Présentation
Déployer le prochain système, face à la nécessité de traiter un grand nombre de journaux différents. Comme l'outil choisi ELK. Cet article présente notre expérience de l'optimisation de cette pile.
Nous n'avons pas pour objectif de décrire toutes ses possibilités, mais nous voulons nous concentrer précisément sur la résolution de problèmes pratiques. Cela est dû au fait qu'en présence d'une quantité suffisamment importante de documentation et d'images prêtes à l'emploi, il existe de nombreux pièges, du moins nous les avons trouvés.
Nous avons déployé la pile via docker-compose. De plus, nous avions un docker-compose.yml bien écrit, ce qui nous a permis d'augmenter la pile sans presque aucun problème. Et il nous a semblé que la victoire était déjà proche, maintenant nous allons tordre un peu pour répondre à nos besoins et c'est tout.
Malheureusement, une tentative de réglage du système pour recevoir et traiter les journaux de notre application n'a pas été couronnée de succès. Par conséquent, nous avons décidé qu'il valait la peine d'explorer chaque composante séparément, puis de revenir à leurs relations.
Nous avons donc commencé avec logstash.
Environnement, déploiement, lancement de Logstash dans le conteneur
Pour le déploiement, nous utilisons docker-compose, les expériences décrites ici ont été menées sur MacOS et Ubuntu 18.0.4.
L'image logstash enregistrée avec nous dans le docker-compose.yml d'origine est docker.elastic.co/logstash/logstash:6.3.2
Nous l'utiliserons pour des expériences.
Pour exécuter logstash, nous avons écrit un docker-compose.yml distinct. Bien sûr, il était possible de lancer l'image à partir de la ligne de commande, mais nous avons résolu un problème spécifique, où tout de docker-compose est lancé.
En bref sur les fichiers de configuration
Comme il ressort de la description, logstash peut être exécuté à la fois pour un canal, dans ce cas, il doit transférer le fichier * .conf ou pour plusieurs canaux, dans ce cas, il doit être transféré le fichier pipelines.yml, qui, à son tour, sera lié aux fichiers .conf pour chaque canal.
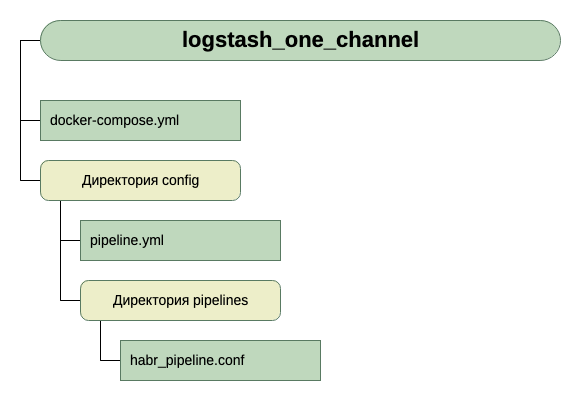
Nous sommes allés dans la deuxième voie. Il nous a semblé plus universel et évolutif. Par conséquent, nous avons créé pipelines.yml et créé le répertoire pipelines dans lequel nous placerons les fichiers .conf pour chaque canal.
À l'intérieur du conteneur, il y a un autre fichier de configuration - logstash.yml. On ne le touche pas, on l'utilise tel quel.
Ainsi, la structure de nos répertoires:
Pour obtenir l'entrée, pour l'instant, nous pensons que c'est TCP sur le port 5046, et pour la sortie, nous utiliserons stdout.
Voici une configuration si simple pour la première exécution. Depuis la tâche initiale est de lancer.
