L'IA d'aujourd'hui est techniquement «faible» - cependant, elle est complexe et peut affecter de manière significative la société
 Vous n'avez pas besoin d'être Cyrus Dully pour savoir à quel point une intelligence intelligente effrayante peut devenir [un acteur américain qui a joué le rôle de l'astronaute Dave Bowman dans le film "Space Odyssey 2001" / env. perev.]
Vous n'avez pas besoin d'être Cyrus Dully pour savoir à quel point une intelligence intelligente effrayante peut devenir [un acteur américain qui a joué le rôle de l'astronaute Dave Bowman dans le film "Space Odyssey 2001" / env. perev.]L'IA, ou intelligence artificielle, est désormais l'un des domaines de connaissances les plus importants. Des tâches «insolubles» sont résolues, des milliards de dollars sont investis, et Microsoft
engage même
Common pour nous dire dans un calme poétique, quelle merveilleuse chose c'est - l'IA. C'est vrai.
Et, comme pour toute nouvelle technologie, il peut être difficile de surmonter tout ce battage médiatique. Je fais des recherches dans le domaine des drones et de l'IA depuis des années, mais même cela peut être difficile pour moi de suivre tout cela. Ces dernières années, j'ai passé beaucoup de temps à chercher des réponses aux questions les plus simples comme:
- Que veulent dire les gens en disant «IA»?
- Quelle est la différence entre l'IA, l'apprentissage automatique et l'apprentissage en profondeur?
- Qu'y a-t-il de si génial dans l'apprentissage profond?
- Quelles anciennes tâches difficiles sont maintenant faciles à résoudre et qu'est-ce qui est encore difficile?
Je sais que personne ne s'intéresse à de telles choses. Par conséquent, si vous êtes intéressé par ce que tous ces enthousiasmes à propos de l'IA sont connectés au niveau le plus simple, il est temps de regarder dans les coulisses. Si vous êtes un expert en IA et lisez des rapports de la Conférence sur le traitement de l'information neurologique (NIPS) pour le plaisir, l'article ne sera pas nouveau pour vous - cependant, nous attendons des clarifications et des corrections de votre part dans les commentaires.
Qu'est-ce que l'IA?
Il y a une vieille blague en informatique: quelle est la différence entre l'IA et l'automatisation? L'automatisation est quelque chose qui peut être fait à l'aide d'un ordinateur, et l'IA est quelque chose que nous aimerions pouvoir faire. Dès que l'on apprend à faire quelque chose, on passe du domaine de l'IA à la catégorie de l'automatisation.
Cette blague est valable aujourd'hui, car l'IA n'est pas définie assez clairement. L'intelligence artificielle n'est tout simplement pas un terme technique. Si vous montez sur Wikipédia, il est dit que l'IA est "l'intelligence démontrée par les machines, contrairement à l'intelligence naturelle démontrée par les gens et les autres animaux". On ne peut pas dire moins clairement.
En général, il existe deux types d'IA: forte et faible. La plupart des gens imaginent une IA forte quand ils entendent parler de l'IA - c'est une sorte d'intellect omniscient divin comme Skynet ou Hal 9000, capable de raisonner et comparable à l'homme, tout en dépassant ses capacités.
Les IA faibles sont des algorithmes hautement spécialisés conçus pour répondre à des questions utiles spécifiques dans des domaines étroitement définis. Par exemple, un très bon programme d'échecs entre dans cette catégorie. On peut en dire autant des logiciels qui ajustent très précisément les paiements d'assurance. Dans leur domaine, ces IA atteignent des résultats impressionnants, mais en général elles sont très limitées.
À l'exception des opus hollywoodiens, nous ne sommes même pas aujourd'hui proches d'une IA forte. Jusqu'à présent, toute IA est faible, et la plupart des chercheurs dans ce domaine conviennent que les techniques que nous avons inventées pour créer de grandes IA faibles ne sont pas susceptibles de nous rapprocher de la création d'une IA forte.
L'IA d'aujourd'hui est donc plus un terme marketing qu'un terme technique. La raison pour laquelle les entreprises annoncent leur IA au lieu de l'automatisation est qu'elles veulent introduire l'IA hollywoodienne dans l'esprit du public. Cependant, ce n'est pas si mal. Si cela n'est pas pris trop strictement, les entreprises veulent simplement dire que, bien que nous soyons encore très loin d'une IA forte, l'IA faible d'aujourd'hui est beaucoup plus capable qu'il y a plusieurs années.
Et si vous vous détournez du marketing, il en est ainsi. Dans certains domaines, les capacités des machines ont considérablement augmenté, principalement grâce à deux autres phrases désormais à la mode: le machine learning et le deep learning.
 Tiré d'une courte vidéo des ingénieurs de Facebook montrant comment l'IA en temps réel reconnaît les chats (une tâche également connue sous le nom de Saint Graal d'Internet)
Tiré d'une courte vidéo des ingénieurs de Facebook montrant comment l'IA en temps réel reconnaît les chats (une tâche également connue sous le nom de Saint Graal d'Internet)Apprentissage automatique
MO est un moyen spécial de créer une intelligence machine. Supposons que vous vouliez lancer une fusée et prédisez où elle ira. En général, ce n'est pas si difficile: la gravité est assez bien étudiée, vous pouvez écrire les équations et calculer où elle ira, en fonction de plusieurs variables - telles que la vitesse et la position initiale.
Cependant, cette approche devient maladroite si nous nous tournons vers un domaine dont les règles ne sont pas si bien connues et claires. Supposons que vous vouliez que l'ordinateur vous indique s'il y a des chats sur certaines images. Comment allez-vous écrire les règles qui décrivent la vue sous tous les points de vue possibles sur toutes les combinaisons possibles de moustache et d'oreilles?
Aujourd'hui, l'approche MO est bien connue: au lieu d'essayer d'écrire toutes les règles, vous créez un système qui peut dériver indépendamment un ensemble de règles internes après avoir étudié un grand nombre d'exemples. Au lieu de décrire des chats, vous montrez simplement à votre IA un tas de photos de chats et lui permettez de comprendre par lui-même ce qu'est un chat et ce qui ne l'est pas.
Et aujourd'hui, c'est l'approche parfaite. Un système d'auto-apprentissage basé sur des données peut être amélioré simplement en ajoutant des données. Et si notre espèce est capable de faire quelque chose de très bien, c'est de générer, stocker et gérer des données. Vous voulez apprendre à mieux reconnaître les chats? Internet génère des millions d'exemples dès cette minute.
Le flux toujours croissant de données est l'une des raisons de la croissance explosive des algorithmes MO ces derniers temps. D'autres raisons sont liées à l'utilisation de ces données.
En plus des données, il y a deux autres problèmes liés à cela pour la région de Moscou:
- Comment puis-je me souvenir de ce que j'ai appris? Comment stocker et présenter sur l'ordinateur les communications et les règles que j'ai déduites des données?
