En peu de temps, notre équipe est passée d'une douzaine d'employés à une unité entière de près de 200 personnes et nous souhaitons partager quelques jalons de cette voie. De plus, nous discuterons de qui a exactement besoin de Big Data en ce moment et quel est le véritable seuil d'entrée.

Recette du succès dans un nouveau domaine
Travailler avec les mégadonnées est un domaine technologique relativement nouveau qui, comme tout, passe par le cycle de croissance au fur et à mesure de son développement.
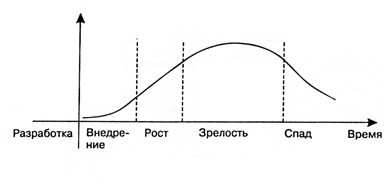
Du point de vue d'un spécialiste particulier, le travail dans le domaine technologique à chaque étape de ce cycle a ses avantages et ses inconvénients.
Étape 1. Mise en œuvreAu premier stade, il s'agit d'une idée originale des unités de R&D, qui ne procurent toujours pas de réel profit.
Des pros: beaucoup d'argent y est investi. Parallèlement aux investissements, les espoirs grandissent pour résoudre des tâches jusque-là inaccessibles et rentabiliser les investissements.
Inconvénients: toute technologie, aussi prometteuse qu'elle puisse paraître au départ, a ses propres limites: elle ne peut pas être utilisée pour éliminer tous les problèmes existants. Ces limites sont révélées à mesure que des expériences avec une nouvelle idée sont menées, ce qui conduit à un refroidissement de l'intérêt pour la technologie après le soi-disant «pic des attentes élevées».
Étape 2. CroissanceLe véritable décollage ne concernera que la technologie qui permettra de surmonter le creux de déception qui en découle en raison de ses capacités réelles, et non le bruit du marketing.
Avantages: à ce stade, la technologie attire des investissements à long terme: non seulement de l'argent, mais aussi le temps des spécialistes du marché du travail. Quand il devient clair que ce n'est pas seulement du battage médiatique, mais une nouvelle approche ou même un segment de marché, il est temps pour les spécialistes de s'intégrer dans la «tendance». C'est un moment idéal pour maîtriser des technologies prometteuses en termes de décollage de carrière.
Inconvénients: à ce stade, la technologie est encore mal documentée.
Étape 3. MaturitéLa technologie mature est le véritable cheval de bataille du marché.
Avantages: à mesure que vous vieillissez, le volume de documentation accumulé augmente, les formations et les cours apparaissent, il devient plus facile d'entrer dans la technologie.
Inconvénients: Dans le même temps, la concurrence sur le marché du travail s'intensifie.
Étape 4. RécessionLe stade de déclin (coucher de soleil) se produit dans toutes les technologies, bien qu'elles continuent de fonctionner.
Avantages: à ce stade, la technologie est déjà entièrement décrite, les limites sont claires, une énorme quantité de documentation, des cours sont disponibles.
Inconvénients: du point de vue de l'acquisition de nouvelles connaissances et perspectives, il n'est plus aussi attractif. En fait, c'est un accompagnement.
La phase de croissance est la plus attractive pour tous ceux qui souhaitent commencer à travailler dans un nouveau domaine technologique: à la fois pour les jeunes professionnels et pour les professionnels déjà établis de segments connexes.
Le développement du big data n'en est qu'à ce stade. De grandes attentes sont restées. Les entreprises ont déjà prouvé que les mégadonnées peuvent générer des bénéfices, et il y a donc un plateau de productivité à venir. Ce moment donne une excellente chance aux spécialistes du marché du travail.
Notre histoire big dataL'introduction de la technologie dans une seule entreprise reprend essentiellement le cycle général de croissance. Et notre expérience ici est assez typique.
Nous avons commencé à constituer notre équipe de Big Data dans X5 il y a un an et demi. À l'époque, ce n'était qu'un petit groupe de spécialistes clés, et maintenant nous sommes près de 200.
Nos équipes de projet sont passées par plusieurs étapes évolutives, au cours desquelles nous avons acquis une meilleure compréhension des rôles et des tâches. En conséquence, nous avons notre propre format d'équipe. Nous avons opté pour l'approche agile. L'idée principale est que l'équipe avait toutes les compétences pour résoudre le problème, et comment exactement ils sont répartis entre les spécialistes n'est pas si important. Sur cette base, la composition des rôles des équipes s'est formée progressivement, notamment en tenant compte de la croissance de la technologie. Et maintenant nous avons:
- Product Owner (Product Owner) - a une compréhension du domaine, formule une idée commerciale générale et prévoit comment il peut être monétisé.
