Il existe plusieurs approches pour comprendre une machine à parler familier: l'approche classique à trois composants (comprend un composant de reconnaissance vocale, un composant de compréhension du langage naturel et un composant responsable d'une certaine logique métier) et une approche End2End qui implique quatre modèles de mise en œuvre: direct, collaboratif, multi-étapes et multi-tâches . Examinons tous les avantages et les inconvénients de ces approches, y compris celles basées sur les expériences de Google, et analysons en détail pourquoi l'approche End2End résout les problèmes de l'approche classique.

Nous donnons la parole au développeur leader du centre AI MTS Nikita Semenov.
Salut En guise de préface, je veux citer les scientifiques bien connus Jan Lekun, Joshua Benjio et Jeffrey Hinton - ce sont trois pionniers de l'intelligence artificielle qui ont récemment reçu l'un des prix les plus prestigieux dans le domaine des technologies de l'information - le prix Turing. Dans l'un des numéros du magazine Nature en 2015, ils ont publié un article très intéressant «Deep learning», dans lequel il y avait une phrase intéressante: «Le deep learning est venu avec la promesse de sa capacité à traiter les signaux bruts sans avoir besoin de fonctionnalités artisanales». Il est difficile de le traduire correctement, mais le sens est quelque chose comme ceci: "L'apprentissage profond est venu avec la promesse de la capacité de faire face aux signaux bruts sans avoir besoin de créer manuellement des signes." À mon avis, pour les développeurs, c'est le principal facteur de motivation de tous les développeurs existants.
Approche classique
Commençons donc par l'approche classique. Lorsque nous parlons de comprendre parler avec une machine, nous voulons dire que nous avons une certaine personne qui veut contrôler certains services avec sa voix ou ressent le besoin d'un système pour répondre à ses commandes vocales avec une certaine logique.
Comment ce problème est-il résolu? Dans la version classique, un système est utilisé, qui, comme mentionné ci-dessus, se compose de trois grands composants: un composant de reconnaissance vocale, un composant pour comprendre un langage naturel et un composant responsable d'une certaine logique métier. Il est clair qu'au début, l'utilisateur crée un certain signal sonore, qui tombe sur le composant de reconnaissance vocale et passe du son au texte. Ensuite, le texte tombe dans la composante de compréhension du langage naturel, d'où est extraite une certaine structure sémantique, nécessaire pour la composante responsable de la logique métier.
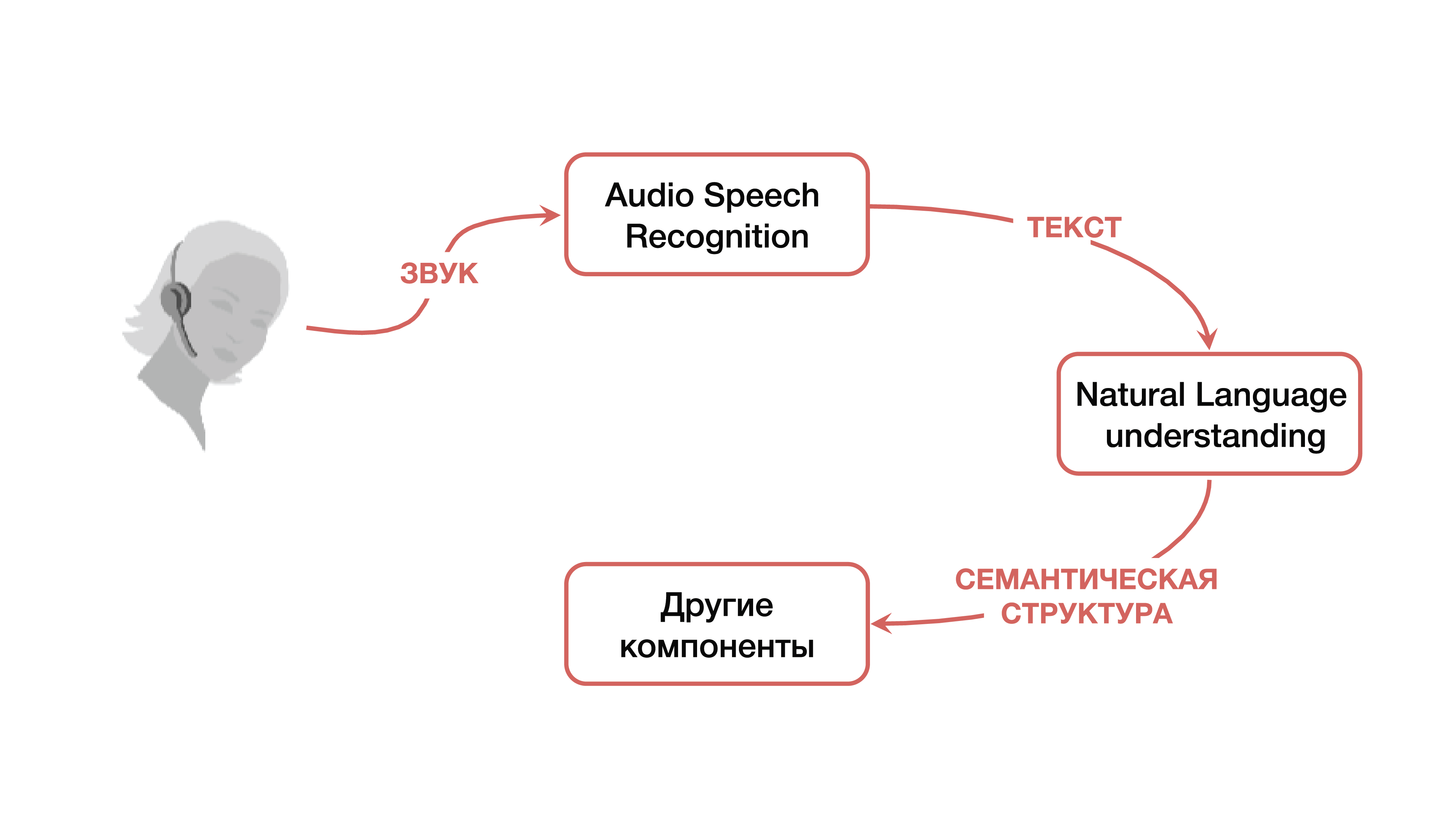