- Comment puis-je apprendre? Comment changer la représentation stockée en réponse à de nouveaux exemples, et s'améliorer?
En d'autres termes, que forme-t-on exactement sur la base de toutes ces données?
En MO, la représentation informatique de la formation que nous stockons est un modèle. Le type de modèle utilisé est très important: il détermine comment votre IA apprend, quelles données elle peut apprendre et quelles questions vous pouvez lui poser.
Regardons un exemple très simple. Supposons que nous achetions des figues dans une épicerie et que nous voulions faire une IA avec le MO qui nous dirait si elle est mûre. Cela devrait être facile à faire, car dans le cas des figues, plus le plus doux est doux.
Nous pouvons prendre plusieurs échantillons de figues mûres et non mûres, voir à quel point elles sont douces, puis les placer sur le graphique et ajuster la ligne droite pour cela. Cette ligne sera notre modèle.
 Embryon AI sous la forme de «le plus doux le plus doux»
Embryon AI sous la forme de «le plus doux le plus doux» Avec l'ajout de nouvelles données, la tâche devient plus compliquée.
Avec l'ajout de nouvelles données, la tâche devient plus compliquée.Jetez un oeil! La ligne droite suit implicitement l'idée que "plus ils sont doux, plus ils sont doux", et nous n'avons même pas eu à écrire quoi que ce soit. Notre fœtus IA ne sait rien de la teneur en sucre ou de la maturation des fruits, mais peut prédire la douceur d'un fruit en le pressant.
Comment former un modèle pour le rendre meilleur? Nous pouvons collecter encore plus d'échantillons et tracer une autre ligne droite pour obtenir des prédictions plus précises (comme dans la deuxième image ci-dessus). Cependant, les problèmes deviennent immédiatement apparents. Jusqu'à présent, nous avons formé notre IA aux figues sur des baies de qualité - et si nous prenions des données du verger? Du coup, nous avons non seulement des fruits mûrs, mais aussi des fruits pourris. Ils sont très mous, mais certainement pas adaptés à la consommation.
On fait quoi? Eh bien, comme il s'agit d'un modèle MO, nous pouvons simplement lui fournir plus de données, non?
Comme le montre la première image ci-dessous, dans ce cas, nous obtiendrons des résultats complètement dénués de sens. La ligne n'est tout simplement pas adaptée pour décrire ce qui se passe lorsque le fruit devient trop mûr. Notre modèle ne s'inscrit plus dans la structure des données.
Au lieu de cela, nous devons le changer et utiliser un modèle meilleur et plus complexe - peut-être une parabole ou quelque chose de similaire. Ce changement complique l'apprentissage car dessiner des courbes nécessite des mathématiques plus sophistiquées que tracer une ligne droite.
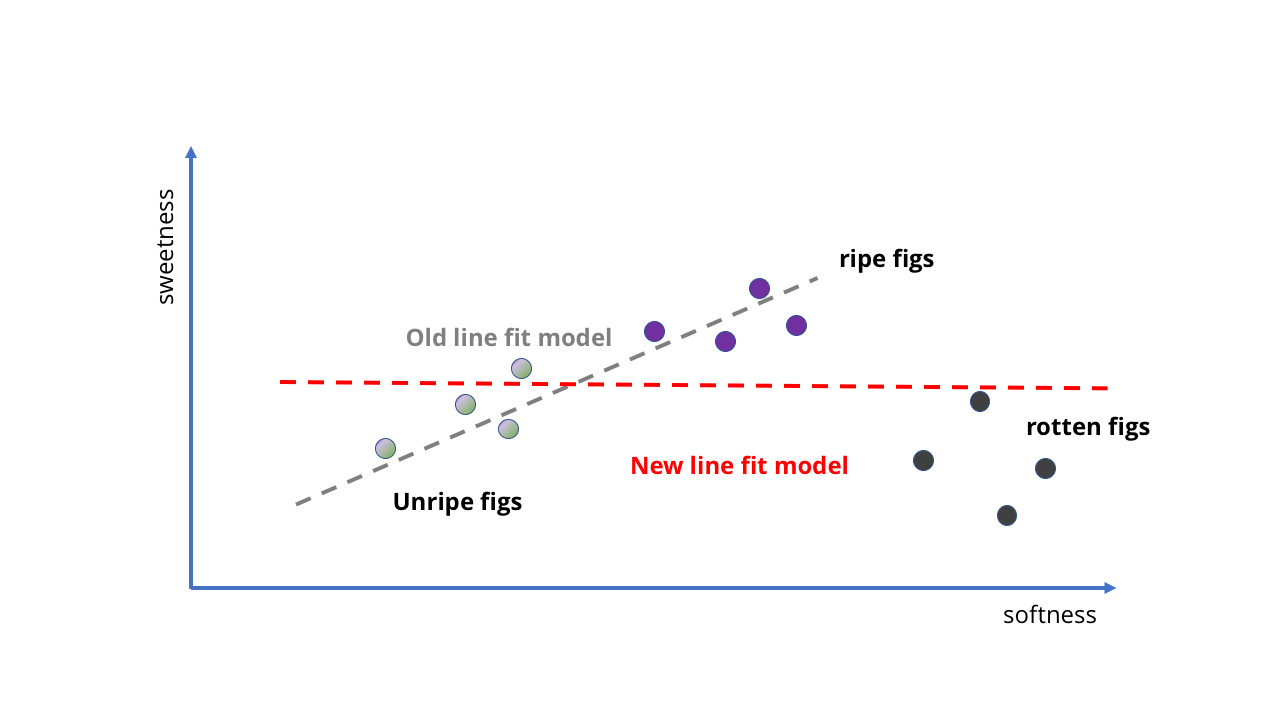 D'accord, l'idée d'utiliser une ligne droite pour une IA complexe n'a probablement pas été très réussie
D'accord, l'idée d'utiliser une ligne droite pour une IA complexe n'a probablement pas été très réussie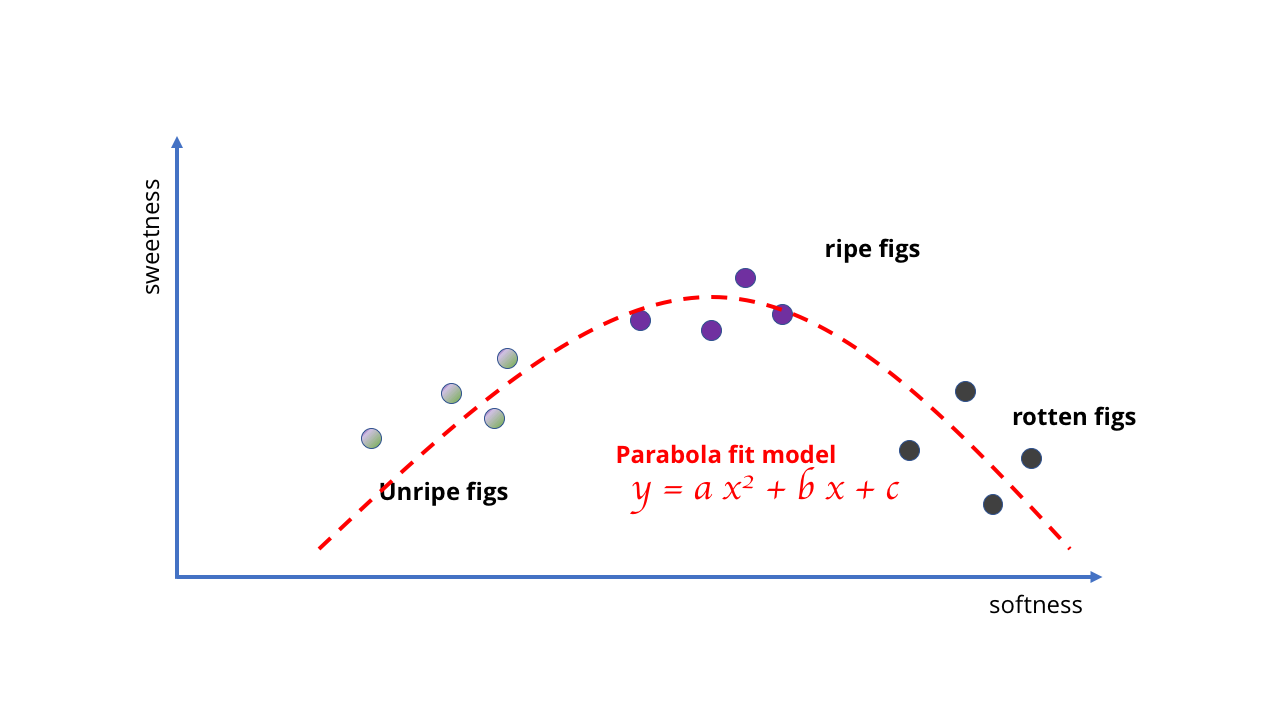 Des calculs plus compliqués sont nécessaires
Des calculs plus compliqués sont nécessairesL'exemple est assez stupide, mais il montre que le choix du modèle détermine les possibilités d'apprentissage. Dans le cas des figues, les données sont simples et les modèles peuvent être simples. Mais si vous essayez d'apprendre quelque chose de plus complexe, des modèles plus complexes sont nécessaires. Tout comme aucune quantité de données ne fait qu'un modèle linéaire reflète le comportement des baies pourries, il est impossible de sélectionner une simple courbe correspondant à un tas d'images pour créer un algorithme de vision par ordinateur.
Par conséquent, la difficulté pour le MO est de créer et de sélectionner les bons modèles pour les tâches correspondantes. Nous avons besoin d'un modèle suffisamment complexe pour décrire les relations et les structures vraiment complexes, mais suffisamment simple pour que vous puissiez travailler avec lui et le former. Ainsi, bien qu'Internet, les smartphones, etc. aient créé des montagnes de données incroyables pour apprendre, nous avons toujours besoin des bons modèles pour tirer parti de ces données.