- Analyste d'affaires (analyste d'affaires) - travaille sur cette tâche.
- Qualité des données (spécialiste de la qualité des données) - vérifie si les données existantes peuvent être utilisées pour résoudre le problème.
- Directement Data Science / Data Analyst (Data Scientist / Data Analyst) - construit des modèles mathématiques (il existe différentes sous-espèces, y compris celles qui ne fonctionnent qu'avec des feuilles de calcul).
- Gestionnaires de tests.
- Développeurs
Dans notre cas, l'infrastructure et les données sont utilisées par toutes les équipes et les rôles suivants sont mis en œuvre pour les équipes en tant que services: - Infrastructure
- ETL (commande de chargement des données).
 Comment en sommes-nous arrivés à l'équipe de rêve
Comment en sommes-nous arrivés à l'équipe de rêve
Dream-not´dream, mais, comme je l'ai dit, la composition des équipes a changé en raison de la maturité de l'analyse du Big Data et de sa pénétration dans la vie quotidienne de X5 et de nos réseaux de distribution.
«Démarrage rapide» - rôles minimaux, vitesse maximale
La première équipe ne comprenait que deux rôles:
- Le Product Owner a proposé un modèle, a fait des recommandations.
- Analyste de données - collecté des statistiques sur la base des données existantes.
Tout a été rapidement planifié et mis en œuvre manuellement dans l'entreprise.
"Le pensons-nous?" - nous avons appris à comprendre l'entreprise et à produire le résultat le plus utile
De nouveaux rôles sont apparus pour interagir avec les entreprises:
- Analyste d'affaires - Exigences de processus décrites.
- Qualité des données - vérification de la cohérence des données.
- Selon la tâche, Data Analyst / Data Scientist a analysé les statistiques de données / effectué le calcul du modèle sur le poste de travail local.
«Besoin de plus de ressources» - les tâches de calcul locales ont été déplacées vers le cluster et ont commencé à toucher les systèmes externes
Pour prendre en charge la mise à l'échelle requise:
- L'infrastructure à l'origine du serveur HADOOP.
- Développeurs - ils ont mis en œuvre l'intégration avec des systèmes informatiques externes et ont eux-mêmes vérifié les interfaces utilisateur à ce stade.
Désormais, Data Analyst / Data Scientist pourrait vérifier plusieurs options de calcul du modèle sur le cluster, bien que la mise en œuvre manuelle dans l'entreprise soit toujours préservée.
«Les charges continuent de croître» - de nouvelles données apparaissent, de nouvelles capacités sont nécessaires pour les traiter
Ces changements n'ont pas pu se refléter dans l'équipe:
- L'infrastructure a développé le cluster HADOOP sous des charges croissantes.
- L'équipe ETL a commencé à télécharger et à mettre à jour régulièrement les données.
- Des tests fonctionnels sont apparus.
"Automatisation en tout" - la technologie a pris racine, il est temps d'automatiser la mise en œuvre de l'entreprise
À ce stade, DevOps est apparu dans l'équipe, qui a mis en place l'assemblage automatique, les tests et l'installation des fonctionnalités.
Réflexions clés sur l'esprit d'équipe1. Ce n'est pas un fait que tout se passerait bien si nous n'avions pas eu les bons spécialistes dès le début, autour desquels nous pourrions former une équipe. C'est le squelette sur lequel les muscles ont commencé à se développer.
2. Le marché des mégadonnées est complètement vert, il n'y a donc pas assez de spécialistes «prêts à l'emploi» pour chacun des rôles. Bien sûr, il serait très commode de recruter toute une division de seniors, mais, évidemment, de telles équipes «vedettes» ne peuvent pas être construites beaucoup. Nous avons décidé de ne pas chasser uniquement le personnel «tout fait». Comme nous l'avons mentionné, en adhérant à l'agilité, nous ne devons nous soucier que de l'équipe dans son ensemble a les compétences nécessaires pour résoudre un problème particulier. En d'autres termes, nous pouvons prendre (et prendre) en une seule équipe des professionnels et des débutants avec une certaine base technique et mathématique, afin qu'ils forment ensemble un ensemble de compétences nécessaires pour atteindre les résultats souhaités.