Qu'est-ce qu'une structure sémantique? Il s'agit d'une sorte de généralisation / agrégation de plusieurs tâches en une seule - pour faciliter la compréhension. La structure comprend trois parties importantes: la classification du domaine (une certaine définition du sujet), la classification de l'intention (comprendre ce qui doit être fait) et l'allocation d'entités nommées pour remplir les fiches nécessaires à des tâches commerciales spécifiques à l'étape suivante. Pour comprendre ce qu'est une structure sémantique, vous pouvez considérer un exemple simple, que Google cite le plus souvent. Nous avons une simple demande: "Veuillez jouer une chanson d'un artiste."

Le domaine et l'objet de cette demande sont la musique; intention - jouer une chanson; attributs de la carte «jouer une chanson» - quel genre de chanson, quel genre d'artiste. Une telle structure est le résultat de la compréhension d'un langage naturel.
Si nous parlons de résoudre un problème complexe et à plusieurs étapes de compréhension de la parole familière, alors, comme je l'ai dit, il se compose de deux étapes: la première est la reconnaissance vocale, la seconde est la compréhension du langage naturel. L'approche classique implique une séparation complète de ces étapes. Dans un premier temps, nous avons un certain modèle qui reçoit un signal acoustique en entrée, et en sortie, en utilisant des modèles linguistiques et acoustiques et un lexique, détermine l'hypothèse verbale la plus probable à partir de ce signal acoustique. C'est une histoire complètement probabiliste - elle peut être décomposée selon la formule bien connue de Bayes et obtenir une formule qui vous permet d'écrire la fonction de vraisemblance de l'échantillon et d'utiliser la méthode du maximum de vraisemblance. Nous avons une probabilité conditionnelle du signal X à condition que la séquence de mots W soit multipliée par la probabilité de cette séquence de mots.

La première étape que nous avons traversée - nous avons obtenu une hypothèse verbale à partir du signal sonore. Vient ensuite le deuxième composant, qui prend cette hypothèse très verbale et tente de tirer la structure sémantique décrite ci-dessus.
Nous avons la probabilité de la structure sémantique S à condition que la séquence verbale W soit à l'entrée.

Quelle est la mauvaise chose à propos de l'approche classique, consistant en ces deux éléments / étapes, qui sont enseignés séparément (c'est-à-dire que nous formons d'abord le modèle du premier élément, puis le modèle du second)?
- La composante de compréhension du langage naturel fonctionne avec les hypothèses verbales de haut niveau générées par ASR. C'est un gros problème, car le premier composant (ASR lui-même) fonctionne avec des données brutes de bas niveau et génère une hypothèse verbale de haut niveau, et le deuxième composant prend l'hypothèse en entrée - pas les données brutes de la source principale, mais l'hypothèse que le premier modèle donne - et construit son hypothèse sur l'hypothèse de la première étape. C'est une histoire assez problématique, car elle devient trop «conditionnelle».
- Le problème suivant: nous ne pouvons faire aucun lien entre l’importance des mots qui sont nécessaires pour construire la structure très sémantique et ce que le premier composant préfère lors de la construction de notre hypothèse verbale. Autrement dit, si vous reformulez, nous obtenons que l'hypothèse a déjà été construite. Il est construit sur la base de trois composantes, comme je l'ai dit: la partie acoustique (celle qui est entrée et qui est en quelque sorte modélisée), la partie langage (modélise complètement tous les engrammes linguistiques - la probabilité de la parole) et le lexique (prononciation des mots). Ce sont trois grandes parties qui doivent être combinées et une hypothèse doit y être trouvée. Mais il n'y a aucun moyen d'influencer le choix de la même hypothèse de sorte que cette hypothèse soit importante pour l'étape suivante (ce qui, en principe, est le fait qu'ils apprennent complètement séparément et ne s'influencent pas du tout).
Approche End2End
Nous avons compris ce qu'est l'approche classique, quels problèmes elle a. Essayons de résoudre ces problèmes en utilisant l'approche End2End.
Par End2End, nous entendons un modèle qui combinera les différents composants en un seul composant. Nous modéliserons à l'aide de modèles constitués d'une architecture codeur-décodeur contenant des modules d'attention (attention). De telles architectures sont souvent utilisées dans les problèmes de reconnaissance vocale et dans les tâches liées au traitement d'un langage naturel, en particulier la traduction automatique.
Il existe quatre options pour la mise en œuvre de telles approches qui pourraient résoudre le problème posé par l'approche classique: ce sont des modèles directs, collaboratifs, multi-étapes et multi-tâches.
Modèle direct
Le modèle direct reprend les attributs bruts d'entrée de bas niveau, c'est-à-dire signal audio de bas niveau, et à la sortie, nous obtenons immédiatement une structure sémantique. Autrement dit, nous obtenons un module - l'entrée du premier module de l'approche classique et la sortie du deuxième module de la même approche classique. Juste une telle "boîte noire". De là, il y a des avantages et des inconvénients. Le modèle n'apprend pas à transcrire complètement le signal d'entrée - c'est un avantage clair, car nous n'avons pas besoin de collecter de très grandes marques, nous n'avons pas besoin de collecter beaucoup de signal audio, puis de le donner aux accesseurs pour le balisage. Nous avons juste besoin de ce signal audio et de la structure sémantique correspondante. Et c'est tout. Cela réduit à plusieurs reprises le travail impliqué dans le balisage des données. Le plus gros inconvénient de cette approche est probablement que la tâche est trop compliquée pour une telle "boîte noire", qui essaie de résoudre immédiatement, conditionnellement, deux problèmes. D'abord, à l'intérieur de lui-même, il essaie de construire une sorte de transcription, puis à partir de cette transcription révéler la structure très sémantique. Cela soulève une tâche assez difficile - apprendre à ignorer certaines parties de la transcription. Et c'est très difficile. Ce facteur est un inconvénient assez important et colossal de cette approche.
Si nous parlons de probabilités, alors ce modèle résout le problème de trouver la structure sémantique la plus probable S à partir du signal acoustique X avec les paramètres du modèle θ.
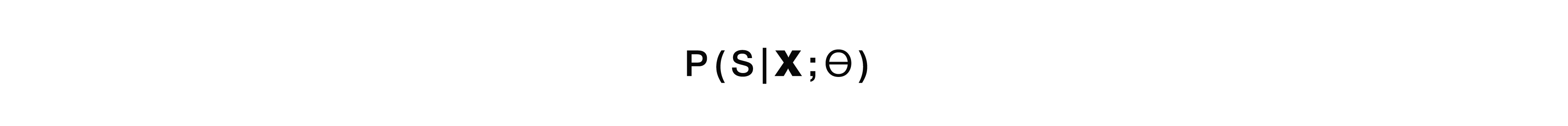
Modèle commun
Quelle est l'alternative? Il s'agit d'un modèle collaboratif. Autrement dit, certains modèles sont très similaires à une ligne droite, mais à une exception près: la sortie pour nous est déjà constituée de séquences verbales et une structure sémantique leur est simplement concaténée. Autrement dit, à l'entrée, nous avons un signal sonore et un modèle de réseau neuronal, qui à la sortie donne déjà à la fois la transcription verbale et la structure sémantique.
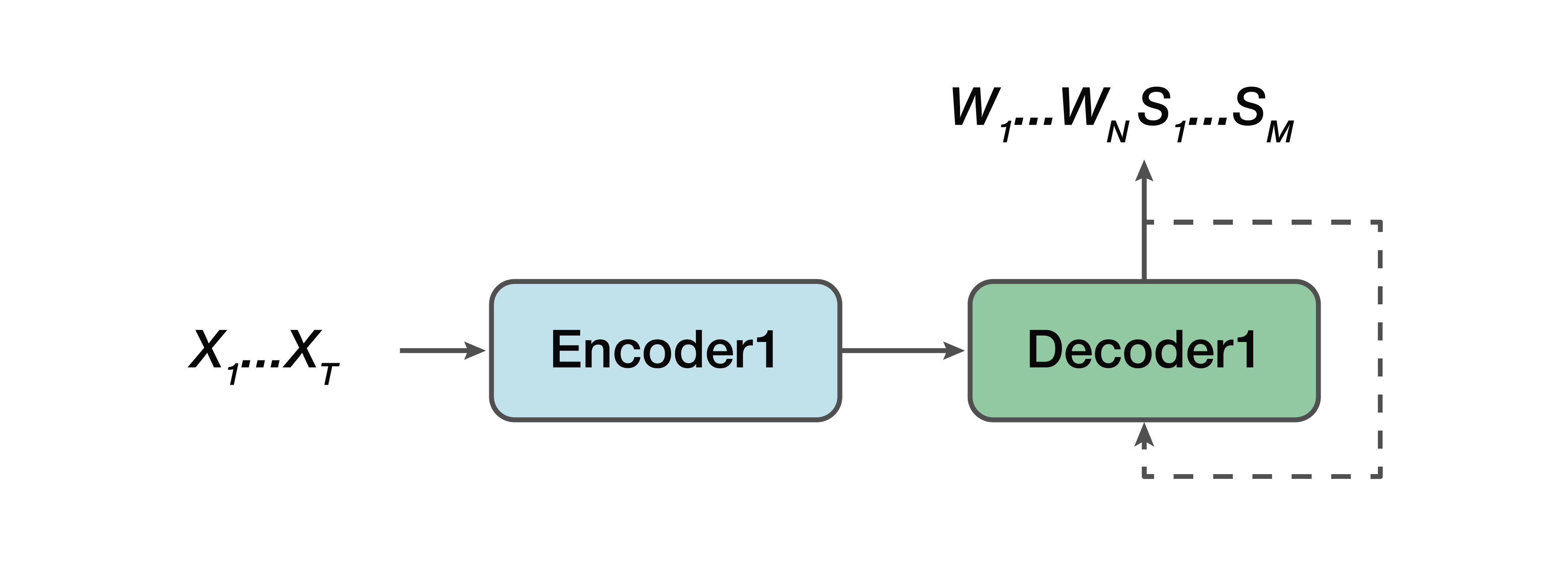
Des pros: nous avons toujours un simple encodeur, un simple décodeur. L'apprentissage est facilité car le modèle n'essaie pas de résoudre deux problèmes à la fois, comme dans le cas du modèle direct. Un autre avantage est que cette dépendance de la structure sémantique des attributs sonores de bas niveau est toujours présente. Parce que, encore une fois, un codeur, un décodeur. Et, en conséquence, l'un des avantages peut être noté qu'il y a une dépendance à prédire cette structure très sémantique et son influence directement sur la transcription elle-même - ce qui ne nous convenait pas dans l'approche classique.
Encore une fois, nous devons trouver la séquence de mots W la plus probable et les structures sémantiques correspondantes S à partir du signal acoustique X avec les paramètres θ.
Modèle multitâche
La prochaine approche est un modèle multitâche. Encore une fois, l'approche codeur-décodeur, mais à une exception près.
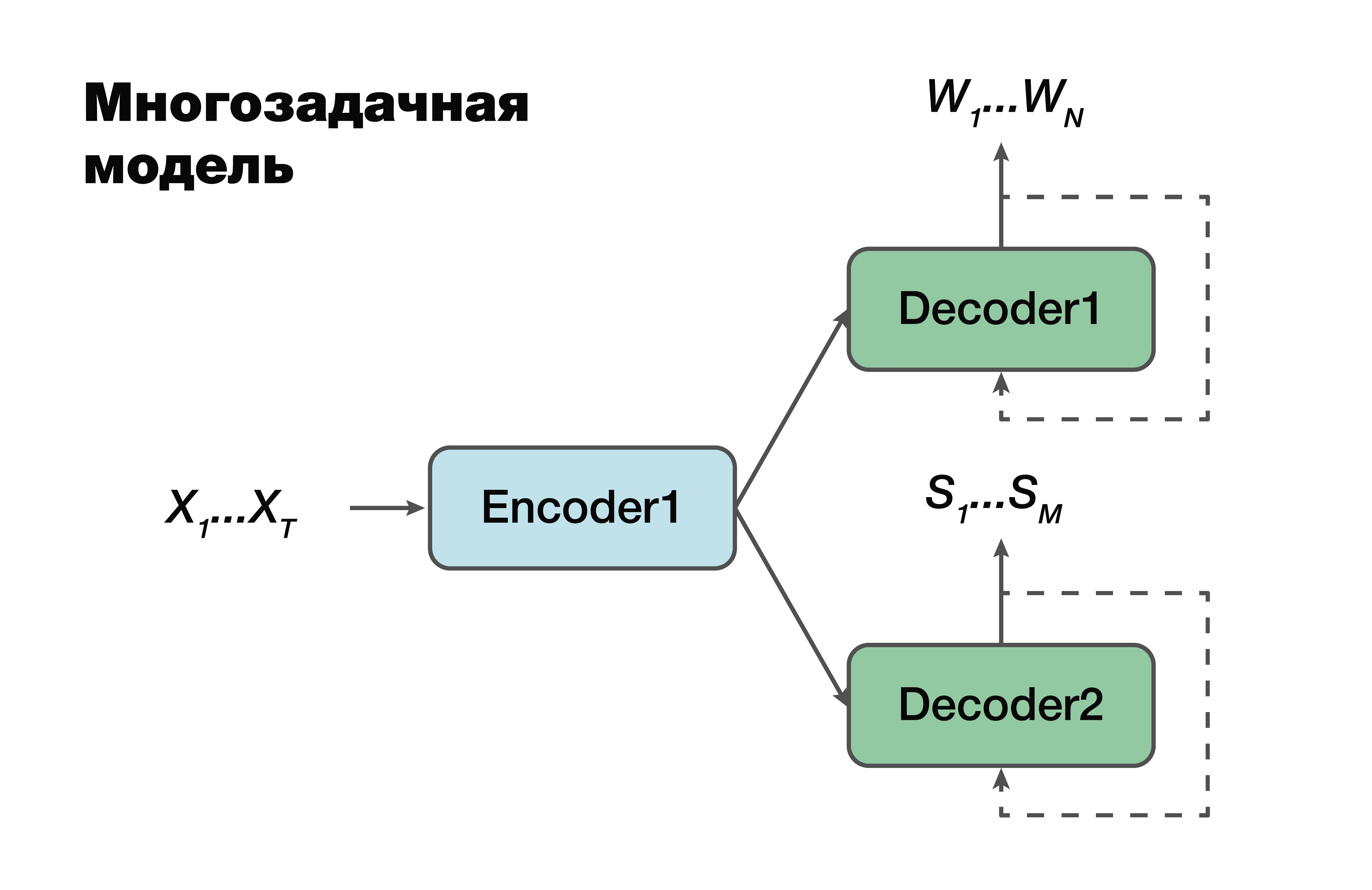
Pour chaque tâche, c'est-à-dire pour créer une séquence verbale, pour créer une structure sémantique, nous avons notre propre décodeur qui utilise une représentation cachée commune qui génère un seul encodeur. Un truc très connu dans l'apprentissage automatique, très souvent utilisé au travail. La résolution de deux problèmes différents à la fois permet de mieux rechercher les dépendances dans les données source. Et en conséquence - la meilleure capacité de généralisation, car le paramètre optimal est sélectionné pour plusieurs tâches à la fois. Cette approche convient mieux aux tâches avec moins de données. Et les décodeurs utilisent un espace vectoriel caché dans lequel leur encodeur crée.

Il est important de noter que la probabilité dépend déjà des paramètres des modèles de codeur et de décodeur. Et ces paramètres sont importants.
Modèle à plusieurs étages
Nous nous tournons, à mon avis, vers l'approche la plus intéressante: un modèle à plusieurs étapes. Si vous regardez très attentivement, vous pouvez voir qu'il s'agit en fait de la même approche classique à deux composants à une exception près.
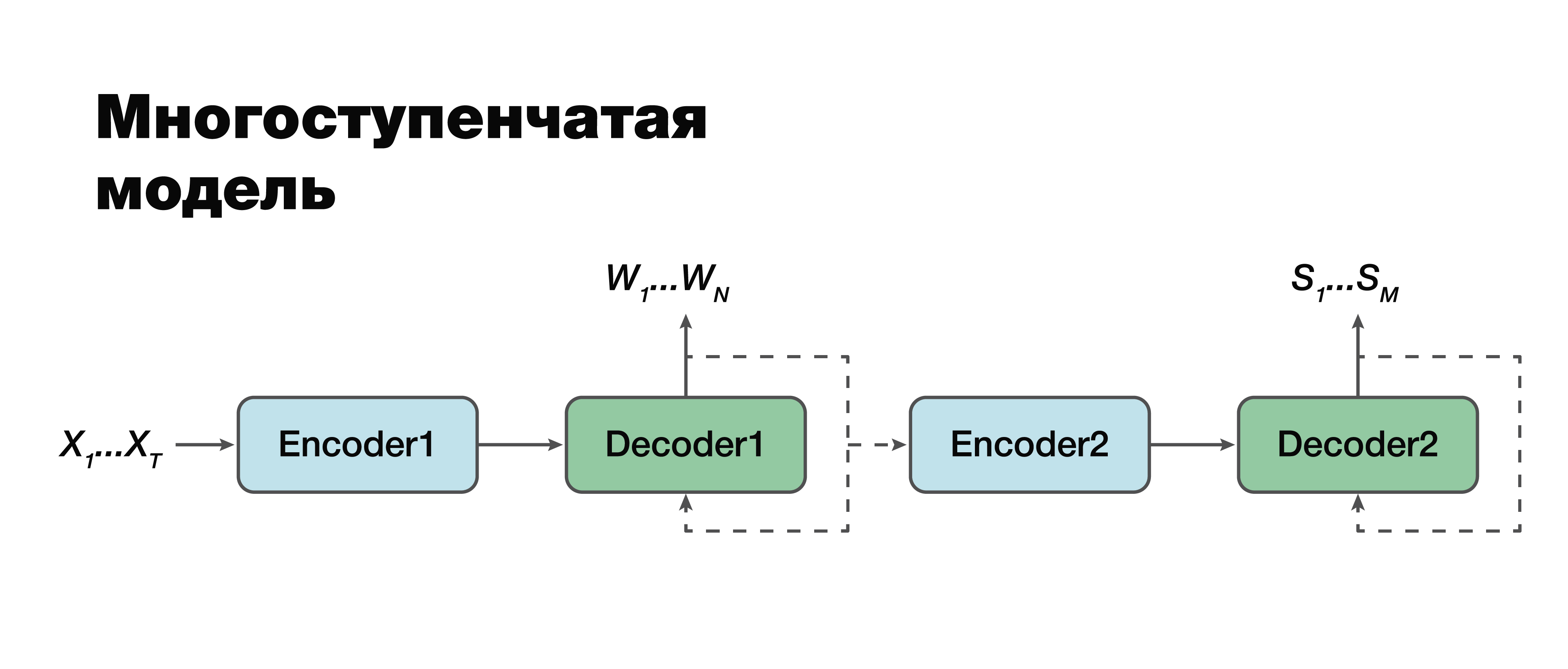
Ici, il est possible d'établir une connexion entre les modules et de les rendre mono-module. Par conséquent, la structure sémantique est considérée conditionnellement dépendante de la transcription. Il existe deux options pour travailler avec ce modèle. On peut entraîner individuellement ces deux mini-blocs: le premier et le deuxième encodeur-décodeur. Ou combinez-les et entraînez les deux tâches en même temps.
Dans le premier cas, les paramètres des deux tâches ne sont pas liés (nous pouvons nous entraîner à l'aide de données différentes). Supposons que nous ayons un grand corps de sons et les séquences verbales et transcriptions correspondantes. Nous les «conduisons», nous ne formons que la première partie. On obtient une bonne simulation de transcription. Ensuite, nous prenons la deuxième partie, nous nous entraînons sur un autre cas. Nous connectons et obtenons une solution qui dans cette approche est 100% cohérente avec l'approche classique, car nous avons séparément pris et formé la première partie et séparément la seconde. Et puis nous formons le modèle connecté sur le cas, qui contient déjà des triades de données: un signal audio, la transcription correspondante et la structure sémantique correspondante. Si nous avons un tel bâtiment, nous pouvons former le modèle, formé individuellement sur de grands bâtiments, pour notre petite tâche spécifique et obtenir le gain de précision maximal d'une manière aussi délicate. Cette approche permet de prendre en compte l'importance des différentes parties de la transcription et leur influence sur la prédiction de la structure sémantique en
prenant en compte les erreurs de la deuxième étape dans la première.
Il est important de noter que la tâche finale est très similaire à l'approche classique avec une seule grande différence: le deuxième terme de notre fonction - le logarithme de la probabilité de la structure sémantique - à condition que le signal acoustique d'entrée X dépend également des paramètres du
modèle du premier étage .

Il est également important de noter ici que le deuxième composant dépend des paramètres des premier et deuxième modèles.
Méthodologie pour évaluer la précision des approches
Il vaut maintenant la peine de décider de la méthodologie d'évaluation de la précision. Comment, en effet, mesurer cette précision afin de prendre en compte des caractéristiques qui ne nous conviennent pas dans l'approche classique? Il existe des étiquettes classiques pour ces tâches distinctes. Pour évaluer les composants de reconnaissance vocale, nous pouvons prendre la métrique WER classique. Il s'agit d'un taux d'erreur sur les mots. Nous considérons, selon une formule peu compliquée, le nombre d'insertions, substitutions, permutations du mot et les divisons par le nombre de tous les mots. Et nous obtenons une certaine caractéristique estimée de la qualité de notre reconnaissance. Pour une structure sémantique, composante par composante, nous pouvons simplement considérer le score F1. Il s'agit également d'une métrique classique pour le problème de classification. Ici, tout plus ou moins est clair. Il y a de la plénitude, il y a de la précision. Et ce n'est qu'un moyen harmonique entre eux.
Mais la question se pose de savoir comment mesurer la précision lorsque la transcription d'entrée et l'argument de sortie ne correspondent pas ou lorsque la sortie est des données audio. Google a proposé une métrique qui tiendra compte de l'importance de prédire le premier composant de la reconnaissance vocale en évaluant l'effet de cette reconnaissance sur le deuxième composant lui-même. Ils l'ont appelé Arg WER, c'est-à-dire qu'il pèse WER sur les entités de structure sémantique.
Prenez la demande: "Réglez l'alarme sur 5 heures." Cette structure sémantique contient un argument tel que «cinq heures», un argument de type «date heure». Il est important de comprendre que si le composant de reconnaissance vocale produit cet argument, alors la métrique d'erreur de cet argument, c'est-à-dire WER, est de 0%. Si cette valeur ne correspond pas à cinq heures, alors la métrique a 100% WER. Ainsi, nous considérons simplement la valeur moyenne pondérée pour tous les arguments et, en général, nous obtenons une certaine métrique agrégée qui estime l'importance des erreurs de transcription qui créent la composante de reconnaissance vocale.
Permettez-moi de vous donner un exemple des expériences de Google qu'elle a menées dans l'une de ses études sur ce sujet. Ils ont utilisé des données provenant de cinq domaines, cinq sujets: médias, Media_Control, productivité, plaisir, aucun - avec la distribution correspondante de données sur les ensembles de données de test de formation. Il est important de noter que tous les modèles ont été formés à partir de zéro. Cross_entropy a été utilisé, le paramètre de recherche de faisceau était 8, l'optimiseur qu'ils ont utilisé, bien sûr, Adam. Considéré, bien sûr, sur un grand nuage de leur TPU. Quel est le résultat? Ce sont des chiffres intéressants:
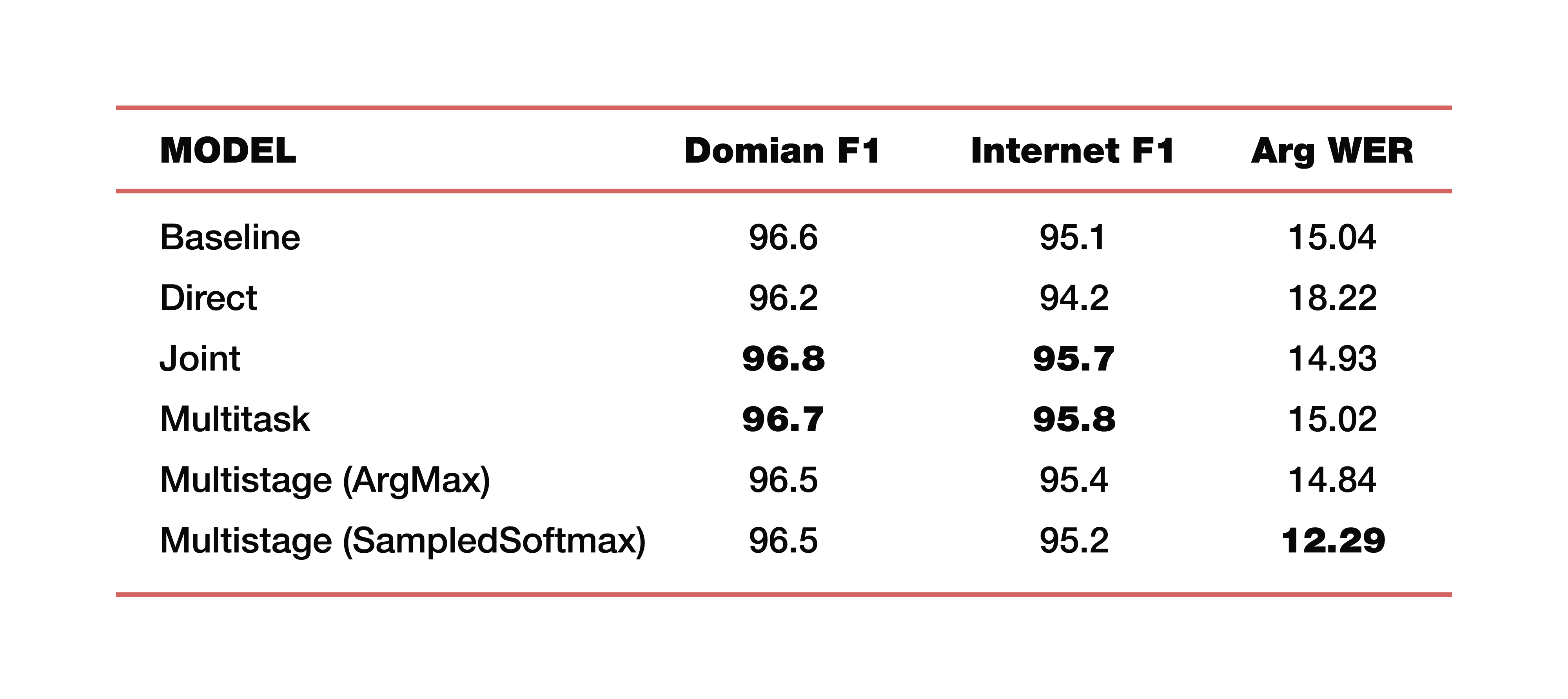
Pour la compréhension, Baseline est une approche classique qui se compose de deux composantes, comme nous l'avons dit au tout début. Voici des exemples de modèles directs, connectés, multitâches et à plusieurs étapes.
Combien coûtent deux modèles à plusieurs étages? Juste à la jonction des première et deuxième parties, différentes couches ont été utilisées. Dans le premier cas, c'est ArgMax, dans le second cas, SampedSoftmax.
À quoi vaut-il attention? L'approche classique perd dans les trois métriques, qui sont une estimation de la collaboration directe de ces deux composantes. Oui, nous ne nous intéressons pas à la façon dont la transcription se fait là-bas, nous nous intéressons uniquement à la façon dont fonctionne l'élément qui prédit la structure sémantique. Il est évalué par trois métriques: F1 - par sujet, F1 - par intention et métrique ArgWer, qui est prise en compte par les arguments des entités. F1 est considéré comme une moyenne pondérée entre l'exactitude et l'exhaustivité. Autrement dit, la norme est 100. ArgWer, au contraire, n'est pas un succès, c'est une erreur, c'est-à-dire que la norme est ici 0.
Il convient de noter que nos modèles couplés et multitâches surpassent complètement tous les modèles de classification pour les sujets et les intentions. Et le modèle, qui est à plusieurs étapes, a une très forte augmentation de l'ArgWer total. Pourquoi est-ce important? Parce que dans les tâches associées à la compréhension de la parole familière, l'action finale qui sera effectuée dans le composant responsable de la logique métier est importante. Il ne dépend pas directement des transcriptions créées par ASR, mais de la qualité des composants ASR et NLU travaillant ensemble. Par conséquent, une différence de près de trois points dans la métrique argWER est un indicateur très intéressant, qui indique le succès de cette approche. Il convient également de noter que toutes les approches ont des valeurs comparables par définition des thèmes et des intentions.
Je vais donner quelques exemples de l'utilisation de tels algorithmes pour comprendre la parole conversationnelle. Google, en parlant des tâches de compréhension de la conversation, note principalement les interfaces homme-ordinateur, c'est-à-dire que ce sont toutes sortes d'assistants virtuels tels que Google Assistant, Apple Siri, Amazon Alexa, etc. Comme deuxième exemple, il convient de mentionner un tel pool de tâches comme Interactive Voice Response. Autrement dit, c'est une certaine histoire qui est engagée dans l'automatisation des centres d'appels.
Nous avons donc examiné les approches avec la possibilité d'utiliser l'optimisation conjointe, ce qui aide le modèle à se concentrer sur les erreurs qui sont plus importantes pour les SLU. Cette approche de la tâche de comprendre la langue parlée simplifie considérablement la complexité globale.
Nous avons l'occasion de tirer une conclusion logique, c'est-à-dire d'obtenir une sorte de résultat, sans avoir besoin de ressources supplémentaires telles que le lexique, les modèles de langage, les analyseurs, etc. (c'est-à-dire que ce sont tous des facteurs inhérents à l'approche classique). La tâche est résolue «directement».
En fait, vous ne pouvez pas vous arrêter là. Et si maintenant nous avons combiné les deux approches, les deux composantes d'une structure commune, alors nous pouvons viser plus. Combinez les trois composants et quatre - continuez simplement à combiner cette chaîne logique et à «faire passer» l'importance des erreurs à un niveau inférieur, étant donné la criticité déjà présente. Cela nous permettra d'augmenter la précision de la résolution du problème.