C'est là que l'apprentissage profond entre en jeu.

Apprentissage profond
L'apprentissage profond est un apprentissage automatique qui utilise un certain type de modèle: les réseaux de neurones profonds.
Les réseaux de neurones sont un type de modèle MO qui utilise une structure ressemblant à des neurones dans le cerveau pour les calculs et les prévisions. Les neurones des réseaux de neurones sont organisés en couches: chaque couche effectue un ensemble de calculs simples et passe la réponse à la suivante.
Le modèle en couches permet des calculs plus complexes. Un simple réseau avec un petit nombre de couches de neurones suffit à reproduire la ligne droite ou la parabole que nous avons utilisée ci-dessus. Les réseaux de neurones profonds sont des réseaux de neurones avec un grand nombre de couches, des dizaines, voire des centaines; d'où leur nom. Avec autant de couches, vous pouvez créer des modèles incroyablement puissants.
Cette opportunité est l'une des principales raisons de l'énorme popularité des réseaux de neurones profonds ces derniers temps. Ils peuvent apprendre diverses choses complexes sans forcer un chercheur humain à définir des règles, ce qui nous a permis de créer des algorithmes qui peuvent résoudre une variété de problèmes que les ordinateurs ne pouvaient pas aborder auparavant.
Cependant, un autre aspect a contribué au succès des réseaux de neurones: la formation.
La «mémoire» d'un modèle est un ensemble de paramètres numériques qui détermine comment il fournit des réponses aux questions posées. Former un modèle signifie affiner ces paramètres afin que le modèle donne les meilleures réponses possibles.
Dans notre modèle avec figues, nous avons recherché l'équation de la droite. Il s'agit d'une tâche de régression simple et il existe des formules qui vous donneront la réponse en une seule étape.
 Réseau neuronal simple et réseau neuronal profond
Réseau neuronal simple et réseau neuronal profondAvec des modèles plus complexes, les choses ne sont pas si simples. Une ligne droite et une parabole peuvent facilement être représentées par plusieurs nombres, mais un réseau neuronal profond peut avoir des millions de paramètres, et l'ensemble de données pour sa formation peut également se composer de millions d'exemples. Il n'existe pas de solution analytique en une seule étape.
Heureusement, il y a une astuce étrange: vous pouvez commencer avec un mauvais réseau de neurones, puis l'améliorer avec des ajustements progressifs.
Apprendre le modèle MO de cette manière est similaire à tester un élève à l'aide de tests. Chaque fois que nous obtenons une évaluation en comparant quelles réponses devraient être de l'avis du modèle avec les réponses «correctes» dans les données de formation. Ensuite, nous apportons une amélioration et relançons le test.
Comment savons-nous quels paramètres ajuster et combien? Les réseaux de neurones ont une telle fonctionnalité intéressante lorsque, pour de nombreux types de formation, vous pouvez non seulement obtenir une évaluation dans le test, mais aussi calculer combien cela changera en réponse à un changement de chaque paramètre. En termes mathématiques, une estimation est une fonction de la valeur, et pour la plupart de ces fonctions, nous pouvons facilement calculer le gradient de cette fonction par rapport à l'espace des paramètres.
Maintenant, nous savons exactement de quelle manière nous devons ajuster les paramètres pour augmenter le score, et nous pouvons ajuster le réseau par étapes successives dans toutes les meilleures et meilleures «directions», jusqu'à ce que vous atteigniez un point où rien ne peut être amélioré. C'est ce qu'on appelle souvent grimper une colline, car c'est vraiment comme monter une colline: si vous montez constamment, vous vous retrouverez au sommet.
 Vous avez vu? Top!