3. Chacun des rôles implique une compréhension des principes de travail avec les mégadonnées, nécessitant toutefois sa profondeur de cette compréhension. La plus grande variabilité des rôles qui ont des analogies directes dans le développement classique - testeurs, analystes, etc. Pour eux, il existe des tâches où l'appartenance au Big Data est presque invisible, et des tâches dans lesquelles vous devez plonger un peu plus profondément. D'une manière ou d'une autre, pour débuter une carrière, une certaine expérience, une compréhension de l'informatique, une envie d'apprendre et des connaissances théoriques sur les outils utilisés (qui s'obtiennent en lisant les articles) suffisent.
4. La pratique a montré qu'en dépit du fait que la technologie est bien connue et que beaucoup aimeraient le faire, loin de tout spécialiste qui serait apte à débuter une carrière dans le big data (et voudrait y travailler dans l'âme) essaie vraiment de venir ici .
De nombreux excellents candidats pensent que travailler dans des équipes BigData relève strictement de la Data Science. Qu'est-ce qu'un changement cardinal d'activité avec un seuil d'entrée élevé. Cependant, ils sous-estiment leurs compétences ou ne savent tout simplement pas que les personnes de différents profils sont recherchées dans les mégadonnées, et il serait plus facile de commencer une carrière dans un autre rôle - l'une des options ci-dessus.
a. En fait, pour commencer à travailler dans une équipe mixte sur de nombreux rôles, vous n'avez pas besoin d'une formation spécialisée étroite dans le domaine des mégadonnées.
b. Nous avons activement élargi l'équipe, en adhérant à l'idée de construire des unités structurelles mixtes. Et la chose la plus intéressante est que les personnes qui sont venues à nos tâches, qui n'avaient jamais travaillé avec le big data, ont parfaitement pris racine dans l'entreprise, ayant fait face aux tâches. Ils ont pu rapidement apprendre la pratique du big data.
5. Sans même avoir beaucoup d'expérience, vous pouvez plonger plus profondément, apprendre les langues et les outils nécessaires, être motivé à grandir dans ce segment afin de traiter des tâches plus stratégiques au sein du projet. Et l'expérience accumulée aide à passer à ces rôles où la connaissance est requise dans les mégadonnées et à comprendre la logique de cette direction. Soit dit en passant, dans ce sens, une équipe mixte aide beaucoup à accélérer le développement.
Comment entrer dans BigData?
Dans notre cas, l'idée d'équipes équilibrées de spécialistes de différents niveaux a «décollé» - le groupe a déjà mis en œuvre plus d'un projet interne. Il me semble qu'avec une pénurie de personnel prêt à l'emploi et une augmentation des besoins d'affaires pour de telles équipes, d'autres entreprises arriveront au même scénario.
Si vous voulez sérieusement choisir cette direction, vous immerger dans Data Sciense - Kaggle, ODS et d'autres ressources spécialisées vous aidera. De plus, si dans un futur proche vous ne vous voyez pas dans le rôle de Data Scientist, mais que vous vous intéressez à la direction en soi, vous avez toujours besoin du Big Data!
Pour augmenter votre valeur:
- mettez à jour vos connaissances en mathématiques. Pour résoudre les problèmes ordinaires des mégadonnées, un doctorat n'est pas requis, mais des connaissances de base en mathématiques supérieures sont encore nécessaires. Comprendre les mécanismes qui sous-tendent les statistiques, il vous sera plus facile d'être au courant des processus;
- Choisissez les rôles les plus proches de votre spécialité actuelle. Découvrez les défis auxquels vous serez confronté dans ce rôle (et dans une entreprise particulière, où vous voulez aller). Et si vous avez déjà résolu des problèmes similaires, ils doivent être soulignés dans le CV;
- les outils spécifiques au rôle sélectionné sont très importants, même s'il semble que cela ne soit pas pertinent pour le big data. Par exemple, lors du développement de notre solution interne, il s'est avéré que nous avions besoin de nombreux développeurs frontaux qui travaillent avec des interfaces complexes;
- rappelez-vous que le marché se développe activement. Quelqu'un construit et pompe des équipes à l'intérieur, tandis que quelqu'un s'attend à trouver des spécialistes prêts à l'emploi sur le marché du travail. Si vous êtes débutant, essayez de faire partie d'une équipe solide, où il sera possible d'acquérir des connaissances supplémentaires.
PS Soit dit en passant, nous continuons actuellement de croître activement et recherchons un
ingénieur de données ,
un spécialiste des tests , un
développeur React et un
spécialiste UI / UX . Les 10 et 11 mai, nous discuterons de l'inclusion du travail dans # bigdatax5 avec tout le monde sur notre stand au
DataFest .