Nous avons donc ce docker-compose.yml
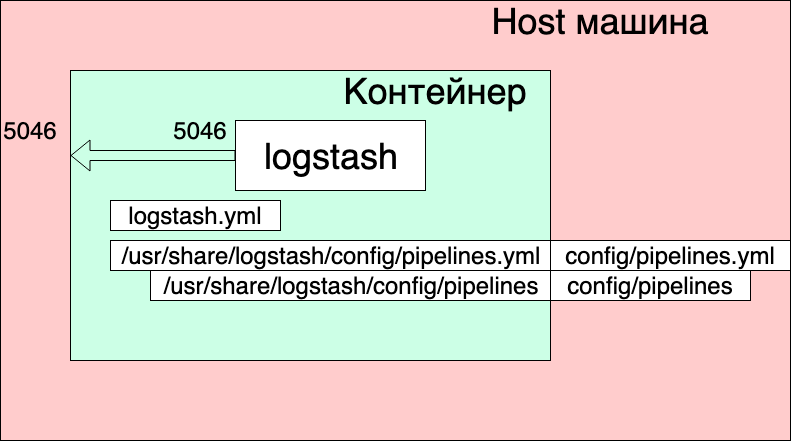
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro
Que voyons-nous ici?
- Les réseaux et les volumes ont été pris à partir du docker-compose.yml d'origine (celui où la pile entière est lancée) et je pense qu'ils n'affectent pas de manière significative l'image globale ici.
- Nous créons un service logstash à partir de l'image docker.elastic.co/logstash/logstash:6.3.2 et lui donnons le nom logstash_one_channel.
- Nous transmettons le port 5046 à l'intérieur du conteneur au même port interne.
- Nous mappons notre fichier de paramètres de canal ./config/pipelines.yml au fichier /usr/share/logstash/config/pipelines.yml à l'intérieur du conteneur, où logstash le récupérera et le rendra en lecture seule, juste au cas où.
- Nous affichons le répertoire ./config/pipelines, où nous avons les fichiers avec les paramètres de canal, dans le répertoire / usr / share / logstash / config / pipelines et le rendons en lecture seule.
Fichier Pipelines.yml
- pipeline.id: HABR pipeline.workers: 1 pipeline.batch.size: 1 path.config: "./config/pipelines/habr_pipeline.conf"
Ici, un canal avec l'identifiant HABR et le chemin vers son fichier de configuration sont décrits.
Et enfin le fichier "./config/pipelines/habr_pipeline.conf"
input { tcp { port => "5046" } } filter { mutate { add_field => [ "habra_field", "Hello Habr" ] } } output { stdout { } }
N'entrons pas dans sa description pour l'instant, essayons de lancer:
docker-compose up
Que voyons-nous?
Le conteneur a démarré. On peut vérifier son fonctionnement:
echo '13123123123123123123123213123213' | nc localhost 5046
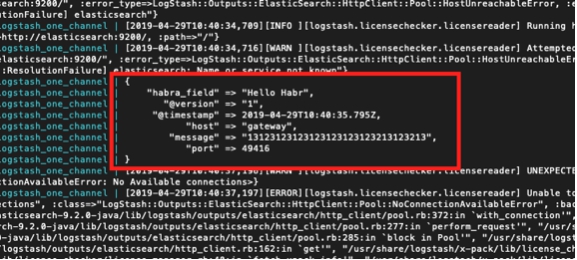
Et nous voyons la réponse dans la console de conteneur:
Mais en même temps, nous voyons également:
logstash_one_channel | [2019-04-29T11: 28: 59,790]
[ERREUR] [logstash.licensechecker.licensereader] Impossible de récupérer les informations de licence à partir du serveur de licences {: message => "Elasticsearch inaccessible: [http: // elasticsearch: 9200 /] [Manticore :: ResolutionFailure] elasticsearch ", ...