Vous avez vu? Top!Grâce à cela, il est facile d'améliorer le réseau neuronal. Si votre réseau a une bonne structure, après avoir reçu de nouvelles données, vous n'avez pas besoin de recommencer à zéro. Vous pouvez commencer avec les paramètres disponibles et réapprendre des nouvelles données. Votre réseau s'améliorera progressivement. La plus importante des IA d'aujourd'hui - de la reconnaissance des chats sur Facebook aux technologies qu'Amazon utilise (probablement) dans les magasins sans vendeurs - est construite sur ce simple fait.
C'est la clé d'une autre raison pour laquelle la protection civile s'est répandue si rapidement et si largement: gravir une colline vous permet de prendre un réseau neuronal formé à une tâche et de le recycler pour en effectuer un autre, mais similaire. Si vous avez formé l'IA à bien reconnaître les chats, ce réseau peut être utilisé pour former une IA qui reconnaît les chiens ou les girafes sans avoir à recommencer à zéro. Commencez par l'IA pour chats, évaluez-la par la qualité de la reconnaissance des chiens, puis grimpez la colline, améliorant le réseau!
Par conséquent, au cours des 5-6 dernières années, il y a eu une nette amélioration des capacités de l'IA. Plusieurs pièces du puzzle se sont réunies de manière synergique: Internet a généré une énorme quantité de données à apprendre. Les calculs, en particulier les calculs parallèles sur les GPU, ont permis de traiter ces énormes ensembles. Enfin, les réseaux de neurones profonds ont permis de profiter de ces kits et de créer des modèles MO incroyablement puissants.
Et tout cela signifie que certaines choses qui étaient auparavant extrêmement difficiles sont maintenant très faciles à faire.
Et que pouvons-nous faire maintenant? Reconnaissance de formes
Peut-être le plus profond (désolé pour le jeu de mots) et le premier impact que l'apprentissage en profondeur a eu sur le domaine de la vision par ordinateur - en particulier, sur la reconnaissance des objets dans les photographies. Il y a quelques années, cette bande dessinée xkcd décrivait parfaitement la pointe de l'informatique:

Aujourd'hui, la reconnaissance des oiseaux et même de certains types d'oiseaux est une tâche banale qu'un élève du secondaire correctement motivé peut résoudre. Qu'est-ce qui a changé?
L'idée de la reconnaissance visuelle des objets est facile à décrire, mais difficile à mettre en œuvre: les objets complexes se composent d'ensembles plus simples, qui à leur tour se composent de formes et de lignes plus simples. Les visages sont constitués d'yeux, de nez et de bouches, et ceux-ci sont constitués de cercles et de lignes, etc.
Par conséquent, la reconnaissance faciale devient une question de reconnaissance des motifs dans lesquels les yeux et la bouche sont situés, ce qui peut nécessiter la reconnaissance de la forme de l'œil et de la bouche à partir des lignes et des cercles.
Ces modèles sont appelés fonctionnalités, et avant un apprentissage approfondi pour la reconnaissance, il était nécessaire de décrire toutes les fonctionnalités manuellement et de programmer l'ordinateur pour les trouver. Par exemple, il existe le célèbre algorithme de reconnaissance faciale
Viola-Jones , basé sur le fait que les sourcils et le nez sont généralement plus légers que les orbites, de sorte qu'ils forment une forme de T brillante avec deux points sombres. En fait, l'algorithme recherche des formes en T similaires.
La méthode Viola-Jones fonctionne bien et est étonnamment rapide, et sert de base à la reconnaissance faciale dans les appareils photo bon marché, etc. Mais, évidemment, tous les objets que vous devez reconnaître ne se prêtent pas à une telle simplification, et les gens ont proposé des modèles de plus en plus complexes et de bas niveau. Pour que les algorithmes fonctionnent correctement, une équipe de docteurs en sciences était nécessaire, ils étaient très sensibles et sujets à l'échec.
La grande percée est survenue grâce à la protection civile, et notamment à un certain type de réseau neuronal appelé réseau neuronal convolutionnel. Réseaux de neurones convolutifs, les SNS sont des réseaux profonds avec une certaine structure, inspirés de la structure du cortex visuel du cerveau des mammifères. Cette structure permet au SCN d'apprendre indépendamment la hiérarchie des lignes et des motifs pour reconnaître les objets, plutôt que d'attendre que les docteurs en sciences passent des années à rechercher les caractéristiques les mieux adaptées à cela. Par exemple, le SCN, formé sur les visages, apprendra sa propre représentation interne des lignes et des cercles, se pliant dans les yeux, les oreilles et le nez, etc.
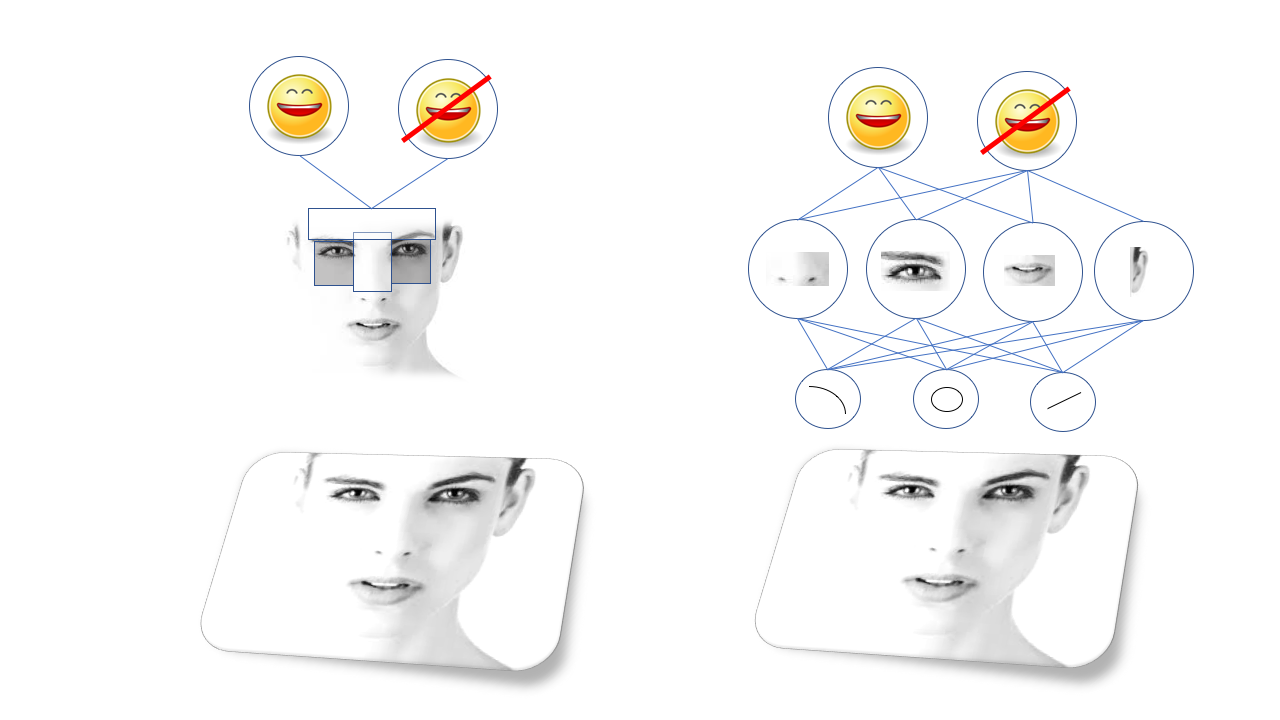 Les anciens algorithmes visuels (méthode Viola-Jones, à gauche) reposent sur des caractéristiques sélectionnées manuellement, et les réseaux de neurones profonds (à droite) sur leur propre hiérarchie de caractéristiques plus complexes composées de plus simples
Les anciens algorithmes visuels (méthode Viola-Jones, à gauche) reposent sur des caractéristiques sélectionnées manuellement, et les réseaux de neurones profonds (à droite) sur leur propre hiérarchie de caractéristiques plus complexes composées de plus simplesLe SCN était incroyablement bon pour la vision par ordinateur, et bientôt les chercheurs ont pu les former à effectuer toutes sortes de tâches sur la reconnaissance visuelle, de la recherche de chats sur la photo à l'identification des piétons qui se sont introduits dans la caméra d'un robot.
