Si vous avez déjà comparé les données de deux outils analytiques sur le même site Web ou comparé des analyses avec des rapports et des ventes, vous avez probablement remarqué qu'elles ne correspondent pas toujours. Dans cet article, je vais expliquer pourquoi il n'y a pas de données dans les statistiques des plates-formes d'analyse Web, et quelle peut être l'ampleur de ces pertes.
Dans cet article, nous nous concentrerons sur Google Analytics, le service analytique le plus populaire, bien que la plupart des plates-formes analytiques implémentées sur la page aient les mêmes problèmes. Les services qui s'appuient sur les journaux du serveur évitent certains de ces problèmes, mais ils sont si rarement utilisés que nous ne les couvrirons pas dans cet article.
Configurations de test Analytics dans Distilled
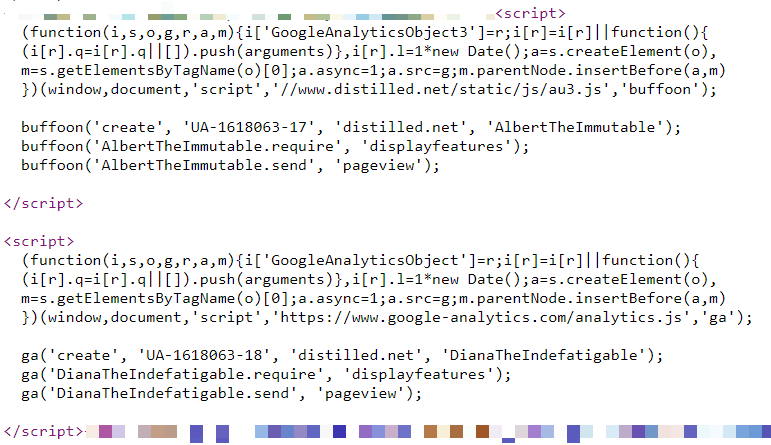
Chez Distilled.net, nous avons une ressource Google Analtics standard qui fonctionne à partir d'une balise HTML dans Google Tag Manager. En outre, au cours des deux dernières années, j'ai utilisé trois implémentations parallèles supplémentaires de Google Analytics, conçues pour mesurer les différences entre différentes configurations.
Deux de ces implémentations supplémentaires - une dans GTM et l'autre sur la page - gèrent des copies renommées stockées localement du fichier JavaScript de Google Analytics (www.distilled.net/static/js/au3.js au lieu de
www.google-analytics.com/ analytics.js ) pour les rendre plus difficiles à détecter pour les bloqueurs de publicités.
J'ai également utilisé des fonctions JavaScript renommées ("tcap" et "Buffoon" au lieu du "ga" standard) et des trackers renommés ("FredTheUnblockable" et "AlbertTheImmutable") pour éviter le problème des trackers en double (qui peuvent souvent entraîner des problèmes).
Enfin, nous avons la configuration «DianaTheIndefatigable», qui a un tracker renommé, mais utilise du code standard et est implémentée au niveau de la page.
Toutes nos configurations sont présentées dans le tableau ci-dessous:

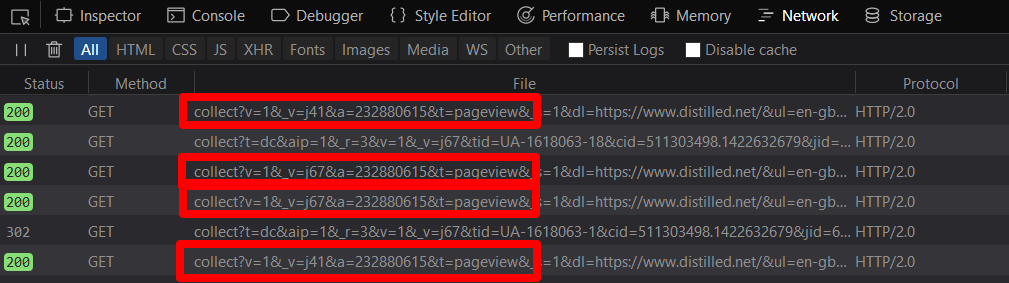
J'ai testé leurs fonctionnalités dans différents navigateurs et bloqueurs de publicités en analysant les pages vues apparaissant dans les outils de développement de navigateur:
Raisons de la perte de données
1. Bloqueurs de publicités
Les bloqueurs de publicités, principalement sous la forme d'extensions de navigateur, sont de plus en plus courants. Initialement, la principale raison de leur utilisation était d'améliorer les performances et l'expérience d'interaction sur les sites avec une grande quantité de publicité. Ces dernières années, l'accent mis sur la confidentialité des données a augmenté, ce qui a également contribué à la popularité des bloqueurs de publicités.
L'effet des bloqueurs de publicitésCertains bloqueurs de publicités bloquent les plates-formes d'analyse Web par défaut; d'autres peuvent être configurés pour exécuter cette fonction. J'ai testé le site Web Distilled avec Adblock Plus et uBlock Origin, les deux extensions de navigateur de bureau les plus populaires pour le blocage des publicités, mais il convient de noter que les bloqueurs de publicités sont également de plus en plus utilisés sur les smartphones.
Les résultats suivants ont été obtenus (tous les chiffres se rapportent à avril 2018):
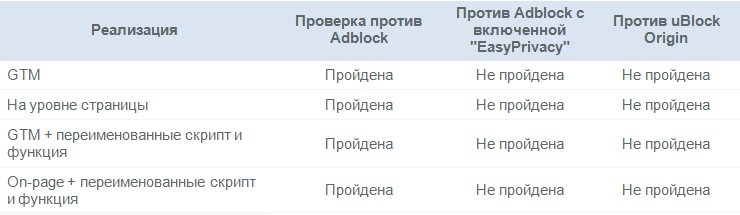
Comme le montre le tableau, les paramètres GA modifiés n'aident pas beaucoup à résister aux bloqueurs.
Perte de données due aux bloqueurs de publicités: ~ 10%L'utilisation de bloqueurs de publicités peut être de 15 à 25% selon la région, mais bon nombre de ces paramètres sont AdBlock Plus avec des paramètres par défaut, dans lesquels, comme nous l'avons vu ci-dessus, le suivi n'est pas bloqué.
La part d'AdBlock Plus sur le marché des bloqueurs de publicités varie entre 50 et 70%.
Selon des estimations récentes , ce chiffre est plus proche de 50%. Par conséquent, si nous supposons que pas plus de 50% des bloqueurs de publicités installés bloquent les analyses, nous obtiendrons une perte de données au niveau d'environ 10%.
2. Fonction Ne pas suivre dans les navigateurs
Il s'agit d'une autre fonctionnalité motivée par la protection de la vie privée. Mais cette fois, il ne s'agit pas de l'add-on, mais de la fonction des navigateurs eux-mêmes. Il n'est pas nécessaire de répondre à la demande «Ne pas suivre» pour les sites et les plates-formes, mais, par exemple, Firefox offre une fonction plus puissante sous le même ensemble de paramètres, que j'ai également décidé de tester.
L'effet de Ne pas suivreLa plupart des navigateurs proposent désormais l'option de message Ne pas suivre. J'ai testé les dernières versions des navigateurs Firefox et Chrome pour Windows 10.
 Encore une fois, il semble que les paramètres modifiés ici n'aident pas beaucoup non plus.Perte de données due à "Ne pas suivre": <1%
Encore une fois, il semble que les paramètres modifiés ici n'aident pas beaucoup non plus.Perte de données due à "Ne pas suivre": <1%Les tests ont montré que seule la fonctionnalité de protection contre le suivi du navigateur Firefox Quantum affecte les trackers. Firefox occupe 5% du marché des navigateurs, mais la protection contre le suivi n'est pas activée par défaut. Par conséquent, le lancement de cette fonction n'a pas affecté les tendances du trafic Firefox sur Distilled.net.
3. Filtres
Les filtres que vous configurez dans le système d'analyse peuvent sous-estimer intentionnellement ou non le volume du trafic reçu dans les rapports.
Par exemple, un filtre qui exclut certaines résolutions d'écran, qui peuvent être des bots ou du trafic interne, entraînera évidemment une sous-estimation du trafic.
Perte de données due aux filtres: N / A
L'impact de ce facteur est difficile à évaluer, car ce paramètre varie en fonction du site. Mais je recommande fortement d'avoir une vue "principale" en double (sans filtres) afin que vous puissiez voir rapidement la perte d'informations importantes.
4. GTM vs sur la page vs code mal localisé
Ces dernières années, Google Tag Manager est devenu un moyen de plus en plus populaire d'implémenter l'analyse en raison de sa flexibilité et de sa facilité à apporter des modifications. Cependant, j'ai longtemps remarqué que cette méthode d'implémentation GA peut conduire à une sous-estimation par rapport au paramètre au niveau de la page.
J'étais également curieux de savoir ce qui se passerait si vous ne suiviez pas les recommandations de Google pour définir le code sur la page.
En combinant mes propres données avec les données du
site de mon collègue Dom Woodman, qui utilise l'extension analytique Drupal, ainsi que GTM, j'ai pu voir la différence entre le gestionnaire de balises et le code incorrectement situé sur la page (placé au bas de la balise). Ensuite, j'ai fait correspondre ces données avec mes propres données GTM pour voir l'image complète à travers les 5 configurations.