logstash_one_channel | [2019-04-29T11: 28: 59,894] [INFO] [logstash.pipeline] Le
pipeline a démarré avec succès {: pipeline_id => ". Monitoring-logstash" ,: thread => "# <Thread: 0x119abb86 run>"}
logstash_one_channel | [2019-04-29T11: 28: 59,988] [INFO] [logstash.agent] Pipelines en cours d'exécution {: count => 2 ,: running_pipelines => [: HABR ,: ". Monitoring-logstash"] ,: non_running_pipelines => [ ]}
logstash_one_channel | [2019-04-29T11: 29: 00,015]
[ERREUR] [logstash.inputs.metrics] X-Pack est installé sur Logstash mais pas sur Elasticsearch. Veuillez installer X-Pack sur Elasticsearch pour utiliser la fonction de surveillance. D'autres fonctionnalités peuvent être disponibles.logstash_one_channel | [2019-04-29T11: 29: 00,526] [INFO] [logstash.agent] Point de terminaison de l'API Logstash démarré avec succès {: port => 9600}
logstash_one_channel | [2019-04-29T11: 29: 04,478] [INFO] [logstash.outputs.elasticsearch] Exécution d'un contrôle d'intégrité pour voir si une connexion Elasticsearch fonctionne {: healthcheck_url => http: // elasticsearch: 9200 / ,: path => "/"}
l
ogstash_one_channel | [2019-04-29T11: 29: 04,487]
[WARN] [logstash.outputs.elasticsearch] Tentative de ressusciter la connexion à une instance ES morte, mais a obtenu une erreur. {: url => « elasticsearch : 9200 /» ,: error_type => LogStash :: Outputs :: ElasticSearch :: HttpClient :: Pool :: HostUnreachableError ,: error => «Elasticsearch Unreachable: [http: // elasticsearch: 9200 / ] [Manticore :: ResolutionFailure] elasticsearch ”}logstash_one_channel | [2019-04-29T11: 29: 04,704] [INFO] [logstash.licensechecker.licensereader] Exécution d'un contrôle d'intégrité pour voir si une connexion Elasticsearch fonctionne {: healthcheck_url => http: // elasticsearch: 9200 / ,: path => "/"}
logstash_one_channel | [2019-04-29T11: 29: 04,710]
[AVERTISSEMENT] [logstash.licensechecker.licensereader] Vous avez tenté de ressusciter la connexion à une instance ES morte, mais vous avez obtenu une erreur. {: url => « elasticsearch : 9200 /» ,: error_type => LogStash :: Outputs :: ElasticSearch :: HttpClient :: Pool :: HostUnreachableError ,: error => «Elasticsearch Unreachable: [http: // elasticsearch: 9200 / ] [Manticore :: ResolutionFailure] elasticsearch ”}Et notre journal grimpe tout le temps.
Ici, j'ai mis en évidence en vert un message indiquant que le pipeline a démarré avec succès, en rouge - un message d'erreur et en jaune - un message concernant une tentative de contact avec
elasticsearch : 9200.
Cela se produit du fait que logstash.conf inclus dans l'image contient une vérification de la disponibilité d'elasticsearch. Après tout, logstash suppose qu'il fonctionne dans le cadre de la pile Elk, et nous l'avons séparé.
Vous pouvez travailler, mais pas pratique.
La solution consiste à désactiver cette vérification via la variable d'environnement XPACK_MONITORING_ENABLED.
Apportez une modification à docker-compose.yml et exécutez-le à nouveau:
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro
Maintenant, tout va bien. Le conteneur est prêt pour l'expérimentation.
On peut encore taper dans la console suivante:
echo '13123123123123123123123213123213' | nc localhost 5046
Et voyez:
logstash_one_channel | { logstash_one_channel | "message" => "13123123123123123123123213123213", logstash_one_channel | "@timestamp" => 2019-04-29T11:43:44.582Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "host" => "gateway", logstash_one_channel | "port" => 49418 logstash_one_channel | }
Travailler dans un seul canal
Nous avons donc commencé. Vous pouvez maintenant prendre le temps de configurer directement logstash. Nous ne toucherons pas au fichier pipelines.yml pour le moment, nous verrons ce que vous pouvez obtenir en travaillant avec un seul canal.
Je dois dire que le principe général de travailler avec le fichier de configuration de canal est bien décrit dans le guide officiel,
iciSi vous voulez lire en russe, nous avons utilisé cet
article ici (mais la syntaxe de la requête est ancienne là-bas, nous devons en tenir compte).
Allons séquentiellement à partir de la section Input. Nous avons déjà vu des travaux sur TCP. Quoi d'autre pourrait être intéressant ici?
Tester les messages à l'aide de Heartbeat
Il existe une opportunité intéressante pour générer des messages de test automatiques.