Tout cela est merveilleux, mais il y a une autre raison à une telle diffusion rapide et large du SCN - c'est leur facilité d'adaptation. Tu te souviens de gravir une colline?
Si notre lycéen veut reconnaître un oiseau spécifique, il peut prendre l'un des nombreux réseaux visuels avec du code open source et le former sur son propre ensemble de données, sans même comprendre comment les mathématiques sous-jacentes fonctionnent.Naturellement, cela peut encore être étendu.Qui est là? (reconnaissance faciale)
Supposons que vous souhaitiez former un réseau qui reconnaît non seulement les visages, mais un visage spécifique. Vous pouvez entraîner le réseau à reconnaître une personne spécifique, puis une autre personne, etc. Cependant, il faut du temps pour former les réseaux, et cela signifierait que pour chaque nouvelle personne, il serait nécessaire de recycler le réseau. Non, vraiment.Au lieu de cela, nous pouvons commencer avec un réseau formé pour reconnaître les visages en général. Ses neurones sont configurés pour reconnaître toutes les structures faciales: yeux, oreilles, bouches, etc. Ensuite, vous modifiez simplement la sortie: au lieu de la forcer à reconnaître certains visages, vous lui ordonnez de donner une description du visage sous la forme de centaines de chiffres décrivant la courbure du nez ou la forme des yeux, etc. Le réseau peut le faire car il «connaît» déjà les composants du visage.Bien sûr, vous ne définissez pas tout cela directement. Au lieu de cela, vous entraînez le réseau en lui montrant un ensemble de visages, puis en comparant la sortie. Vous lui apprenez aussi à ce qu'elle donne des descriptions similaires les unes aux autres de la même personne, et très différentes les unes des autres des descriptions de personnes différentes. Mathématiquement parlant, vous entraînez un réseau à construire une correspondance avec les images de visages d'un point dans un espace d'entités, où la distance cartésienne entre les points peut être utilisée pour déterminer leur similitude. Changer le réseau neuronal de la reconnaissance des visages (à gauche) à la description des visages (à droite) ne nécessite que de changer le format des données de sortie, sans changer sa base.
Changer le réseau neuronal de la reconnaissance des visages (à gauche) à la description des visages (à droite) ne nécessite que de changer le format des données de sortie, sans changer sa base. Vous pouvez maintenant reconnaître les visages en comparant les descriptions de chacun des visages créés par le réseau neuronalAprès avoir formé le réseau, vous pouvez facilement reconnaître les visages. Vous prenez la personne d'origine et obtenez sa description. Ensuite, prenez un nouveau visage et comparez la description fournie par le réseau avec votre original. S'ils sont assez proches, vous dites que c'est une seule et même personne. Et maintenant, vous êtes passé d'un réseau capable de reconnaître un visage à ce qui peut être utilisé pour reconnaître n'importe quel visage!Cette flexibilité structurelle est une autre raison de l'utilité des réseaux de neurones profonds. Un grand nombre de différents modèles d'OM pour la vision par ordinateur ont déjà été développés, et bien qu'ils évoluent dans des directions très différentes, la structure de base de beaucoup d'entre eux est basée sur des SNA antérieurs comme Alexnet et Resnet.J'ai même entendu des histoires de personnes utilisant des réseaux de neurones visuels pour travailler avec des données de séries chronologiques ou des mesures de capteurs. Au lieu de créer un réseau spécial pour analyser le flux de données, ils ont formé un réseau neuronal open source conçu pour la vision par ordinateur à regarder littéralement les formes des graphiques linéaires.Une telle flexibilité est une bonne chose, mais pas infinie. Pour résoudre certains autres problèmes, vous devez utiliser d'autres types de réseaux.
Vous pouvez maintenant reconnaître les visages en comparant les descriptions de chacun des visages créés par le réseau neuronalAprès avoir formé le réseau, vous pouvez facilement reconnaître les visages. Vous prenez la personne d'origine et obtenez sa description. Ensuite, prenez un nouveau visage et comparez la description fournie par le réseau avec votre original. S'ils sont assez proches, vous dites que c'est une seule et même personne. Et maintenant, vous êtes passé d'un réseau capable de reconnaître un visage à ce qui peut être utilisé pour reconnaître n'importe quel visage!Cette flexibilité structurelle est une autre raison de l'utilité des réseaux de neurones profonds. Un grand nombre de différents modèles d'OM pour la vision par ordinateur ont déjà été développés, et bien qu'ils évoluent dans des directions très différentes, la structure de base de beaucoup d'entre eux est basée sur des SNA antérieurs comme Alexnet et Resnet.J'ai même entendu des histoires de personnes utilisant des réseaux de neurones visuels pour travailler avec des données de séries chronologiques ou des mesures de capteurs. Au lieu de créer un réseau spécial pour analyser le flux de données, ils ont formé un réseau neuronal open source conçu pour la vision par ordinateur à regarder littéralement les formes des graphiques linéaires.Une telle flexibilité est une bonne chose, mais pas infinie. Pour résoudre certains autres problèmes, vous devez utiliser d'autres types de réseaux. Et même à ce point, les assistants virtuels ont pris très longtemps
Et même à ce point, les assistants virtuels ont pris très longtempsQu'avez-vous dit? (Reconnaissance vocale)
Le catalogage d'images et la vision par ordinateur ne sont pas les seuls domaines de résurgence de l'IA. Un autre domaine dans lequel les ordinateurs sont venus très loin est la reconnaissance vocale, en particulier dans la traduction de la parole en écriture.L'idée de base de la reconnaissance vocale est assez similaire au principe de la vision par ordinateur: reconnaître des choses complexes sous la forme d'ensembles de choses plus simples. Dans le cas de la parole, la reconnaissance des phrases et des phrases est basée sur la reconnaissance des mots, qui est basée sur la reconnaissance des syllabes ou, pour être plus précis, des phonèmes. Donc, quand quelqu'un dit «Bond, James Bond», nous entendons en fait BON + DUH + JAY + MMS + BON + DUH.En vision, les entités sont organisées spatialement et le SCN traite cette structure. Dans la rumeur, ces fonctionnalités sont organisées dans le temps. Les gens peuvent parler rapidement ou lentement, sans début ni fin de discours clairs. Nous avons besoin d'un modèle capable de percevoir les sons à mesure qu'ils arrivent, en tant que personne, au lieu d'attendre et de chercher des phrases complètes en eux. Nous ne pouvons pas, comme en physique, dire que l'espace et le temps sont une seule et même chose.Reconnaître des syllabes individuelles est assez facile, mais elles sont difficiles à isoler. Par exemple, «Hello there» peut sonner comme «hell no they»… Ainsi, pour toute séquence de sons, il existe généralement plusieurs combinaisons de syllabes réellement prononcées.Pour comprendre tout cela, nous avons besoin d'étudier la séquence dans un certain contexte. Si j'entends un son, ce qui est plus probable est que la personne a dit "bonjour mon cher" ou "bon sang non ce sont des cerfs?" Là encore, l'apprentissage automatique vient à la rescousse. Avec un ensemble suffisamment large de modèles de mots prononcés, vous pouvez apprendre les phrases les plus probables. Et plus vous avez d'exemples, mieux cela se révélera.Pour cela, les gens utilisent des réseaux de neurones récurrents, RNS. Dans la plupart des types de réseaux de neurones, comme le SNA impliqué dans la vision par ordinateur, les connexions entre les neurones fonctionnent dans une direction, de l'entrée à la sortie (mathématiquement parlant, ce sont des graphiques acycliques dirigés). Dans RNS, la sortie des neurones peut être redirigée vers des neurones du même niveau, vers eux-mêmes ou même plus loin. Cela permet au RNS d'avoir sa propre mémoire (si vous connaissez la logique binaire, cette situation est similaire au fonctionnement des déclencheurs).SNA travaille pour une approche: nous lui donnons une image et elle donne une description. Le RNS maintient la mémoire interne de ce qui lui a été donné plus tôt et donne des réponses basées sur ce qu'elle a déjà vu, plus ce qu'elle voit maintenant.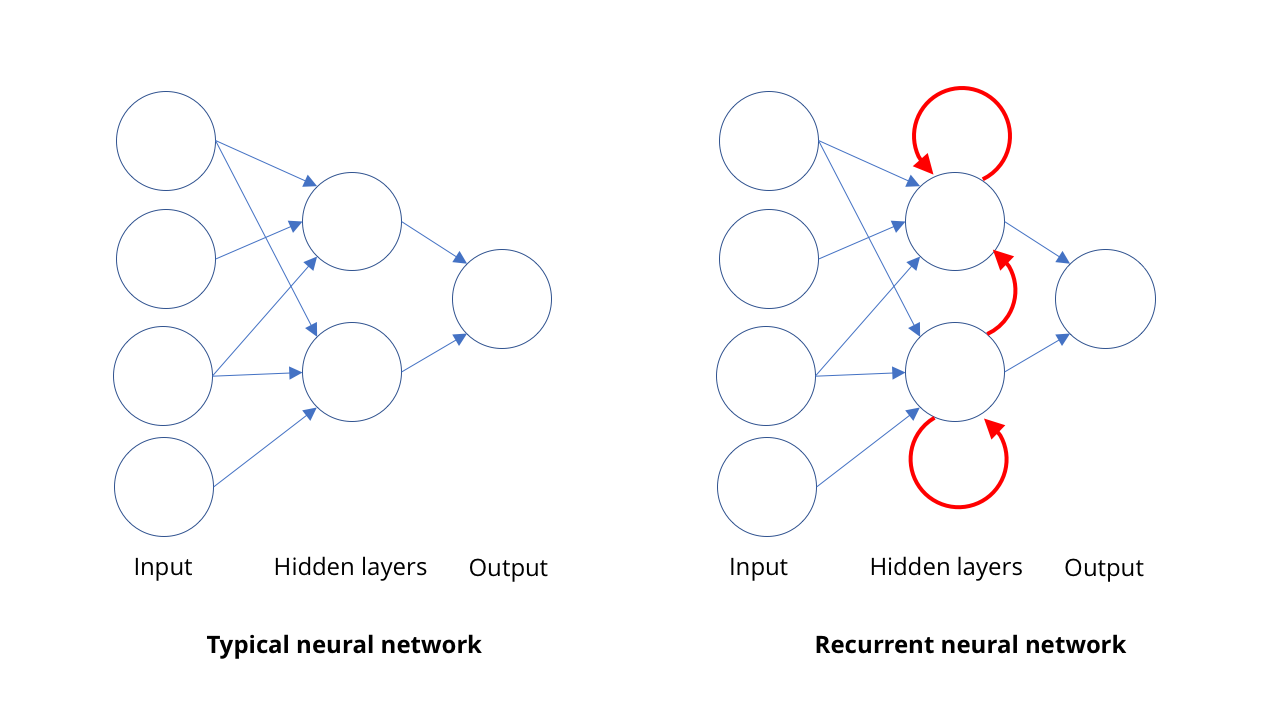 Cette propriété de la mémoire dans le RNS leur permet non seulement «d'écouter» les syllabes qui lui viennent une à une. Cela permet au réseau d'apprendre quelles syllabes vont ensemble pour former un mot, et la probabilité de certaines séquences.En utilisant RNS, il est possible d'obtenir une très bonne transcription de la parole humaine - à tel point que les ordinateurs peuvent désormais surpasser les humains dans certaines mesures de la précision de la transcription. Bien sûr, les sons ne sont pas le seul domaine où les séquences apparaissent. Aujourd'hui, RNS est également utilisé pour déterminer des séquences de mouvements pour reconnaître des actions sur vidéo.
Cette propriété de la mémoire dans le RNS leur permet non seulement «d'écouter» les syllabes qui lui viennent une à une. Cela permet au réseau d'apprendre quelles syllabes vont ensemble pour former un mot, et la probabilité de certaines séquences.En utilisant RNS, il est possible d'obtenir une très bonne transcription de la parole humaine - à tel point que les ordinateurs peuvent désormais surpasser les humains dans certaines mesures de la précision de la transcription. Bien sûr, les sons ne sont pas le seul domaine où les séquences apparaissent. Aujourd'hui, RNS est également utilisé pour déterminer des séquences de mouvements pour reconnaître des actions sur vidéo.Montrez-moi comment vous pouvez vous déplacer (contrefaçons profondes et réseaux génératifs)
Jusqu'à présent, nous avons parlé de modèles MO conçus pour la reconnaissance: dites-moi ce qui est montré sur l'image, dites-moi ce que la personne a dit. Mais ces modèles sont capables de plus: les modèles GO actuels peuvent également être utilisés pour créer du contenu.C'est à ce moment-là que les gens parlent de deepfake - de fausses vidéos et images incroyablement réalistes créées à l'aide de GO. Il y a quelque temps, un responsable de la télévision allemande a provoqué une discussion politique approfondie en créant une fausse vidéodans lequel le ministre grec des finances a montré à l'Allemagne le doigt du milieu. Pour créer cette vidéo, nous avions besoin d'une équipe de rédacteurs qui ont travaillé pour créer une émission de télévision, mais dans le monde moderne, cela peut être fait en quelques minutes par toute personne ayant accès à un ordinateur de jeu de taille moyenne.Tout cela est plutôt triste, mais pas si sombre dans ce domaine - ma vidéo préférée sur le sujet de cette technologie est montrée en haut.Cette équipe a créé un modèle capable de traiter une vidéo avec les mouvements de danse d'une personne et de créer une vidéo avec une autre personne répétant ces mouvements, les exécutant comme par magie au niveau expert. Il est également intéressant de lire les travaux scientifiques qui l'accompagnent .On peut imaginer qu'en utilisant toutes les techniques discutées par nous, il est possible de former un réseau qui reçoit l'image d'un danseur et indique où se trouvent ses bras et ses jambes. Et dans ce cas, évidemment, à un certain niveau, le réseau a appris à connecter les pixels de l'image à l'emplacement des membres humains. Étant donné qu'un réseau neuronal n'est que des données stockées sur un ordinateur, et non un cerveau biologique, il devrait être possible de prendre ces données et d'aller dans la direction opposée - pour obtenir des pixels correspondant à l'emplacement des membres.Commencez avec un réseau qui extrait des poses d'images de personnes.
Les modèles MO qui peuvent le faire sont appelés modèles génératifs. générer - générer, produire, créer / env. trad.]. Tous les modèles précédents que nous avons considérés sont appelés discriminatoires [eng. discriminer - pour distinguer / env. trad.]. La différence entre eux peut être imaginée comme suit: un modèle discriminatoire pour les chats regarde les photos et fait la distinction entre les photos contenant des chats et les photos où elles ne le sont pas. Le modèle génératif crée des images de chats basées sur, disons, une description de ce à quoi devrait ressembler un chat. Les modèles génératifs qui «dessinent» des images d'objets sont créés en utilisant les mêmes structures SNA que les modèles utilisés pour reconnaître ces objets. Et ces modèles peuvent être formés de la même manière que les autres modèles MO.Cependant, l'astuce consiste à proposer une «évaluation» de leur formation. Lors de la formation d'un modèle discriminatoire, il existe un moyen simple d'évaluer l'exactitude et l'inexactitude de la réponse - par exemple, si le réseau a correctement distingué le chien du chat. Cependant, comment évaluer la qualité de l'image de chat résultante, ou sa précision?Et ici, pour une personne qui aime les théories du complot et croit que nous sommes tous condamnés, la situation devient un peu effrayante. Vous voyez, la meilleure façon que nous avons inventée pour apprendre les réseaux génératifs n'est pas de le faire vous-même. Pour cela, nous utilisons simplement un réseau neuronal différent.Cette technologie s'appelle un réseau contradictoire génératif, ou GSS. Vous forcez deux réseaux de neurones à rivaliser: un réseau essaie de créer des faux, par exemple, en dessinant un nouveau danseur basé sur les anciennes postures. Un autre réseau est formé pour trouver la différence entre des exemples réels et faux en utilisant un tas d'exemples de danseurs réels.Et ces deux réseaux jouent un jeu compétitif. D'où le mot "contradictoire" dans le titre. Le réseau génératif essaie de faire des faux convaincants, et le réseau discriminatoire essaie de comprendre où est le faux et où est la vraie chose.Dans le cas d'une vidéo avec une danseuse, un réseau discriminatoire distinct a été créé pendant le processus de formation, donnant des réponses simples oui / non. Elle a regardé l'image de la personne et la description de la position de ses membres, et a décidé si l'image était une vraie photographie ou une image dessinée par un modèle génératif.
Les modèles génératifs qui «dessinent» des images d'objets sont créés en utilisant les mêmes structures SNA que les modèles utilisés pour reconnaître ces objets. Et ces modèles peuvent être formés de la même manière que les autres modèles MO.Cependant, l'astuce consiste à proposer une «évaluation» de leur formation. Lors de la formation d'un modèle discriminatoire, il existe un moyen simple d'évaluer l'exactitude et l'inexactitude de la réponse - par exemple, si le réseau a correctement distingué le chien du chat. Cependant, comment évaluer la qualité de l'image de chat résultante, ou sa précision?Et ici, pour une personne qui aime les théories du complot et croit que nous sommes tous condamnés, la situation devient un peu effrayante. Vous voyez, la meilleure façon que nous avons inventée pour apprendre les réseaux génératifs n'est pas de le faire vous-même. Pour cela, nous utilisons simplement un réseau neuronal différent.Cette technologie s'appelle un réseau contradictoire génératif, ou GSS. Vous forcez deux réseaux de neurones à rivaliser: un réseau essaie de créer des faux, par exemple, en dessinant un nouveau danseur basé sur les anciennes postures. Un autre réseau est formé pour trouver la différence entre des exemples réels et faux en utilisant un tas d'exemples de danseurs réels.Et ces deux réseaux jouent un jeu compétitif. D'où le mot "contradictoire" dans le titre. Le réseau génératif essaie de faire des faux convaincants, et le réseau discriminatoire essaie de comprendre où est le faux et où est la vraie chose.Dans le cas d'une vidéo avec une danseuse, un réseau discriminatoire distinct a été créé pendant le processus de formation, donnant des réponses simples oui / non. Elle a regardé l'image de la personne et la description de la position de ses membres, et a décidé si l'image était une vraie photographie ou une image dessinée par un modèle génératif. GSS force deux réseaux à se faire concurrence: l'un produit des faux et l'autre essaie de distinguer les faux de l'original.