Impact de GTM et code sur la page égaré
Trafic en pourcentage de la ligne de base (implémentation standard à l'aide de Tag Manager):
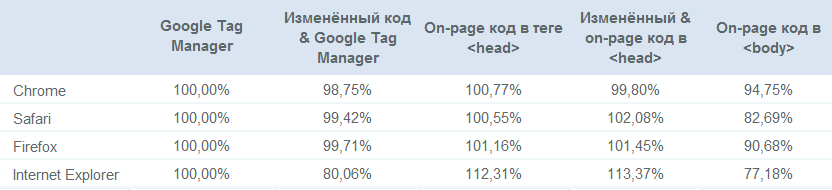
Constatations clés
- Le code sur la page enregistre généralement plus de trafic que GTM;
- Le code modifié est généralement dans la marge d'erreur, à l'exception du code GTM modifié dans Internet Explorer;
- Un code de suivi mal localisé vous coûtera jusqu'à 30% de votre trafic par rapport au code en ligne correctement implémenté, selon le navigateur (!);
- Les configurations personnalisées conçues pour recevoir plus de trafic en évitant les bloqueurs de publicités ne le font pas.
Il convient également de noter que les implémentations utilisateur reçoivent en fait moins de trafic que les implémentations standard. Dans le cas du code sur la page, les pertes sont dans la marge d'erreur, mais dans le cas de GTM, il y a une autre nuance qui pourrait affecter les données finales.
Depuis que j'ai utilisé des profils non filtrés pour la comparaison, il y avait beaucoup de spam de robots dans le profil principal, qui était principalement déguisé en Internet Explorer.
Aujourd'hui, notre profil principal est le plus spammé, mais il est également utilisé comme niveau choisi pour la comparaison, de sorte que la différence entre le code sur la page et le gestionnaire de balises est en fait légèrement plus grande.
Perte de données GTM: 1-5%
Les pertes associées à GTM varient en fonction des navigateurs et des appareils utilisés par les visiteurs de votre site. Sur Distilled.net, la différence est d'environ 1,7%, notre public utilise activement les ordinateurs de bureau et est techniquement avancé, Internet Explorer est rarement utilisé. Selon la verticale, les pertes peuvent atteindre 5%.
J'ai également effectué une ventilation par appareil:

Perte de données due à un code sur la page mal localisé: ~ 10%
Sur Teflsearch.com, environ 7,5% des données ont été perdues en raison d'un code mal localisé, contre GTM. Étant donné que le Tag Manager lui-même sous-estime les données, la perte totale pourrait facilement atteindre 10%.
Bonus: perte de données des canaux
Ci-dessus, nous avons examiné les domaines dans lesquels vous pouvez perdre des données en général. Cependant, il existe d'autres facteurs conduisant à des données incomplètes. Nous les examinerons plus brièvement. Les principaux problèmes ici sont le trafic sombre et l'attribution.
Trafic sombreLe trafic sombre est du trafic direct, qui n'est pas vraiment du trafic direct.
Et cela devient une situation de plus en plus courante.
Causes typiques du trafic sombre:
- Campagnes de marketing par e-mail non marquées;
- Campagnes non marquées dans les applications (notamment Facebook, Twitter, etc.);
- Trafic organique déformé;
- Données envoyées en raison d'erreurs commises lors du processus de configuration du suivi (peuvent également apparaître comme des références automatiques);
Il convient également de noter une tendance dans le sens d'une croissance du trafic réellement direct, historiquement organique. Par exemple, en lien avec l'amélioration de la fonction de saisie semi-automatique dans les navigateurs, la synchronisation de l'historique de recherche sur différents appareils, etc., les gens semblent «saisir» l'URL qu'ils recherchaient plus tôt.
Attribution
En général, une session dans Google Analytics (et sur toute autre plate-forme) est une construction plutôt arbitraire. Vous pouvez trouver évident comment un groupe d'appels doit être combiné en une ou plusieurs sessions, mais en réalité, ce processus repose sur un certain nombre d'hypothèses plutôt douteuses. En particulier, il convient de noter que Google Analytics attribue généralement le trafic direct (y compris le trafic sombre) à la source non directe précédente, le cas échéant.
Conclusion
J'ai été quelque peu surpris par certains des résultats que j'ai reçus, mais je suis sûr que je n'ai pas tout couvert, et il existe d'autres façons de perdre des données. Ainsi, la recherche dans ce domaine peut être poursuivie.
D'autres articles de ce type peuvent être lus sur ma
chaîne de télégrammes (proroas).