Pour ce faire, vous devez inclure le plugin heartbean dans la section d'entrée.
input { heartbeat { message => "HeartBeat!" } }
Allumez, commencez une fois par minute pour recevoir
logstash_one_channel | { logstash_one_channel | "@timestamp" => 2019-04-29T13:52:04.567Z, logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "HeartBeat!", logstash_one_channel | "@version" => "1", logstash_one_channel | "host" => "a0667e5c57ec" logstash_one_channel | }
Nous voulons obtenir plus souvent, nous devons ajouter le paramètre d'intervalle.
C'est ainsi que nous recevrons un message toutes les 10 secondes.
input { heartbeat { message => "HeartBeat!" interval => 10 } }
Récupération des données d'un fichier
Nous avons également décidé de voir le mode fichier. Si cela fonctionne normalement avec le fichier, il est possible qu'aucun agent ne soit nécessaire, enfin, au moins pour une utilisation locale.
Selon la description, le mode de fonctionnement doit être similaire à tail -f, c'est-à-dire lit les nouvelles lignes ou, en option, lit le fichier entier.
Donc, ce que nous voulons obtenir:
- Nous voulons obtenir des lignes qui sont ajoutées à un fichier journal.
- Nous voulons recevoir des données qui sont écrites dans plusieurs fichiers journaux, tout en pouvant partager ce qui en est issu.
- Nous voulons vérifier qu'au redémarrage de logstash, il ne recevra plus ces données.
- Nous voulons vérifier que si logstash est désactivé et que les données continuent d'être écrites dans des fichiers, alors lorsque nous l'exécuterons, nous obtiendrons ces données.
Pour mener l'expérience, ajoutez une autre ligne à docker-compose.yml, ouvrant le répertoire dans lequel nous avons placé les fichiers.
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro - ./logs:/usr/share/logstash/input
Et changez la section d'entrée dans habr_pipeline.conf
input { file { path => "/usr/share/logstash/input/*.log" } }
Nous commençons:
docker-compose up
Pour créer et enregistrer des fichiers journaux, nous utiliserons la commande:
echo '1' >> logs/number1.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:28:53.876Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log" logstash_one_channel | }
Ouais, ça marche!
En même temps, nous voyons que nous avons ajouté automatiquement le champ du chemin. Donc, à l'avenir, nous pouvons filtrer les enregistrements par celui-ci.
Essayons encore:
echo '2' >> logs/number1.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:28:59.906Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "2", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log" logstash_one_channel | }
Et maintenant, dans un autre fichier:
echo '1' >> logs/number2.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:29:26.061Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log" logstash_one_channel | }
Super! Le fichier a été récupéré, le chemin était correct, tout va bien.
Arrêtez logstash et redémarrez. Attendons. Le silence. C'est-à-dire Nous ne recevons plus ces enregistrements.
Et maintenant l'expérience la plus audacieuse.
Nous mettons logstash et exécutons:
echo '3' >> logs/number2.log echo '4' >> logs/number1.log
Exécutez à nouveau logstash et voyez:
logstash_one_channel | { logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "3", logstash_one_channel | "@version" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log", logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.589Z logstash_one_channel | } logstash_one_channel | { logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "4", logstash_one_channel | "@version" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log", logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.856Z logstash_one_channel | }
Hourra! Tout a été ramassé.
Mais, nous devons mettre en garde contre les éléments suivants. Si le conteneur avec logstash est supprimé (docker stop logstash_one_channel && docker rm logstash_one_channel), rien ne sera récupéré. À l'intérieur du conteneur, la position du fichier dans lequel il a été lu a été enregistrée. S'il est exécuté à partir de zéro, il n'acceptera que les nouvelles lignes.
Lire les fichiers existants
Supposons que nous exécutions logstash pour la première fois, mais nous avons déjà des journaux et nous aimerions les traiter.
Si nous exécutons logstash avec la section d'entrée que nous avons utilisée ci-dessus, nous n'obtiendrons rien. Seuls les retours à la ligne seront traités par logstash.