GSS force deux réseaux à se faire concurrence: l'un produit des faux et l'autre essaie de distinguer les faux de l'original.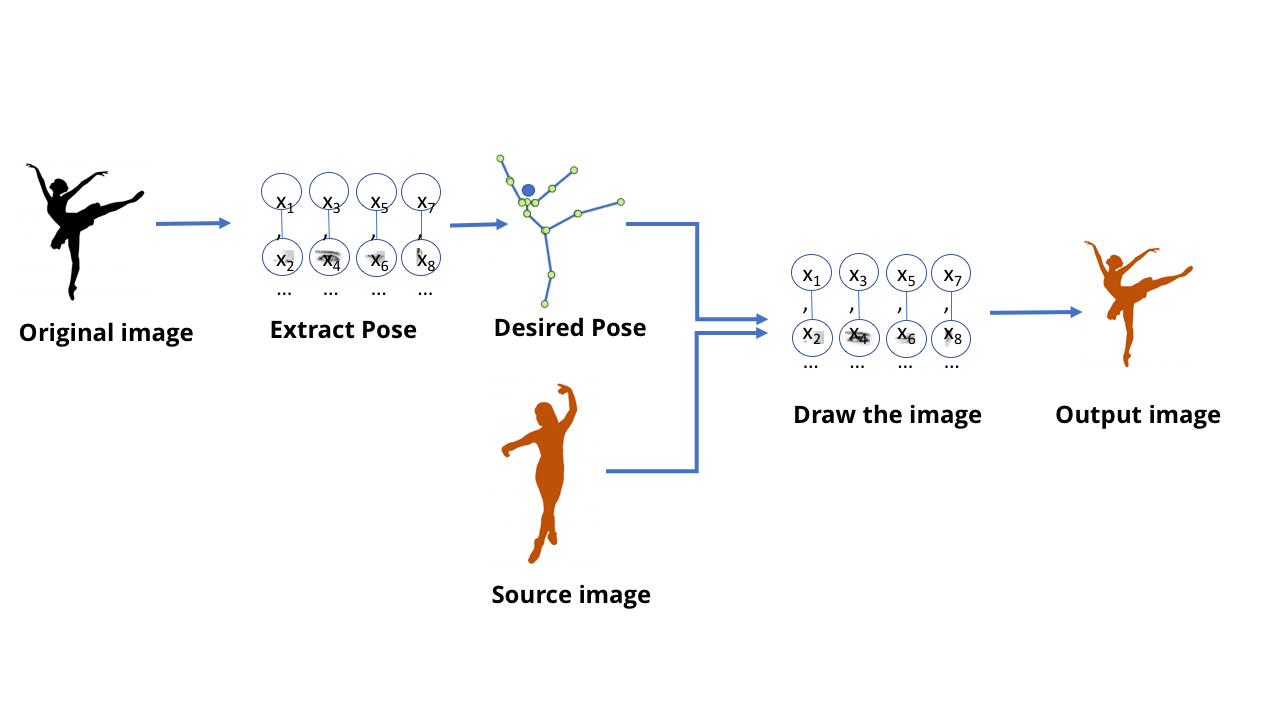 Dans le flux de travail final, seul un modèle génératif est utilisé pour créer les images nécessairesAu cours des cycles d'entraînement répétés, les modèles sont devenus de mieux en mieux. Cela ressemble à une compétition entre un expert en bijoux et un expert en évaluation - en concurrence avec un adversaire fort, chacun d'eux devient plus fort et plus intelligent. Enfin, lorsque les modèles fonctionnent assez bien, vous pouvez prendre un modèle génératif et l'utiliser séparément.Les modèles génératifs post-formation peuvent être très utiles pour créer du contenu. Par exemple, ils peuvent générer des images de visages (qui peuvent être utilisés pour former des programmes de reconnaissance faciale), ou des arrière-plans pour les jeux vidéo.Pour que tout cela fonctionne correctement, beaucoup de travail sur les ajustements et les corrections est nécessaire, mais essentiellement la personne ici agit comme arbitre. C'est l'IA qui fonctionne les uns contre les autres, apportant des améliorations majeures.
Dans le flux de travail final, seul un modèle génératif est utilisé pour créer les images nécessairesAu cours des cycles d'entraînement répétés, les modèles sont devenus de mieux en mieux. Cela ressemble à une compétition entre un expert en bijoux et un expert en évaluation - en concurrence avec un adversaire fort, chacun d'eux devient plus fort et plus intelligent. Enfin, lorsque les modèles fonctionnent assez bien, vous pouvez prendre un modèle génératif et l'utiliser séparément.Les modèles génératifs post-formation peuvent être très utiles pour créer du contenu. Par exemple, ils peuvent générer des images de visages (qui peuvent être utilisés pour former des programmes de reconnaissance faciale), ou des arrière-plans pour les jeux vidéo.Pour que tout cela fonctionne correctement, beaucoup de travail sur les ajustements et les corrections est nécessaire, mais essentiellement la personne ici agit comme arbitre. C'est l'IA qui fonctionne les uns contre les autres, apportant des améliorations majeures.Alors, faut-il s'attendre à l'apparition de Skynet et Hal 9000 dans un futur proche?
Dans chaque documentaire sur la nature à la fin, il y a un épisode où les auteurs parlent de la façon dont toute cette beauté grandiose disparaîtra bientôt en raison de la façon dont les gens sont terribles. Je pense que dans le même esprit, chaque discussion responsable concernant l'IA devrait inclure une section sur ses limites et ses conséquences sociales.
Tout d'abord, soulignons une fois de plus les limites actuelles de l'IA: l'idée principale que j'espère que vous avez apprise en lisant cet article est que le succès du MO ou de l'IA dépend fortement des modèles de formation que nous avons choisis. Si les gens n'organisent pas bien le réseau ou n'utilisent pas du matériel inapproprié pour la formation, ces distorsions peuvent être très évidentes pour tout le monde.
Les réseaux de neurones profonds sont incroyablement flexibles et puissants, mais n'ont pas de propriétés magiques. Malgré le fait que vous utilisez des réseaux de neurones profonds pour le RNS et le SNA, leur structure est très différente, et par conséquent, les gens devraient la déterminer de toute façon. Donc, même si vous pouvez prendre le SCN pour les voitures et le recycler pour la reconnaissance des oiseaux, vous ne pouvez pas prendre ce modèle et le recycler pour la reconnaissance vocale.
Si nous le décrivons en termes humains, alors tout semble avoir compris comment fonctionnent le cortex visuel et le cortex auditif, mais nous n'avons aucune idée du fonctionnement du cortex cérébral et où nous pouvons commencer à l'approcher.
Cela signifie que dans un avenir proche, nous ne verrons probablement pas l'IA dieu hollywoodienne. Mais cela ne signifie pas que dans sa forme actuelle, l'IA ne peut pas avoir un impact sérieux sur la société.
Nous imaginons souvent comment l'IA nous «remplace», c'est-à-dire comment les robots font littéralement notre travail, mais en réalité, cela ne se produira pas. Jetez un oeil à la radiologie, par exemple: parfois, les gens, en regardant le succès de la vision par ordinateur, disent que l'IA remplacera les radiologues. Peut-être n'arriverons-nous pas au point où nous n'aurons plus du tout de radiologue humain. Mais un avenir est tout à fait possible dans lequel, pour une centaine de radiologues d'aujourd'hui, l'IA permettra à cinq à dix d'entre eux de faire le travail de tout le monde. Si un tel scénario se concrétise, où iront les 90 médecins restants?
Même si la génération moderne de l'IA ne répond pas aux espoirs de ses partisans les plus optimistes, cela entraînera encore des conséquences très importantes. Et nous devrons résoudre ces problèmes, donc un bon début sera probablement de maîtriser les bases de ce domaine.