: guest rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we definitions: policies: |- { "name": "ha-all", "pattern": ".*", "vhost": "/", "definition": { "ha-mode": "all", "ha-sync-mode": "automatic", "ha-sync-batch-size": 81920 } }
2. Définissez le graphique:
helm install . --name rmq-old --namespace rmq-old
3. Accédez au panneau d'administration RabbitMQ, créez une nouvelle file d'attente et ajoutez quelques messages. Ils seront nécessaires pour qu'après la migration, nous puissions nous assurer que toutes les données ont été enregistrées et que nous n'avons rien perdu:

Le banc de test est prêt: nous avons le "vieux" RabbitMQ avec les données à transférer.
Migration de cluster RabbitMQ
1. Tout d'abord, déployez le nouveau RabbitMQ dans un espace de noms
différent avec
le même ErlangCookie et
le même mot de passe pour l'utilisateur. Pour ce faire, nous effectuons les opérations décrites ci-dessus, en modifiant la commande d'installation RMQ finale comme suit:
helm install . --name rmq-new --namespace rmq-new
2. Vous devez maintenant fusionner le nouveau cluster avec l'ancien. Pour ce faire, accédez à chacun des pods du
nouveau RabbitMQ et exécutez les commandes:
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local && \ rabbitmqctl stop_app && \ rabbitmqctl join_cluster $OLD_RMQ && \ rabbitmqctl start_app
La variable
OLD_RMQ adresse d'un des nœuds de l'
ancien cluster RMQ.
Ces commandes arrêteront le nœud actuel du
nouveau cluster RMQ, le rattacheront à l'ancien cluster et le redémarreront.
3. Le cluster RMQ de 6 nœuds est prêt:

Vous devez attendre que les messages soient synchronisés entre tous les nœuds. Il est facile de deviner que le temps de synchronisation des messages dépend des capacités du fer sur lequel le cluster est déployé et du nombre de messages. Dans le scénario décrit, il n'y en a que 10, de sorte que les données ont été synchronisées instantanément, mais avec un nombre suffisamment important de messages, la synchronisation peut prendre des heures.
Ainsi, l'état de synchronisation:

Ici,
+5 signifie que les messages sont
déjà sur 5
autres nœuds (à l'exception de ce qui est spécifié dans le champ
Node ). Ainsi, la synchronisation a réussi.
4. Il ne reste plus qu'à basculer l'adresse RMQ dans l'application vers le nouveau cluster (les actions spécifiques ici dépendent de la pile technologique que vous utilisez et d'autres spécificités de l'application), après quoi vous pouvez dire au revoir à l'ancienne.
Pour la dernière opération (c'est-à-dire
après le basculement de l'application vers un nouveau cluster), nous allons à chaque nœud de l'
ancien cluster et exécutons les commandes:
rabbitmqctl stop_app rabbitmqctl reset
Le cluster a «oublié» les anciens nœuds: vous pouvez supprimer l'ancien RMQ, ce qui achèvera le déplacement.
Remarque : Si vous utilisez RMQ avec des certificats, alors fondamentalement rien ne change - le processus de déplacement sera effectué exactement de la même manière.Conclusions
Le schéma décrit convient à presque tous les cas où nous devons transférer RabbitMQ ou simplement passer à un nouveau cluster.
Dans notre cas, des difficultés ne sont survenues qu'une seule fois lorsque RMQ a été accessible à partir de nombreux endroits, et nous n'avons pas eu la possibilité de changer l'adresse RMQ par une nouvelle partout. Ensuite, nous avons lancé un nouveau RMQ dans le même espace de noms avec les mêmes étiquettes, afin qu'il tombe sous les services et les entrées existants, et lorsque nous avons démarré le pod, nous avons manipulé les étiquettes avec nos mains, en les supprimant au début, afin que les demandes ne tombent pas sur un RMQ vide, et les ajouter après la synchronisation des messages.
Nous avons utilisé la même stratégie lors de la mise à jour de RabbitMQ vers une nouvelle version avec une configuration modifiée - tout fonctionnait comme une horloge.
PS
Dans le prolongement logique de ce matériel, nous préparons des articles sur MongoDB (migration d'un serveur Iron vers Kubernetes) et MySQL (l'une des options pour "préparer" ce SGBD dans Kubernetes). Ils seront publiés dans les prochains mois.
PPS
Lisez aussi dans notre blog: