
Je vis dans une bonne ville. Mais, comme dans beaucoup d'autres, la recherche d'une place de parking se transforme toujours en test. Les espaces libres occupent rapidement, et même si vous en avez un, vos amis auront du mal à vous appeler car ils n'auront nulle part où se garer.
J'ai donc décidé de pointer la caméra par la fenêtre et d'utiliser le deep learning pour que mon ordinateur me dise quand l'espace est disponible:

Cela peut sembler compliqué, mais l'écriture d'un prototype fonctionnel avec un apprentissage approfondi est rapide et facile. Tous les composants nécessaires sont déjà là - il vous suffit de savoir où les trouver et comment les assembler.
Alors amusons-nous et écrivons un système précis de notification de stationnement gratuit en utilisant Python et l'apprentissage en profondeur
Décomposer la tâche
Lorsque nous avons une tâche difficile que nous voulons résoudre à l'aide de l'apprentissage automatique, la première étape consiste à la décomposer en une séquence de tâches simples. Ensuite, nous pouvons utiliser différents outils pour résoudre chacun d'eux. En combinant plusieurs solutions simples ensemble, nous obtenons un système capable de quelque chose de complexe.
Voici comment j'ai rompu ma tâche:

Le flux vidéo de la webcam dirigé vers la fenêtre entre dans l'entrée du convoyeur:

Grâce au pipeline, nous transmettrons chaque image de la vidéo, une à la fois.
La première étape consiste à reconnaître toutes les places de stationnement possibles dans le cadre. Évidemment, avant de pouvoir rechercher des lieux inoccupés, nous devons comprendre dans quelles parties de l'image il y a du stationnement.
Ensuite, sur chaque cadre, vous devez trouver toutes les voitures. Cela nous permettra de suivre le mouvement de chaque machine d'un châssis à l'autre.
La troisième étape consiste à déterminer quels endroits sont occupés par des machines et lesquels ne le sont pas. Pour ce faire, combinez les résultats des deux premières étapes.
Enfin, le programme devrait envoyer une alerte lorsque la place de parking devient libre. Cela sera déterminé par les changements d'emplacement des machines entre les images de la vidéo.
Chacune de ces étapes peut être effectuée de différentes manières en utilisant différentes technologies. Il n'y a pas de bonne ou de mauvaise façon de composer ce convoyeur; différentes approches auront leurs avantages et leurs inconvénients. Examinons chaque étape plus en détail.
Nous reconnaissons les espaces de stationnement
Voici ce que voit notre caméra:

Nous devons en quelque sorte scanner cette image et obtenir une liste des endroits pour se garer:

La solution «dans le front» serait de simplement coder en dur les emplacements de toutes les places de stationnement manuellement au lieu de les reconnaître automatiquement. Mais dans ce cas, si nous bougeons la caméra ou si nous voulons chercher des places de parking dans une autre rue, nous devrons refaire toute la procédure. Cela sonne tellement, alors cherchons un moyen automatique de reconnaître les places de stationnement.
Alternativement, vous pouvez rechercher des parcmètres dans l'image et supposer qu'il y a une place de parking à côté de chacun d'eux:

Cependant, avec cette approche, tout n'est pas si fluide. Premièrement, toutes les places de stationnement n'ont pas de parcmètre, et en effet, nous sommes plus intéressés à trouver des places de stationnement pour lesquelles vous n'avez pas à payer. Deuxièmement, l'emplacement du parcmètre ne nous dit rien sur l'emplacement de l'espace de stationnement, mais nous permet seulement de faire une hypothèse.
Une autre idée est de créer un modèle de reconnaissance d'objets qui recherche les marques d'espace de stationnement tracées sur la route:

Mais cette approche est moyenne. Premièrement, dans ma ville, toutes ces marques sont très petites et difficiles à voir à distance, il sera donc difficile de les détecter à l'aide d'un ordinateur. Deuxièmement, la rue est pleine de toutes sortes d'autres lignes et marques. Il sera difficile de séparer les marques de stationnement des séparateurs de voies et des passages pour piétons.
Lorsque vous rencontrez un problème qui semble difficile à première vue, prenez quelques minutes pour trouver une autre approche pour résoudre le problème, ce qui vous aidera à contourner certains problèmes techniques. Qu'y a-t-il une place de parking? C'est juste un endroit où une voiture est garée pendant longtemps. Peut-être n'avons-nous pas du tout besoin de reconnaître les places de stationnement. Pourquoi ne reconnaissons-nous pas simplement les voitures qui restent immobiles pendant longtemps et ne supposons-nous pas qu'elles se trouvent dans l'espace de stationnement?
En d'autres termes, les places de stationnement sont situées là où les voitures se trouvent pendant longtemps:

Ainsi, si nous pouvons reconnaître les voitures et savoir lesquelles ne se déplacent pas entre les cadres, nous pouvons deviner où se trouvent les places de stationnement. Aussi simple que cela - passez à la reconnaissance de la machine!
Reconnaître les voitures
Reconnaître des voitures sur une image vidéo est une tâche classique de reconnaissance d'objets. Il existe de nombreuses approches d'apprentissage automatique que nous pourrions utiliser pour la reconnaissance. En voici quelques-unes dans l'ordre de la «vieille école» à la «nouvelle école»:
- Vous pouvez entraîner le détecteur sur la base du HOG (histogramme des gradients orientés, histogrammes des gradients directionnels) et le parcourir toute l'image pour trouver toutes les voitures. Cette ancienne approche, qui n'utilise pas le deep learning, fonctionne relativement rapidement, mais ne fonctionne pas très bien avec des machines situées de différentes manières.
- Vous pouvez entraîner le détecteur basé sur CNN (Convolutional Neural Network, un réseau de neurones à convolution) et le parcourir toute l'image jusqu'à ce que nous trouvions toutes les machines. Cette approche fonctionne exactement, mais pas aussi efficacement, car nous devons numériser l'image plusieurs fois à l'aide de CNN pour trouver toutes les machines. Et bien que nous puissions trouver des machines situées de différentes manières, nous avons besoin de beaucoup plus de données d'entraînement que pour un détecteur HOG.
- Vous pouvez utiliser une nouvelle approche avec un apprentissage en profondeur comme Mask R-CNN, Faster R-CNN ou YOLO, qui combine la précision de CNN et un ensemble de trucs techniques qui augmentent considérablement la vitesse de reconnaissance. De tels modèles fonctionneront relativement rapidement (sur le GPU) si nous avons beaucoup de données pour former le modèle.
Dans le cas général, nous avons besoin de la solution la plus simple, qui fonctionnera comme elle le devrait et nécessitera le moins de données de formation. Il n'est pas nécessaire que ce soit l'algorithme le plus récent et le plus rapide. Cependant, en particulier dans notre cas, le masque R-CNN est un choix raisonnable, malgré le fait qu'il soit assez nouveau et rapide.
L'architecture Mask R-CNN est conçue de manière à reconnaître les objets dans l'image entière, à dépenser efficacement les ressources et à ne pas utiliser l'approche à fenêtre coulissante. En d'autres termes, cela fonctionne assez rapidement. Avec un GPU moderne, nous pourrons reconnaître des objets en vidéo en haute résolution à une vitesse de plusieurs images par seconde. Pour notre projet, cela devrait suffire.
De plus, Mask R-CNN fournit de nombreuses informations sur chaque objet reconnu. La plupart des algorithmes de reconnaissance renvoient uniquement une boîte englobante pour chaque objet. Cependant, Mask R-CNN ne nous donnera pas seulement l'emplacement de chaque objet, mais aussi son contour (masque):

Pour former Mask R-CNN, nous avons besoin de beaucoup d'images d'objets que nous voulons reconnaître. Nous pourrions sortir, prendre des photos de voitures et les marquer sur des photos, ce qui nécessiterait plusieurs jours de travail. Heureusement, les voitures sont l'un de ces objets que les gens veulent souvent reconnaître, il existe donc déjà plusieurs jeux de données publics avec des images de voitures.
L'un d'eux est le populaire
ensemble de données SOCO (abréviation de Common Objects In Context), qui a des images annotées avec des masques d'objets. Cet ensemble de données contient plus de 12 000 images avec des machines déjà étiquetées. Voici un exemple d'image de l'ensemble de données:

Ces données sont excellentes pour la formation d'un modèle basé sur le masque R-CNN.
Mais tenez les chevaux, il y a encore des nouvelles! Nous ne sommes pas les premiers à vouloir former leur modèle à l'aide de l'ensemble de données COCO - de nombreuses personnes l'ont déjà fait avant nous et ont partagé leurs résultats. Par conséquent, au lieu de former notre modèle, nous pouvons prendre un modèle prêt à l'emploi qui peut déjà reconnaître les voitures. Pour notre projet, nous utiliserons le
modèle open-source de Matterport.Si nous donnons une image de la caméra à l'entrée de ce modèle, c'est ce que nous obtenons déjà "hors de la boîte":

Le modèle a reconnu non seulement les voitures, mais aussi les objets tels que les feux de circulation et les personnes. C'est drôle qu'elle ait reconnu l'arbre comme plante d'intérieur.
Pour chaque objet reconnu, le modèle Mask R-CNN renvoie 4 choses:
- Type d'objet détecté (entier). Le modèle COCO pré-formé peut reconnaître 80 objets communs différents comme les voitures et les camions. Une liste complète d'entre eux peut être trouvée ici.
- Le degré de confiance dans les résultats de reconnaissance. Plus le nombre est élevé, plus le modèle est confiant dans la reconnaissance de l'objet.
- Un cadre de délimitation pour un objet sous la forme de coordonnées XY de pixels dans l'image.
- Un «masque» qui montre quels pixels dans le cadre de sélection font partie de l'objet. En utilisant les données du masque, vous pouvez trouver le contour de l'objet.
Vous trouverez ci-dessous le code Python pour détecter la boîte englobante pour les machines utilisant les modèles Mask R-CNN et OpenCV pré-formés:
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path
Après avoir exécuté ce script, une image avec un cadre autour de chaque machine détectée apparaîtra à l'écran:

De plus, les coordonnées de chaque machine seront affichées dans la console:
Cars found in frame of video: Car: [492 871 551 961] Car: [450 819 509 913] Car: [411 774 470 856]
Nous avons donc appris à reconnaître les voitures dans l'image.
Nous reconnaissons les espaces de stationnement vides
Nous connaissons les coordonnées en pixels de chaque machine. En regardant à travers plusieurs cadres consécutifs, nous pouvons facilement déterminer laquelle des voitures n'a pas bougé et supposer qu'il y a des places de parking. Mais comment comprendre que la voiture a quitté le parking?
Le problème est que les châssis des machines se chevauchent partiellement:

Par conséquent, si vous imaginez que chaque châssis représente un espace de stationnement, il peut s'avérer qu'il est partiellement occupé par la machine, alors qu'en fait il est vide. Nous devons trouver un moyen de mesurer le degré d'intersection de deux objets afin de rechercher uniquement les cadres «les plus vides».
Nous utiliserons une mesure appelée Intersection Over Union (rapport de l'aire d'intersection à l'aire totale) ou IoU. IoU peut être trouvé en calculant le nombre de pixels où deux objets se croisent et en divisant par le nombre de pixels occupés par ces objets:
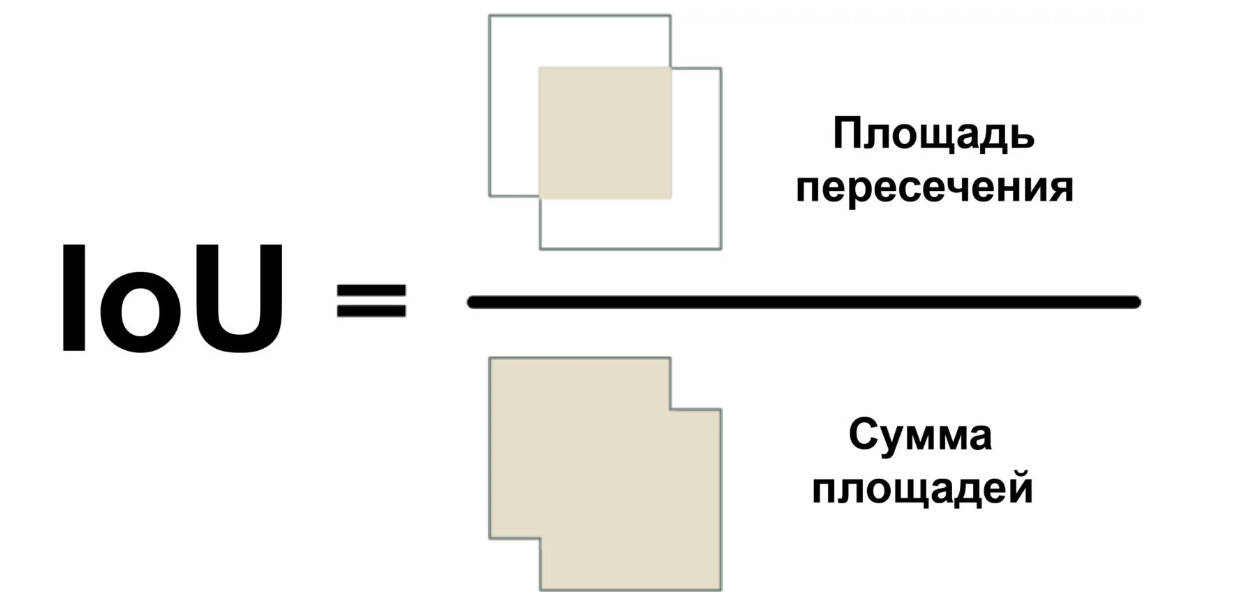
Ainsi, nous pouvons comprendre comment le cadre très délimité de la voiture croise le cadre de l'espace de stationnement. Cela vous permettra de déterminer facilement si le stationnement est gratuit. Si la valeur IoU est faible, comme 0,15, alors la voiture occupe une petite partie de l'espace de stationnement. Et si elle est élevée, comme 0,6, cela signifie que la voiture occupe la majeure partie de l'espace et que vous ne pouvez pas vous y garer.
Étant donné que l'IoU est utilisé assez souvent en vision par ordinateur, il est très probable que les bibliothèques correspondantes mettent en œuvre cette mesure. Dans notre bibliothèque Mask R-CNN, il est implémenté comme une fonction mrcnn.utils.compute_overlaps ().
Si nous avons une liste de boîtes de délimitation pour les espaces de stationnement, vous pouvez ajouter un contrôle de la présence de voitures dans ce cadre en ajoutant une ligne entière ou deux de code:
Le résultat devrait ressembler à ceci:
[ [1. 0.07040032 0. 0.] [0.07040032 1. 0.07673165 0.] [0. 0. 0.02332112 0.] ]
Dans ce tableau à deux dimensions, chaque rangée reflète une image de l'espace de stationnement. Et chaque colonne indique à quel point chacun des endroits croise fortement avec l'une des machines détectées. Un résultat de 1,0 signifie que toute la place est complètement occupée par la voiture, et une valeur faible comme 0,02 indique que la voiture s'est un peu mise en place, mais vous pouvez toujours vous garer dessus.
Pour trouver des endroits inoccupés, il vous suffit de vérifier chaque ligne de ce tableau. Si tous les nombres sont proches de zéro, alors la place est probablement gratuite!
Cependant, gardez à l'esprit que la reconnaissance d'objets ne fonctionne pas toujours parfaitement avec la vidéo en temps réel. Bien que le modèle basé sur Mask R-CNN soit assez précis, il peut de temps en temps manquer une voiture ou deux dans une image de la vidéo. Par conséquent, avant d'affirmer que l'endroit est libre, vous devez vous assurer qu'il le reste pour les 5 à 10 prochaines images de la vidéo. De cette façon, nous pouvons éviter les situations où le système marque par erreur un endroit vide en raison d'un problème dans une image de la vidéo. Dès que nous nous assurons que le lieu reste libre pour plusieurs images, vous pouvez envoyer un message!
Envoyer un SMS
La dernière partie de notre convoyeur envoie des notifications par SMS lorsqu'une place de parking gratuite apparaît.
L'envoi d'un message depuis Python est très facile si vous utilisez Twilio. Twilio est une API populaire qui vous permet d'envoyer des SMS à partir de presque n'importe quel langage de programmation avec seulement quelques lignes de code. Bien sûr, si vous préférez un service différent, vous pouvez l'utiliser. Je n'ai rien à voir avec Twilio, c'est juste la première chose qui me vient à l'esprit.
Pour utiliser Twilio, inscrivez-vous pour un
compte d'essai , créez un numéro de téléphone Twilio et obtenez les informations d'authentification de votre compte. Installez ensuite la bibliothèque cliente:
$ pip3 install twilio
Après cela, utilisez le code suivant pour envoyer le message:
from twilio.rest import Client
Pour ajouter la possibilité d'envoyer des messages à notre script, copiez simplement ce code là. Cependant, vous devez vous assurer que le message n'est pas envoyé sur chaque trame, où vous pouvez voir l'espace libre. Par conséquent, nous aurons un indicateur qui, dans l'état installé, ne permettra pas d'envoyer des messages pendant un certain temps ou jusqu'à ce qu'un autre endroit soit libéré.
Tout mettre ensemble
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path from twilio.rest import Client
Pour exécuter ce code, vous devez d'abord installer Python 3.6+,
Matterport Mask R-CNN et
OpenCV .
J'ai spécifiquement écrit le code aussi simple que possible. Par exemple, s'il voit une voiture sur le premier cadre, il conclut qu'elles sont toutes garées. Essayez de l'expérimenter et voyez si vous pouvez améliorer sa fiabilité.
En changeant simplement les identifiants des objets que le modèle recherche, vous pouvez transformer le code en quelque chose de complètement différent. Par exemple, imaginez que vous travaillez dans une station de ski. Après avoir apporté quelques modifications, vous pouvez transformer ce script en un système qui reconnaît automatiquement les snowboarders sautant de la rampe et enregistre des vidéos avec des sauts sympas. Ou, si vous travaillez dans une réserve naturelle, vous pouvez créer un système qui compte les zèbres. Vous n'êtes limité que par votre imagination.
D'autres articles de ce type peuvent être lus dans la chaîne de télégramme
Neuron (@neurondata)
Lien de traduction alternatif:
tproger.ru/translations/parking-searching/Toutes les connaissances. Expérimentez!