Pour extraire des lignes de fichiers existants, ajoutez une ligne supplémentaire à la section d'entrée:
input { file { start_position => "beginning" path => "/usr/share/logstash/input/*.log" } }
De plus, il y a une nuance, cela n'affecte que les nouveaux fichiers que logstash n'a pas encore vus. Pour les mêmes fichiers qui tombaient déjà dans le champ de vision de logstash, il s'est déjà souvenu de leur taille et n'acceptera désormais que de nouvelles entrées.
Arrêtons-nous sur l'étude de la section d'entrée. Il y a beaucoup plus d'options, mais pour nous, pour de nouvelles expériences, c'est suffisant.
Routage et conversion de données
Essayons de résoudre le problème suivant, disons que nous avons des messages d'un canal, certains d'entre eux sont informatifs, et en partie un message d'erreur. Différent dans la balise. Certaines INFO, d'autres ERREUR.
Nous devons les séparer à la sortie. C'est-à-dire Nous écrivons des messages d'information dans un canal et des messages d'erreur dans un autre.
Pour ce faire, passez de la section d'entrée au filtre et à la sortie.
En utilisant la section filtre, nous analyserons le message entrant, en en tirant du hachage (paires clé-valeur), avec lequel vous pouvez déjà travailler, c'est-à-dire démonter par conditions. Et dans la section sortie, nous sélectionnons les messages et les envoyons à notre chaîne.
Analyser un message à l'aide de grok
Afin d'analyser les chaînes de texte et d'en obtenir un ensemble de champs, il existe un plugin spécial dans la section filtre - grok.
Ne visant pas à donner ici une description détaillée ici (pour cela je me réfère à la
documentation officielle ), je vais donner mon exemple simple.
Pour ce faire, vous devez décider du format des lignes d'entrée. Je les ai:
1 message INFO1
2 Message d'erreur 2
C'est-à-dire L'identifiant vient d'abord, puis INFO / ERREUR, puis un mot sans espaces.
Pas difficile, mais assez pour comprendre comment ça marche.
Donc, dans la section filtre, dans le plugin grok, nous devons définir un modèle pour analyser nos lignes.
Cela ressemblera à ceci:
filter { grok { match => { "message" => ["%{INT:message_id} %{LOGLEVEL:message_type} %{WORD:message_text}"] } } }
Il s'agit essentiellement d'une expression régulière. Des modèles prêts à l'emploi sont utilisés, tels que INT, LOGLEVEL, WORD. Leur description, ainsi que d'autres modèles, peuvent être trouvés
ici.Maintenant, en passant par ce filtre, notre chaîne se transformera en un hachage de trois champs: message_id, message_type, message_text.
Ils seront affichés dans la section de sortie.
Routage des messages dans la section de sortie à l'aide de la commande if
Dans la section de sortie, comme nous nous en souvenons, nous allions diviser les messages en deux flux. Certains - dont iNFO, nous sortirons sur la console, et avec des erreurs, nous sortirons dans un fichier.
Comment divisons-nous ces messages? La condition du problème invite déjà la solution - nous avons déjà le champ message_type sélectionné, qui ne peut prendre que deux valeurs INFO et ERROR. C'est pour lui que nous ferons un choix en utilisant l'instruction if.
if [message_type] == "ERROR" { # } else { # stdout }
La description de l'utilisation des champs et des opérateurs se trouve dans cette section du
manuel officiel .
Maintenant, à propos de la conclusion proprement dite.
La sortie vers la console, tout est clair ici - stdout {}
Et voici la sortie du fichier - rappelez-vous que nous l'exécutons à partir du conteneur et que pour que le fichier dans lequel nous écrivons le résultat soit accessible de l'extérieur, nous devons ouvrir ce répertoire dans docker-compose.yml.
Total:
La section de sortie de notre fichier ressemble à ceci:
output { if [message_type] == "ERROR" { file { path => "/usr/share/logstash/output/test.log" codec => line { format => "custom format: %{message}"} } } else {stdout { } } }
Dans docker-compose.yml, ajoutez un autre volume à la sortie:
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro - ./logs:/usr/share/logstash/input - ./output:/usr/share/logstash/output
Nous commençons, nous essayons, nous voyons la division en deux flux.